---
title: AI Maker 案例教學 - YOLOv3 影像辨識應用
description: OneAI 文件
tags: 案例教學, YOLO
---
[OneAI 文件](/s/xKNcU3O5D)
# AI Maker 案例教學 - YOLOv3 影像辨識應用
[TOC]
## 0. 部署 YOLOv3 影像辨識應用
在本範例中,我們將使用 AI Maker 針對 YOLOv3 影像辨識應用所提供的 **`yolov3`** 範本,從無到有逐步建立一個 YOLO 影像辨識應用。系統所提供的 **`yolov3`** 範本中事先定義了從訓練任務到推論各階段任務中所需使用的環境變數、映像檔、程式等設定,方便您快速地開發屬於自己的 YOLO 網路。
主要步驟如下:
1. [**資料集準備**](#1-準備資料集)
在此階段,我們要準備進行機器學習訓練的影像資料集,並上傳至指定位置。
2. [**資料標註**](#2-標註資料)
在此階段,我們將標註影像中的物體,這些標註資料稍後會用於神經網路的訓練。
3. [**訓練 YOLO 模型**](#3-訓練-YOLO-模型)
在此階段,我們將配置相關訓練任務,以進行神經網路的訓練與擬合,並將訓練好的模型儲存。
4. [**建立推論服務**](#4-建立推論服務)
在此階段,我們會部署已儲存的模型並進行推論。
