---
title: AI Maker 案例教學 - 行人屬性辨識
description: OneAI 文件
tags: 案例教學
---
[OneAI 文件](/s/xKNcU3O5D)
# AI Maker 案例教學 - 行人屬性辨識
[TOC]
## 0 部署行人屬性辨識應用
本範例將使用 AI Maker 針對行人屬性辨識任務所提供的範本 **`pedestrian-attribute-recognition`**,此範本事先定義了行人屬性辨識訓練及推論任務中所需使用的映像檔 **`pedestrian-attribute-recognition:v1`**、環境變數、程式等設定,方便您快速地開發自己的行人屬性辨識應用。
主要步驟包含如下:
* [前言](#1-前言)
簡介行人屬性辨識任務的流程及可應用的場景,並介紹兩組可供學術使用的行人屬性辨識資料集。
* [資料集準備](#2-準備資料集並上傳)
此階段,會著手準備要讓電腦學習的影像集,並上傳至指定位置。
* [訓練模型](#3-訓練模型)
此階段,將進行以 TensorFlow 為框架的訓練任務,並將訓練好的模型儲存。
* [推論服務](#4-推論服務)
此階段,會將儲存的模型部署到推論服務中進行推論,並示範如何在 [Jupyter Notebook](#5-進行影像辨識) 中使用 Python 語言發送推論請求。
當完成本範例後,您將學會:
1. 熟悉 AI Maker 功能並建立各階段任務。
2. 使用 AI Maker 內建的範本建置相關任務。
3. 使用儲存服務並上傳資料。
4. 透過 Jupyter Notebook 執行物件辨識。
<br>
## 1. 前言
行人屬性辨識(Pedestrian Attribute Recognition)的目的是找出目標人物的特徵,也就是所謂的屬性,例如輸入一張行人的圖片,便能輸出此人的屬性,屬性可以自行定義,如性別、年齡範圍、上半身衣服特性、下半身褲子特性與顔色、是否有戴帽子、背包、手提袋等。透過這樣的辨識,能夠瞭解到行人的屬性特徵,例如下面這個範例就呈現此位行人的屬性標記。
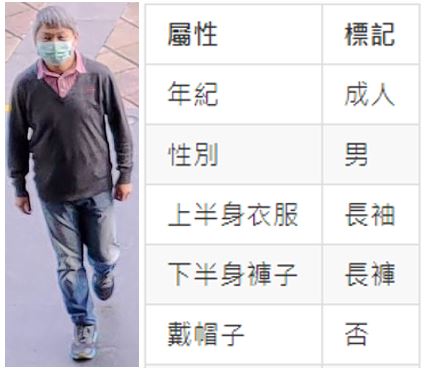
行人屬性辨識的技術可應用在智慧交通或安防上,例如在影像資料庫中,搜尋符合特徵條件的行人圖片,用來協尋失智老人、走失的小孩或警察調用路口監視器來追尋嫌疑犯或特定人士等用途。
目前有很多學術用的行人屬性資料庫,每個資料庫包含很多不同屬性,有的詳細到多達百種的屬性特徵,例如:[Market-1501 Dataset](http://zheng-lab.cecs.anu.edu.au/Project/project_reid.html)、[PETA](http://mmlab.ie.cuhk.edu.hk/projects/PETA.html) 兩組可供學術研究的行人屬性資料庫。
