---
description: OneAI Documentation
tags: Case Study, CVAT, EN
---
[OneAI Documentation](/s/user-guide-en)
# AI Maker Case Study - Implement Assisted Inference Module to CVAT
[TOC]
## 1. Introduction
AI Maker has a integrated with CVAT (Computer Vision Annotation Tool) to help you quickly annotate the training data of machine learning, or connect the trained model to CVAT through the inference service for automatic annotation.
In the [**AI Maker Case Study - YOLOv4 Image Recognition Application**](/s/casestudy-yolov4-en) example, we learned to train our own deep learning model using AI Maker, and use the trained model to provide **`yolov4-cvat`** inference templates through AI Maker to perform image data annotation inference service in combination with CVAT's automatic annotation function. This is an advanced tutorial with two API implementation examples to illustrate how to connect the CVAT assisted/automated annotation API with YOLOv4 and SiamMask models.
Before learning this example, please familiarize yourself with the basic operations of AI Maker and CVAT (Computer Vision Annotation Tool), or read the following documents:
* [**Container Image**](/s/container-image-en)
* [**AI Maker > Inference Service**](/s/ai-maker-en#Inference)
* [**AI Maker Case Study - YOLOv4 Image Recognition Application > CVAT Assisted Annotation**](/s/casestudy-yolov4-en#6-CVAT-Assisted-Annotation)
* [**CVAT Documentation**](https://opencv.github.io/cvat/docs/)
* [**CVAT GitHub**](https://github.com/opencv/cvat)
## 2. CVAT-Assisted Annotation Inference Service
CVAT's native model deployment functionality is built on the [**Nuclio**](https://nuclio.io/) platform and implemented as its counterpart Serverless Functions. However, it is very tedious to [**Set Up Nuclio Environment**](https://github.com/nuclio/nuclio/blob/development/docs/setup/k8s/getting-started-k8s.md) and [**Deploy Relevant Functions**](https://github.com/nuclio/nuclio/blob/development/docs/tasks/deploying-functions.md). The CVAT annotation tool integrated by AI Maker makes CVAT-assisted annotation in model inference deployment less tedious, you can quickly deploy CVAT-assisted annotation inference service through AI Maker by implementing the API of CVAT-assisted annotation inference service.
### 2.1 Architecture Description
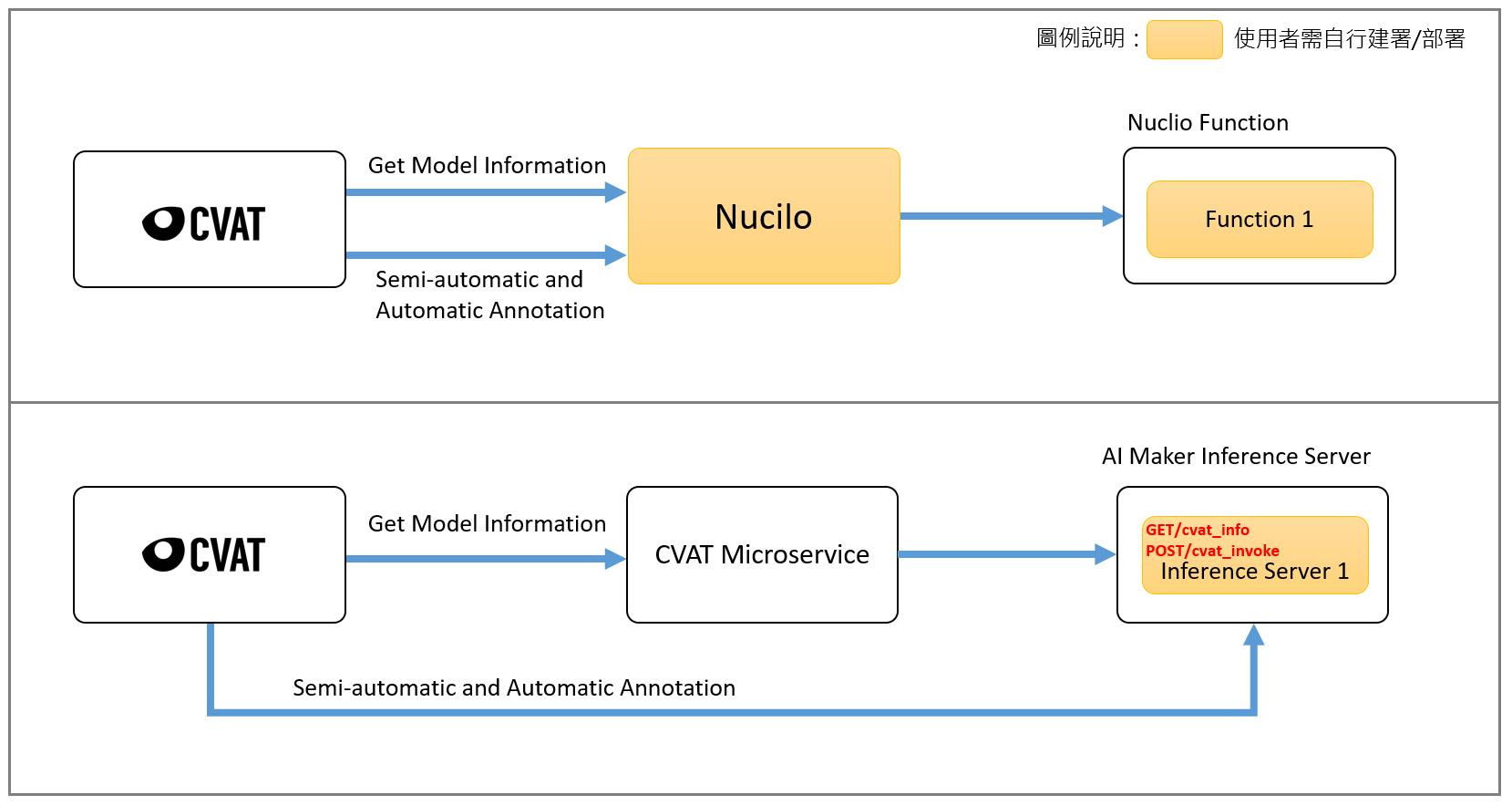
The architecture of CVAT assisted annotation service is shown below. The yellow squares represent the functions that users need to build and deploy by themselves. The upper part of the diagram is the native CVAT and Nuclio platforms. Users need to set up the Nuclio platform and deploy the relevant Functions ; The lower part of the diagram shows the integration of CVAT's assisted annotation and model inference deployment functions through AI Maker. Users only need to deploy the relevant inference service to connect with CVAT's assisted annotation service.
:::info
:bulb: **Tips: CVAT Microservice** is a built-in microservice in AI Maker. Its function is to bridge CVAT and inference service, so that AI Maker's built-in CVAT can query model information and allow AI Maker's inference service to connect with CVAT's assisted/automatic annotation function.
