---
title: AI Maker 案例教學 - 表格式資料機器學習:分類應用
description: OneAI 文件
tags: 案例教學
---
[OneAI 文件](/s/xKNcU3O5D)
# AI Maker 案例教學 - 表格式資料機器學習:分類應用
[TOC]
## 0. 前言
在監督式學習中,當預測的目標值為非連續數值 (亦即離散),稱其為「**分類 (Classification)**」;若目標值為連續數值,則稱為「**迴歸 (Regression)**」。
| 分類 (Classification) | 迴歸 (Regression) |
| :------------------: | :--------------: |
| 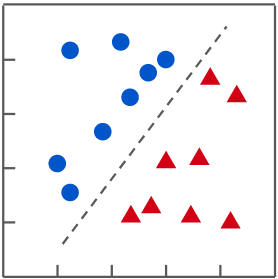 | 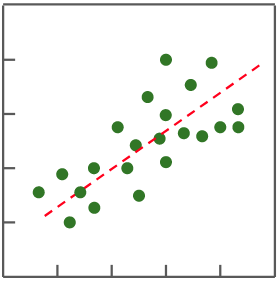 |
| 在分類問題中,找到一條能將不同類別資料分開的函數 | 在迴歸問題中,找到一條符合資料分佈的函數 |
在這份範例中,我們將使用「表格式資料」進行分類講解,從無到有逐步建立表格式資料機器學習的應用,其步驟如下:
1. [**準備資料集**](#1-準備資料集並上傳)
在此階段,我們會從 Kaggle 下載資料集,並上傳到指定位置,其中 Kaggle 是目前最大的資料科學競賽平台。
2. [**訓練模型**](#2-訓練分類任務模型)
在此階段,我們將配置相關訓練任務,以進行指定演算法的訓練與擬合,並將訓練好的模型儲存,以供推論服務使用。
3. [**建立推論服務**](#3-建立推論服務)
在此階段,我們將儲存下來的模型,建立該模型的 Web 服務,以執行推論。
4. [**[進階操作] 調整演算法的參數**](#4-進階操作-調整演算法的參數)
在此階段,我們將學習當機器學習結果不符合預期時,如何進一步調整演算法參數。
本教學提供一個名為 **`ml-sklearn-classification`** 的範本,您只需上傳欲訓練的資料集、配置訓練所需的環境變數,即可進行訓練與驗證。
## 1. 準備資料集並上傳
### 1.1 資料格式說明
使用 **表格式資料 (tabular data)**,表格式資料是由欄 (Column) 與列 (Row) 所組成的二維資料,並以 **.csv** 作為副檔名,如下表所示。
sample_dataset.csv
| | Column 1 | Column 2 | Column 3 | ... | Column 9 |
| ----- | -------- | -------- | -------- | --- | -------- |
| **Row 1** | A1 | B1 | C1 | | I1 |
| **Row 2** | A2 | B2 | C2 | | I2 |
| **Row 3** | A2 | B3 | C3 | | I3 |
| **...** | | | | | |
| **Row 9** | A9 | B9 | C9 | | I9 |
原始表格資料,需拆成 **特徵資料 (檔名:train_x.csv)** 與 **目標值資料 (檔名:train_y.csv)** 才能作為訓練模型的輸入。
- **特徵資料 (檔名:train_x.csv)**
為已知欄位資料,將用於預測目標值資料。
- **目標值資料 (檔名:train_y.csv,只有一欄資料)**
為真實的目標值資料,作為訓練和與預測做對照之用。
:::info
:bulb: **提示:分割資料的工具**
一般可以透過試算表軟體快速處理,例如 **Microsoft Excel**、[**Google Sheets**](https://docs.google.com/spreadsheets/)、**LibreOffice Calc** ... 等工具,藉由刪除欄位,再另存新檔,即可完成。
:::
### 1.2 準備資料
本教學使用 Kaggle 提供的公開資料集:**[企鵝資料 (penguin data)](https://www.kaggle.com/parulpandey/palmer-archipelago-antarctica-penguin-data)** 作為講解範例。為了簡化操作流程,我們選用其中簡化版的資料集 **penguins_size.csv** 進行說明。
- **欄位說明**
| 欄位名稱 | 說明 |
| ----------------- | ---- |
| species | 物種,其值有<br> - Chinstrap (南極企鵝)<br> - Adélie (阿德利企鵝)<br> - Gentoo (巴布亞企鵝) |
| culmen_length_mm | 嘴喙長度 (單位毫米) |
| culmen_depth_mm | 嘴喙深度 (單位毫米) |
| flipper_length_mm | 鰭狀肢長度 (單位毫米) |
| body_mass_g | 體重 (單位克) |
| island | 所在島嶼,其值有<br> - Dream (德里姆島)<br> - Torgersen (托格森島)<br> - Biscoe (比斯科群島)<br>位於南極洲的 Palmer Archipelago (帕默群島) |
| sex | 性別 |
- **資料內容 (示範)**
| 1 | species | island | culmen_<br>length_mm | culmen_<br>depth_mm | flipper_<br>length_mm | body_<br>mass_g | sex |
|-----|-----------|-----------|------------------|-----------------|-------------------|-------------|--------|
| 2 | Adelie | Torgersen | 39.1 | 18.7 | 181 | 3750 | MALE |
| ... | | | | | | | |
| 154 | Chinstrap | Dream | 46.5 | 17.9 | 192 | 3500 | FEMALE |
| ... | | | | | | | |
| 222 | Gentoo | Biscoe | 46.1 | 13.2 | 211 | 4500 | FEMALE |
| ... | | | | | | | |
備註:最左欄的索引為行數,供示範參考,不在資料集裡面。
以分類任務為例,無論是範例資料集或是自定義的資料集,在資料集中會包含兩大類資訊:
1. **特徵 (特徵資料)**:
如嘴喙長度、嘴喙深度、鰭狀肢長度、體重、所在島嶼、性別... 資訊。
2. **分類結果 (目標值資料)**:
如企鵝資料中的物種,Chinstrap (南極企鵝)、Adélie (阿德利企鵝)、Gentoo (巴布亞企鵝)。
請依照下列步驟重新分割資料集,並將資料集轉換成訓練模型所能接收的格式:
1. **訓練集** 與 **測試集**
將 penguins_size.csv 依 80%、20% 比例 (自定義) 分割成
- 訓練集 (train.csv):用於訓練模型。
- 測試集 (test.csv):保留部份資料,用於評估模型好壞。
2. **特徵** 與 **分類結果**
再將訓練集與測試集,各自分割成「**特徵**」和「**分類結果**」兩部份。
| | 特徵 | 分類結果 |
| ------------- | ----------- | ----------- |
| train.csv | train_x.csv| train_y.csv |
| test.csv | test_x.csv | test_y.csv |
隨後準備上傳 train_x.csv、train_y.csv、test_x.csv、test_y.csv 這四個檔案。