## 2. 準備資料集並上傳
在正式開始前,請自行準備好欲訓練的資料集,或下載 [Market-1501 Dataset](http://zheng-lab.cecs.anu.edu.au/Project/project_reid.html) 或 [PETA](http://mmlab.ie.cuhk.edu.hk/projects/PETA.html) 資料集,解壓縮後挑選所需的圖片數量並依照指定的目錄結構存放,以進行後續開發使用。
:::info
:bulb: **提示:** 訓練資料的數量會影響模型的準確率,請至少準備 100 ~ 500 張圖片,如果要達到準確率更好的結果(90% 以上),則要準備 10000 張以上的圖片。
:::
### 2.1 資料集結構與準備
本節使用以下的範例來介紹資料集結構,首先需準備三個檔案與一組資料集:**attributes.json**、**train.csv**、**valid.csv** 以及圖片資料集 **images**,檔案結構如下圖所示,在 **images** 的目錄夾内為所有需要用到的圖片檔案。
:::info
:bulb: **提示:** 請確認 **images** 目錄的拼寫無誤,因為在以下步驟中,會使用 **images** 資料夾,並讀取此資料夾中的圖片作爲訓練與驗證。
:::
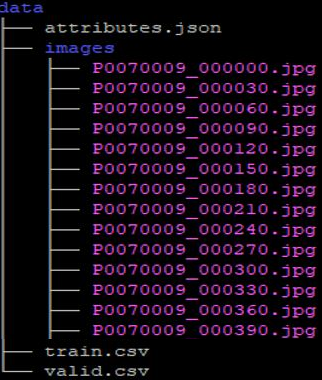
其中 train.csv 與 valid.csv 的内容是包含了訓練、驗證資料集的圖片檔名以及行人屬性標記。第一行是行人屬性的標題,這個例子分別爲 **`images`**,以及五個屬性,之後的每一行就是按照標題的規範,把圖片檔名與行人屬性填入。**1** 代表 yes,**0** 代表 no,中間用逗號隔開。
train.csv 資料內容 (示範):
```=1
images,adult,female,hat,upperShort,lowerShort
P0070009_000000.jpg,1,0,0,1,1
P0070009_000030.jpg,1,1,0,1,0
P0070009_000060.jpg,1,1,0,1,1
P0070009_000090.jpg,1,1,0,0,1
P0070009_000120.jpg,1,1,0,0,1
...
```
結合上面的資料集結構圖片與 **train.csv** 來説明,例如:**P0070009_000000.jpg** 的屬性為:成人/男性/沒戴帽子/長袖/長褲。因此,**train.csv** 的五個特徵 **`adult,female,hat,upperShort,lowerShort`** 分別為 **```1,0,0,1,1```**。