:::
### 2.2 API Description
From the above diagram, we can see that there are two APIs that users need to implement to connect CVAT assisted annotation and AI Maker inference service: **`cvat_info`** and **`cvat_invoke`**. The implementation of these two APIs is described below.
| API Name | Description |
|-----|------------|
| **cvat_info** |To define the model information, you need to fill in the framework, type, description and spec information. CVAT will call this API when querying the model information, as shown in the figure. <br> <br> 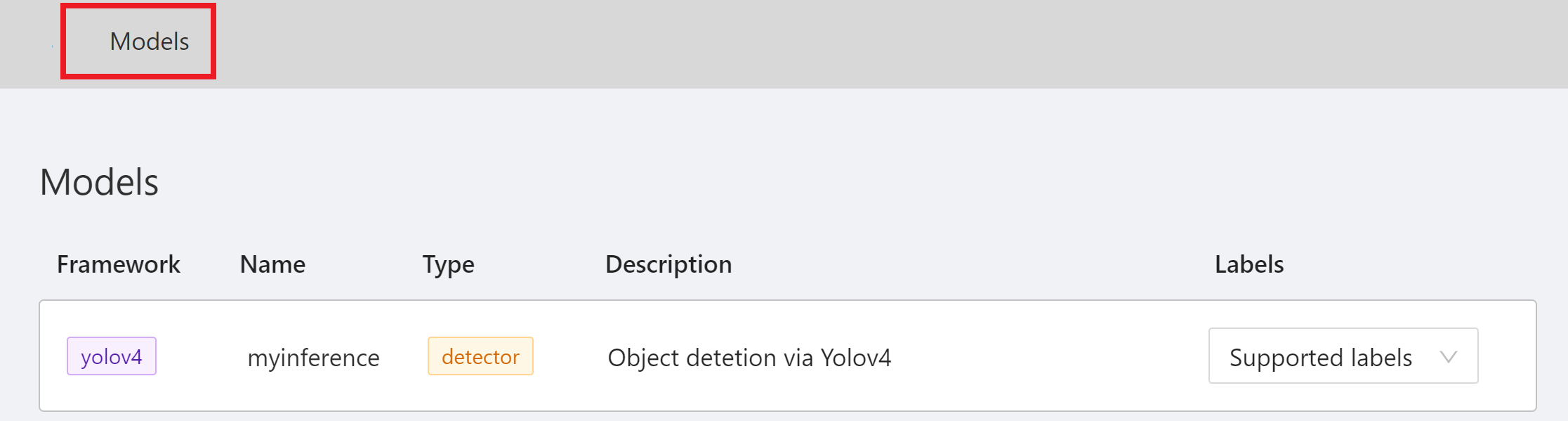
| **cvat_invoke** | The result of inference implementation, CVAT will call this API when performing **Assisted and Automatic Annotation**. CVAT will send a Base64-encoded image through HTTP POST Method. We need to implement and return the inference result to CVAT. The type of data returned will be different according to the type filled in the information of the definition model. Detailed information will be presented in the following sections.
The following information about **cvat_info** is required to implement the model.
| Name | Description |
|-----|------------|
|framework |The frame of the model.
|type |There are four types of identification tasks that define the model. For details, please refer to the links in parentheses.<br>** detector**- used for automatic annotation (CVAT [detectors](https://opencv.github.io/cvat/docs/manual/advanced/ai-tools/#detectors) and [automatic annotation](https://opencv.github.io/cvat/docs/manual/advanced/automatic-annotation/))<br>**interactor** - for assisted annotation of frame (CVAT [interactors](https://opencv.github.io/cvat/docs/manual/advanced/ai-tools/#interactors)) <br>**tracker** - for tracking assisted annotation (CVAT [trackers](https://opencv.github.io/cvat/docs/manual/advanced/ai-tools/#trackers))<br>**reid** - automatic annotation for pedestrian re-identification (CVAT [automatic annotation](https://opencv.github.io/cvat/docs/manual/advanced/automatic-annotation/))
|description | A description of the model.
|spec | Lists the supported tags (only required when the model type is detector, if not, please enter None for this field).
The table below shows the corresponding types of commonly used models in CVAT. For more information, please refer to [**CVAT GitHub**](https://github.com/opencv/cvat#deep-learning-serverless-functions-for-automatic-labeling).
| Name | Type|
|-----|------------|
|Deep Extreme Cut|interactor
|Faster RCNN | detector
|Mask RCNN| detector
|YOLO v3/v4| detector
|Object reidentification|reid
|Semantic segmentation for ADAS|detector
|Text detection v4|detector
|SiamMask|tracker
|f-BRS|interactor
|HRNet|interactor
|Inside-Outside Guidance|interactor
|RetinaNet|detector
## 3. Example 1: Detector API
Example 1 will use the Yolov4 model to implement the Detector API connected with CVAT automatic annotation. Before starting, it is recommended that you read [**AI Maker Case Study - YOLOv4 Image Recognition Application > CVAT Assisted Annotation**](/s/casestudy-yolov4-en#6-CVAT-assisted-annotation).
<center>Automatic Annotation Schema</center>
### 3.1 API Example
Blow is an example of the Yolov4 model implementation Detector API, showing the input data and the data structure to be returned by the cvat_info and cvat_invoke APIs.
**Request**
* URL: GET /cvat_info
**Response**
* Body:
```json=
HTTP/1.1 200 OK
{
"framework":"yolov4",
"spec":[
{ "id": 0, "name": "people" },
{ "id": 1, "name": "cat"}
],
"type": "detector",
"description":"Object detection via Yolov4"
}
```
**Request**
* URL: POST /cvat_invoke
* Body:
```json=
{
"image":"base64_encode_image"
}
```
**Response**
* Body:
```json=
HTTP/1.1 200 OK
[
{
"label": "people",
"points": [
286,
751,
432,
903
],
"type": "rectangle"
},
{
"label": "cat",
"points": [
69,
1112,
331,
1175
],
"type": "rectangle"
}
]
```
### 3.2 API Sample Code
This section provides a sample Detector program to demonstrate how to implement the two APIs cvat_info and cvat_invoke using the lightweight **Python Flask** web framework.
This example uses [**YOLOv4**](https://github.com/AlexeyAB/darknet) to implement the Detector API, as described below:
:::spoiler **Example code: `main.py`**
```python=
# -*- coding: utf-8 -*-
import base64
from flask import Flask, request, jsonify
import logging
import json
from model_handler import ModelHandler
app = Flask(__name__)
logger = logging.getLogger('flask.app')
model_handler = ModelHandler()
model_handler.init()
@app.route('/cvat_info', methods=['GET'])
def cvat_info():
labels = model_handler.label()
resp = {
"framework": "yolov4",
"type": "detector",
"spec": labels,
"description": "Object detection via Yolov4"
}
return resp
@app.route('/cvat_invoke', methods=['POST'])
def cvat_invoke():
data = request.get_json()
img = base64.b64decode(data['image'].encode('utf8'))
detections = model_handler.detection(img)
results = []
for detection in detections:
obj_class = detection[0]
bbox = detection[2]
left, top, right, bottom = model_handler.bbox2points(bbox)
points = [left, top, right, bottom]
results.append({
"label": obj_class,
"points": points,
"type": "rectangle"
})
body=json.dumps(results)
return body
if __name__ == "__main__":
app.run(host="0.0.0.0", debug=True, port=9999)
```
:::
* Line 10~11: Model initialization.
* Line 13 ~ 22: Implement the cvat_info API, define model information and return the information in JSON format.
* Line 24 ~ 41: Implement the cvat_invoke API, which mainly receives Base64-encoded images, decodes them and inputs them into the YOLOv4 Model for identification, and returns the identified data in JSON format.