### 1.3 建立儲存體
資料備妥後,即可前往「**儲存服務**」服務進行上傳資料集。
1. **進入「**儲存服務**」服務**
從 OneAI 服務列表選擇「**儲存服務**」,進入儲存服務管理頁面。
2. **建立儲存體**
接著點擊「**+建立**」,新增一個名為 **`penguin`** 的儲存體,此儲存體會用來存放訓練用的資料集。
3. **檢視儲存體**
完成儲存體的建立後,重新回到儲存服務管理頁面,此時會看到新增的儲存體已建立完成,點擊建立好的儲存體 **`penguin`**,準備上傳資料集。
### 1.4 上傳資料集
接著上傳企鵝資料集 train_x.csv、train_y.csv、test_x.csv、test_y.csv 四個檔案,上傳完成後結果如下:
## 2. 訓練分類任務模型
完成 [**資料集的上傳**](#1-準備資料集並上傳) 後,就可以使用這些資料來訓練與擬合我們的分類任務模型。
### 2.1 建立訓練任務
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**訓練任務**」,進入訓練任務管理頁面後,切換至「**一般訓練任務**」頁籤,接著點擊「**+建立**」,新增一個訓練任務。

建立訓練任務可分成五個步驟,詳細的建立說明請參考 [**AI Maker 使用手冊**](/s/QFn7N5R-H)。
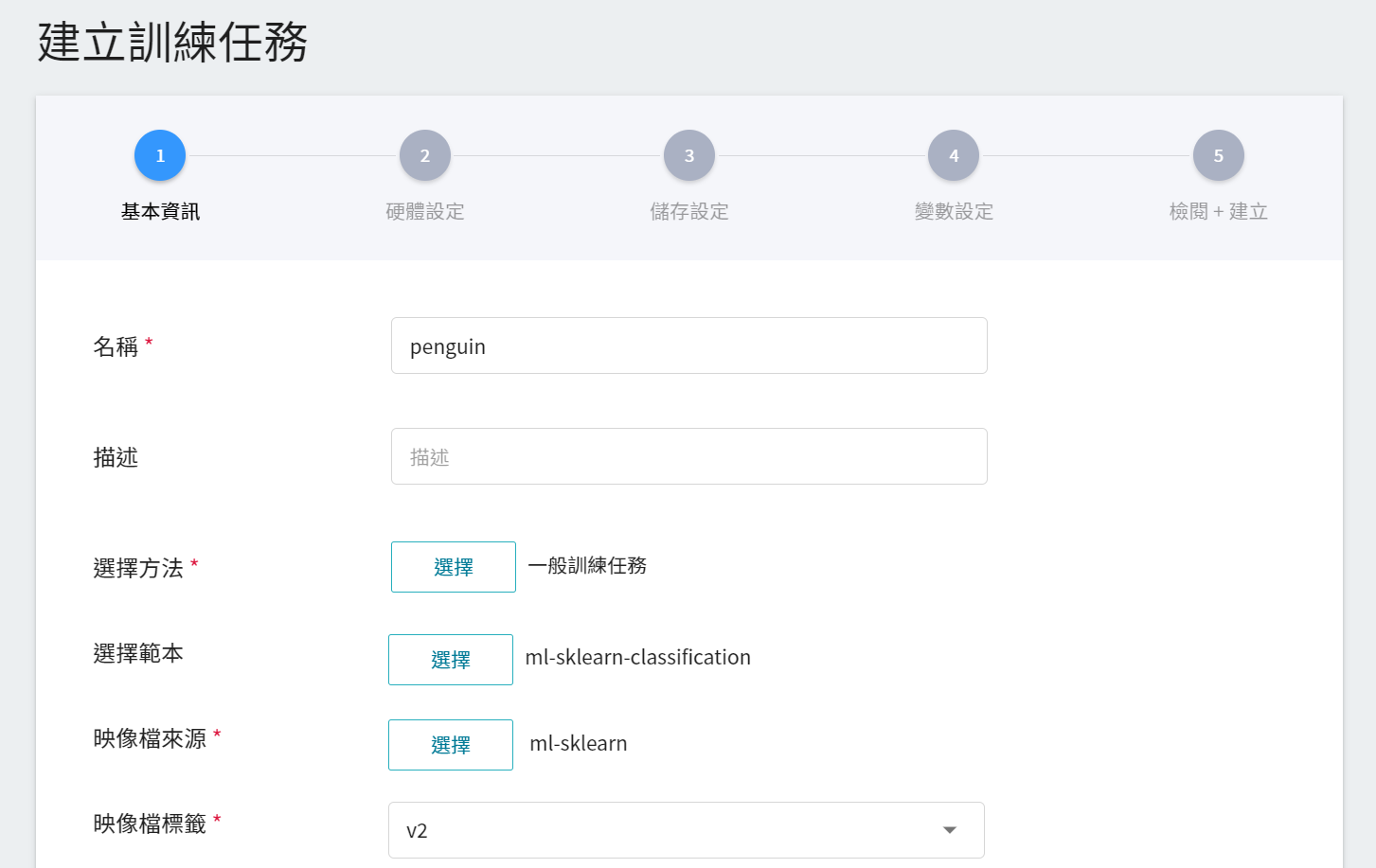
#### 2.1.1 基本資訊
第一步是基本資訊的設定,依序輸入名稱、描述、選擇方法,並選擇 **`ml-sklearn-classification`** 範本,此範本會自動帶出公用映像檔 **`ml-sklearn:v2`** 以及後續步驟的各項參數設定。
:::info
:bulb: **提示:範本功能**
AI Maker 提供的範本功能,定義了各階段任務所使用的預設參數與設定。透過範本功能,可以快速套用各項任務所需使用的參數或設定,為機器學習的工作流程與訓練環境提供了便利性。
:::
#### 2.1.2 硬體設定
此範例所使用的機器學習演算法,可使用 CPU 或 GPU 運算資源,請依目前的可用配額與運算需求,從列表中挑選出合適的硬體資源。
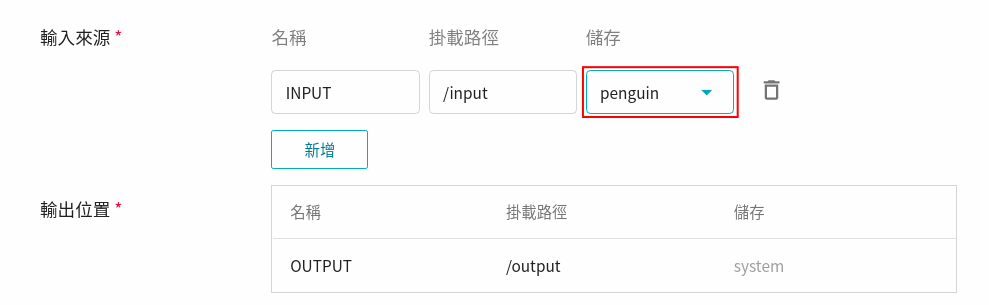
#### 2.1.3 儲存設定
此步驟需掛載之前上傳資料集的儲存體 **`penguin`**。
#### 2.1.4 變數設定
接下來進行環境變數及命令的設定,若是在填寫基本資訊,選擇套用 **`ml-sklearn-classification:v2`** 範本,下列變數及設定值會自動帶入,各參數說明如下,可依照需求自行調整。
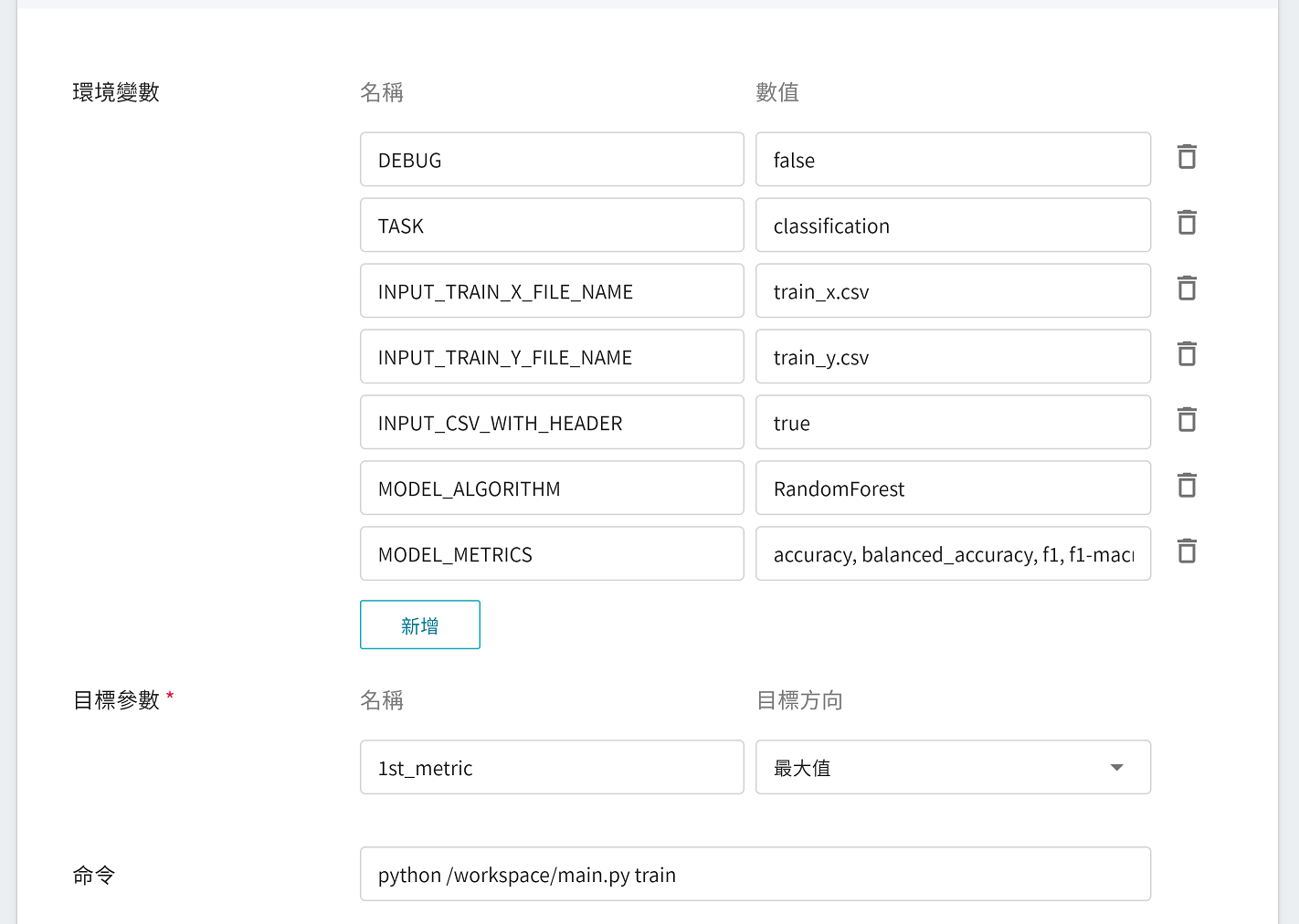
|參數|預設值|介紹|
|---|-----|---|
| [DEBUG](#DEBUG) | `false` | 是否啟用更多的日誌 (log),以便於檢視機器學習在執行中的細節。若要啟用,將值設為 `true`;反之,則將此值設為 `false`。 |
| [TASK](#TASK) <sup style="color:red"><b>*</b></sup> | `classification` | 機器學習要處理的任務類型。當機器學習要處理的問題為 **分類問題** 時,將值設為 **`classification`**;若是 **迴歸問題** ,則將此值設為 **`regression`**。<br>|
| INPUT_TRAIN_X_FILE_NAME | `train_x.csv` | 要訓練用的特徵資料之檔名。 |
| INPUT_TRAIN_Y_FILE_NAME | `train_y.csv` | 要訓練用的分類結果之檔名。 |
| <span style="white-space: nowrap">[INPUT_CSV_WITH_HEADER](#INPUT_CSV_WITH_HEADER) <sup style="color:red"><b>*</b></sup></span> | `true` | 要訓練的資料集是否有欄位名稱,若有欄位名稱,將值設為 `true`;反之,則將此值設為 `false`。 |
| [MODEL_ALGORITHM](#MODEL_ALGORITHM) <sup style="color:red"><b>*</b></sup> | `RandomForest` | 機器學習所使用的演算法。 |
| [MODEL_METRICS](#MODEL_METRICS) | `accuracy`, `balanced_accuracy`, `f1-macro`, `f1-micro` | 用於評估分類模型的多項指標,列舉時請使用 `,`(逗號) 隔開,目前僅限於日誌輸出。 |
<sup style="color:red"><b>\*</b></sup> 一般情況下,使用機器學習需注意的參數有 **TASK**、**INPUT_CSV_WITH_HEADER** 及 **MODEL_ALGORITHM**,更多的參數細節,詳述如下:
- #### DEBUG
是否啟用更多的日誌 (log),以便於檢視機器學習在執行中的細節,包括:檔案的輸出入資訊、資料表格的欄位資訊與頭尾資料、資料表格使用記憶體多寡的資訊、特徵處理過程、模型的多個評價指標。
| 值 | 說明 |
| -- | -------- |
| `true`<br>`1` | 啟用更多日誌 (建議使用) |
| 其餘的值 | 關閉日誌 |
- #### TASK
機器學習要處理的任務類型。
| 值 | 說明 |
| -- | -------- |
| `classification` | 機器學習將使用 **分類** 的演算法,參見 [**`MODEL_ALGORITHM`**](#MODEL_ALGORITHM) 說明 |
| `regression` | 機器學習將使用 **迴歸** 的演算法,參見 [**`MODEL_ALGORITHM`**](#MODEL_ALGORITHM) 說明 |
- #### INPUT_CSV_WITH_HEADER
要訓練的資料集是否有欄位名稱。
| 值 | 說明 |
| -- | -------- |
| `true`<br>`1` | 表示 csv 檔裡,首列(第一列)為欄位名稱 |
| 其餘的值 | 表示 csv 檔裡,首列沒有欄位名稱,直接就是數據 |
- #### MODEL_ALGORITHM
機器學習使用的演算法。
| 值 | 支援分類 | 支援迴歸 | 補充說明<br>詳細說明見表格下方說明 |
| --------------------- |:--------:|:--------:| -------- |
| `Auto` | ✔ | ✔ | 自動化機器學習 (Auto-ML),能自動 **挑選演算法** 與 **調校超參數** |
| `AutoGluon` | ✔ | ✔ | 一種 AutoML 工具,可支援 CPU & GPU |
| `AutoSklearn` | ✔ | ✔ | 一種 AutoML 工具,不支援 GPU,但仍可以在 GPU 環境下執行 |
| `AdaBoost` | ✔ | ✔ | 自適應增強 |
| `ExtraTree` | ✔ | ✔ | 極限隨機樹 |
| `DecisionTree` | ✔ | ✔ | 決策樹 |
| <span style="white-space: nowrap">`GradientBoosting`</span> | ✔ | ✔ | 梯度提升 |
| `KNeighbors` | ✔ | ✔ | k 個最近的鄰居 |
| `LightGBM` | ✔ | ✔ | 高效的梯度提升決策樹 |