準備好訓練資料集 **train.csv** 後,接著請依照相同的結構另外準備驗證資料集 **valid.csv**。
**attributes.json** 的内容為之後要做推論服務時所輸出的結果,分別把五個特徵的結果寫在 **attributes.json** 檔案内。由於每個特徵只有兩個結果,因此在輸出的部分,也能只有兩類。如 `adult` 的輸出特徵為 `child`或是 `adult`,以此類推其他特徵。
**attributes.json** 的内容 (示範):
```json
{
"adult": ["age",["child", "adult"]],
"female": ["gender",["male", "female"]],
"hat" : ["hat",["NO", "YES"]],
"upperShort": ["upperShort",["long", "short"]],
"lowerShort": ["lowerShort",["long", "short"]]
}
```
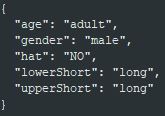
下圖為辨識圖片後所呈現結果,您可以自行依照這樣的格式來設計 **attributes.json** 的内容。
### 2.2 上傳自有資料集
#### 2.2.1 建立儲存體
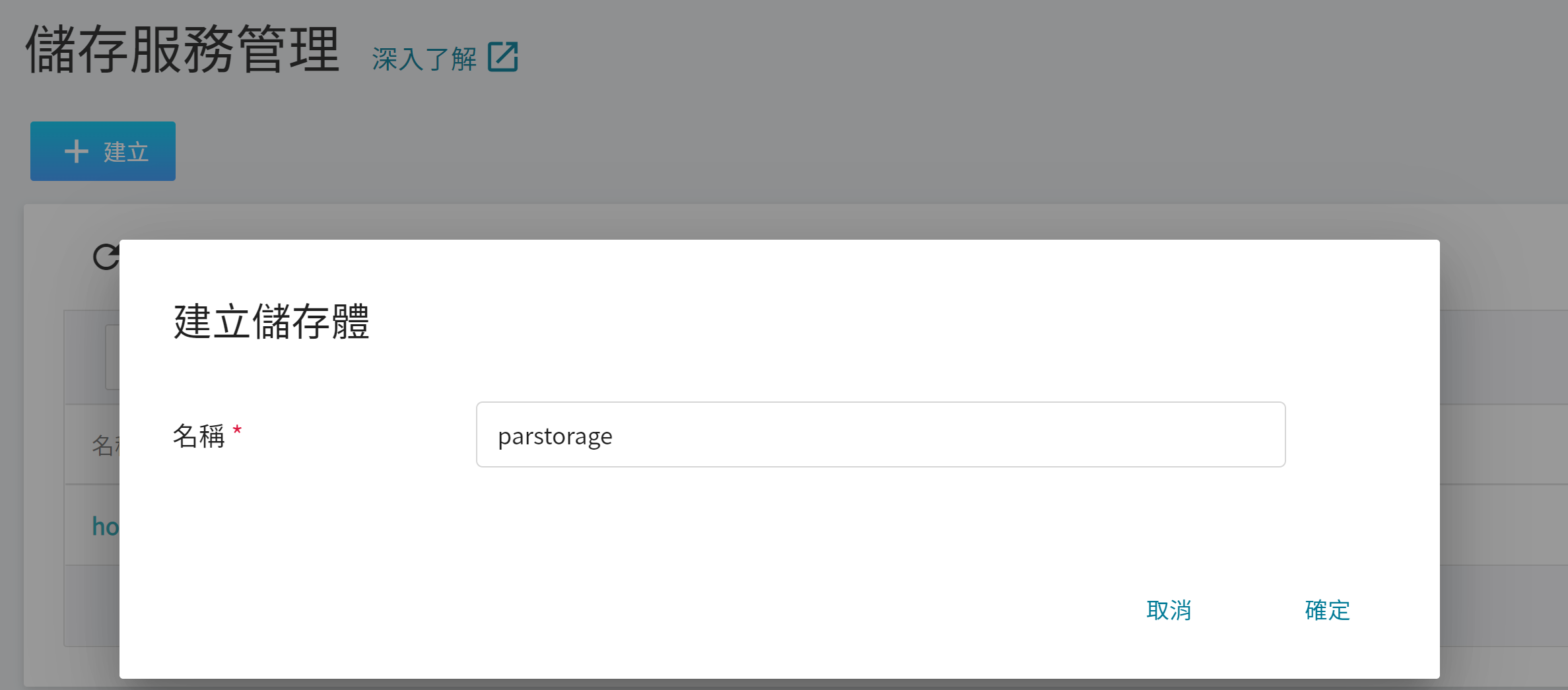
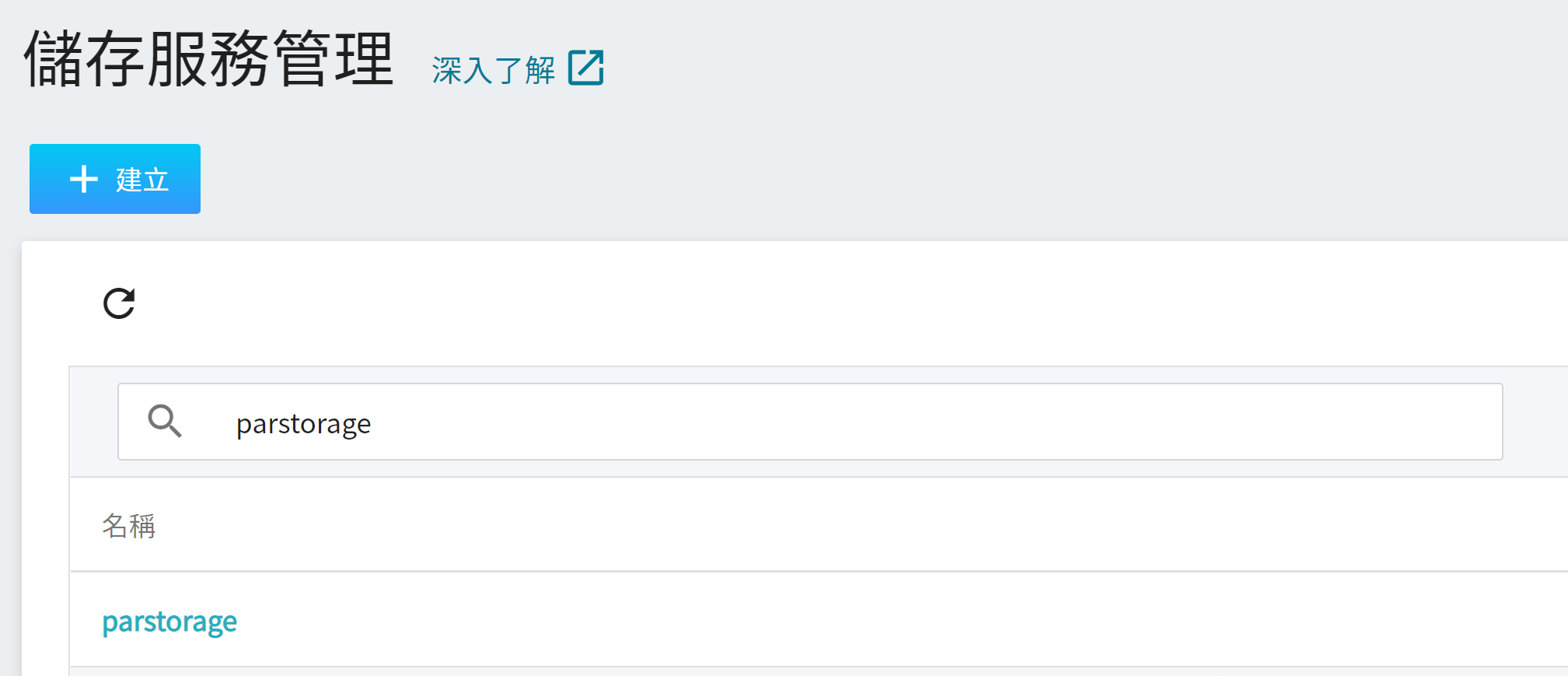
準備好 [**資料集**](#2-準備資料集並上傳) 之後,從 OneAI 服務列表選擇「**儲存服務**」,進入儲存服務管理頁面,接著點擊「**+建立**」,新增一個儲存名稱,例如:**`parstorage`** ,這個儲存體稍後會用來存放資料集。
#### 2.2.2 檢視儲存體
完成儲存體的建立後,重新回到儲存服務管理頁面,此時會看到剛剛新增的儲存體已建立完成。點擊建立好的儲存體 **`parstorage`** 即可以開始上傳資料集。
#### 2.2.3. 上傳自有資料集
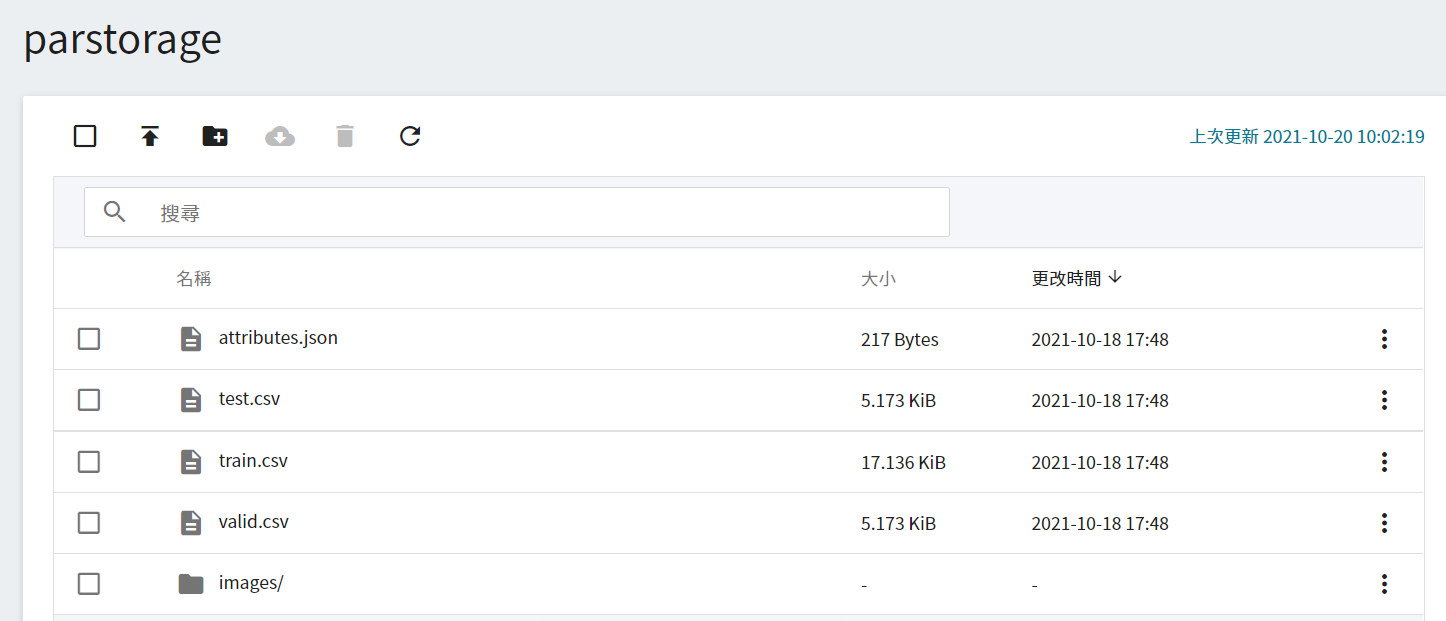
若完成上述步驟後,我們就可以著手將自有資料集存放到儲存體中。若資料量不大,可以直接點選上傳,將整理好的資料集拖曳上傳。若資料量太大,可以一個個資料夾分批上傳;或是使用第三方軟體如 [**S3 Browser**](http://s3browser.com/) 或 [**Cyberduck**](https://cyberduck.io/) 上傳,上傳完成後,頁面上所呈現的結果如下:
## 3. 訓練模型
完成 [**準備資料集並上傳**](#2-準備資料集並上傳) 後,此章節介紹如何設定訓練任務,並將所訓練好的模型儲存,以供日後測試之用。
### 3.1 建立訓練任務
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**訓練任務**」,進入訓練任務管理頁面後,點擊「**+建立**」,新增一個訓練任務。

訓練任務的建立可以細分成 5 個步驟:
1. **基本資訊**
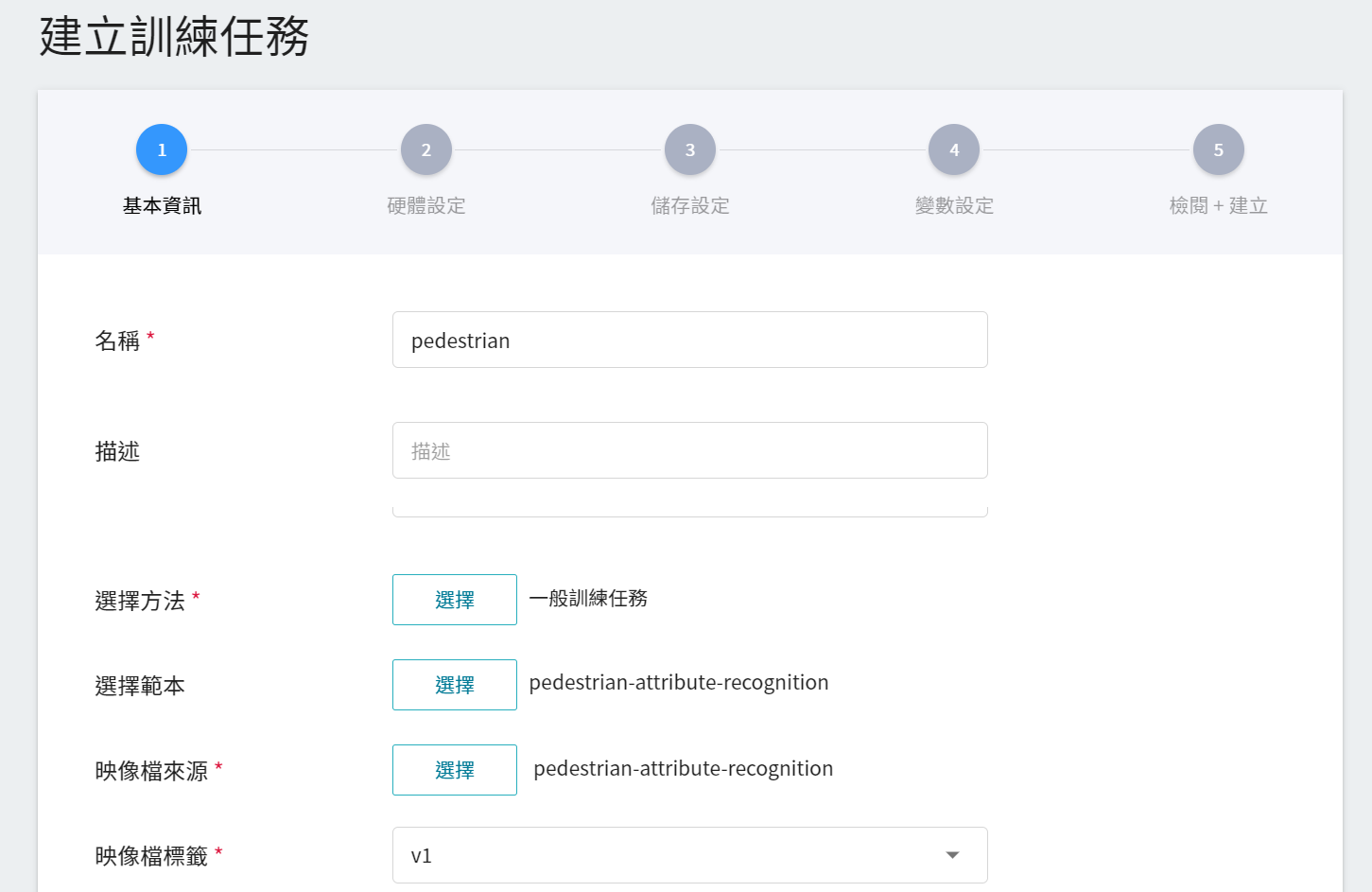
第一步是基礎資訊的設定,依序輸入名稱、描述、選擇方法,並選擇我們針對行人屬性辨識所提供的 **`pedestrian-attribute-recognition`** 範本,來帶入映像檔 **`pedestrian-attribute-recognition:v1`** 及環境變數等各項設定。實際設定畫面如下:
2. **硬體設定**
參考目前的可用配額與訓練程式的需求,從列表中選出合適的硬體資源。但需注意的是本範例的映像檔中所使用的機器學習框架為 tensorflow-gpu,因此在挑選硬體時,請選擇包含 GPU 的規格。
3. **儲存設定**
這個階段是將我們存放訓練資料的儲存體掛載到容器中。掛載路徑與環境變數的宣告在範本中已經設定完成,這邊只要選擇在基本資訊時所建立的儲存體名稱 **`parstorage`** 即可。

4. **變數設定**
接下來進行環境變數及命令的設定,各欄位的說明如下:
| 欄位名稱 | 說明 |
| -------- | -------- |
| 環境變數 | 輸入環境變數的名稱及數值。這邊的環境變數除包含訓練執行的相關設定外,也包括了訓練網路所需的參數設定。 |
| 目標參數 | 訓練結束,會回傳一值作為最終結果,這裡為該回傳值設定名稱及目標方向。例如:若回傳的數值為準確率,則可命名為 acc (accuracy 縮寫),並設定其目標方向為最大值;若回傳的值為錯誤率,則命名為 error ,其方向為最小值。 |
| 命令 | 輸入欲執行的命令或程式名稱。例如:`cd /workspace/parpackage; python train.py`。|
不過因為我們在基本資訊填寫時,已經套用 **`pedestrian-attribute-recognition`** 範本,這些指令與參數會自動帶入。
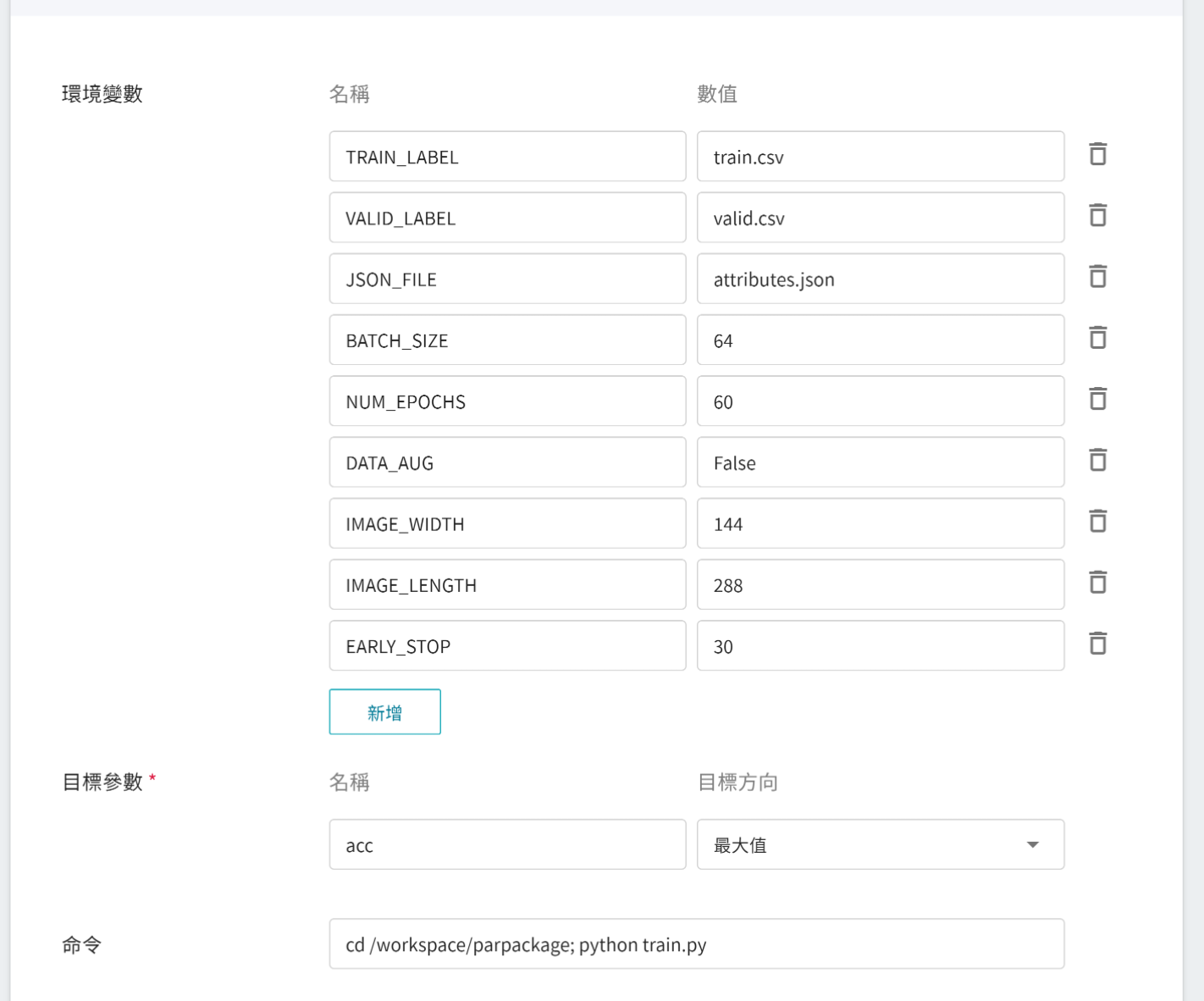
環境變數的設定值可依照您的開發需求進行調整,請參見下表說明。
| 變數 | 預設值 | 說明 |
| -------- | -------- | -------- |
|TRAIN_LABEL|train.csv|訓練資料集相對應的檔名以及標記檔案,檔案内容之圖片檔名與特徵標記以逗號隔開。|