:::spoiler **Example code: `model_handler.py`**
```python=
import os
import glob
import random
import time
import shutil
import cv2
import numpy as np
import darknet
YOLO_SUB_FOLDER = os.environ.get('YOLO_SUB_FOLDER', 'yolov4')
YOLO_NAMES_FILENAME = os.environ.get('YOLO_NAMES_FILENAME', 'dataset.names')
YOLO_DATA_FILENAME = os.environ.get('YOLO_DATA_FILENAME', 'dataset.data')
YOLO_CFG_FILENAME = os.environ.get('YOLO_CFG_FILENAME', 'yolo.cfg')
YOLO_WEIGHTS_FILENAME = os.environ.get('YOLO_WEIGHTS_FILENAME', 'yolo_final.weights')
AIMAKER_FOLDER = os.environ.get('AI_MAKER_FOLDER', '/ai-maker/models/')
ORI_PATH = AIMAKER_FOLDER + YOLO_SUB_FOLDER
DST_PATH = "/output/" + "yolov4"
SEPARATE = "/"
EndLine = "\n"
DARKNET_NAME = DST_PATH + SEPARATE + YOLO_NAMES_FILENAME
DARKNET_DATA = DST_PATH + SEPARATE + YOLO_DATA_FILENAME
DARKNET_CFG = DST_PATH + SEPARATE + YOLO_CFG_FILENAME
DARKNET_WEIGHTS = ORI_PATH + SEPARATE + YOLO_WEIGHTS_FILENAME
class ModelHandler:
def __init__(self):
self.weights = DARKNET_WEIGHTS
self.config_file = DARKNET_CFG
self.data_file = DARKNET_DATA
self.name_file = DARKNET_NAME
self.batch_size = 1
self.thresh = 0.3
self.network = None
self.class_names = None
self.class_colors = None
def copyFile(self):
print("copy:--------------------", flush=True)
fileNames = [
YOLO_DATA_FILENAME,
YOLO_NAMES_FILENAME,
YOLO_CFG_FILENAME
]
for fileName in fileNames:
src = ORI_PATH + SEPARATE + fileName
dst = DST_PATH + SEPARATE + fileName
shutil.copyfile(src, dst)
def createFolder(self):
dirs = [
DST_PATH,
]
for dir in dirs:
if not os.path.exists(dir):
os.makedirs(dir)
else:
print(dir + 'already exist')
def updateNameInData(self):
src = DST_PATH + SEPARATE + YOLO_DATA_FILENAME
labelPath = DST_PATH + SEPARATE + YOLO_NAMES_FILENAME
dst = src + ".bak"
key = "names"
with open(src, 'r', encoding='utf-8') as f:
with open(dst, 'w', encoding='utf-8') as f2:
for line in f.readlines():
find = line.startswith(key, 0, len(key))
if (find):
line = key + "=" + labelPath + EndLine
f2.write(line)
os.remove(src)
os.rename(dst, src)
def init(self):
self.createFolder()
self.copyFile()
self.updateNameInData()
self.network, self.class_names, self.class_colors = darknet.load_network(
self.config_file,
self.data_file,
self.weights,
batch_size=self.batch_size)
self.width = darknet.network_width(self.network)
self.height = darknet.network_height(self.network)
def image_detection(self, data):
npimg = np.frombuffer(data,'u1')
source = cv2.imdecode(npimg, cv2.COLOR_BGR2RGB)
img_height, img_width, channels = source.shape
darknet_image = darknet.make_image(img_width, img_height, 3)
darknet.copy_image_from_bytes(darknet_image, source.tobytes())
detections = darknet.detect_image(self.network, self.class_names, darknet_image, self.thresh)
darknet.free_image(darknet_image)
return detections
def detection(self,img):
detections = self.image_detection(img)
return detections
def bbox2points(self,bbox):
"""
From bounding box yolo format
to corner points cv2 rectangle
"""
x, y, w, h = bbox
xmin = int(round(x - (w / 2)))
xmax = int(round(x + (w / 2)))
ymin = int(round(y - (h / 2)))
ymax = int(round(y + (h / 2)))
return xmin, ymin, xmax, ymax
def label(self):
index = 0
labels = []
for line in open(self.name_file):
labels.append({"id":index,"name":line.rstrip('\n')})
index = index +1
return labels
```
:::
* It is mainly responsible for model loading and model inference.
### 3.3 Create And Upload Container Image
In the previous section, we introduced a sample program for implementing CVAT-assisted annotation in model inference deployment, followed by packaging the program into a **Container Image** for deployment to AI Maker's inference service.
Below is the Dockerfile for creating the Detector API container image. Please put the corresponding sample programs (`main.py` and `model_handler.py`) and the Dockerfile in the same folder, and then use the **`docker build`** command to build the container image and upload the created container image. For details, please refer to the [**Container Image Documentation**](/s/container-image-en).
:::spoiler **Detector Dockerfile**
```dockerfile=
From nvidia/cuda:11.0.3-cudnn8-devel-ubuntu18.04
ENV PATH "/root/miniconda3/bin:${PATH}"
RUN apt update \
&& apt install -y --no-install-recommends \
wget \
git \
ca-certificates \
libglib2.0-0 \
libsm6 \
libxrender1 \
libxext6 \
vim \
&& rm -rf /var/lib/apt/lists/*
RUN wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh \
&& chmod +x Miniconda3-latest-Linux-x86_64.sh && ./Miniconda3-latest-Linux-x86_64.sh -b \
&& rm -f Miniconda3-latest-Linux-x86_64.sh
RUN conda create -y -n yolov4 python=3.6
# Override Default Shell And Use Bash
SHELL ["conda", "run", "-n", "yolov4", "/bin/bash", "-c"]
RUN pip install flask \
Cython \
colorama \
numpy \
requests \
fire \
matplotlib \
numba \
scipy \
h5py \
pandas \
tqdm \
opencv_python==3.4.8.29 \
&& conda install -y gcc_linux-64
RUN git clone https://github.com/AlexeyAB/darknet.git
WORKDIR /darknet
RUN sed -i 's/LIBSO=0/LIBSO=1/g' Makefile
RUN make
COPY main.py /darknet/
COPY model_handler.py /darknet/
ENTRYPOINT ["conda", "run","--no-capture-output", "-n", "yolov4", "python", "-u","/darknet/main.py"]
```
:::
### 3.4 Model Preparation
If you use the model trained by the yolov4 template, please skip this step; if you use your own YOLOv4 model or a model obtained from other sources (for example: [**YOLOv4 model zoo**](https://github.com/AlexeyAB/darknet/wiki/YOLOv4-model-zoo)), please follow these steps to prepare the model using the YOLOv4 COCO pre-trained model as an example.
1. Download the files related to the model
* Click here to download [**yolov4.cfg**](https://drive.google.com/open?id=1hSrVqiEbuVewEIVU4cqG-SqJFUNTYmIC)
* Click here to download [**yolov4.weights**](https://drive.google.com/open?id=1L-SO373Udc9tPz5yLkgti5IAXFboVhUt)
* Click here to download [**coco.names**](https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/coco.names)
* Click here to download [**coco.data**](https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/coco.data)
2. Modify the file name
* Please rename yolov4.cfg to yolo.cfg
* Please rename coco.names to dataset.names
* Please rename coco.data to dataset.data
* Please rename yolov4.weights to yolo_final.weights
3. Compress the files and upload
* Add a new folder named yolov4.
* Put the above four files into the yolov4 folder and compress it into a ZIP file. The folder structure is as follows:
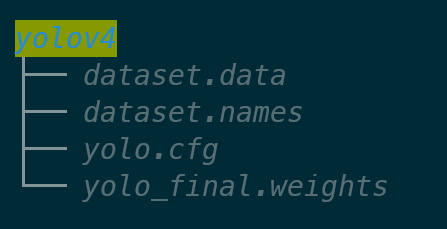
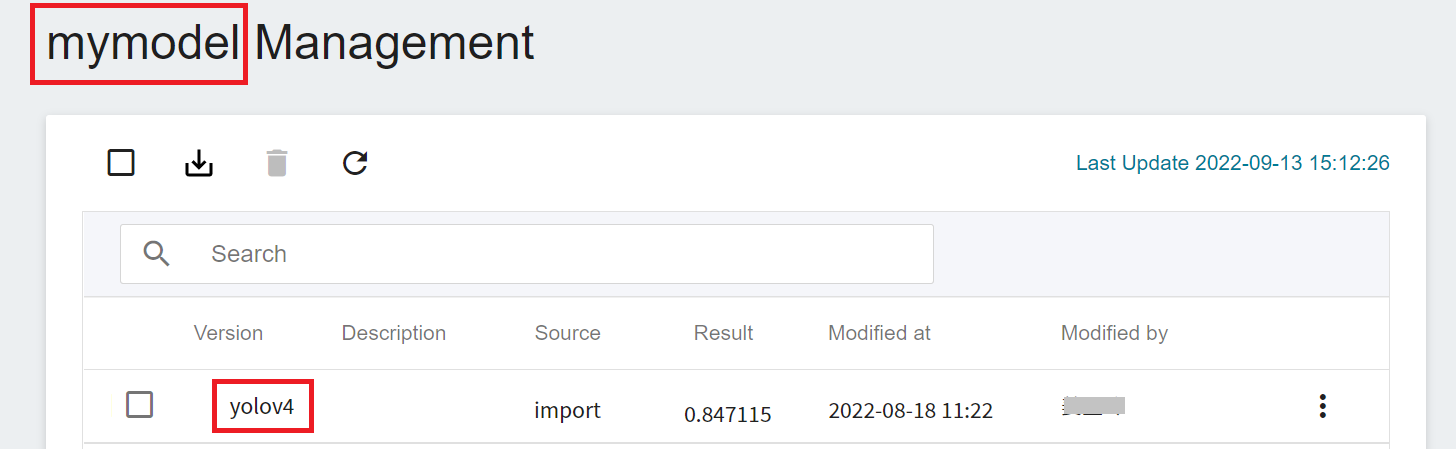
* Then upload this ZIP file to OneAI's **Storage Service**, and then go to AI Maker's model management to import this model. For detailed steps, please refer to the [**AI Maker Import Model Instructions**](/s/ai-maker-en#Import-Model).