| <span style="white-space: nowrap">`LinearRegression`</span> | ✘ | ✔ | 線性迴歸 |
| <span style="white-space: nowrap">`LogisticRegression`</span> | ✔ | ✘ | 羅吉斯迴歸/邏輯斯迴歸 |
| `RandomForest` | ✔ | ✔ | 隨機森林 |
| `SGD` | ✔ | ✔ | 隨機梯度下降法 |
| `SVM` | ✔ | ✔ | 支援向量機 |
| `XGBoost` | ✔ | ✔ | 極限梯度提升 |
:::spoiler **值設為 `Auto` 時的作用**
當機器學習演算法設為`Auto`時,`ml-sklearn` 映像檔所提供的程式會根據當前的硬體資源有無 GPU 來做選擇:
- 若硬體資源有含 GPU 時,會採用 [`AutoGluon`](https://auto.gluon.ai/stable/tutorials/tabular_prediction/index.html) 這一套 AutoML 工具;
- 反之,若硬體資源不含 GPU 時,也就是只有 CPU 情況下,則會採用 [`AutoSklearn`](https://automl.github.io/auto-sklearn/master/index.html) 這一套 AutoML 工具。
- 在使用上,使用者亦可以自行選擇要使用 [`AutoGluon`](https://auto.gluon.ai/stable/tutorials/tabular_prediction/index.html) 或是 [`AutoSklearn`](https://automl.github.io/auto-sklearn/master/index.html)。<br><br>
:::
:::spoiler **值設為 `AutoGluon` 時的作用**
- `ml-sklearn` 映像檔所提供的程式會直接採用 `AutoGluon` 這一套 AutoML 工具。
- `AutoGluon` 在訓練時,預設會將底下的機器學習演算法整合在一起,並產生一個更強大的模型。
| 演算法名稱 | 支援GPU | 文件 |
| -------- | ------ | ---- |
| CatBoost | ✔ | [查看](https://catboost.ai/) |
| ExtraTrees | | [查看](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.ExtraTreesClassifier.html) |
| KNeightbors | | [查看](https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html) |
| LightGBM | | [查看](https://lightgbm.readthedocs.io/en/latest/) |
| NeuralNetFast | ✔ | [查看](https://docs.fast.ai/tabular.models.html) |
| NeuralNetTorch | ✔ | - |
| RandomForest | | [查看](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html) |
| XGBoost | ✔ | [查看](https://xgboost.readthedocs.io/en/latest/) |
- `AutoGluon` 預設會啟用 GPU 模式。在 GPU 環境下,若演算法有支援 GPU,則會採用 GPU 加速;若不支援 GPU,則使用 CPU 進行運算。若使用者在沒有 GPU 環境下選擇 `AutoGluon`,則會採用 CPU 模式。
- 更多詳細的介紹可參考 [**官方文件**](https://auto.gluon.ai/stable/tutorials/tabular_prediction/index.html)。<br>
:::
:::spoiler **值設為 `AutoSklearn` 時的作用**
- `ml-sklearn` 映像檔所提供的程式會直接採用 `AutoSklearn` 這一套 AutoML 工具。
- `AutoSklearn` 不支援 GPU,但該工具亦可以在 GPU 環境下執行,只是不會使用到 GPU 資源。
- 更多詳細的介紹可參考 [**官方文件**](https://automl.github.io/auto-sklearn/master/index.html)。
:::
:::spoiler **更多其他機器學習演算法**
<span id="footnote_experimental_algorithm_class_list"></span>若使用的機器學習演算法並未出現在上述清單,使用者可從下面清單選取。底下列舉分類模型演算法所能使用的全部**值**(按字母順序排序):
- `AdaBoostClassifier`
- `AutoSklearnClassifier`
- `AutoGluonClassifier`
- `BaggingClassifier`
- `BernoulliNB`
- `CategoricalNB`
- `ComplementNB`
- `DummyClassifier`
- `ExtraTreeClassifier`
- `ExtraTreesClassifier`
- `GaussianNB`
- `GaussianProcessClassifier`
- `GradientBoostingClassifier`
- `KNeighborsClassifier`
- `LGBMClassifier`
- `LinearSVCDecisionTreeClassifier`
- `LogisticRegression`
- `MLPClassifier`
- `MultinomialNB`
- `NuSVC`
- `PassiveAggressiveClassifier`
- `RadiusNeighborsClassifier`
- `RandomForestClassifier`
- `RidgeClassifier`
- `RidgeClassifierCV`
- `SGDClassifier`
- `SVC`
- `XGBClassifier`
:::
- #### MODEL_METRICS
用於評估分類模型的多項指標,列舉時請使用 `,`(逗號) 隔開,目前僅限於日誌輸出。若沒有定義此項環境變數,預設評估指標會使用 `accuracy`。
設定範例:
- `f1`
- `accuracy`
- `accuracy, balanced_accuracy`
- `f1, f1_micro, f1_macro, f1_weighted`
<br>
| 值 | 說明 |
| -- | -------- |
| `accuracy` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#accuracy-score) |
| `balanced_accuracy` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#balanced-accuracy-score) |
| `top_k_accuracy` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#top-k-accuracy-score) |
| `average_precision` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) |