|VALID_LABEL|valid.csv|驗證資料集相對應的檔名以及標記檔案,檔案内容之圖片檔名與特徵標記以逗號隔開。|
|JSON_FILE|attributes.json|推論結果的輸出格式檔案。|
| BATCH_SIZE | 64 | 每批資料量的大小,不建議大於資料集中圖像的總個數。 |
| NUM_EPOCHS | 100 | 指定訓練集中全部樣本訓練的次數。|
|DATA_AUG|False|資料擴增,擴增的方法包含縮放、旋轉、裁切、加噪、仿射轉換等。|
|EARLY_STOP|30|此數字表示如果連續幾次的訓練都沒有增加驗證集的正確率,且訓練次數小於 NUM_EPOCHS,就會停止訓練程序。|
|IMAGE_WIDTH|144|輸入圖片的寬度。|
|IMAGE_LENGTH|288|輸入圖片的長度。|
5. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
### 3.2 啟動訓練任務
完成訓練任務的設定後,回訓練任務管理頁面,可以看到剛剛建立的任務。點擊該任務,可檢視訓練任務的詳細設定。在命令列中,有 **儲存為範本**、**啟動**、**停止**、**編輯**、**删除** 及 **重新整理** 共 6 個圖示。

若此時任務的狀態顯示為 **`Ready`**,即可點擊 **啟動**,執行訓練任務。
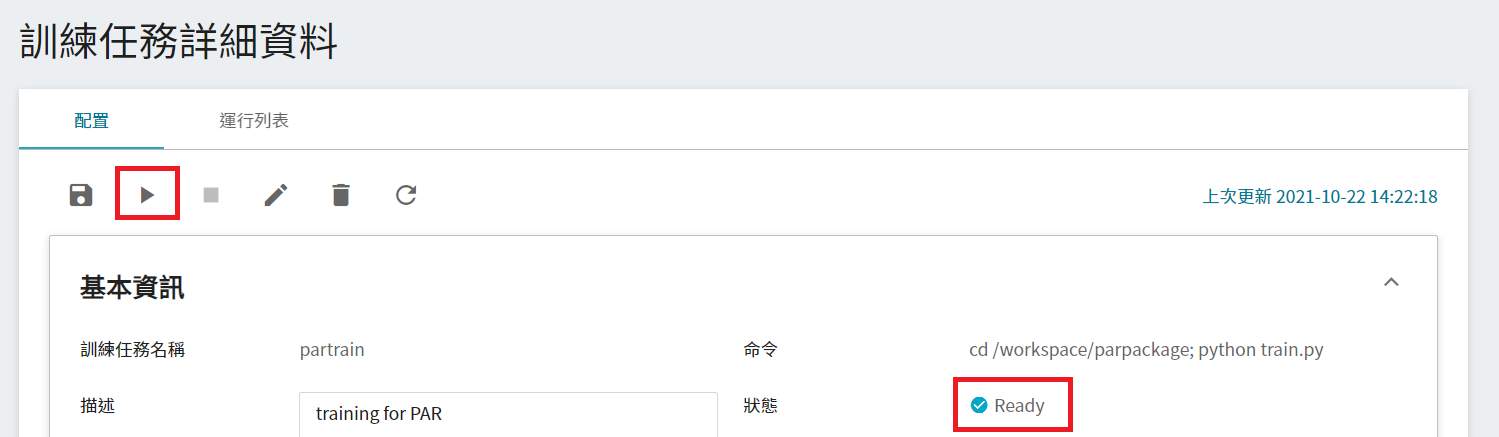
啟動後,點擊上方的「**運行列表**」頁籤,可以在列表中查看該任務的執行狀況與排程。在訓練進行中,可以點擊任務右方清單中的「**查看日誌**」或「**查看詳細狀態**」,來得知目前執行的詳細資訊。
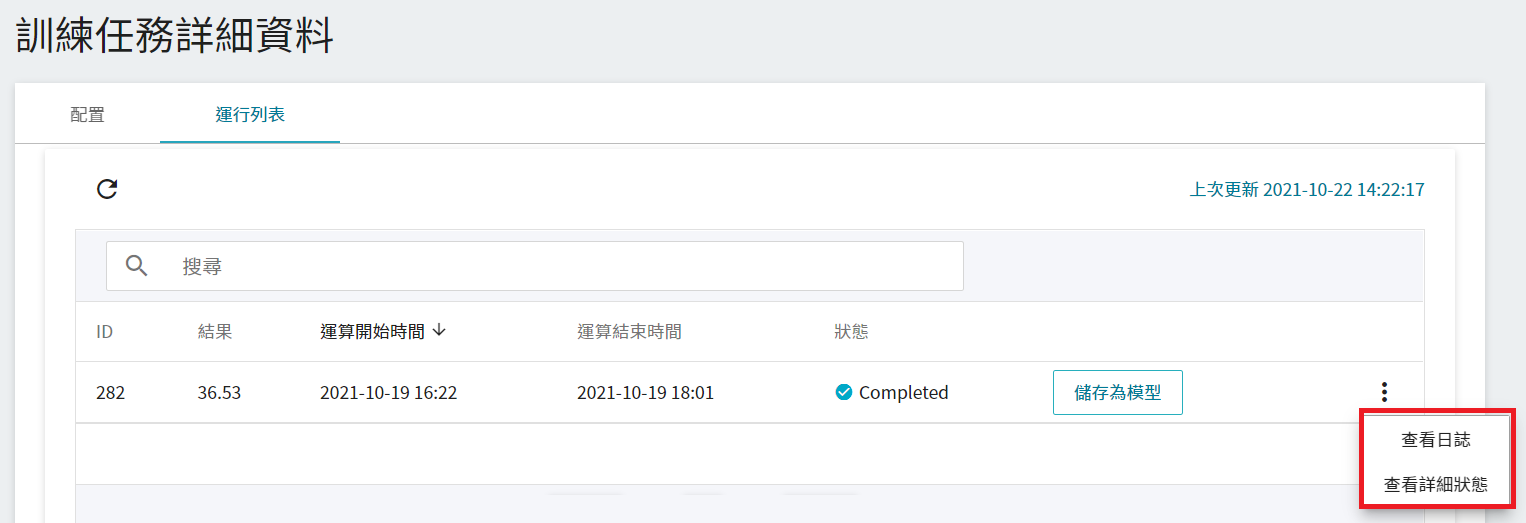
### 3.3 檢視訓練結果並儲存模型
訓練任務運算完成後,在運行列表中的該工作項目會變成 **`Completed`**,並會顯示運算結果。觀察列表中的分數,從中挑選出符合預期結果,在將其儲存至模型儲存庫中;若無符合預期結果,則重新調整環境變數與超參數的數值或數值範圍。
接下來介紹如何將達到預期的模型儲存至模型儲存庫。
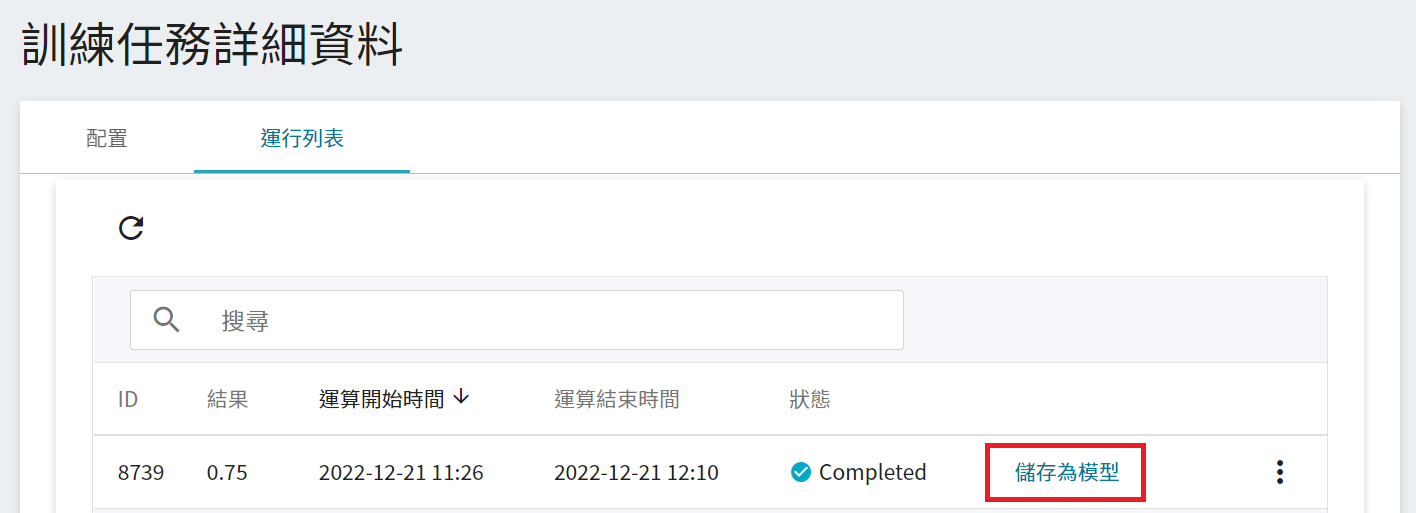
1. **點選儲存為模型**
點擊欲儲存的訓練結果右側的「**儲存為模型**」按鈕。
2. **輸入模型名稱與版號**
接著會出現一個對話框,請依照指示輸入模型名稱和版本,完成後點擊確定。

3. **查看模型**
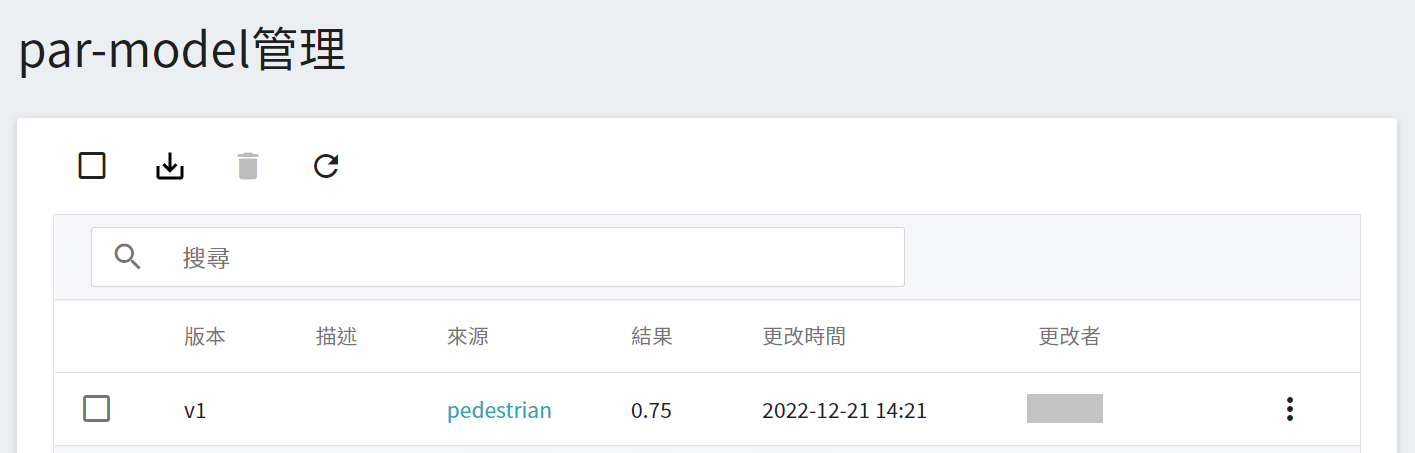
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**模型**」,進入模型管理頁面後,可在列表中找到該模型。