5. [**進行影像辨識**](#5-進行影像辨識)
在此階段,我們會示範如何在 Jupyter Notebook 中使用 Python 語言發送推論請求。
當完成本範例後,您將學會:
1. 熟悉 AI Maker 功能並建立各階段任務。
2. 使用 AI Maker 內建的範本建置相關任務。
3. 使用儲存服務並上傳資料。
4. 使用 CVAT 工具標註物件,進行資料預處理。
5. 透過 Jupyter Notebook 執行物件辨識。
6. 使用 CVAT 輔助標註功能,降低人工標註的時間。
## 1. 準備資料集
在正式開始前,請先準備好欲訓練的資料集,如:貓、狗、人... 等圖片。依照下列步驟,將資料集上傳至本系統所提供的儲存服務中,並將資料集依照指定的目錄結構存放,以供後續開發使用。
### 1.1 上傳自有資料集
若您已經準備好自己的資料集進行訓練,請依照下列步驟進行資料的存放。
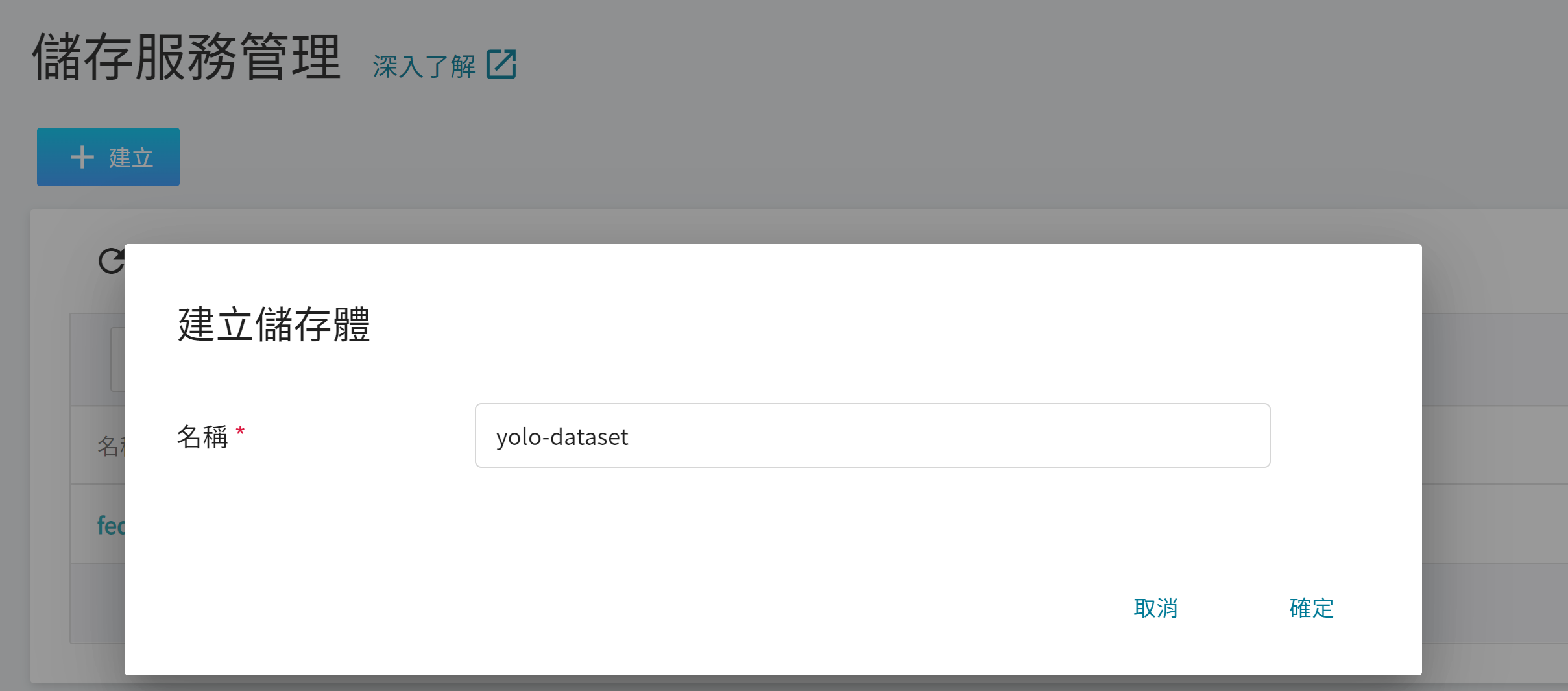
1. **建立儲存體**
從 OneAI 服務列表選擇「**儲存服務**」,進入儲存服務管理頁面,接著點擊「**+建立**」,新增一個儲存體,例如:**yolo-dataset**,這個儲存體稍後會用來存放您的自有資料集。