| `neg_brier_score` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#brier-score-loss) |
| `f1` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) (僅限二元分類) |
| `f1_micro` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) |
| `f1_macro` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) |
| `f1_weighted` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) |
| `f1_samples` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) |
| `neg_log_loss` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#log-loss) |
| `precision` | [使用說明](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_score.html#sklearn.metrics.precision_score) |
| `recall` | [使用說明](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.recall_score.html#sklearn.metrics.recall_score) |
| `jaccard` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#jaccard-similarity-score) |
| `roc_auc` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#roc-metrics)<br>分類結果 (目標值資料) 需為數值型態 |
| `roc_auc_ovr` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#roc-metrics) |
| `roc_auc_ovo` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#roc-metrics) |
| `roc_auc_ovr_weighted` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#roc-metrics) |
| `roc_auc_ovo_weighted` | [使用說明](https://scikit-learn.org/stable/modules/model_evaluation.html#roc-metrics) |
#### 2.1.5 檢閱 + 建立
最後,確認所設定的資訊無誤後,就可按下「**建立**」。
### 2.2 啟動訓練任務
完成訓練任務的設定後,回到訓練任務管理頁面,可以看到剛剛建立的任務,點擊該任務,可檢視訓練任務的詳細設定。若此時任務的狀態顯示為 **`Ready`** ,即可點擊 **啟動** 圖示,執行訓練任務。
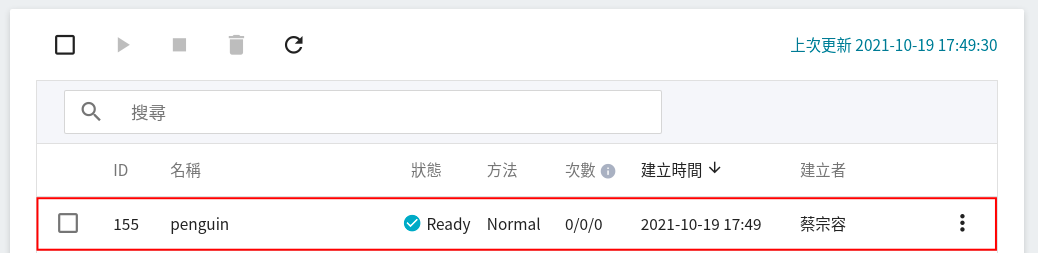
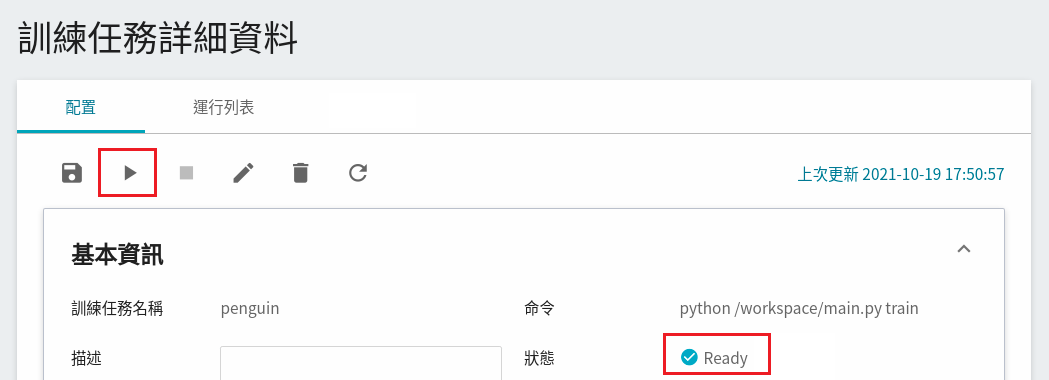
啟動後,點擊上方的「**運行列表**」頁籤,可以在列表中查看該任務的執行狀況與排程。
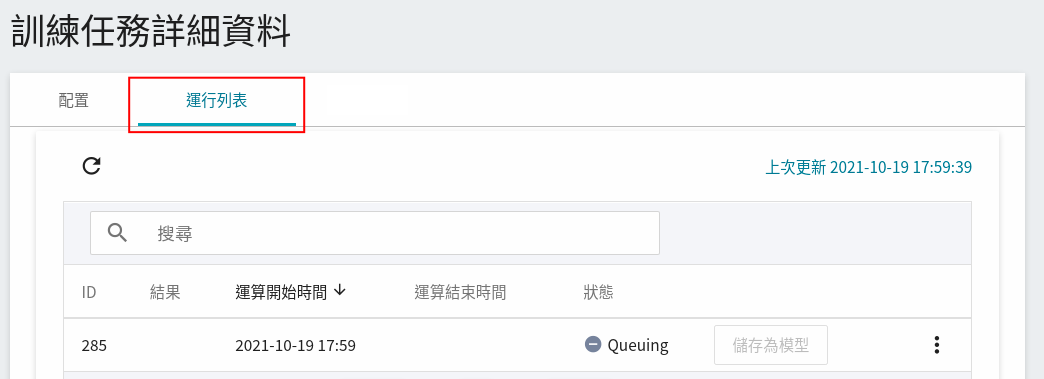
在訓練進行中,可以點擊任務右側選單中的 **查看日誌**、**查看詳細狀態**,查看目前任務執行的詳細資訊。
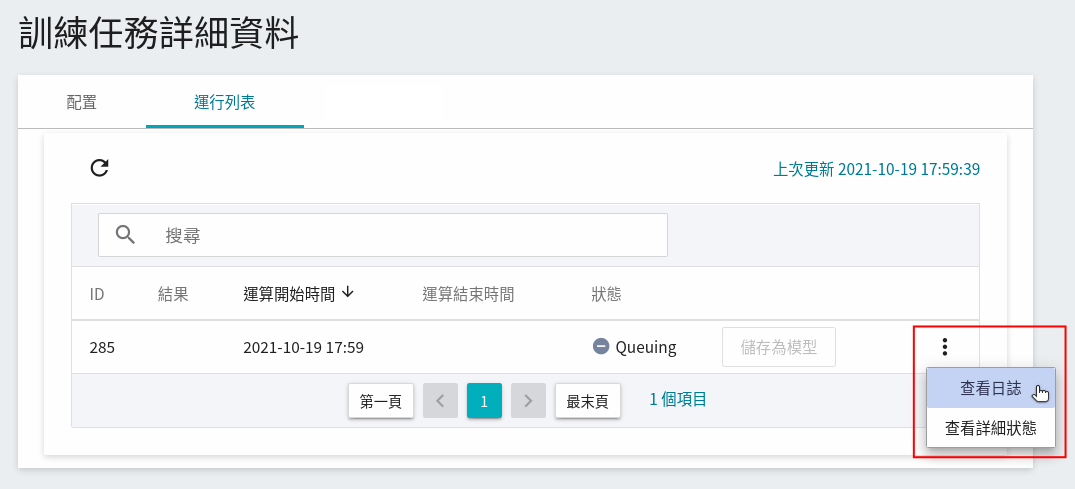
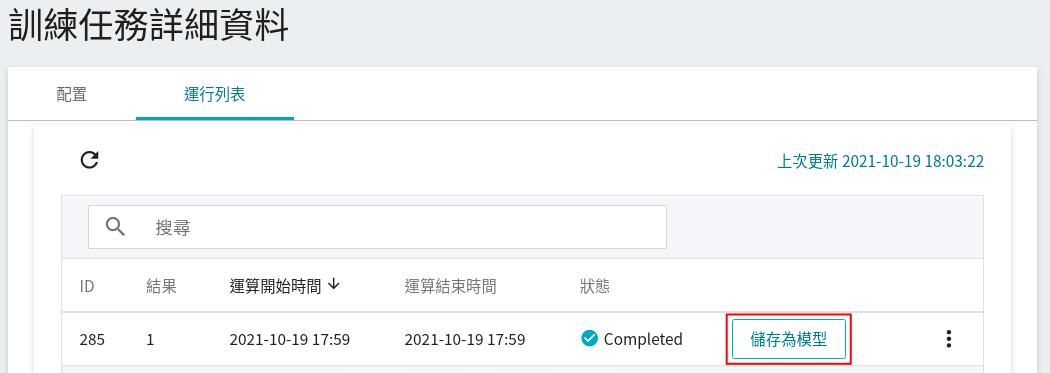
### 2.3 檢視訓練結果
#### 2.3.1 模型評估分數
當訓練完成後,會出現此任務用的機器學習演算法 **`RandomForest`** 所得到的結果。如果符合預期,可點選「**儲存為模型**」將其儲存至 **模型儲存庫** 中;若無,則重新調整環境變數與超參數的數值或數值範圍。
評估機器學習模型的好壞,可以採用下列方法:
1. 採用未看過的測試集(如:test_x.csv 和 test_y.csv)來評估模型;若是沒有測試集,則可從訓練集(train_x.csv 和 train_y.csv)再抽樣劃分出測試集。
2. 模型的評估指標,以 **環境變數** 中 [**MODEL_METRICS**](#MODEL_METRICS) 設定的指標清單中的第一項作為評估指標,參考下表:
| | MODEL_METRICS 設定範例 | 回報的評估指標 |
| ---- | ------------------- | ----------- |
| 範例1 | **f1** | f1|
| 範例2 | **accuracy** | accuracy |
| 範例3 | **accuracy**, balanced_accuracy | accuracy |
| 範例4 | **f1**, f1_micro, f1_macro, f1_weighted | f1 |
| 範例5 | 沒有指定評估指標、或未設定該環境變數 | accuracy |
#### 2.3.2 機器學習的執行日誌
點擊任務右側選單中的「**查看日誌**」。
將日誌捲動到最底部,可以取得 **環境變數** 中,[**MODEL_METRICS**](#MODEL_METRICS) 設定的所有評估指標分數。

### 2.4 嘗試變更不同的演算法,再重新訓練
如果訓練後的模型結果不符合預期,嘗試變更不同的演算法,再重新訓練。
1. 點擊「**配置**」頁籤,回到訓練任務的配置頁面,再點擊命令列上的 **編輯**,修改設定。
2. 將 **環境變數** 中 [**`MODEL_ALGORITHM`**](#MODEL_ALGORITHM) 修改為 **`XGBoost`**,儲存後再重新啟動訓練任務。
嘗試多種不同的演算法後,接著回到「**運行列表**」頁面,可看到多筆任務的執行結果。
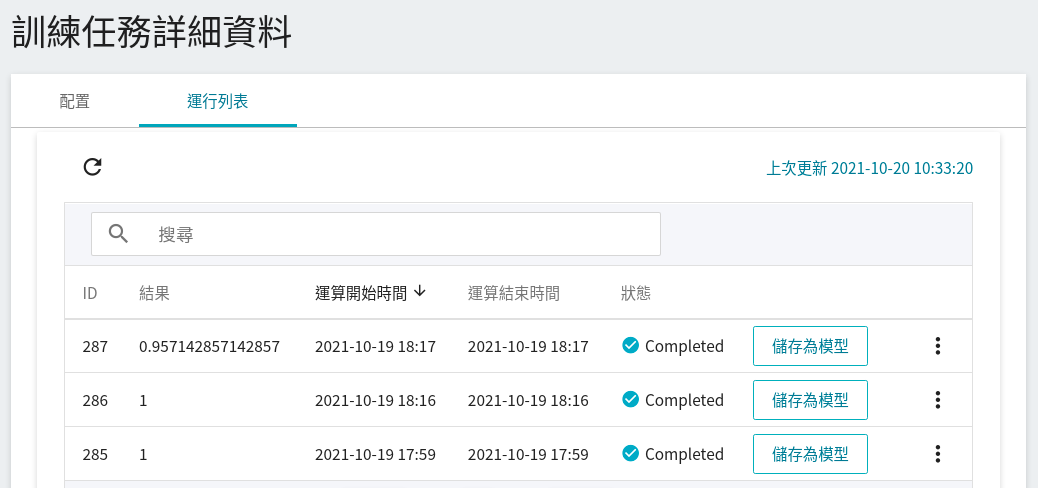
| ID | [`MODEL_ALGORITHM`](#MODEL_ALGORITHM) | 模型的 accuracy 評估分數 |
| ---- | --------------- | ----------- |
| 287 | `DecisionTree` | 0.957 |
| 286 | `XGBoost` | 1.0 |
| 285 | `RandomForest` | 1.0 |
### 2.5 儲存模型
在嘗試不同的演算法後,可以從中挑選符合預期的結果,將其模型儲存至 **模型儲存庫** 中。
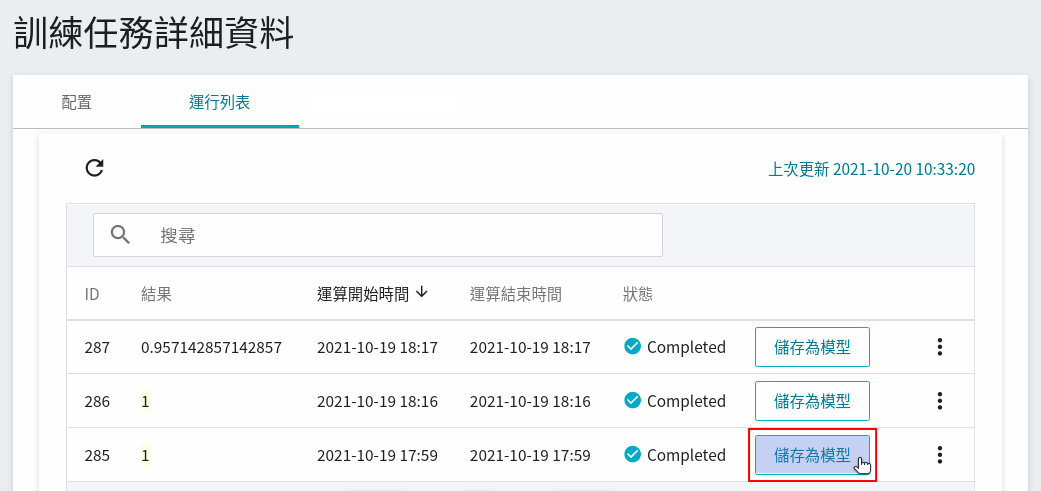

註:`rf-100` 在此用於表示模型演算法為 `RandomForest`,其 `accuracy` 為 100%。
在這個例子中,可以儲存一個或多個模型。
| ID | [`MODEL_ALGORITHM`](#MODEL_ALGORITHM) | 模型的 accuracy 評估分數 | 模型名稱 |
| ---- | --------------------- | ----------- | ------- |
| 287 | `DecisionTree` | 0.957 | (捨棄) |
| 286 | `XGBoost` | 1.0 | `penguin:xgb-100` |