* Please remember the model name and version after the model is imported, the inference service will be deployed with this model next.
### 3.5 Deploy Inference Service
After preparing the inference image and model, you can then deploy the inference service to AI Maker. When creating an inference service, you need to select your model and this image. We only describe some important settings. For other steps, please refer to the [**Create Inference Task instructions**](/s/ai-maker-en#Create-Inference-Tasks).
1. **Basic Settings**
* **Source Model**
- Name: Please enter **`yolov4`**.
- Category: Please select **Private**.
- Model Name: Please select the model name you want to load.
- Version: Please select the model version you want to load.
- Mount Path: Please enter **`/ai-maker/models/`**.
* **Image Source**: Please select the image and tag you just uploaded.
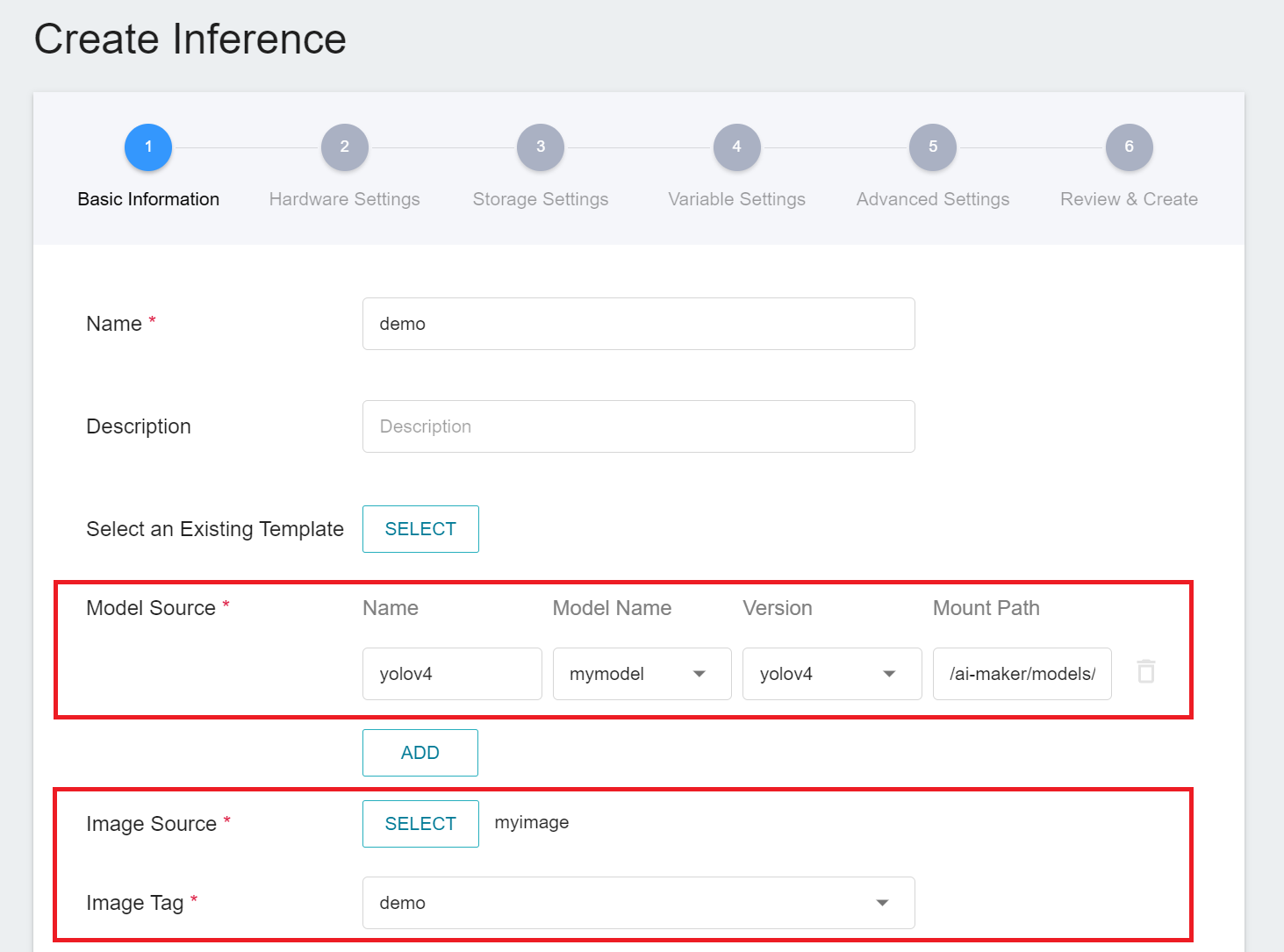
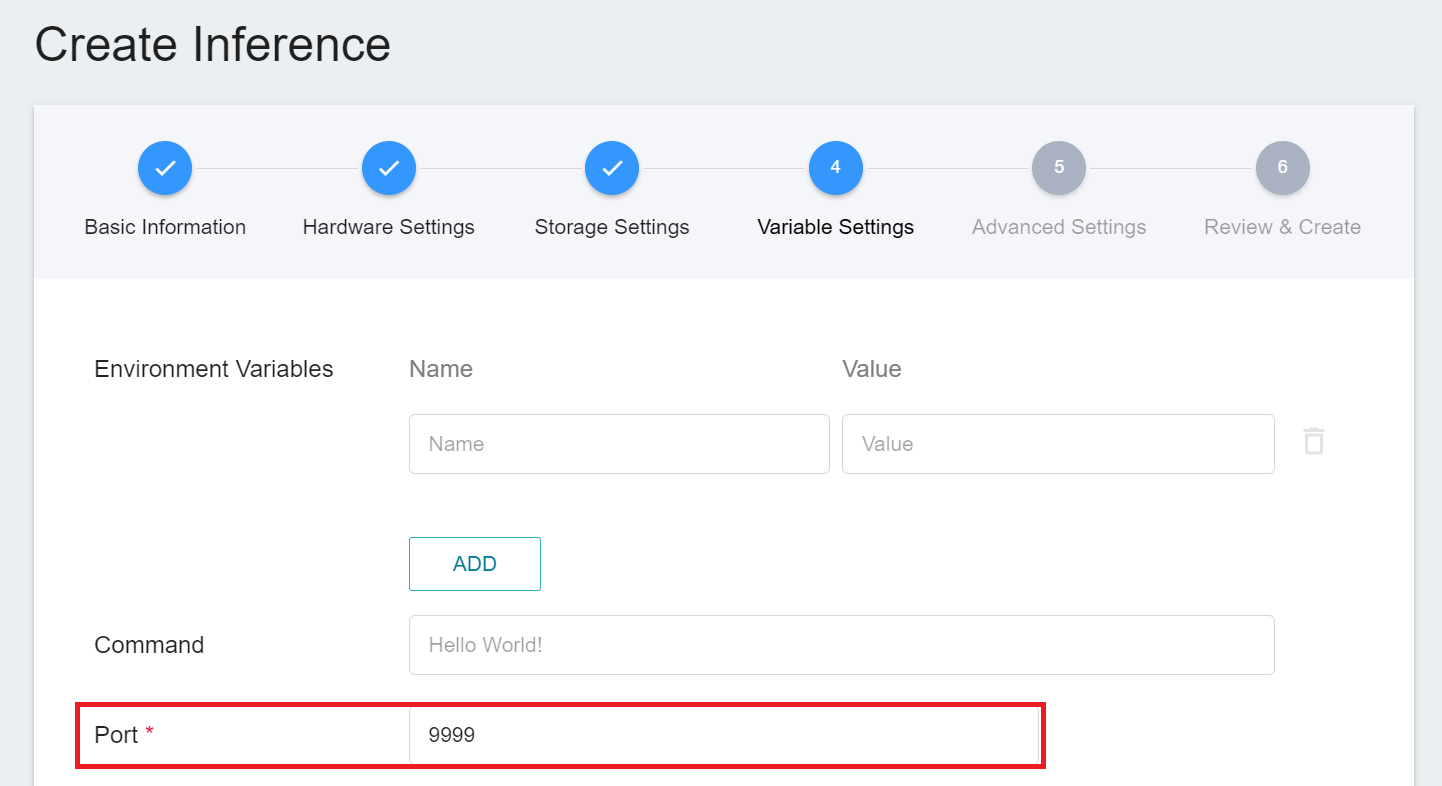
2. **Variable Settings**: Port should be set to **`9999`**.