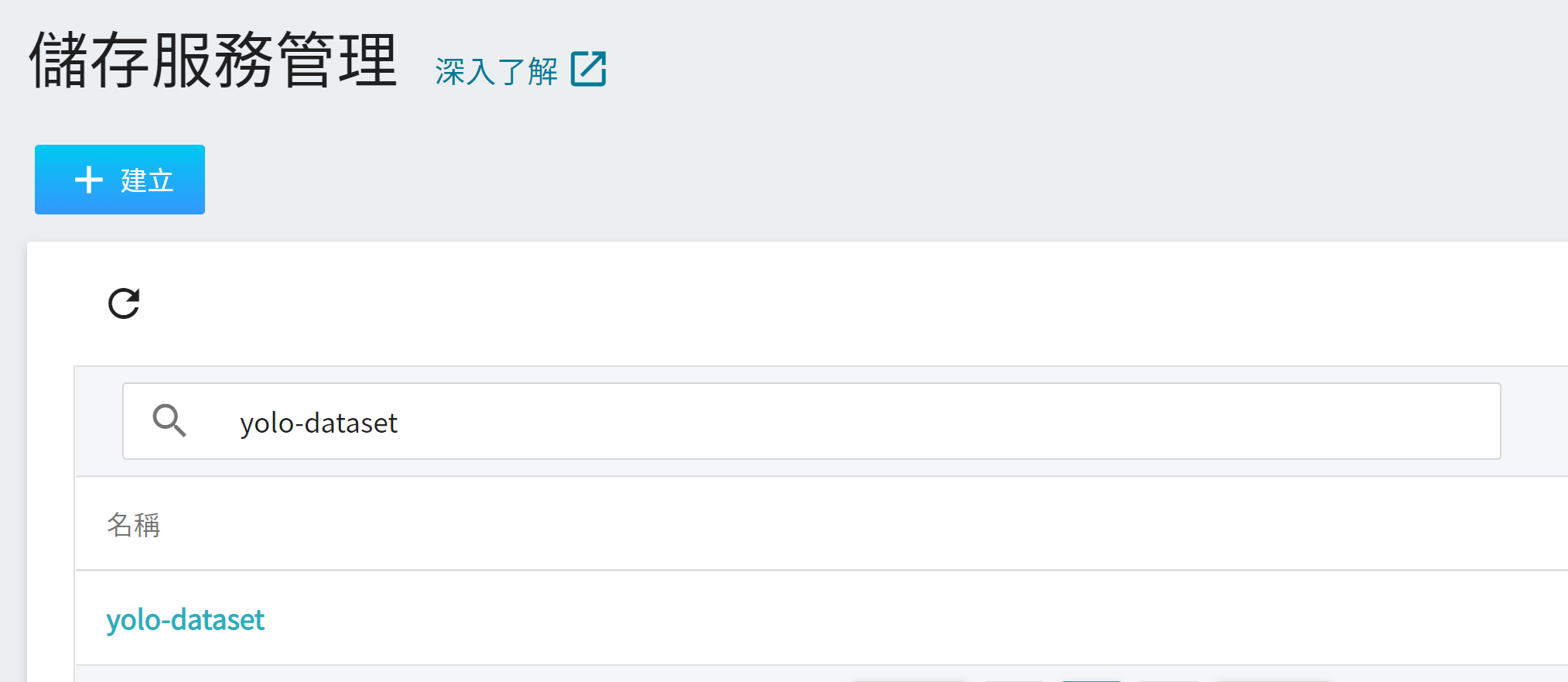
2. **檢視儲存體**
完成儲存體的建立後,重新回到儲存服務管理頁面,此時會看到剛剛新增的儲存體已建立完成。
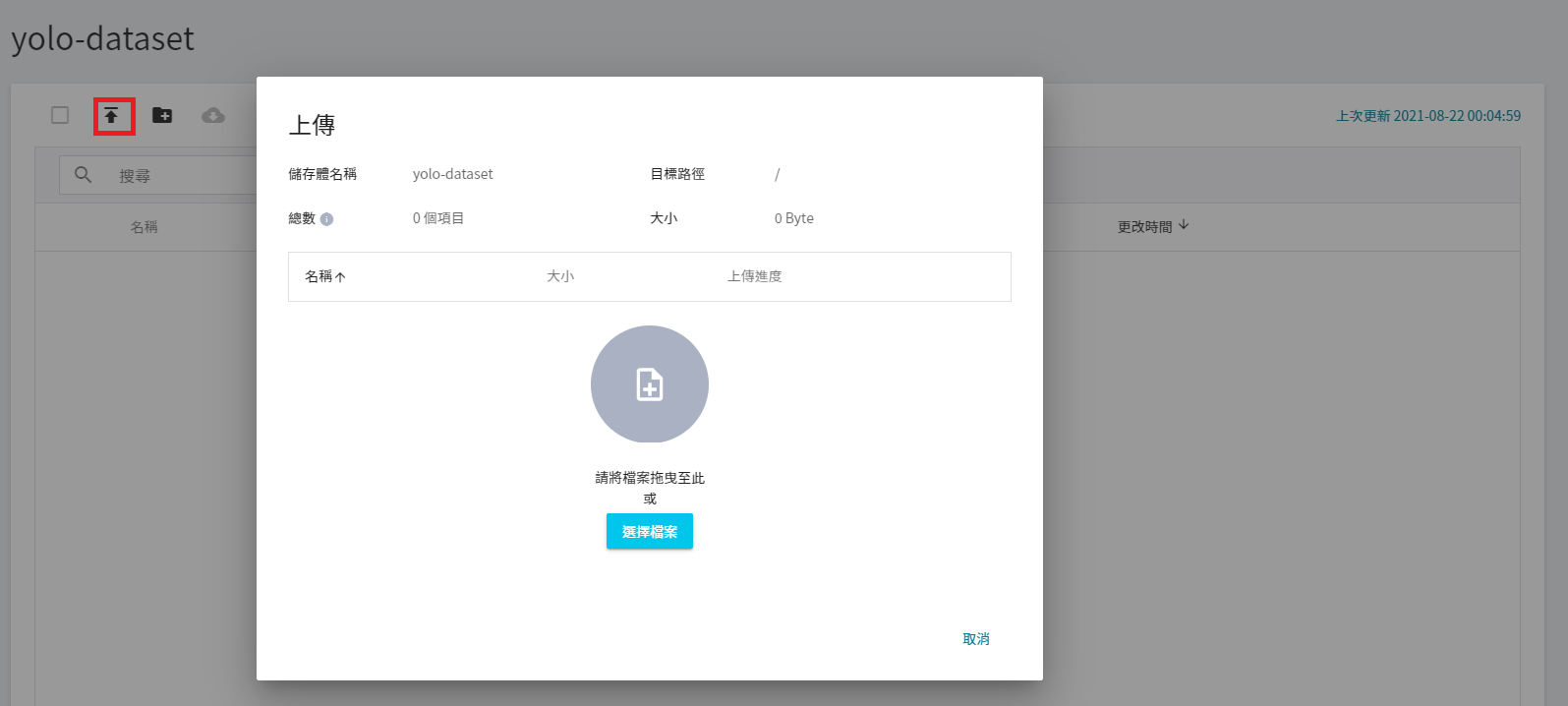
3. **上傳自有資料集**
點擊建立好的儲存體,然後點選「**上傳**」就可以開始上傳資料集。(請參閱 [**儲存服務**](/s/_F4C_EzEa) 說明)。
### 1.2 上傳自有資料集及已標註的資料
若您已經有資料集以及標註資料,可以按照本小節的教學存放自己的資料。
1. 建立儲存體
從 OneAI 服務列表選擇「**儲存服務**」,進入儲存服務管理頁面,接著點擊「**+建立**」,新增一個儲存體,例如:**yolo-dataset**,這個儲存體稍後會用來存放您的資料集。

2. 新增 **dataset** 資料夾
dataset 資料夾請存放訓練的圖片跟標註的文字檔,文字檔的內容為使用標註工具(例如:CVAT)標註好的資料,例如:
```
3 0.716912 0.650000 0.069118 0.541176
```
由左而右說明如下:
```
3:代表標註此物件的 class ID
0.716912:代表該 bounding box 的中心座標 X 與圖片寬的比值,是 bounding box 歸一化後的中心座標 X。