| 285 | `RandomForest` | 1.0 | `penguin:rf-100` |
儲存模型後,前往「**模型管理**」頁面,點選 `penguin` 目錄即可在模型版本列表中找到該模型。
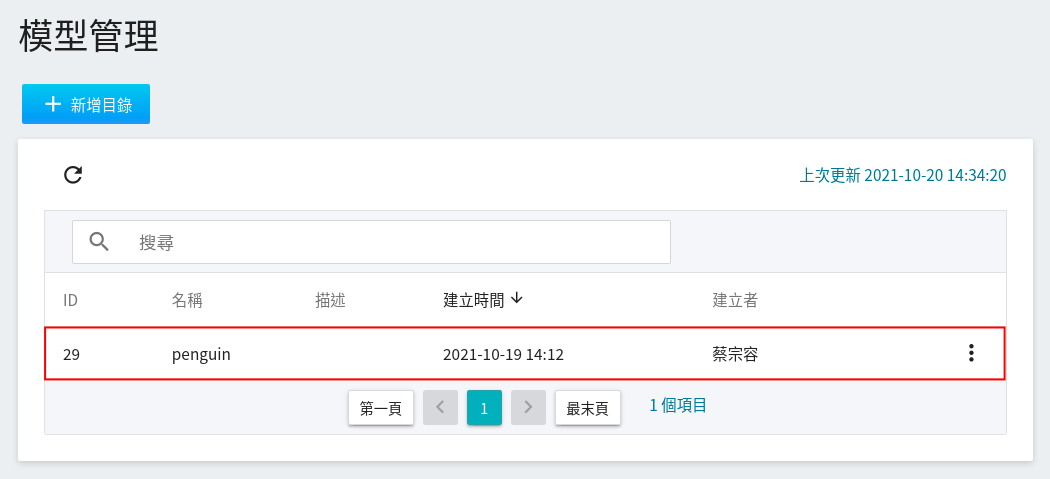
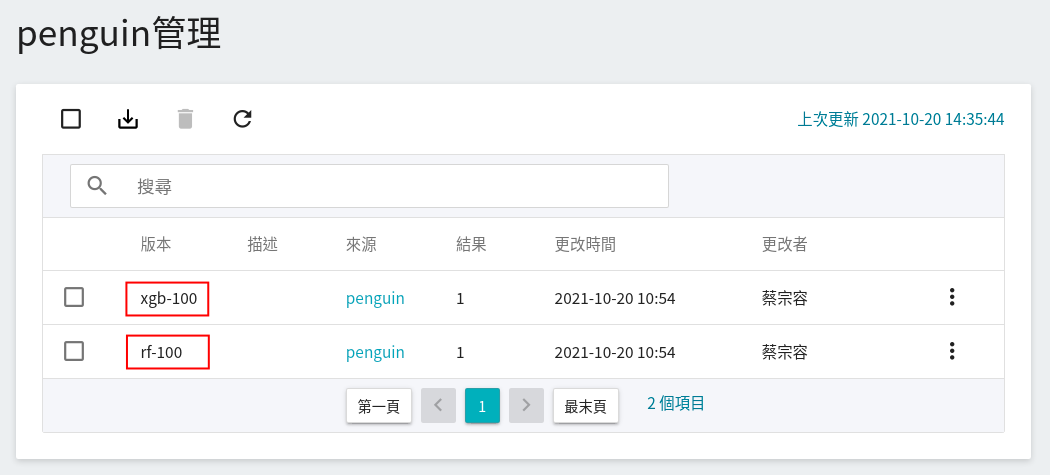
## 3. 建立推論服務
當您訓練好分類模型,並將適合的模型儲存下來後,接著可藉由 **推論功能** 將模型部署為 Web 服務,以供應用程式或服務執行推論。
### 3.1 建立推論服務
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**推論**」,進入推論管理頁面,並按下「**+建立**」,建立一個推論服務。推論服務的建立步驟說明如下:
#### 3.1.1 **基本資訊**
與訓練任務的基本資訊的設定相似,我們也是使用 **`ml-sklearn-classification`** 的推論範本,方便快速設定。範本會自動帶入 **來源模型** 的基本設定,不過,所要載入的模型名稱與版號仍須手動設定,如下圖所示。
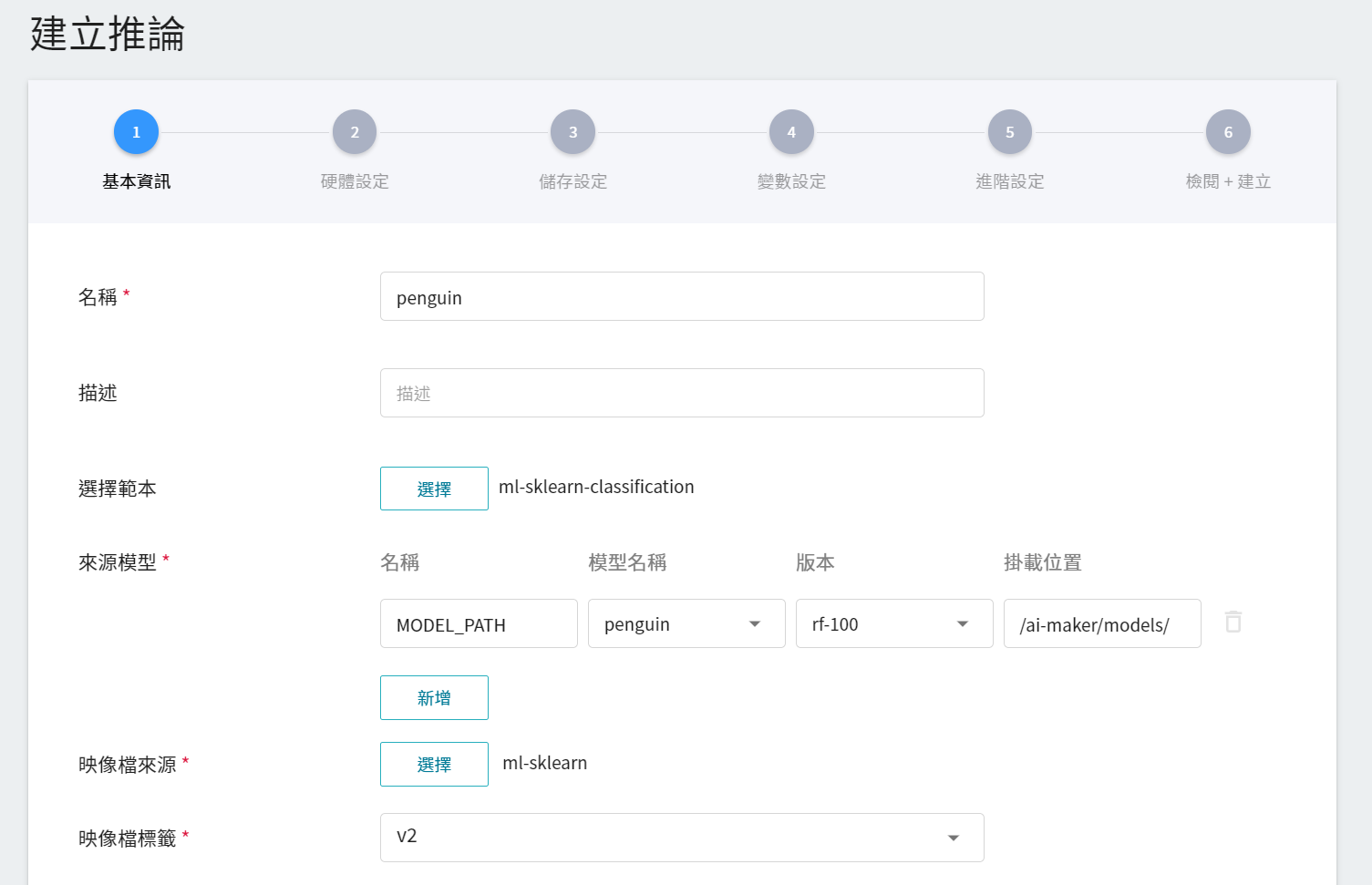
:::info
:bulb: **提示:來源模型資訊**
參考步驟 [**2.5 儲存模型**](#25-儲存模型) 所儲存下來的模型。
| ID | [`MODEL_ALGORITHM`](#MODEL_ALGORITHM) | 模型的 accuracy 評估分數 | 模型名稱 |
| ---- | --------------------- | ----------- | ------- |
| 286 | `XGBoost` | 1.0 | `penguin:xgb-100` |
| 285 | `RandomForest` | 1.0 | ==`penguin:rf-100`== |
:::
#### 3.1.2 **硬體設定**
參考目前的可用配額與需求,從列表中選出合適的硬體資源。
#### 3.1.3 **儲存設定**
此步驟無須設定。
#### 3.1.4 變數設定
在變數設定頁面,這些指令與參數,會在套用範本時自動帶入。
此推論範本在 **環境變數** 中所設定的參數說明如下:
|參數|預設值|介紹|
|---|-----|---|
| [DEBUG](#DEBUG) | `false` | 是否啟用更多的日誌 (log),以便於檢視推論服務的日誌。若要啟用,將值設為 `true`;反之,則將此值設為 `false`。 |
| <span style="white-space: nowrap">[INPUT_CSV_WITH_HEADER](#INPUT_CSV_WITH_HEADER) <sup style="color:red"><b>*</b></sup></span> | `true` | 要推論的資料集是否有欄位名稱,若有欄位名稱,將值設為 `true`;反之,則將此值設為 `false`。 |
<sup style="color:red"><b>\*</b></sup> 一般情況下,使用推論需要注意的參數為 **INPUT_CSV_WITH_HEADER**,更多的參數細節詳述如下:
- #### `DEBUG`
是否啟用更多的日誌(log),以便於檢視推論服務的日誌。
| 值 | 說明 |
| -- | -------- |
| `true`<br>`1` | 啟用更多日誌(建議使用) |
| 其餘的值 | 關閉日誌 |
- #### `INPUT_CSV_WITH_HEADER`
要推論的資料集是否有欄位名稱。此參數是用來設定推論服務的預設選項,隨後的推論測試就不需要攜帶此參數,即可簡化推論測試所需的指令或程式碼。
| 值 | 說明 |
| -- | -------- |
| `true`<br>`1` | 表示 csv 檔裡,首列(第一列)為欄位名稱 |
| 其餘的值 | 表示 csv 檔裡,首列沒有欄位名稱,直接就是數據 |
#### 3.1.5 進階設定:推論監控
推論監控可觀測一段時間內推論服務 API 的呼叫次數及推論結果的統計資訊,本範本設置了兩項監控指標 target 和 statistics,來統計推論結果的類別及數量資訊。
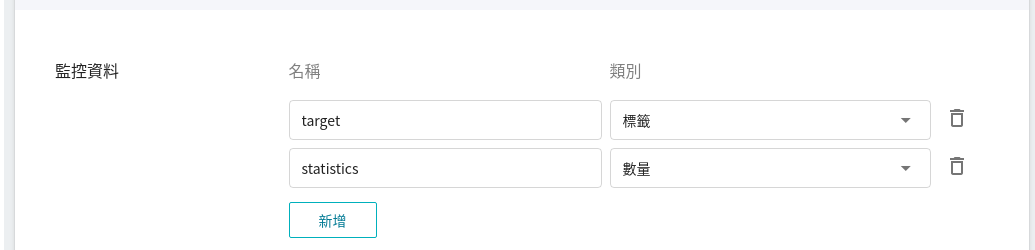
| 名稱 | 類別 | 類型 & 說明 |
|-----|-----|------------|
| target | 標籤 | **計數型**<br>在指定的時間區間內,各目標值所累計的總次數。<br>換言之,可看出各類別在一段時間內的分佈狀況。<br>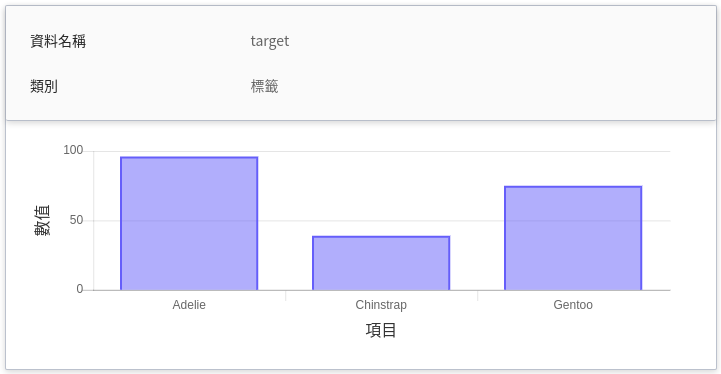|
| statistics | 數量 | **計量型**<br>在某個時間點呼叫推論 API 一次,各目標值出現的總次數。<br>換言之,可看出各類別在每次呼叫 API 時的總次數變化。<br>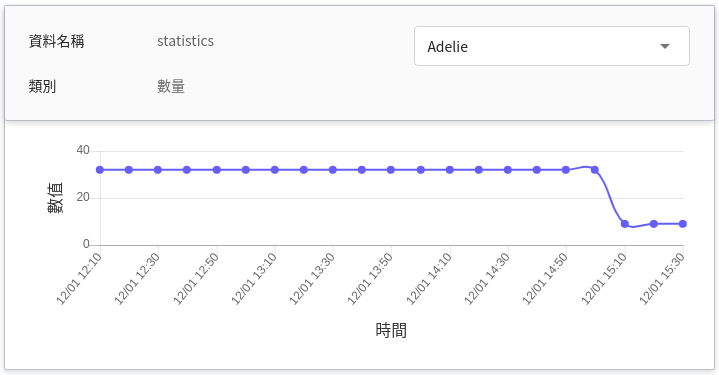<br>(未來的走勢,若無呼叫 API,則會延續過去的值) |
#### 3.1.6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
### 3.2 檢視推論服務的狀態與端點
完成推論服務的設定後,回到推論管理頁面可以看到剛剛建立的服務,點擊建立好的推論服務,可查看基本資訊。當服務的狀態顯示為 **`Ready`**,即可以開始連線到推論服務進行推論。
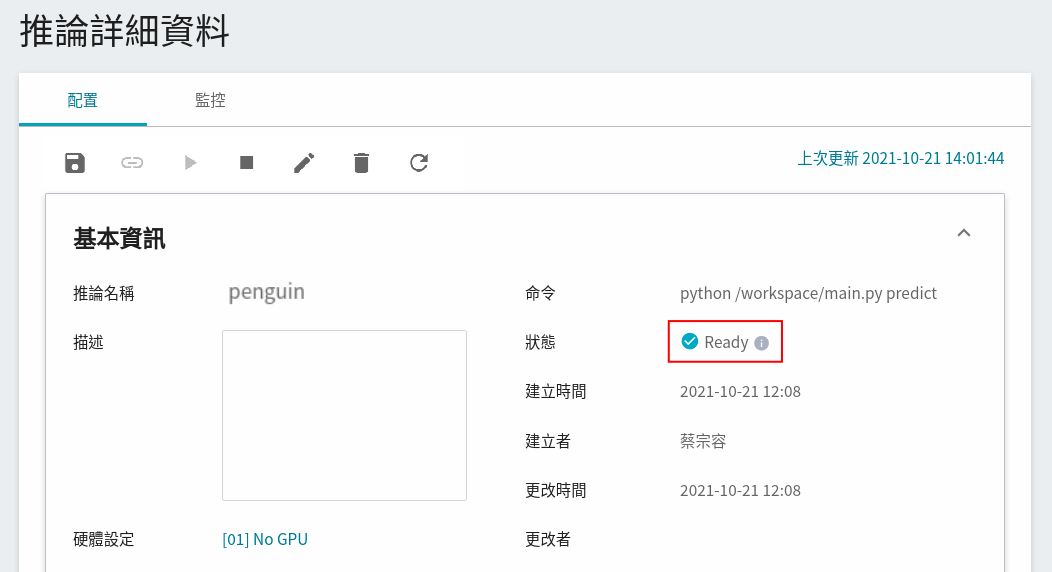
也可點擊「**查看日誌**」,若在日誌中有看到以下訊息,表示推論服務已經在運作中。

此處須注意的是日誌中所顯示的網址 http://{ip}:{port} 只是容器的內部網址,並無法從外部存取。由於目前推論服務為了安全性考量沒有開放對外埠服務,但我們可以透過容器服務來跟已經建立好的推論服務溝通,溝通的方式就是靠「**推論詳細資料**」頁面下方 **網路** 區塊所顯示的網址。
:::warning
:warning: **請注意:** 文件中的網址僅供參考,您所取得的網址名稱可能會與文件中的不同。
:::
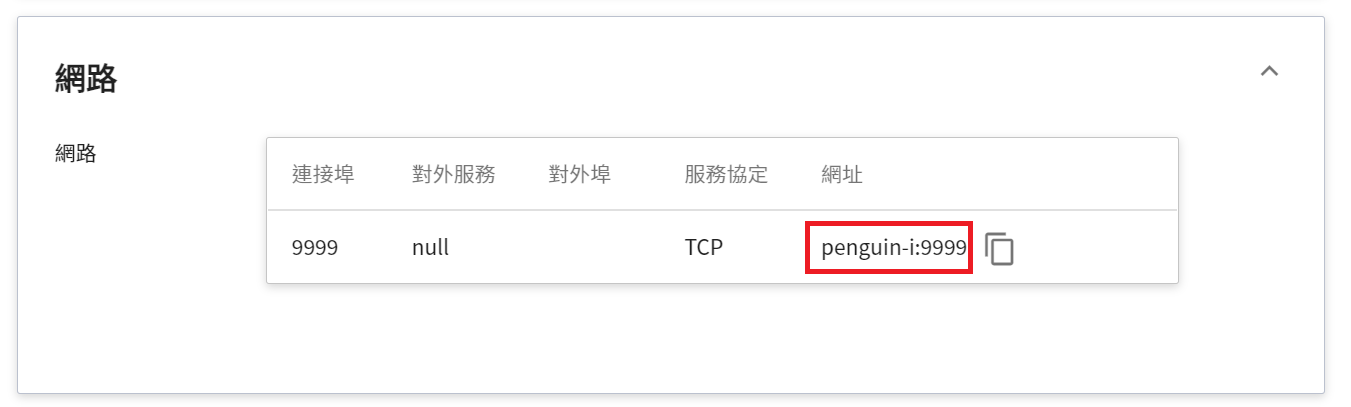
:::info
:bulb: **提示:推論服務網址**
- 為安全性考量,目前推論服務提供的 **網址** 僅能在系統的內部網路中使用,無法透過外部的網際網路存取。
- 若要對外提供此推論服務,需要透過 [**容器服務**](/s/yGbG4JJyi) 轉接到推論服務以提供對外服務。
:::
若要查看推論監控,可點擊「**監控**」頁籤,即可在監控頁面看到相關資訊,經過一段時間,監控頁面可呈現過去期間內呼叫推論服務 API 的統計資訊。
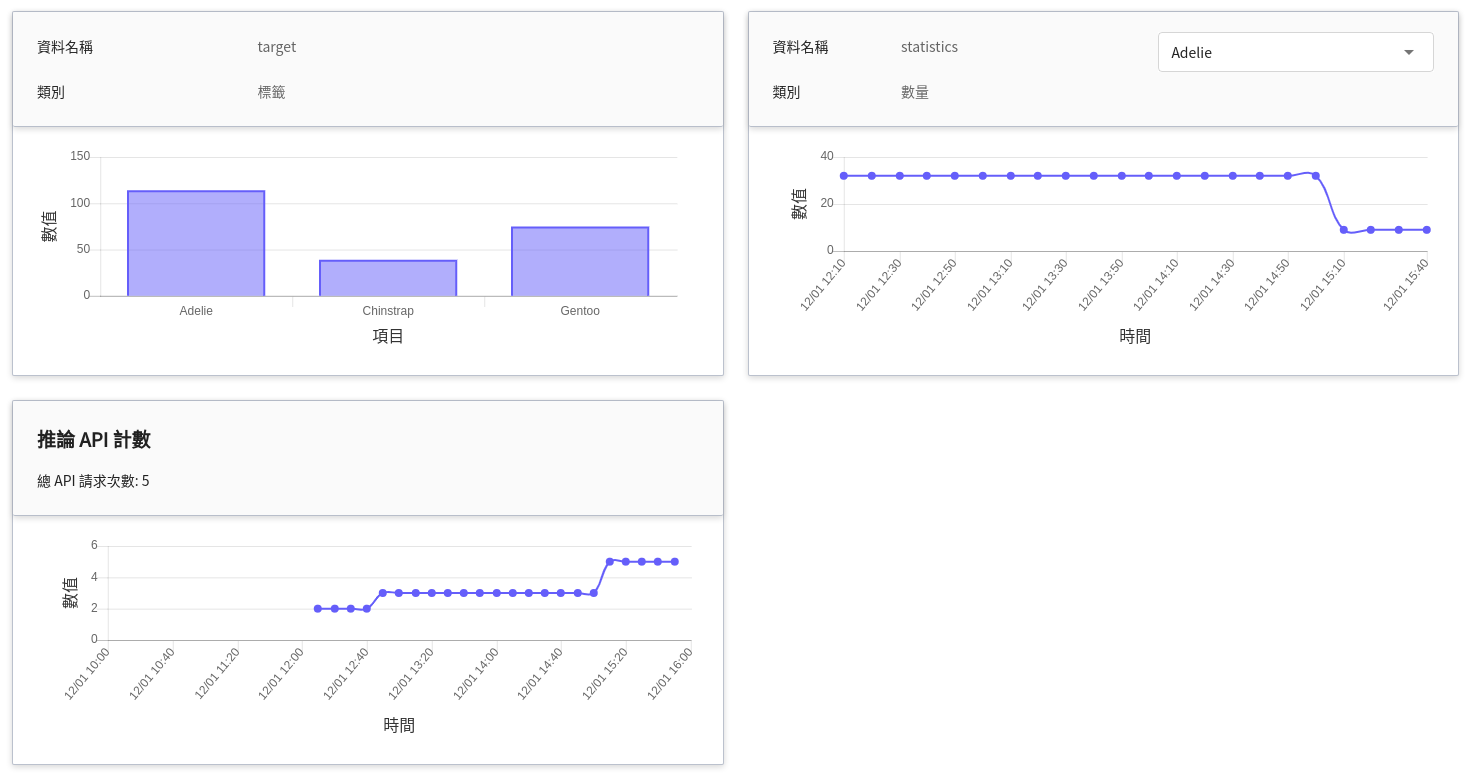
點選期間選單可篩選特定期間呼叫推論 API 的統計資訊,例如:1 小時、3 小時、6 小時、12 小時、1 天、7 天、14 天、1 個月、3 個月、6 個月、1 年或自訂。

:::info
:bulb: **關於觀測期間的起始與結束時間**
例如當前時間為 15:10,則:
- **1 小時** 的範圍是指 15:00 ~ 16:00(並非指過去一小時 14:10 ~ 15:10)
- **3 小時** 的範圍是指 13:00 ~ 16:00
- **6 小時** 的範圍是指 10:00 ~ 16:00
- 以此類推
:::
### 3.3 啟動 JupyterLab
JupyterLab 是提供一個基於 Web 的互動式計算環境,使用者可以在該 Web 服務上撰寫程式語言,像是 Python、R 等。以下將說明如何使用系統內建的 **`ml-sklearn:v2`** 映像檔來啟動 JupyterLab 服務。