### 3.6 Connect to CVAT
When the status of the inference service is **`Ready`**, we need to do the last step, click the **CONNECT TO CVAT** icon above to connect to CVAT for assisted annotation.
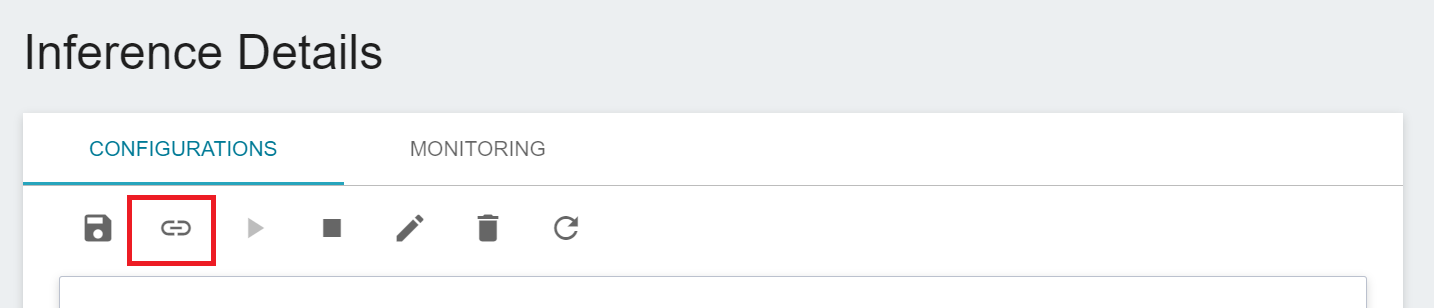
After connecting to CVAT, enter the CVAT service to see the inference service model connected to CVAT on the **Models** page of CVAT.
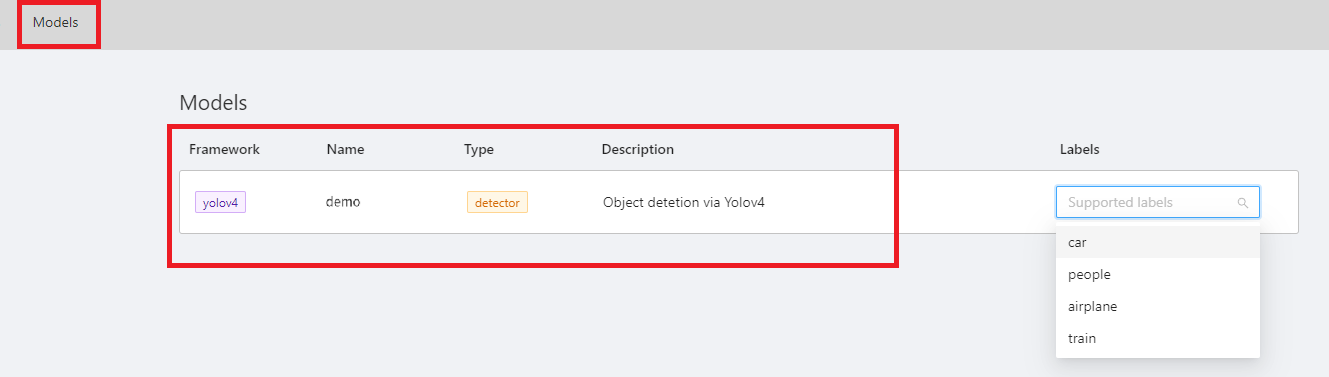
Congratulations, you can start using the CVAT assisted annotation/automatic annotation function now.

### 3.7 Use CVAT Assisted Annotation/Automatic Annotation
There are two ways to use the CVAT assisted annotation/automatic annotation function:
1. Assisted annotation/automatic annotation of all pictures for the entire Task
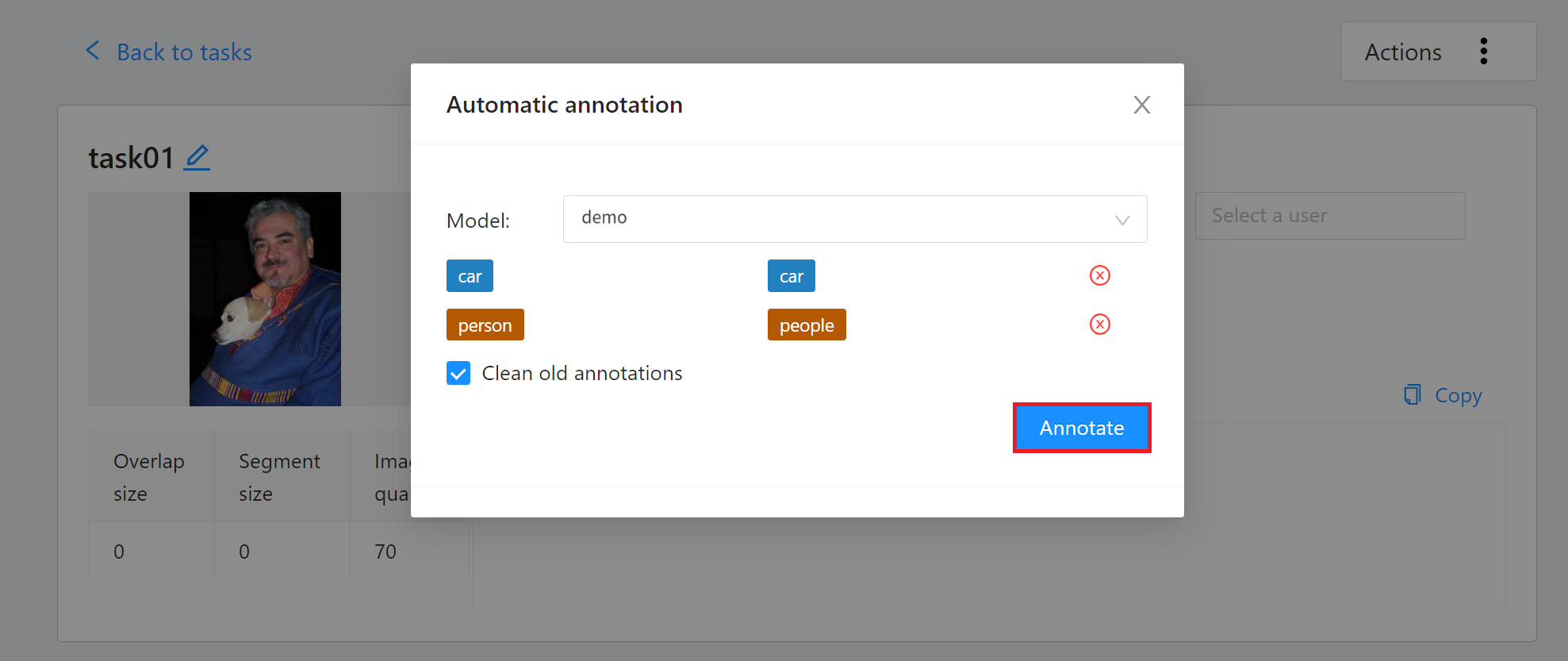