0.650000:代表該 bounding box 的中心座標 Y 與圖片高的比值,是 bounding box 歸一化後的中心座標 Y。
0.069118:代表該 bounding box 的寬與輸入圖像寬的比值,是 bounding box 歸一化後的寬座標。
0.541176:代表該 bounding box 的高與輸入圖像高的比值,是 bounding box 歸一化後的高座標。
```
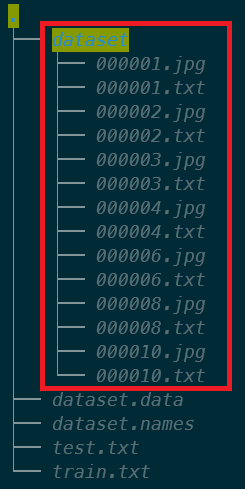
3. 新增 **train.txt** 檔案
所有 images 檔案名稱列表中的 80% (或其它比例,可視需求變更),訓練時 YOLO 會依次讀取該檔內容取出相片進行訓練,其內容以 /dataset/ 串接圖片位置。
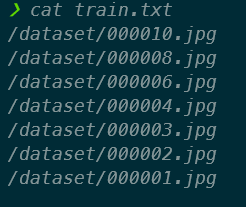
4. 新增 **test.txt** 檔案
所有 images 檔案名稱列表中的 20% (或其它比例,可視需求變更),訓練時 YOLO 會依次讀取該檔內容取出相片進行 validation,其內容以 /dataset/ 串接圖片位置。
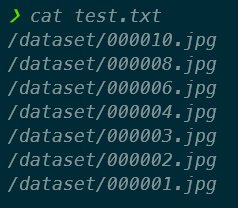
5. 新增 **dataset.names** 檔案