1. 從服務列表中選擇「**容器服務**」,進入容器服務管理頁面後點擊「**+建立**」。
2. 輸入容器名稱,接著挑選 **`ml-sklearn`** 映像檔。
3. 在硬體設定步驟選擇最基本的硬體資源即可,不用配置 GPU。
4. 在儲存設定步驟設定存放資料集的儲存體及掛載路徑。
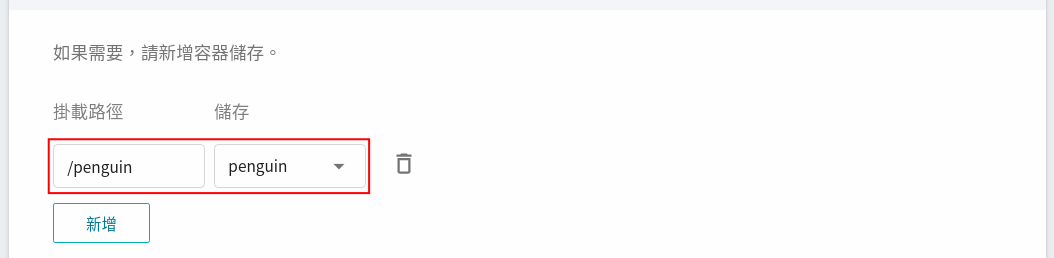
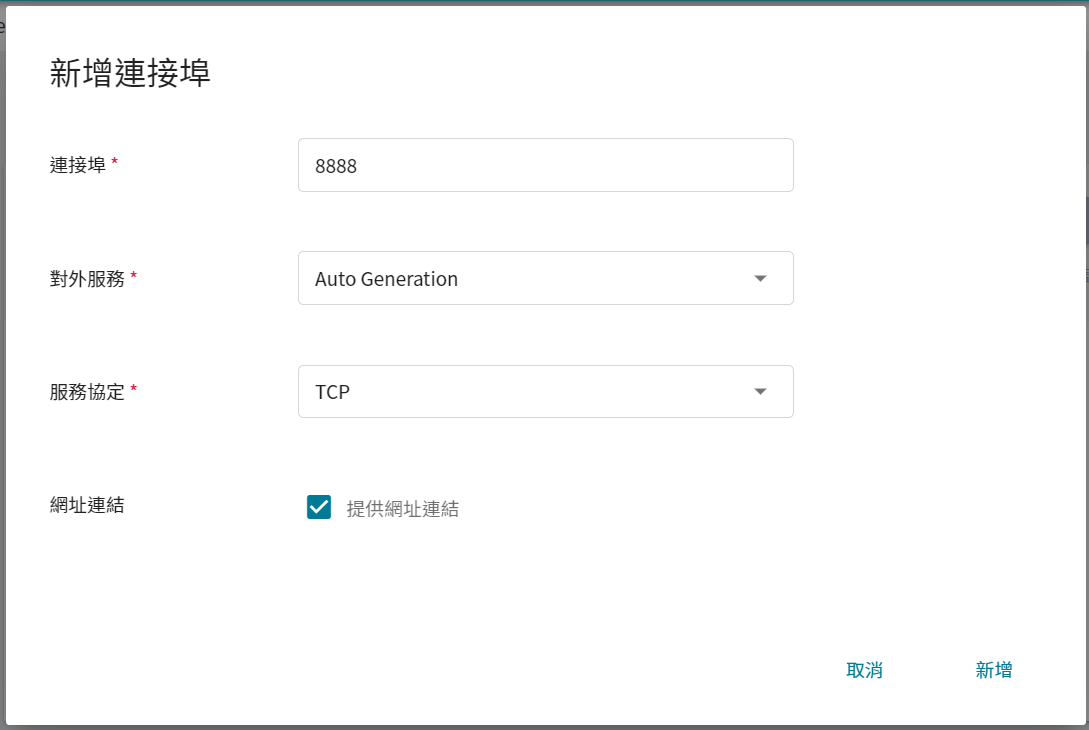
5. 為了能順利從外部存取此服務,在網路設定步驟需設定 JupyterLab 服務的連線埠為 `8888`,選擇自動產生對外服務的連線埠,並勾選 **提供網址連結**。
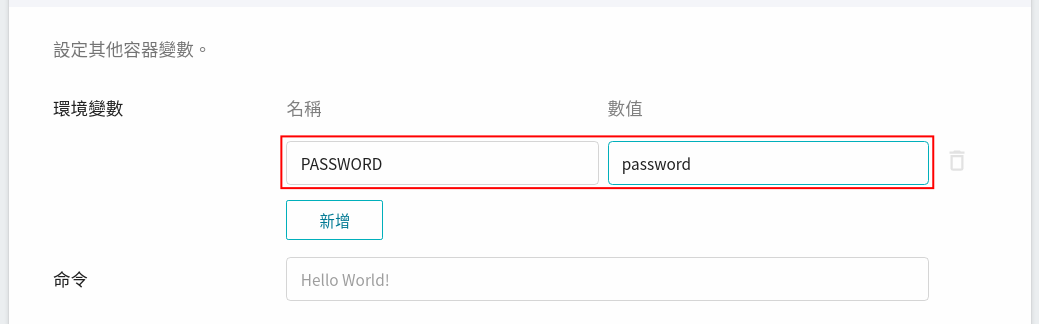
6. 在使用 JupyterLab 時,會需要輸入密碼,因此在變數設定步驟,可以使用映像檔中所預設的環境變數 **`PASSWORD`**,設定您的 JupyterLab 密碼。
7. 最後,檢視所設定的內容,確認無誤後即可按下「**建立**」。
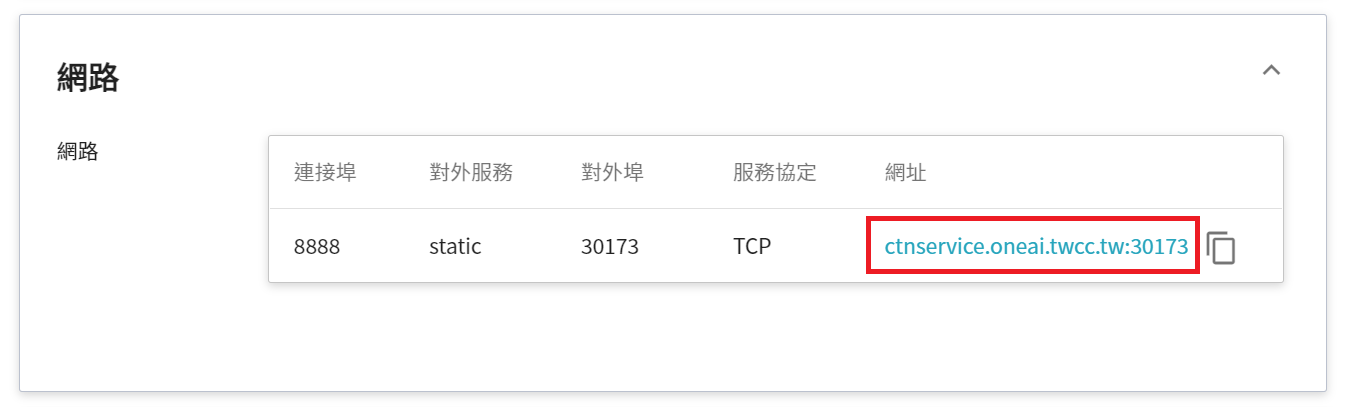
8. 容器建立成功後會出現在容器服務列表,點擊該列表進入容器的詳細資訊頁面。
9. 點擊網路區塊中 8888 連接埠對應的網址連結,即可開啟 JupyterLab。
10. 在 JupyterLab 的登入頁面中輸入密碼並按下 **Log in** 即可進入 **Launcher** 頁面。

### 3.4 使用 curl 指令,測試推論服務
登入 JupyterLab 後,點擊 **Launcher** 頁面下方的 **Terminal** 圖示可開啟 **終端機(Terminal)**。
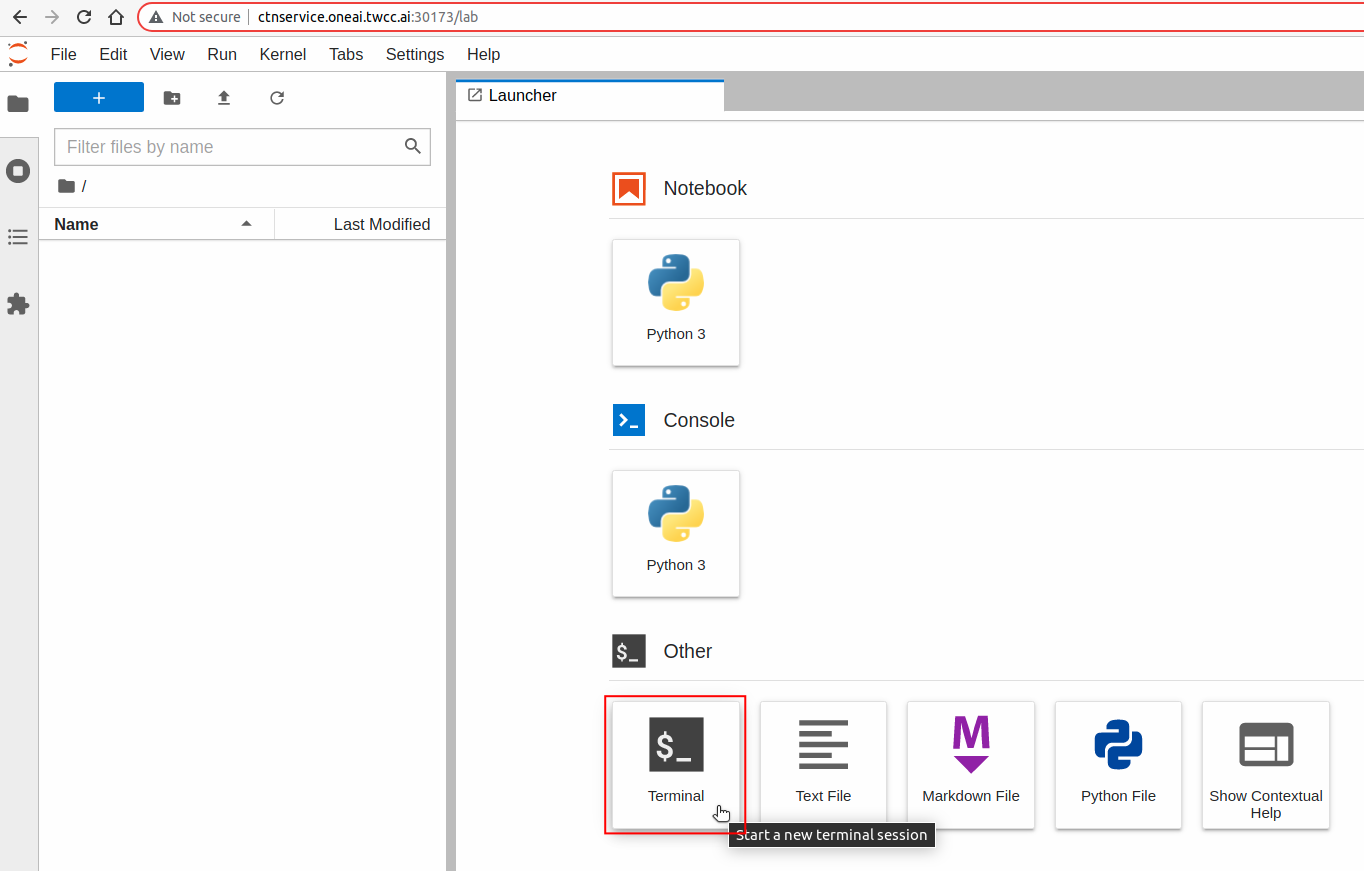
在 **終端機(Terminal)** 中輸入 **`curl`** 指令來確認推論服務是否正常啟動。
```bash
# "penguin-i:9999" 為推論服務的網址
$> curl penguin-i:9999
Start Inference API!
# or
$> curl -X GET penguin-i:9999
Start Inference API!
```
若服務啟動成功,即可呼叫 `predict` 的 API,來進行推論。
```bash
$> curl -X POST \
penguin-i:9999/predict \
-F file=@/penguin/test_x.csv \
-F INPUT_CSV_WITH_HEADER=true
```
其中
- **`-X POST`**
表示 HTTP 請求方法為 POST。
- **`-F file=@<資料集在本地端的位置>`**
表示要上傳本地端的資料集檔案到推論服務,以進行推論;
資料集的檔案,可選擇使用 `train_x.csv` 或 `test_x.csv` 作為測試。
- **`-F INPUT_CSV_WITH_HEADER=true`**
表示上傳的資料集中,首列(第一列)有欄位名稱。
(可參考變數設定 [**INPUT_CSV_WITH_HEADER**](#INPUT_CSV_WITH_HEADER) 的說明)
當推論服務收到資料集後便會進行 predict,最終返回資料集的推論結果。
```json
{
"y_pred": [
"Adelie",
"Adelie",
...
"Chinstrap",
"Chinstrap",
...
"Gentoo",
"Gentoo",
...
]
}
```
### 3.5 使用 Python 的 `requests` 模組,測試推論服務
除了使用終端機測試外,亦可以透過 **容器服務** 來啟動 Python 環境或是 Python Notebook 服務,並藉由執行底下的 Python 程式碼來測試推論服務。
點擊 JupyterLab Launcher 頁面上方的 **Notebook > Python 3** 圖示可開啟 **Notebook**。
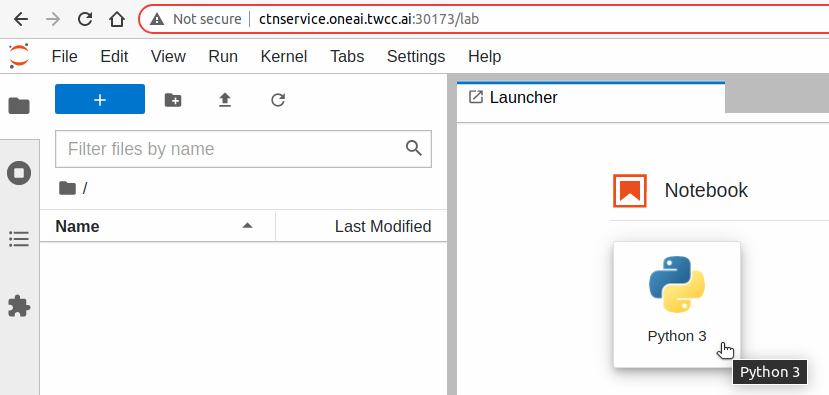
使用 **`requests`** 模組來連線測試:
```python=
import requests
import json
# prepare the post body
my_data = {'INPUT_CSV_WITH_HEADER': True}
# read the local dataset
my_files = None
with open('/penguin/test_x.csv', 'r') as f:
my_files = {'file': f.read()}
# send the post request
response = requests.post(
'http://penguin-i:9999/predict',
data=my_data, files=my_files)
# show the response
print('status_code:', response.status_code)
print('text:', response.text)
print('json:', json.loads(response.text))
```
執行結果:
```
status_code: 200
text: {
"y_pred": [
"Adelie",
"Adelie",
...
]
}
json: {'y_pred': ['Adelie', 'Adelie', ...]}
```
:::spoiler 完整程式碼(包含:發送請求、接受回應、計算評估指標)
```python=
import os
# install related packages (if needed):
os.system('pip install requests')
import requests
import json
# prepare the post body
my_data = {'INPUT_CSV_WITH_HEADER': True}
# read the local dataset
my_files = None
with open('/penguin/test_x.csv', 'r') as f:
my_files = {'file': f.read()}
# send the post request
response = requests.post(
'http://penguin-i:9999/predict',
data=my_data, files=my_files)
# show the response
print('status_code:', response.status_code)
print('text:', response.text)
print('json:', json.loads(response.text))
# ---
# calculate the evaluation metric: accuracy
# install related packages (if needed):
os.system('pip install pandas')
os.system('pip install scikit-learn')
import pandas
from sklearn.metrics import accuracy_score
df_y_true = pandas.read_csv(
'/penguin/test_y.csv',
header=0)
y_true = df_y_true.values
y_pred = json.loads(response.text)['y_pred']