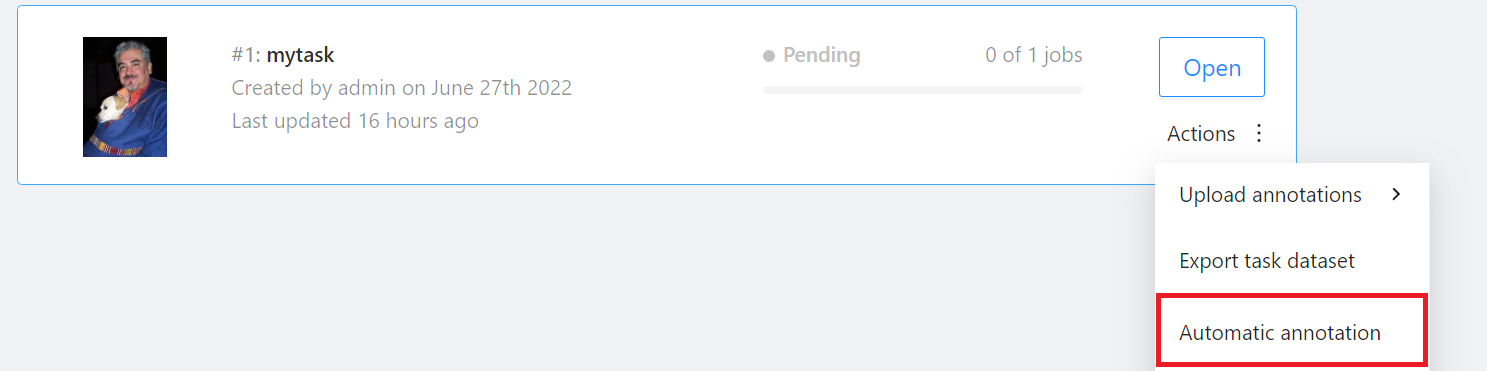
Go to the **Tasks** page and find the Task you want to annotate, then move the mouse over the More options icon in **Actions** to the right of the Task you want to annotate automatically, and then click **AUTOMATIC ANNOTATION**.
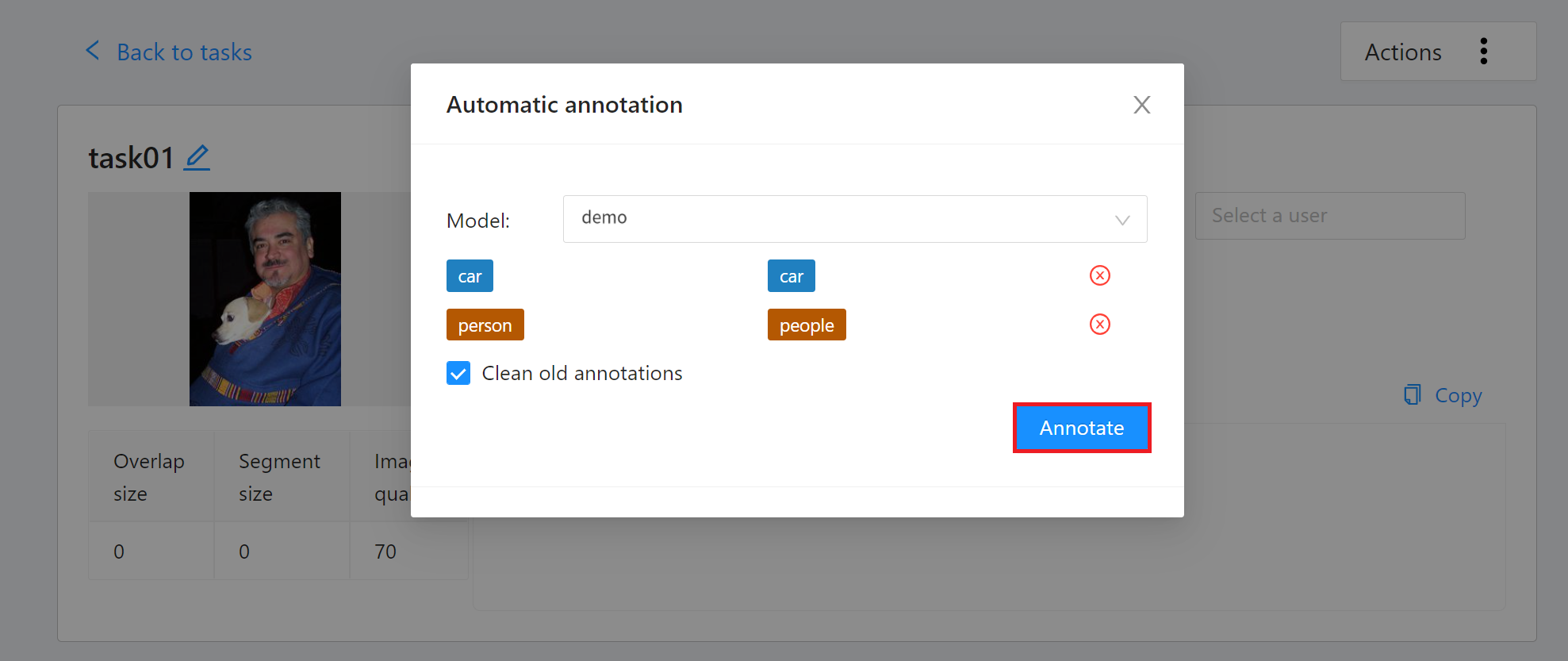
On the **Automatic Annotation** window that appears, click the **Model** drop-down menu and select the connected inference task. Then set the model to correspond to the task Label, and finally click **ANNOTATE** to perform automatic annotation.
After the annotation is completed, enter the CVAT Annotation Tools page to view the automatic annotation result. If you are not satisfied with the result, you can perform manual annotation correction.