此檔內容為 label 的列表,YOLO 在訓練與預測時皆需要讀取此檔,本範例的 label 為 car、person。
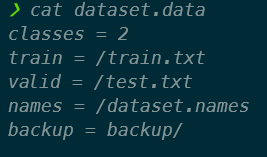
6. 新增 **dataset.data** 檔案
定義 label 數目以及各個設定檔,其中 backup 為設定權重檔 (*.weights) 要儲存的位置。
## 2. 標註資料
為了使 YOLO 網路能夠學習與辨認我們所提供影像,我們須先將準備訓練的影像進行標註。本章節中,我們將透過 **AI Maker** 所整合的 **CVAT 工具(Computer Vision Annotation Tool)**,對欲執行訓練的資料進行標註。
在模型訓練好後或是已經有訓練好的模型,可以使用 **CVAT 工具(Computer Vision Annotation Tool)** 的輔助標註功能,來降低人工標註的時間以及成本,請參閱本教學的 [**6. CVAT 輔助標註**](#6-CVAT-輔助標註)。
:::info
:bulb: **提示**:若您已經自有資料集以及標註資料,可直接到步驟 [**3. 訓練 YOLO 模型**](#3-訓練-YOLO-模型)。
:::
### 2.1 啟用與設定 CVAT
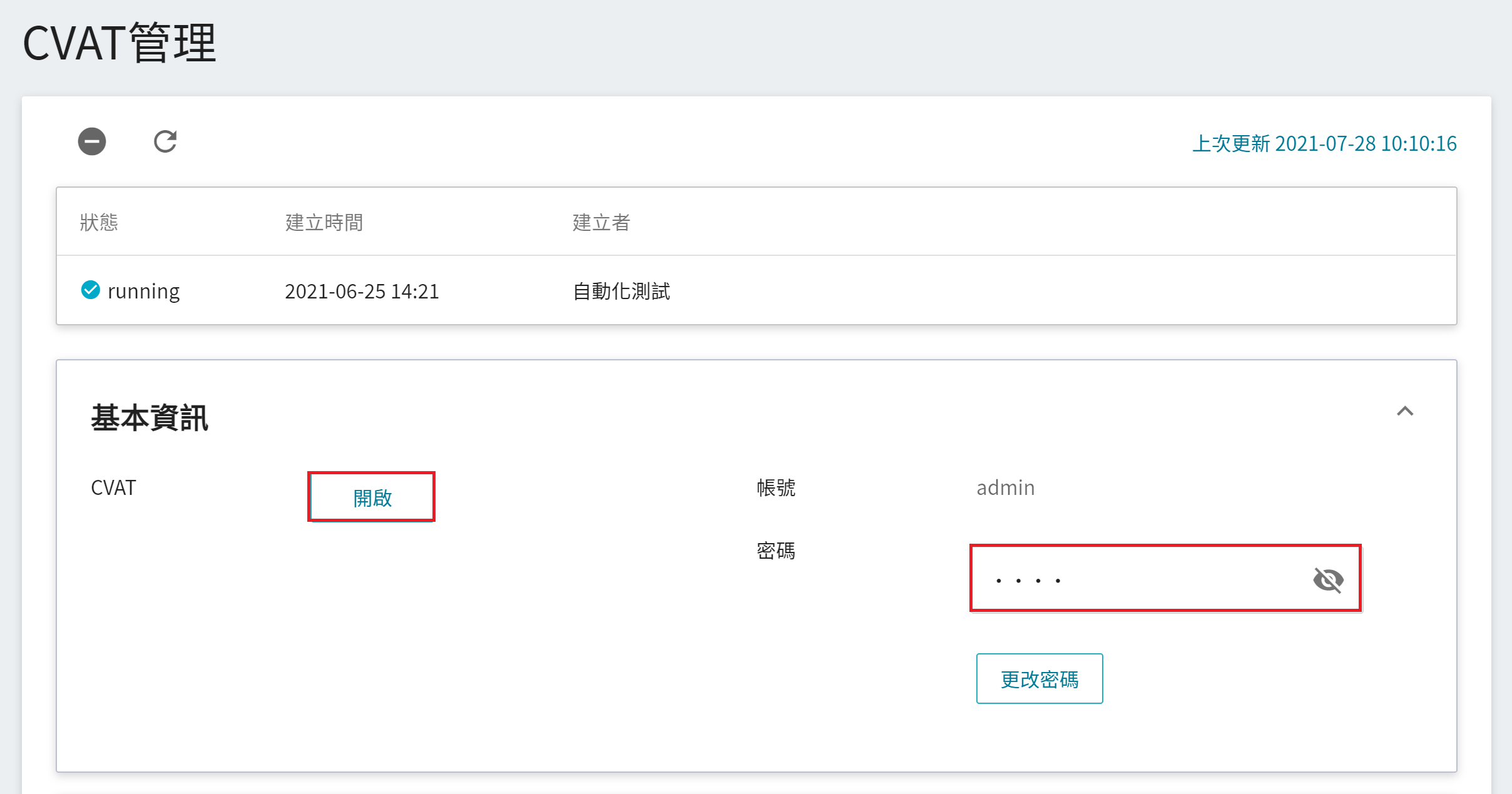
點選左側功能列之「**標註工具**」,進入 CVAT 服務首頁。第一次使用需先點擊「**啟用 CVAT 服務**」,每個專案只能開啟一套 CVAT 服務。

CVAT 啟用成功後,會出現 CVAT 服務的連結及預設的帳號及密碼,此時狀態為 **`running`**。點擊基本資訊之「**開啟**」,可在瀏覽器的新視窗中開啟 CVAT 服務的登入頁面。
:::info
:bulb: **提示:** 首次啟用 CVAT 建議更改預設的密碼,此密碼沒有期限設定,相同專案之成員,皆可使用此密碼登入 CVAT 服務,為安全考量,請定期更改密碼。
:::
### 2.2 使用 CVAT 建立標註任務
1. **登入 CVAT**
點擊「**開啟**」後,在 **CVAT 服務** 的登入頁面輸入帳號及密碼,即可登入 CVAT 服務。
:::warning
:warning: **注意:** 請使用 Google Chrome 瀏覽器登入 CVAT,若使用其他瀏覽器可能會造成不可預期的問題,例如:無法登入或無法成功標註之類的問題。
:::
2. **建立 CVAT 標註 Task**
成功登入 CVAT 服務後點擊上方「**Tasks**」進入 Tasks 頁面。接著點擊「**+**」再點選「**+ Create a new task**」建立標註任務。