accuracy = accuracy_score(y_true, y_pred)
print('accuracy: %.2f%%' % (accuracy * 100))
```
:::
## 4. [進階操作] 調整演算法的參數
:::info
:bulb:**提示:** 這一章節為進階操作,若機器學習結果不符合預期時,想要進一步設定或調整演算法參數,可參考此篇說明。
:::
在 [**2.1.4 變數設定**](#214-變數設定) 章節中,有提及設定機器學習所要使用的 [**演算法 (MODEL_ALGORITHM)**](#MODEL_ALGORITHM)。當演算法的預設參數、或訓練結果,無法滿足實際的需求時,例如:
1. 想花更多時間尋找最適演算法與超參數,需增加演算時間。
2. 迭代次數不夠,模型尚無法擬合定型,需加大迭代次數。
3. 單一演算法中有不同的演算方式,想要選擇不同的演算方式來擬合資料。
4. 以多項式為核心的演算法,可藉由變更冪次(指數部份),來提高模型的複雜度。
5. 更改懲罰程度(罰分)... 等等。
基於需求,可以透過參數調整來滿足實際的需求。此參數調整,亦稱為超參數調整(調校)。
### 4.1 參數調整方式
在 [**變數設定**](#214-變數設定) 頁面,新增一組或多組鍵值,來變更模型演算法的預設參數。
### 4.2 參數語法規則
設定演算法參數的規則為:所填寫的 [MODEL_ALGORITHM](#MODEL_ALGORITHM) 值,再加上**參數名稱**和**參數值**。
範本:
```
{MODEL_ALGORITHM}_param_{參數名稱}:{參數值}
```
:::info
:pencil: **範例1**
- 演算法名稱:`AutoSklearn`
- 參數1
- 名稱:`time_left_for_this_task`
- 值:`60*5` (執行總時間,限制為 5 分鐘)
- 參數2
- 名稱:`per_run_time_limit`
- 值:`30` (單次測試時間,限制為 30 秒)<br><br>
套入上述範本後為:
```
AutoSklearn_param_time_left_for_this_task:60*5
AutoSklearn_param_per_run_time_limit:30
```
並將其設定到環境變數:

:::
:::info
:pencil: **範例2**
- 演算法類別:`AutoSklearnClassifier`
- 參數1
- 名稱:`time_left_for_this_task`
- 值:`60*5` (執行總時間,限制為 5 分鐘)
- 參數2
- 名稱:`per_run_time_limit`
- 值:`30` (單次測試時間,限制為 30 秒)<br><br>
套入上述範本後為:
```
AutoSklearnClassifier_param_time_left_for_this_task:60*5
AutoSklearnClassifier_param_per_run_time_limit:30
```
並將其設定到環境變數:

:::
以下列出各演算法的**名稱**,及其對應的**類別**與**參數說明**:
| 演算法名稱 | 演算法類別 | 參數說明<br>(參數名稱 & 參數值) |
| --------------------- | -------- | -------- |
| `Auto` | [^註1^](#footnote_auto_algorithm_class) | - |
| `AutoSklearn` | AutoSklearnClassifier | [查看參數](https://automl.github.io/auto-sklearn/master/api.html) |
| `AutoGluon` | AutoGluonClassifier | 查看參數:[init](https://auto.gluon.ai/0.1.0/api/autogluon.task.html#autogluon.tabular.TabularPredictor), [fit](https://auto.gluon.ai/0.1.0/api/autogluon.task.html#autogluon.tabular.TabularPredictor.fit) [^註2^](#footnote_autogluon_parameters) |
| `AdaBoost` | AdaBoostClassifier | [查看參數](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html) |
| `ExtraTree` | ExtraTreeClassifier | [查看參數](https://scikit-learn.org/stable/modules/generated/sklearn.tree.ExtraTreeClassifier.html) |
| `DecisionTree` | DecisionTreeClassifier | [查看參數](https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html) |
| <span style="white-space: nowrap">`GradientBoosting`</span> | GradientBoostingClassifier | [查看參數](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html) |
| `KNeighbors` | KNeighborsClassifier | [查看參數](https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html) |
| `LightGBM` | LGBMClassifier | [查看參數](https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.LGBMClassifier.html) |
| <span style="white-space: nowrap">`LogisticRegression`</span> | LogisticRegression | [查看參數](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) |
| `RandomForest` | RandomForestClassifier | [查看參數](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html) |
| `SGD` | SGDClassifier | [查看參數](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassifier.html) |
| `SVM` | SVC | [查看參數](https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html) |
| `XGBoost` | XGBClassifier | [查看參數](https://xgboost.readthedocs.io/en/latest/python/python_api.html#xgboost.XGBClassifier) |
- <span id="footnote_auto_algorithm_class"></span>**註1**:不建議使用,使用者需確實了解 `Auto` 在執行時,是動態綁定到 `AutoSklearnClassifier` 還是 `AutoGluonClassifier`?