2. Assisted annotation /automatic annotation of a single picture
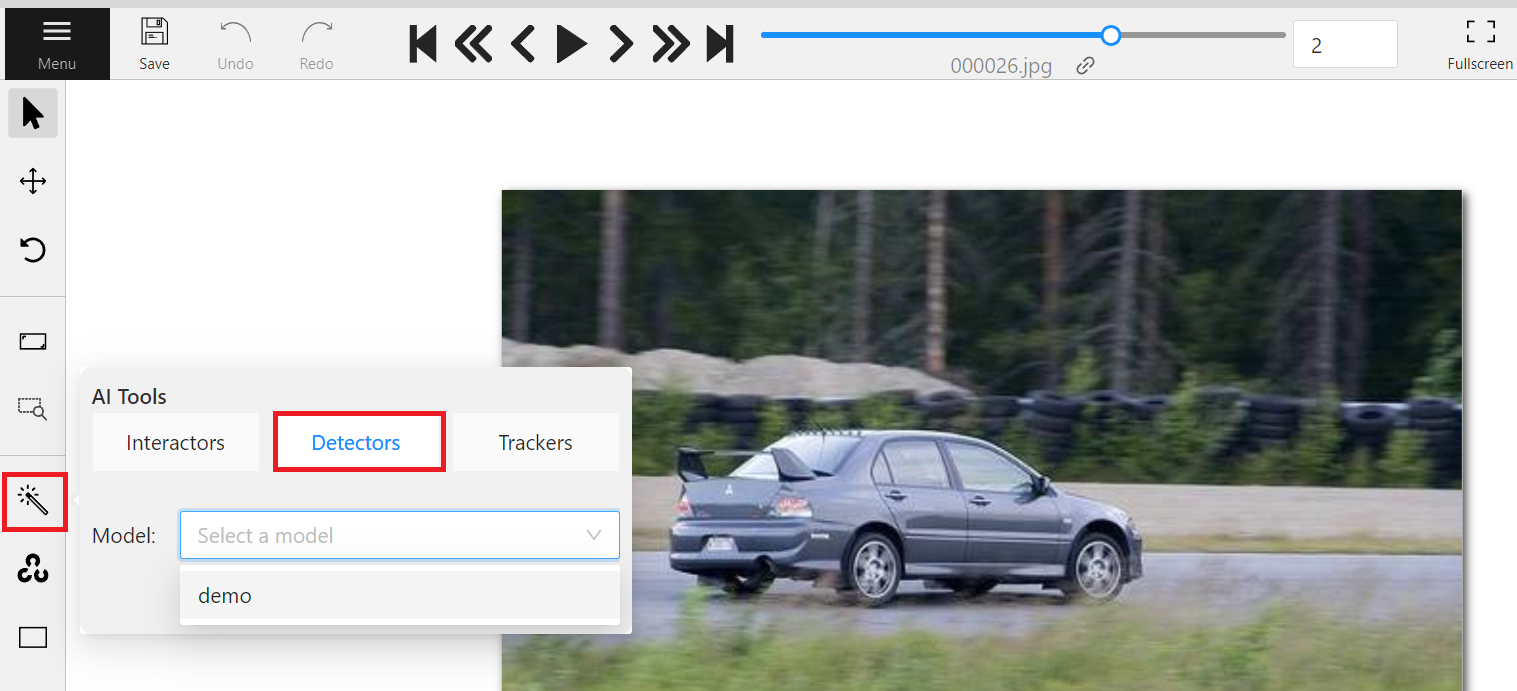
Select the picture you want to annotate after entering the annotation page. If there is a target object in the picture, you can annotate it according to the following steps.
*Click the Magic Wand (AI Tools) on the left toolbar.
*Select **Detectors**
*Select the Model you just connected.
## 4. Example 2: Tracker API
In Example 2, we will use the siamMask model to implement the Tracker API that connects to CVAT automatic annotation. It is recommended that you review the [**CVAT Tracker Mode Usage Instructions**](https://opencv.github.io/cvat/docs/manual/advanced/ai-tools/#trackers) first.
### 4.1 Tracker API Example
**Request**
* URL: GET /cvat_info
**Response**
* Body:
```json=
HTTP/1.1 200 OK
{
"framework":"pytorch",
"spec": None,
"type": "tracker",
"description": "Fast Online Object Tracking and Segmentation"
}
```
**Request**
* URL: POST /cvat_invoke
* Body:
```json=
{
"image":"base64_encode_image",
"state":"tracker_state",
"shape":"[303.61328125, 112.201171875, 469.88011169433594, 380.6956787109375]"
}
```
**Response**
* Body:
```json=
HTTP/1.1 200 OK
{
"state":"tracker_state",
"shape":"[303.61328125, 112.201171875, 469.88011169433594, 380.6956787109375]"
}
```
### 4.2 API Sample Code
This section provides a sample Tracker program using [**SiamMask**](https://github.com/foolwood/SiamMask) as an example to demonstrate how to implement the two APIs cvat_info and cvat_invoke using the lightweight **Python Flask** web framework.
:::spoiler **Example code: `main.py`**
```python=
# -*- coding: utf-8 -*-
import json
import base64
from PIL import Image
import io
from flask import Flask, request
from model_handler import ModelHandler
app = Flask(__name__)
model = ModelHandler()
@app.route('/cvat_info', methods=['GET'])
def cvat_info():
resp = {
"framework":"pytorch",
"spec": None,
"type": "tracker",
"description": "Fast Online Object Tracking and Segmentation"
}
return resp
@app.route('/cvat_invoke', methods=['POST'])
def cvat_invoke():
data = request.get_json()
buf = io.BytesIO(base64.b64decode(data["image"]))
shapes = data.get("shapes")
states = data.get("states")
image = Image.open(buf)
results = {
'shapes': [],
'states': []
}
for i, shape in enumerate(shapes):
shape, state = model.infer(image, shape, states[i] if i < len(states) else None)
results['shapes'].append(shape)
results['states'].append(state)
return json.dumps(results)
if __name__ == "__main__":
app.run(host="0.0.0.0", debug=True, port=9999)
```
:::
* Line 9: Model initialization.
* Line 10 ~ 18: Implement the cvat_info API, define model information and return the information in JSON format.
* Line 20 ~ 28: Implement the cvat_invoke API, which mainly receives Base64-encoded images, decodes them and inputs them into the SiamMask Model for identification, and returns the identified data in JSON format.
:::spoiler **Example code: `model_handler.py`**
```python=
# Copyright (C) 2020 Intel Corporation
#
# SPDX-License-Identifier: MIT
from tools.test import *
import os
from copy import copy
import jsonpickle
import numpy as np
class ModelHandler:
def __init__(self):
# Setup device
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch.backends.cudnn.benchmark = True
base_dir = os.path.abspath(os.environ.get("MODEL_PATH",
"/workdir/SiamMask/experiments/siammask_sharp"))
class configPath:
config = os.path.join(base_dir, "config_davis.json")
self.config = load_config(configPath)
from custom import Custom
siammask = Custom(anchors=self.config['anchors'])
self.siammask = load_pretrain(siammask, os.path.join(base_dir, "SiamMask_DAVIS.pth"))
self.siammask.eval().to(self.device)
def encode_state(self, state):
state['net.zf'] = state['net'].zf
state.pop('net', None)
state.pop('mask', None)
for k,v in state.items():
state[k] = jsonpickle.encode(v)
return state
def decode_state(self, state):
for k,v in state.items():
state[k] = jsonpickle.decode(v)
state['net'] = copy(self.siammask)
state['net'].zf = state['net.zf']
del state['net.zf']
return state
def infer(self, image, shape, state):
image = np.array(image)
if state is None: # init tracking
xtl, ytl, xbr, ybr = shape
target_pos = np.array([(xtl + xbr) / 2, (ytl + ybr) / 2])
target_sz = np.array([xbr - xtl, ybr - ytl])
siammask = copy(self.siammask) # don't modify self.siammask
state = siamese_init(image, target_pos, target_sz, siammask,
self.config['hp'], device=self.device)
state = self.encode_state(state)
else: # track
state = self.decode_state(state)
state = siamese_track(state, image, mask_enable=True,
refine_enable=True, device=self.device)
shape = state['ploygon'].flatten().tolist()
state = self.encode_state(state)
return shape, state
```
:::
* It is mainly responsible for model loading and model inference.
### 4.3 Create And Upload Container Image
In the previous section, we introduced a sample program for implementing CVAT-assisted annotation in model inference deployment, followed by packaging the program into a **Container Image** for deployment to AI Maker's inference service.
The following provides the Dockerfile for creating the Tracker API container image. Please put the corresponding sample programs (`main.py` and `model_handler.py`) and the Dockerfile in the same folder, and then use the **`docker build`** command to build the container image and upload the created container image. For details, please refer to the [**Container Image Documentation**](/s/container-image-en).