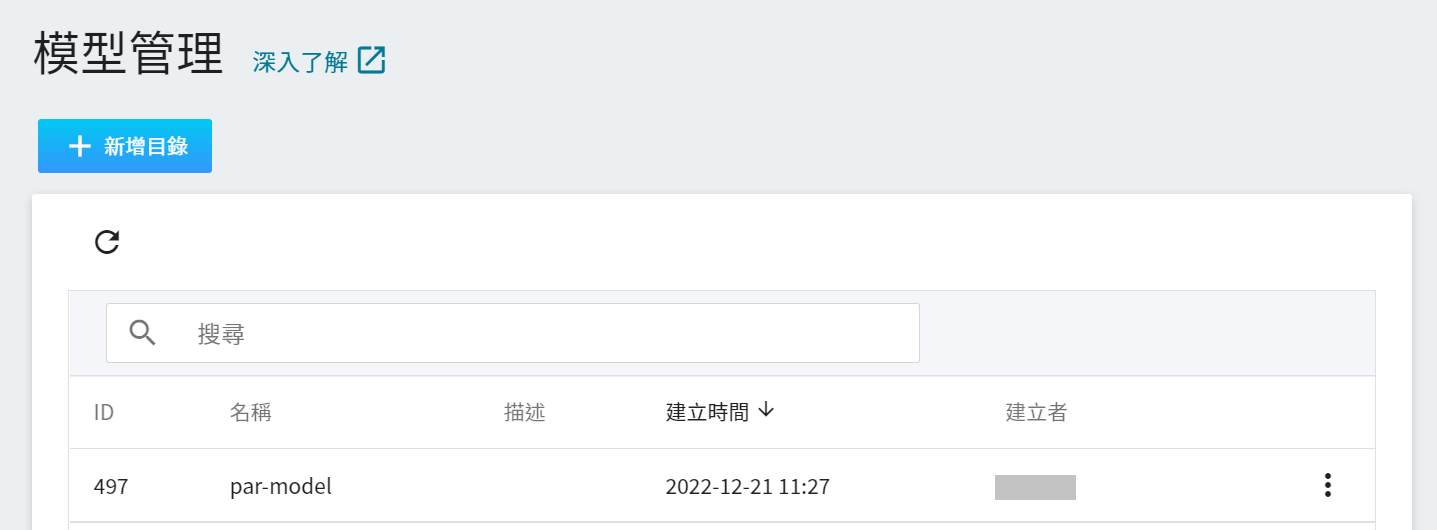
點擊該模型進入模型的版本列表,在這裡可以看到所儲存模型的所有版號,與其相對的訓練任務與結果… 等資訊。
## 4. 推論服務
當您訓練好分類模型,並將適合的模型儲存下來後,接著可藉由 **推論功能** 將模型部署為 Web 服務,以供應用程式或服務執行推論。
### 4.1 建立推論
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**推論**」,進入推論管理頁面後點擊「**+建立**」,建立一個推論服務。推論服務的建立步驟說明如下:
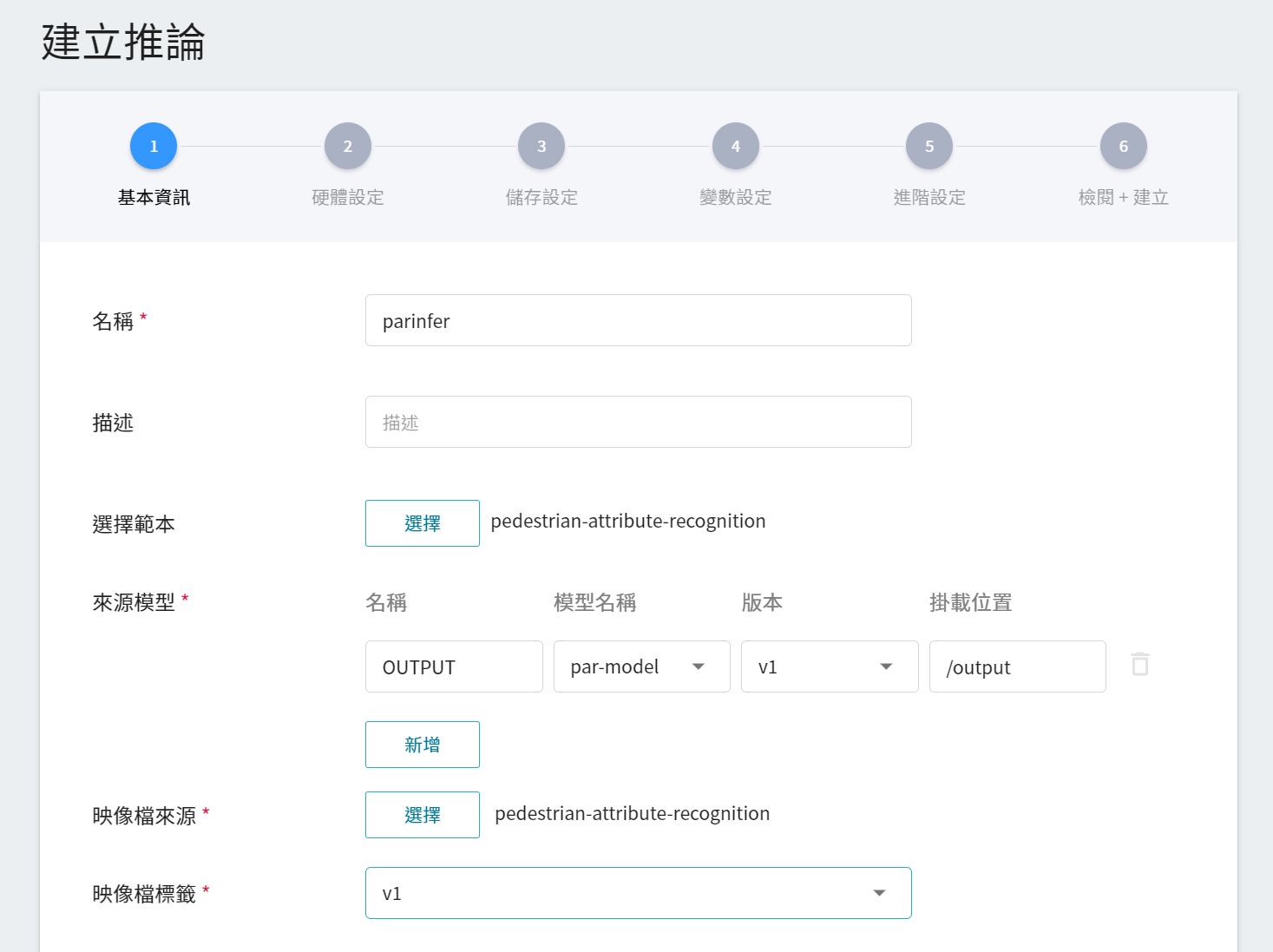
1. **基本資訊**
首先須設定此服務的各項基本資料,與訓練任務的基本資訊的設定相似,我們是使用 **`pedestrian-attribute-recognition`** 的推論範本,方便開發者快速設定。不過,所要載入的模型名稱與版號仍須手動設定:
- **名稱**
載入後模型的檔案名稱,與程式的讀取有關,這值會由 **`pedestrian-attribute-recognition`** 範本帶出。
- **模型名稱**
所要載模型的名稱,即我們在 [**3.3 檢視訓練結果並儲存模型**](#33-檢視訓練結果並儲存模型) 中所儲存的模型。
- **版本**
所要載入模型的版號,亦是 [**3.3 檢視訓練結果並儲存模型**](#33-檢視訓練結果並儲存模型) 中所設定的版號。
- **掛載位置**
載入模型所在位置,與程式的讀取有關,這值會由 **`pedestrian-attribute-recognition`** 範本帶出。
2. **硬體設定**
參考目前的可用配額與需求,從列表中選出合適的硬體資源。但因本範例的映像檔中所使用的機器學習框架為 **tensorflow-gpu**,因此在挑選硬體時,請選擇包含 **GPU** 的規格。
3. **儲存設定**
此步驟無須設定。
4. **變數設定**
在變數設定頁面,所需的指令與參數,會在套用範本時自動帶入。
5. **進階設定**
此步驟無須設定。
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
### 4.2 進行推論
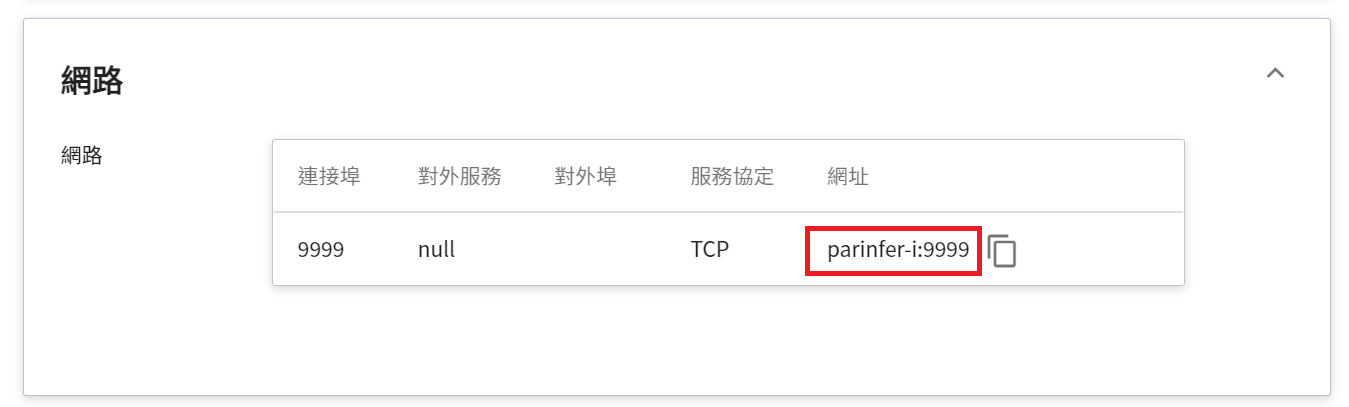
完成推論服務的設定後,回到推論管理頁面,可以看到剛剛建立的任務,點擊該列表,可檢視該服務的詳細設定。當服務的狀態顯示為 **`Ready`**,即可以開始連線到推論服務進行推論。