- 無 GPU 環境,`Auto` 會綁定到 `AutoSklearnClassifier`
- 有 GPU 環境,`Auto` 會綁定到 `AutoGluonClassifier`
- <span id="footnote_autogluon_parameters"></span>**註2**:AutoGluon 當前都使用預設參數。
- 若要調整參數,其參數來源有兩個:
- 一個來源是 [init 參數](https://auto.gluon.ai/0.1.0/api/autogluon.task.html#autogluon.tabular.TabularPredictor);
- 另一個來源是 [fit 參數](https://auto.gluon.ai/0.1.0/api/autogluon.task.html#autogluon.tabular.TabularPredictor.fit)。
- 若要限制執行總時間,可以這麼做:
- 使用演算法名稱
```
AutoGluon_param_time_limit:60*5
```
- 明確指定演算法類別
```
AutoGluonClassifier_param_time_limit:60*5
```
- <span id="footnote_experimental_algorithm_name"></span>**Q & A**:
- **針對不在上述表格中的機器學習演算法要如何設定參數?**
使用不在上述表格中的機器學習演算法,使用者需要明確地指定 `ml-sklearn` 映像檔所提供的 [**演算法類別**](#footnote_experimental_algorithm_class_list)。以所使用的演算法類別作為關鍵字,在 [**scikit-learn 官方文件**](https://scikit-learn.org/stable/modules/classes.html) 中可以找到對應的演算法類別,再點進去即可找到該演算法類別所能使用的參數。<br>
例如,想使用 `MLPClassifier`,在該頁面搜尋關鍵字就可以找到,如下所示:

接著再點進去,就能看到相關參數用法。

### 4.3 實際範例
實際操作過程,將以第 1 個範例作為主要說明;隨後的範例,將簡單陳述說明。
#### 4.3.1 想花更多時間尋找最適演算法與超參數,需增加演算時間
此章節是針對 [**MODEL_ALGORITHM**](#MODEL_ALGORITHM) 設為 `Auto` 選項時的補充說明。在 **AutoClassifier** 的 [**參數說明**](https://automl.github.io/auto-sklearn/master/api.html) 中,有提及:
- **`time_left_for_this_task` (該次任務的總時間)**
> 預設時間為 3600 秒 (1小時),以秒為單位。
>
> 搜尋最佳模型的總時間限制。藉由增加該值,AutoClassifier 更有可能找到更好的模型。
- **`per_run_time_limit` (單次執行的時間限制)**
> 預設時間為 360 秒 (6分鐘),以秒為單位。
>
> 選定一個模型與一組參數,進行單次測試的時間限制。
>
> 有些演算法(如 MLP )在單次測試時,有可能會花費比較久的時間來擬合模型,一旦執行時間超過預設 6 分鐘,此演算法就會被記為失敗,不列入參考模型清單。
何時該調整此參數?
> 透過 [**2.3.2 機器學習的執行日誌**](#232-機器學習的執行日誌) 章節,可了解如何查看日誌。當逾時的演算法比例過高,在不計時間等成本考量之下,可考慮放寬單次執行的時間限制。
> 
為了增加演算時間,可以這麼做:
| 參數 | 設定值 | 說明 |
| --- | ----- | --- |
| `AutoClassifier_param_time_left_for_this_task` | `60*60*24` | 以秒為單位。<br>總時間設定為 24 小時,亦可填入 `86400`。 |
| `AutoClassifier_param_per_run_time_limit` | `60*30` | 以秒為單位。<br>單次測試時間設定為 30 分鐘,亦可填入 `1800`。 |
在 [**變數設定**](#214-變數設定) 階段的 **環境變數** 表格中,實際填入兩筆鍵值:
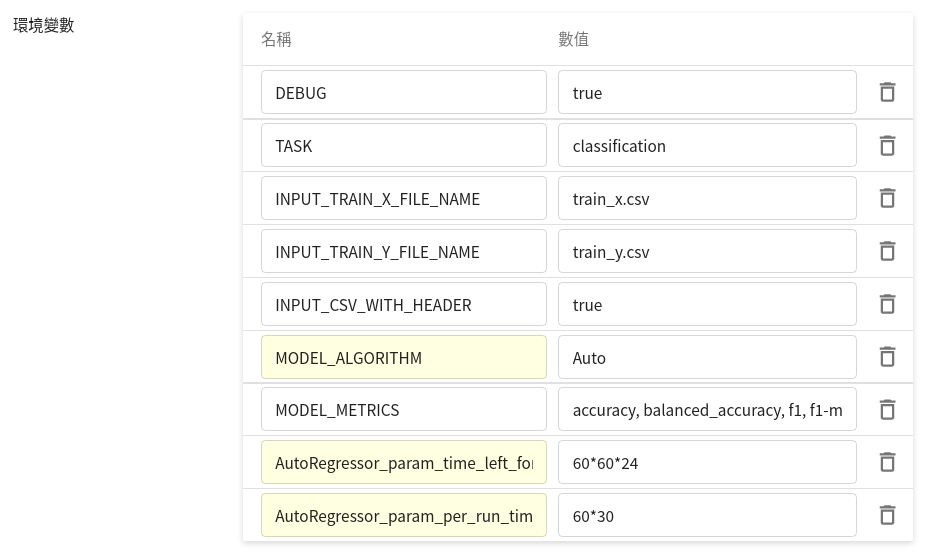
隨後啟動的訓練任務,將採用此設定。
:::info
:bulb: **提示:更多的設定與配置**
在 [**2.1.2 硬體設定**](#212-硬體設定) 章節中,有提及自身需求的硬體資源。為了發揮所配置到硬體資源,可以這麼做:
| 參數 | 設定值 | 說明 |
| --- | ----- | --- |
| `AutoClassifier_param_n_jobs` | `-1` | 使用所有 CPU 。原預設值為單一核心。 |
| `AutoClassifier_param_memory_limit`|`1024*40` |將記憶體上限調高為 40GB,以應付千萬筆的表格數據。|
:::
:::warning
:warning: **注意事項**
演算法參數的設定,需跟 **`MODEL_ALGORITHM`** 參數一起搭配使用;否則演算法參數的設定將會被忽略。
:::
#### 4.3.2 迭代次數不夠,模型尚無法擬合定型,需加大迭代次數
| 參數 | 設定值 | 說明 |
| --- | ----- | --- |
| `LogisticRegression_param_max_iter` | `500` | LogisticRegression 的預設值為 100。 |
| `SGDClassifier_param_max_iter` | `5000` | SGDClassifier 的預設值為 1000。 |
#### 4.3.3 單一演算法中有不同的演算方式,想要選擇不同的演算方式來擬合資料
| LogisticRegression 參數 | 設定值 | 說明 |
| ---------------------- | ----- | --- |
| `LogisticRegression_param_solver` | `liblinear` | 將 LogisticRegression 的求解方法設為 `liblinear` |
| `LogisticRegression_param_solver` | `sag` | 將 LogisticRegression 的求解方法設為 `sag` |
| `LogisticRegression_param_solver` | `saga` | 將 LogisticRegression 的求解方法設為 `saga` |
| SVC 參數 | 設定值 | 說明 |
| ------- | ----- | --- |
| `SVC_param_kernel` | `linear` | 將 SVC (SVM) 的核心設為 `linear` |
| `SVC_param_kernel` | `poly` | 將 SVC (SVM) 的核心設為 `poly` |
| `SVC_param_kernel` | `sigmoid` | 將 SVC (SVM) 的核心設為 `sigmoid` |
<br>
#### 4.3.4 以多項式為核心的演算法,可藉由變更冪次 (次數、指數部份),來提高模型的複雜度
針對 SVC 做設定,底下 3 個設定為一組,需一起搭配使用:
| SVC 參數 | 設定值 | 說明 |
| ------- | ----- | --- |
| `MODEL_ALGORITHM` | `SVM` | 使用 SVM 演算法 |
| `SVC_param_kernel` | `poly` | 將 SVC (SVM) 的核心設為 `poly` |
| `SVC_param_degree` | `5` | 將 [多項式](https://zh.wikipedia.org/wiki/%E5%A4%9A%E9%A0%85%E5%BC%8F) 的冪次,從預設為 3 變更為 5 |
#### 4.3.5 更改懲罰程度(罰分)
懲罰 (penalty) 亦稱為正規化項 (regularization term),一般有 L1、L2、ElasticNet 可以選擇。
| 參數 | 設定值 | 說明 |
| --- | ----- | --- |
| `SGDClassifier_param_penalty` | `elasticnet` | |
| `SVC_param_C` | `2` | 設定懲罰係數,從預設為 `1` 變更為 `2`;`C` 值越高,越不能容忍出現誤差,但可能會過擬合。 |
針對 LogisticRegression 做設定,底下 4 個設定為一組,需一起搭配使用:
| LogisticRegression 參數 | 設定值 | 說明 |
| ---------------------- | ----- | --- |
| `MODEL_ALGORITHM` | `LogisticRegression` | 使用 LogisticRegression 演算法 |
| `LogisticRegression_param_solver` | `saga` | 將求解方法設為 `saga` |
| `LogisticRegression_param_penalty` | `elasticnet` | 需搭配 `saga` 使用 |
| `LogisticRegression_param_l1_ratio` | `0.5` | 需搭配 `elasticnet` 使用 |
若沒有一起使用,訓練任務將會失敗() ,日誌會有底下錯誤訊息:
```
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties,
got elasticnet penalty.
```
```
ValueError: l1_ratio must be between 0 and 1;
got (l1_ratio=None)
```