:::spoiler **Tracker Dockerfile**
```dockerfile=
From nvidia/cuda:11.0.3-cudnn8-devel-ubuntu18.04
ENV PYTHONPATH "/workdir/SiamMask:/workdir/SiamMask/experiments/siammask_sharp"
ENV PATH "/root/miniconda3/bin:${PATH}"
RUN apt update \
&& apt install -y --no-install-recommends \
wget \
git \
ca-certificates \
libglib2.0-0 \
libsm6 \
libxrender1 \
libxext6 \
&& rm -rf /var/lib/apt/lists/*
RUN wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh \
&& chmod +x Miniconda3-latest-Linux-x86_64.sh && ./Miniconda3-latest-Linux-x86_64.sh -b \
&& rm -f Miniconda3-latest-Linux-x86_64.sh
RUN mkdir -p /workdir
WORKDIR /workdir
RUN conda create -y -n siammask python=3.6
# Override Default Shell And Use Bash
SHELL ["conda", "run", "-n", "siammask", "/bin/bash", "-c"]
RUN pip install torch==1.8.0 \
jsonpickle \
flask \
Cython \
colorama \
numpy \
requests \
fire \
matplotlib \
numba \
scipy \
h5py \
pandas \
tqdm \
tensorboardX \
opencv_python==3.4.8.29 \
torchvision==0.9.0 \
&& conda install -y gcc_linux-64
RUN git clone https://github.com/foolwood/SiamMask.git
RUN cd /workdir/SiamMask && bash make.sh
RUN wget -P /workdir/SiamMask/experiments/siammask_sharp http://www.robots.ox.ac.uk/~qwang/SiamMask_DAVIS.pth
COPY main.py /workdir/
COPY model_handler.py /workdir/
ENTRYPOINT ["conda", "run","--no-capture-output", "-n", "siammask", "python", "-u","/workdir/main.py"]
:::
### 4.4 Model Preparation
You can use your own model or download the public SiamMask model from https://github.com/foolwood/SiamMask to the local side, the commands are as follows:
```shell=
wget http://www.robots.ox.ac.uk/~qwang/SiamMask_DAVIS.pth
wget https://raw.githubusercontent.com/foolwood/SiamMask/master/experiments/siammask_sharp/config_davis.json
```
Compress the model into a Zip file after downloading, then upload this ZIP file to OneAI's **Storage Service**, and then go to AI Maker's model management to import this model. Please refer to the [**AI Maker Import Model Instructions**](/s/ai-maker-en#Import-Model).
Please remember the model name and version after the model is imported, the inference service will be deployed with this model next.
### 4.5 Deploy Inference Service
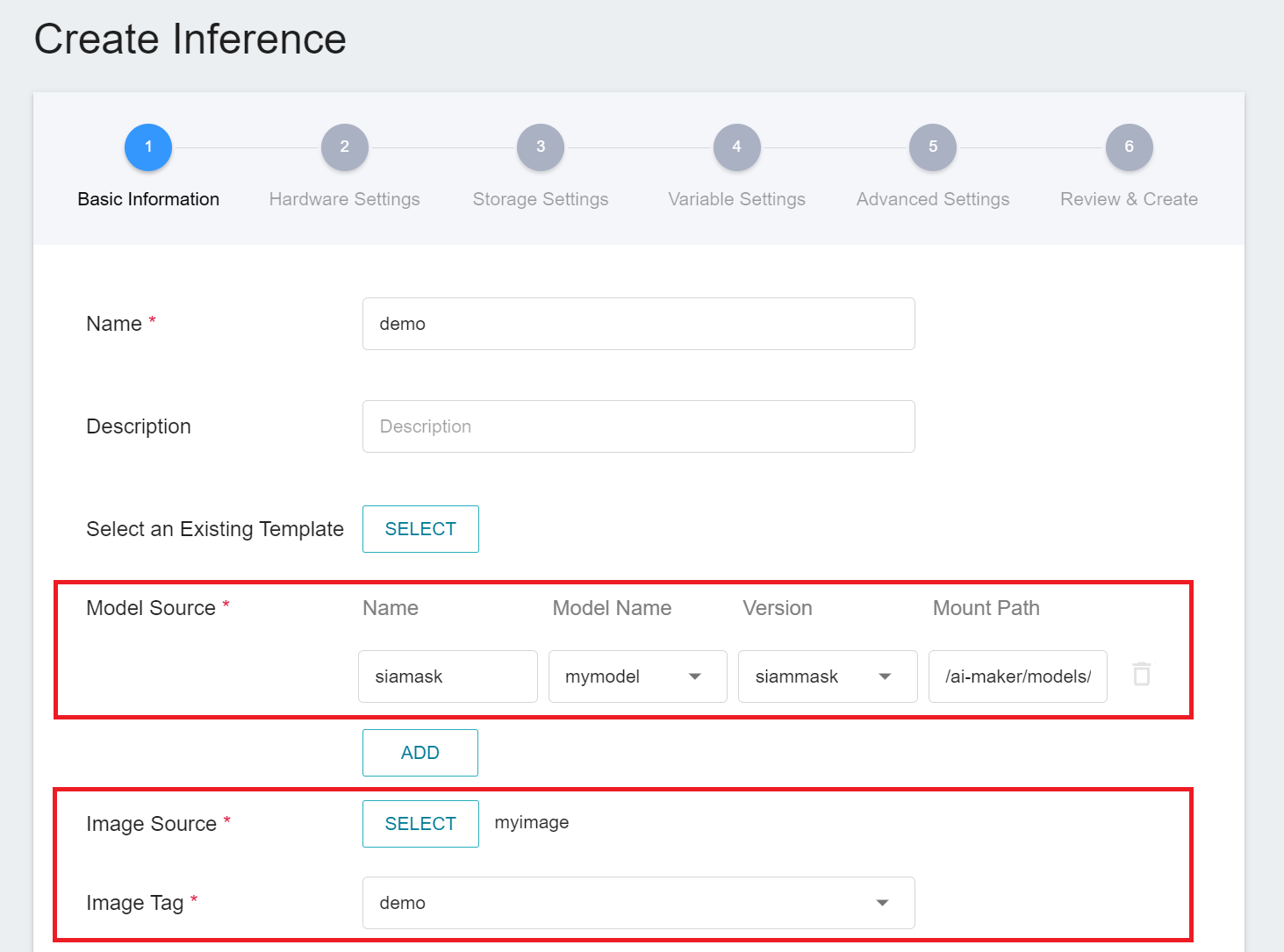
After preparing the inference image and model, you can then deploy the inference service to AI Maker. When creating an inference service, you need to select your model and this image. We only describe some important settings. For other steps, please refer to the [**Create Inference Task instructions**](/s/ai-maker-en#Create-Inference-Tasks).
Please follow the settings below to create the inference service:
1. **Basic Settings**
* **Source Model**
- Name: Please enter **`siammask`**.
- Category: Please select **Private**.
- Model Name: Please select the model name you want to load.
- Version: Please select the model version you want to load.
- Mount Path: Please enter **`/ai-maker/models/`**.
* **Image Source**: Please select the image and tag you just uploaded.
2. **Variable Settings**: Port should be set to **`9999`**.

### 4.6 Connect to CVAT
When the status of the inference service is **`Ready`**, we need to do the last step, click the **Connect to CVAT** icon above to connect to CVAT for assisted annotation.

After connecting to CVAT, enter the CVAT service to see the inference service model connected to CVAT on the **Models** page of CVAT.

Congratulations, you can start using the CVAT assisted annotation/automatic annotation function now.

After learning how to use YOLOv4 and SiamMask models to connect with CVAT's assisted/automated annotation API, you can use the [**CVAT GitHub**](https://github.com/opencv/cvat) as a reference to practice using your own deep learning models to connect with CVAT's assisted/automated annotation API.
:::warning
:warning: **Note:** The CVAT version integrated by AI Maker is [**V2.1.0**](https://github.com/opencv/cvat/tree/v2.1.0). Please refer to this version for related functions and reference documents.
:::