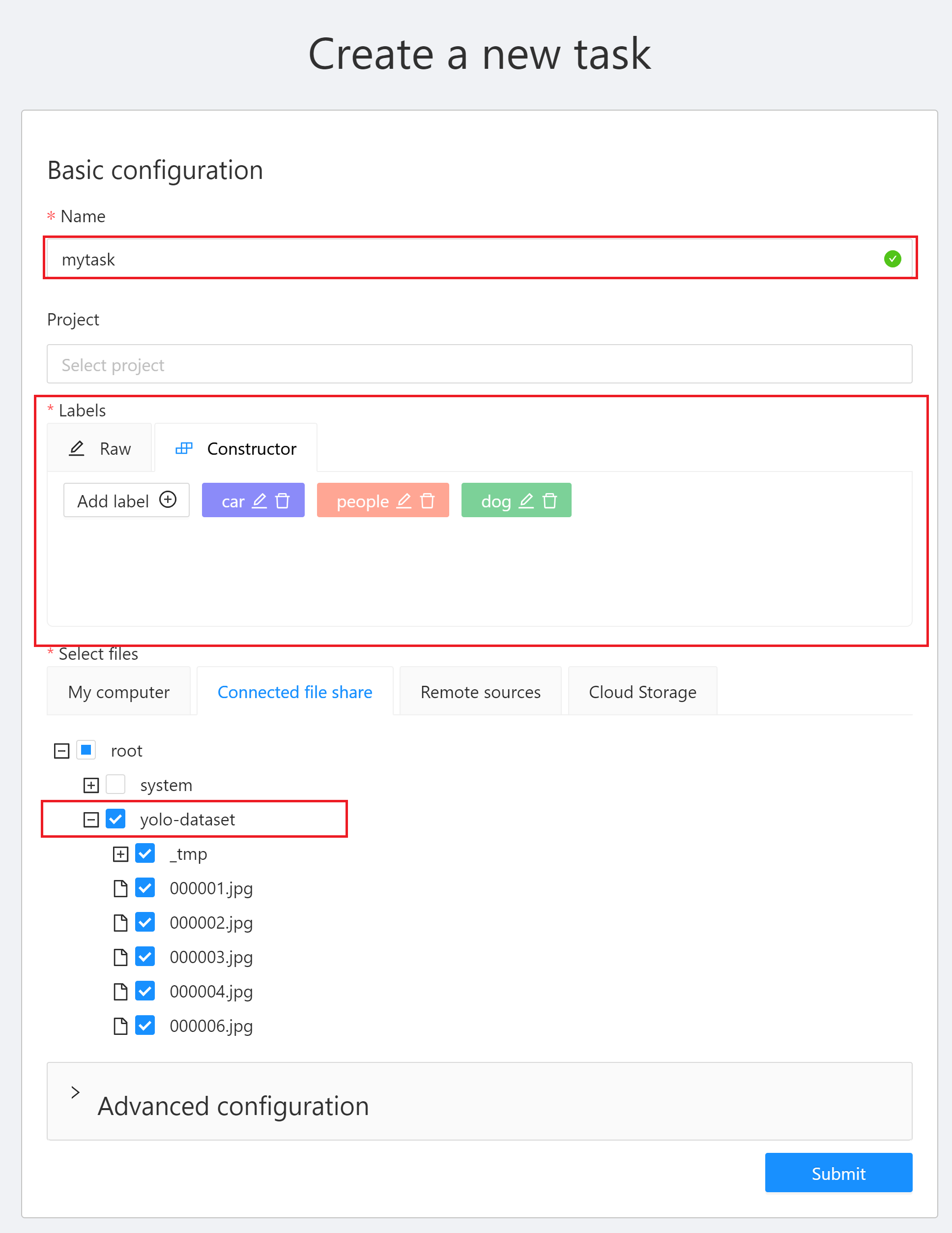
3. 「**Create a new task**」視窗中有三個地方需設定:
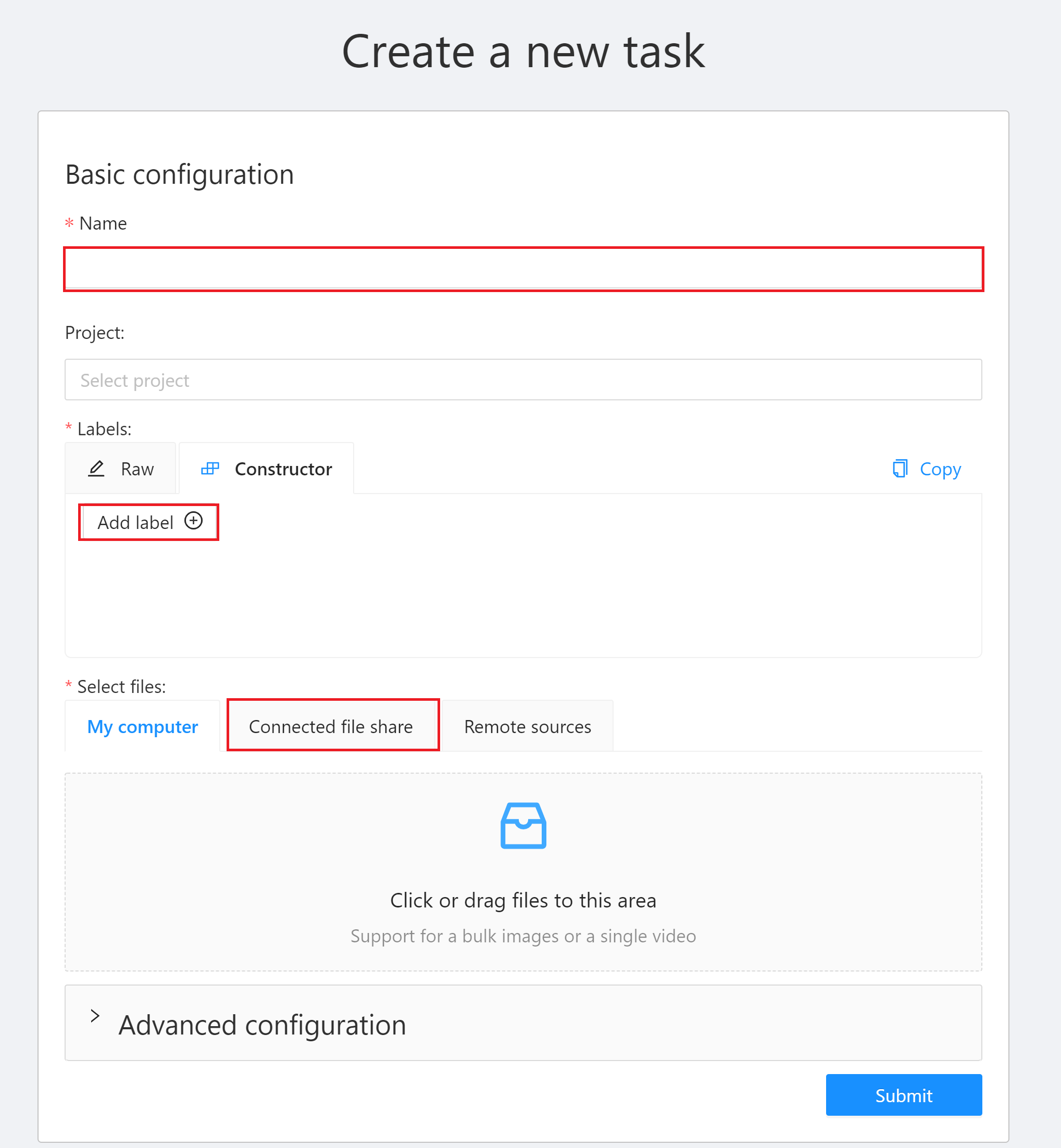
* **Name**:輸入此 Task 的名稱,例如:`mytask`。
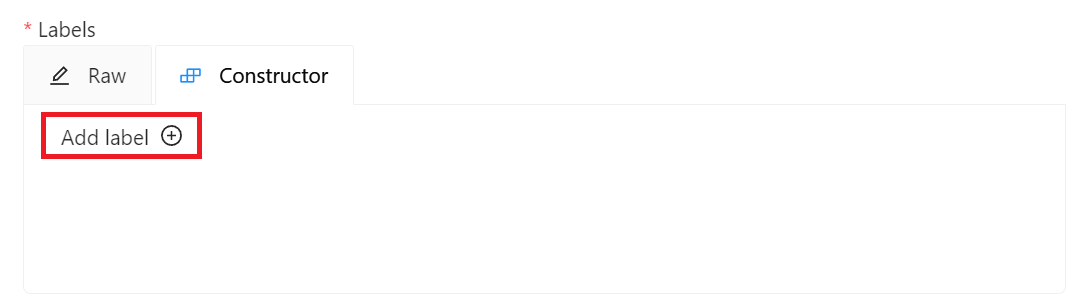
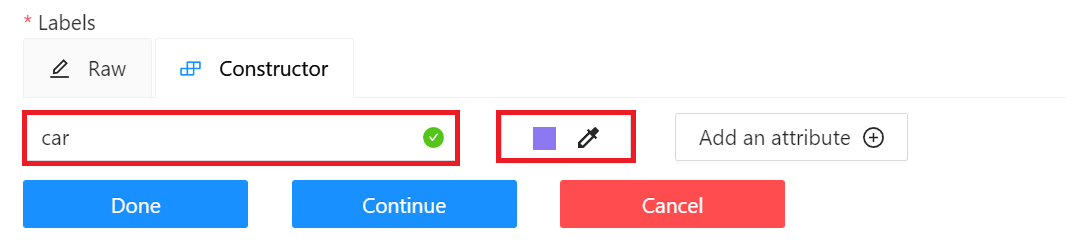
* **Labels**:設定欲辨識的物件標籤。點擊「**Add label**」,輸入標籤名稱,點擊右側的顏色區塊可設定標籤的顏色,接著按下「**Continue**」繼續增加其他標籤,或點擊「**Done**」完成標籤的設定。此範例中,我們將建立 car、people 與 dog 三個標籤。
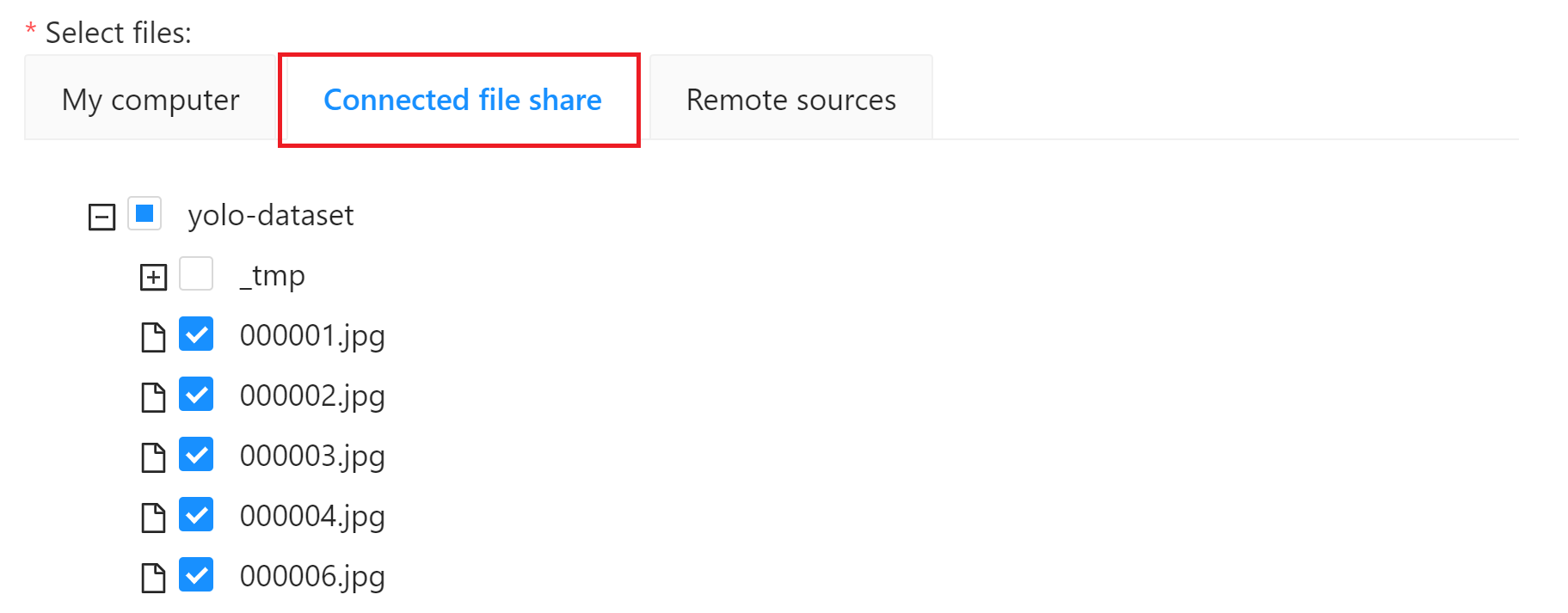
* **Select files**:選擇訓練資料集來源,此範例請點擊 **Connected file share** 選取 **`yolo-dataset`** 儲存體當作資料集來源。關於資料集請參閱 [**1. 準備資料集**](#1-準備資料集)。設定完成後再點擊「**Submit**」即可建立 Task。