由於目前推論服務為了安全性考量沒有開放對外埠服務,但我們可以透過容器服務來跟已經建立好的推論服務溝通,溝通的方式就是靠「**推論詳細資料**」頁面下方 **網路** 資訊所顯示的網址。
:::info
:bulb: **提示:推論服務網址**
- 為安全性考量,目前推論服務提供的 **網址** 僅能在系統的內部網路中使用,無法透過外部的網際網路存取。
- 若要對外提供此推論服務,需要透過 [**容器服務**](/s/yGbG4JJyi) 轉接到推論服務以提供對外服務。
:::
若要查看推論監控,可點擊「**監控**」頁籤即可在監控頁面看到相關資料,下圖為經過一段時間後的推論結果。
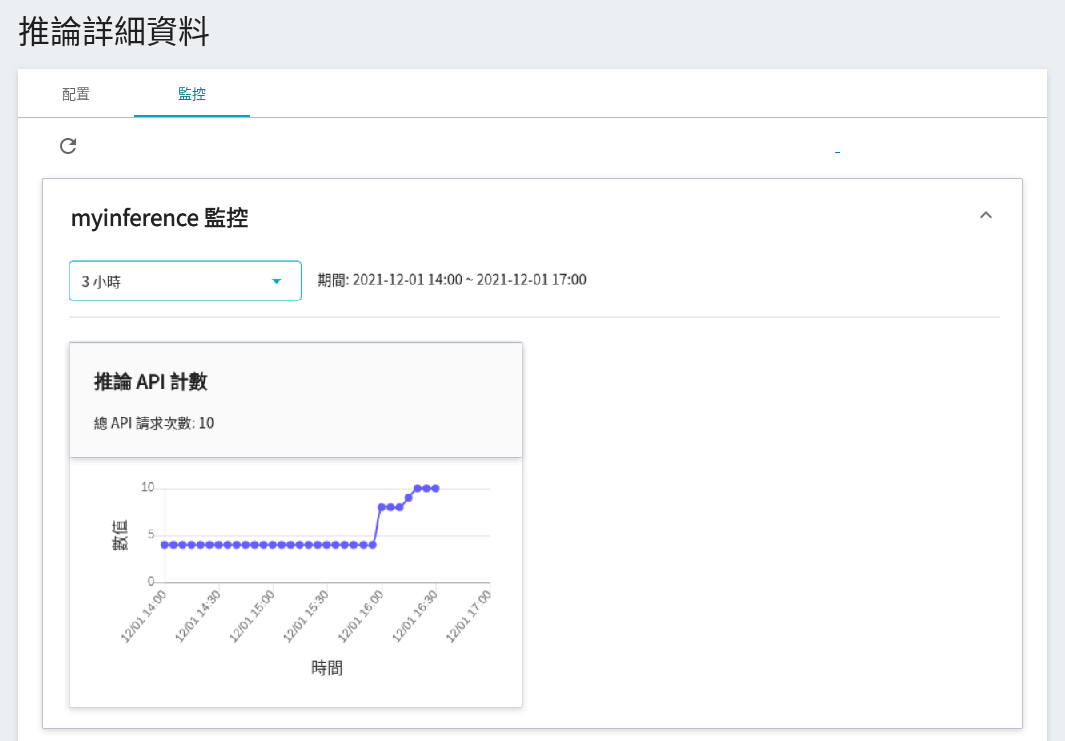
## 5. 進行影像辨識
### 5.1 啟動 Jupyter Notebook
這節主要介紹如何使用 「**容器服務**」來啟動 Jupyter Notebook 調用推論服務。
#### 5.1.1 建立容器服務
從 OneAI 服務列表選擇「**容器服務**」進入容器服務管理頁面,接著點擊「**+建立**」。
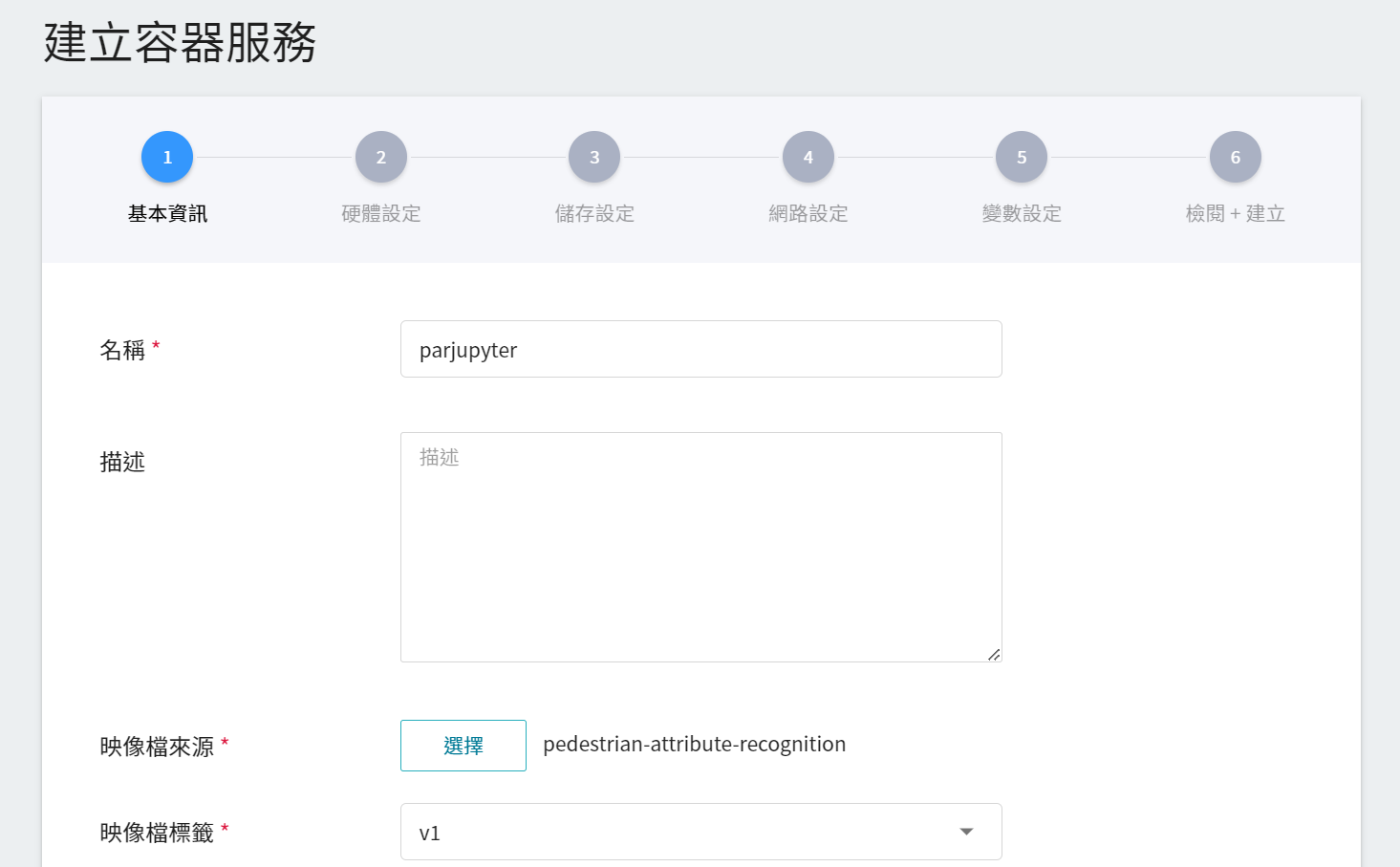
1. **基本資訊**
在建立容器服務時,可挑選 **`pedestrian-attribute-recognition`** 映像檔,在這份映像檔中我們已經提供 Jupyter Notebook 的開發環境。
2. **硬體設定**
參考目前的可用配額與訓練程式的需求,從列表中選出合適的硬體資源。但需注意的是本範例的映像檔中所使用的機器學習框架為 **tensorflow-gpu**,因此在挑選硬體時,請選擇包含 GPU 的規格。
3. **儲存設定**
此步驟可略過。
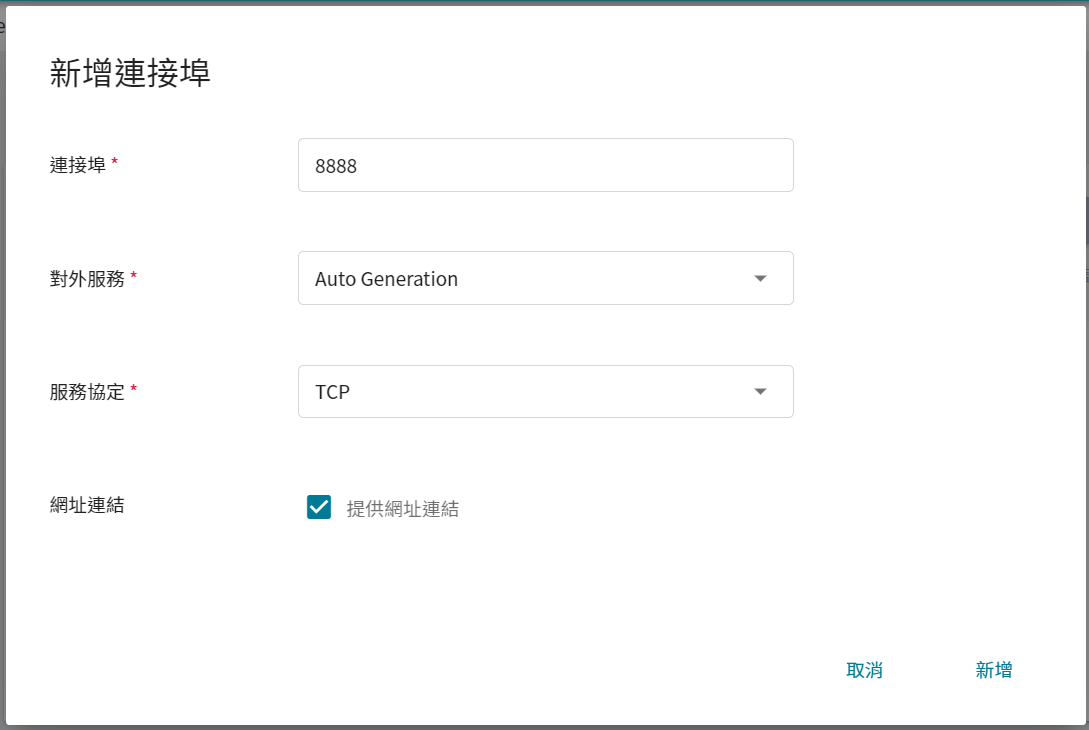
4. **網路設定**
在使用 Jupyter Notebook 服務時,預設會運行在 `8888` 的連接埠,為了能順利從外部使用 Jupyter Notebook,因此需要設定對外公開的服務埠,這邊選擇讓它自動產生對外服務的 Port,並且勾選提供網址連結。
5. **變數設定**
在使用 Jupyter Notebook 時,會跳出密碼請您輸入 token 或是 password。因此在這裡,可以使用我們在映像檔中所設定的環境變數,來設定密碼。因此請建立一個 **`PASSWORD`** 的變數名稱,在數值欄請自行輸入密碼。

6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
#### 5.1.2 使用 Jupyter Notebook
完成容器服務的建立後,回到容器服務管理列表,點擊該服務可以取得詳細資訊。

在詳細資料頁面中,需要特別注意的是 **網路** 區塊,在這區塊中有 Jupyter Notebook 服務埠 `8888` 的對外埠,點擊右側的網址連結即可在瀏覽器中開啟 Jupyter Notebook 服務。
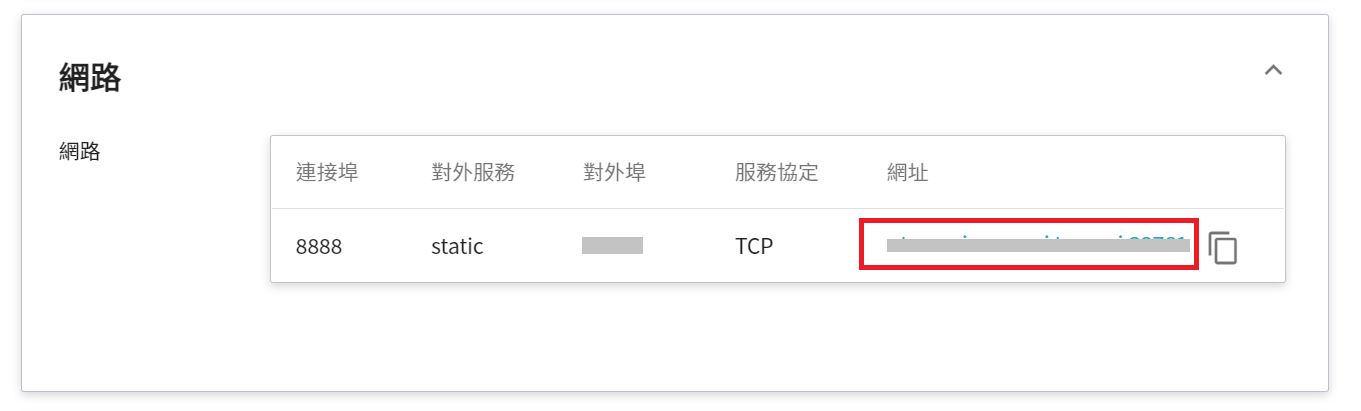
首次連線 Jupyter Notebook 時,需要輸入密碼,這個密碼就是在詳細資料頁面中設定的 PASSWORD 環境變數。
### 5.2 進行推論
啟動 Jupyter Notebook 後,可以藉由新增一份 ipynb 檔案,並複製 [附件中的程式碼](#53-附件程式碼) 來執行推論。
在這節中,我們會針對附件程式碼進行介紹:
1. **發送請求**
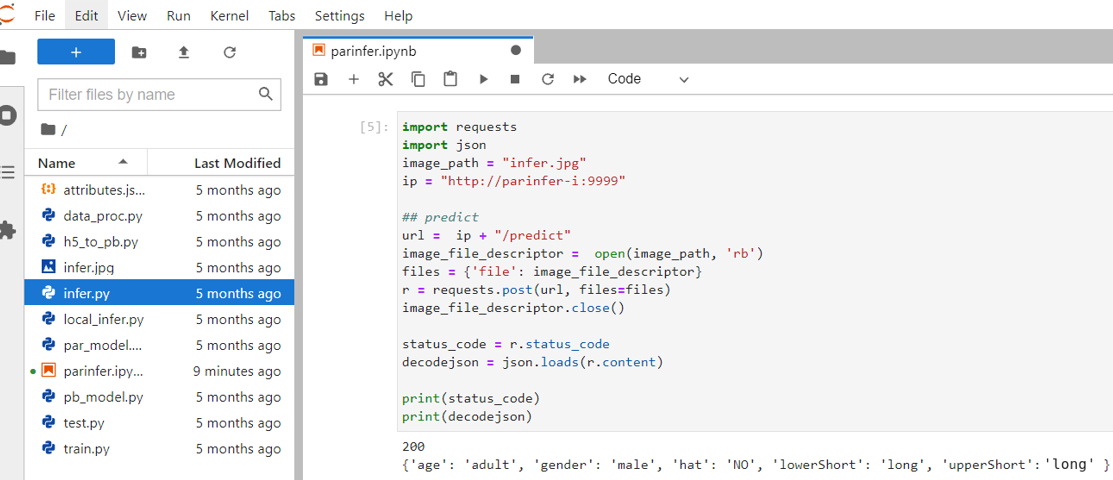
在這邊使用 requests 模組產生 HTTP 的 POST 請求,並將 [圖片](/uploads/bEEsVm7.jpg) 與參數作為一個字典結構遞給 Json 參數。
:::info
:bulb: **提示:圖片格式**
此推論服務範例能夠接受的圖片格式為 png、jpg 和 jpeg 三種。
:::
2. **取回結果**
當服務完成物件偵測後,回傳 **`decodejson`**,如上圖所示,此 json 檔包含每個物件偵測的結果。
- **age**:行人的年紀:小孩或成人。
- **gender**:行人的性別:女生或男生。
- **hat**:行人是否有戴帽子:有或無。
- **lowerShort**:行人下半身衣著樣式:長或短。
- **upperShort**:行人上半身衣著樣式:長或短。
### 5.3 附件程式碼
:::spoiler **程式碼**
```console
import requests
import json
image_path = "infer.jpg"
ip = "http://parinfer-i:9999"
## predict
url = ip + "/predict"
image_file_descriptor = open(image_path, 'rb')
files = {'file': image_file_descriptor}
r = requests.post(url, files=files)
image_file_descriptor.close()
status_code = r.status_code
decodejson = json.loads(r.content)
print(status_code)
print(decodejson)
```
:::
<style>
mark {
background-color: pink;
color: black;
}
</style>