:::warning
:warning: **注意:CVAT 檔案大小限制**
在 CVAT 服務中,建議您的資料集來源使用儲存服務服務的儲存體。若您的資料集來源是使用本機端上傳資料,則 CVAT 服務限制每個 TASK 的檔案限制大小為 1 GB。
:::
### 2.3 使用 CVAT 進行資料標註
完成建立 CVAT 標註的 Task 後,接著即可進行資料標註。
1. **查看建立的 Task**
標註任務建立後會出現在「**Tasks**」列表的最上方,點擊 「**Open**」進入 Task 的詳細資訊頁面。

2. **開始進行標註**
在 Task 的詳細資訊頁面,會帶出已建立的物件標籤,當標籤確認無誤後,即可按下 **Job #id** 開始進行標註。其中 **`Task #1`** 代表此 Taskid 為 1,後續的訓練任務會需要此資訊。
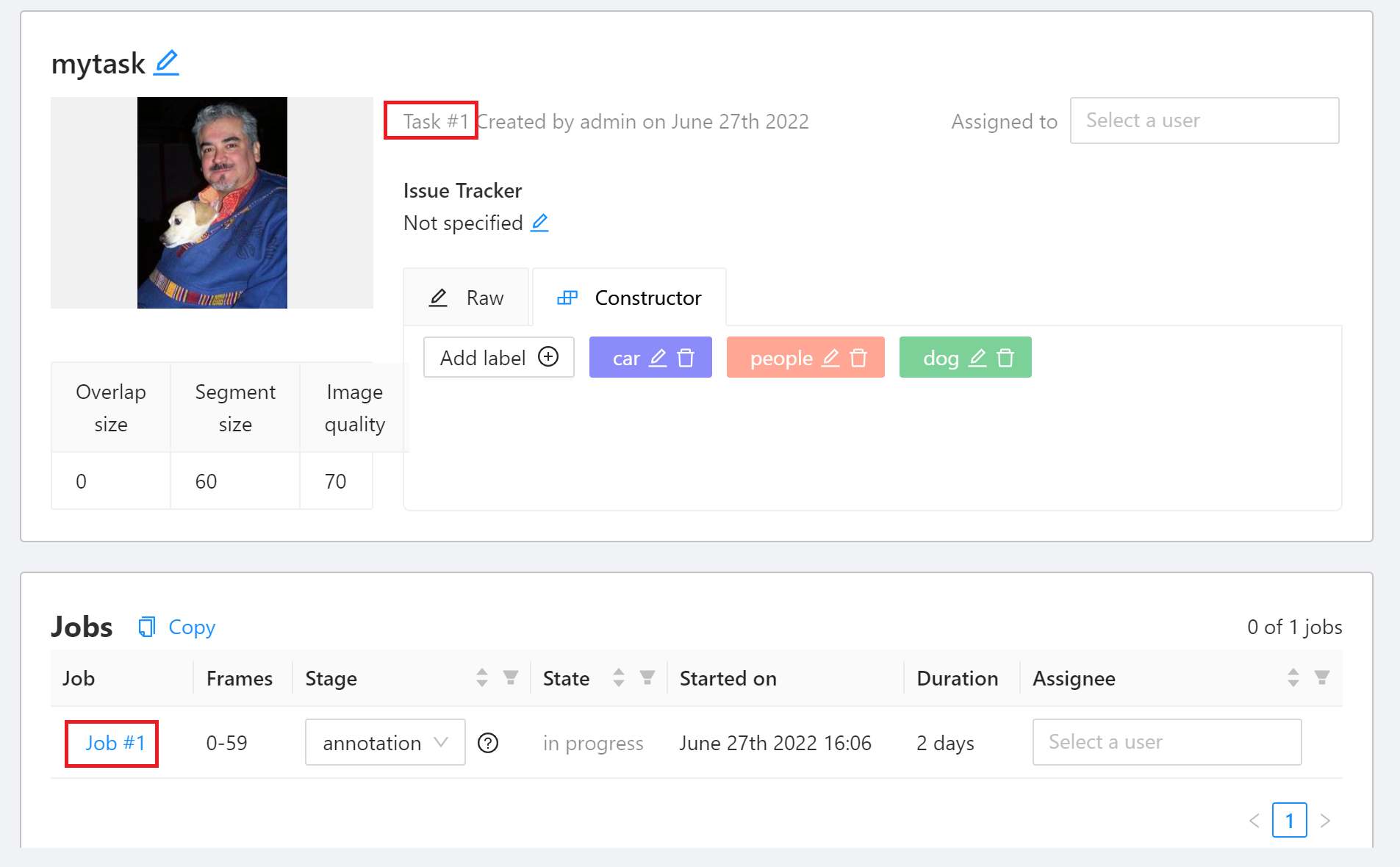
3. **標註**
進入標註頁面後,首先會看到一張欲標註的圖片,若圖中有目標物件,即可依下列步驟進行標註。
1. 點選左側工具列的矩形標註工具「**Draw new rectangle**」。
2. 選擇物件所對應的標籤。
3. 框出目標物件。
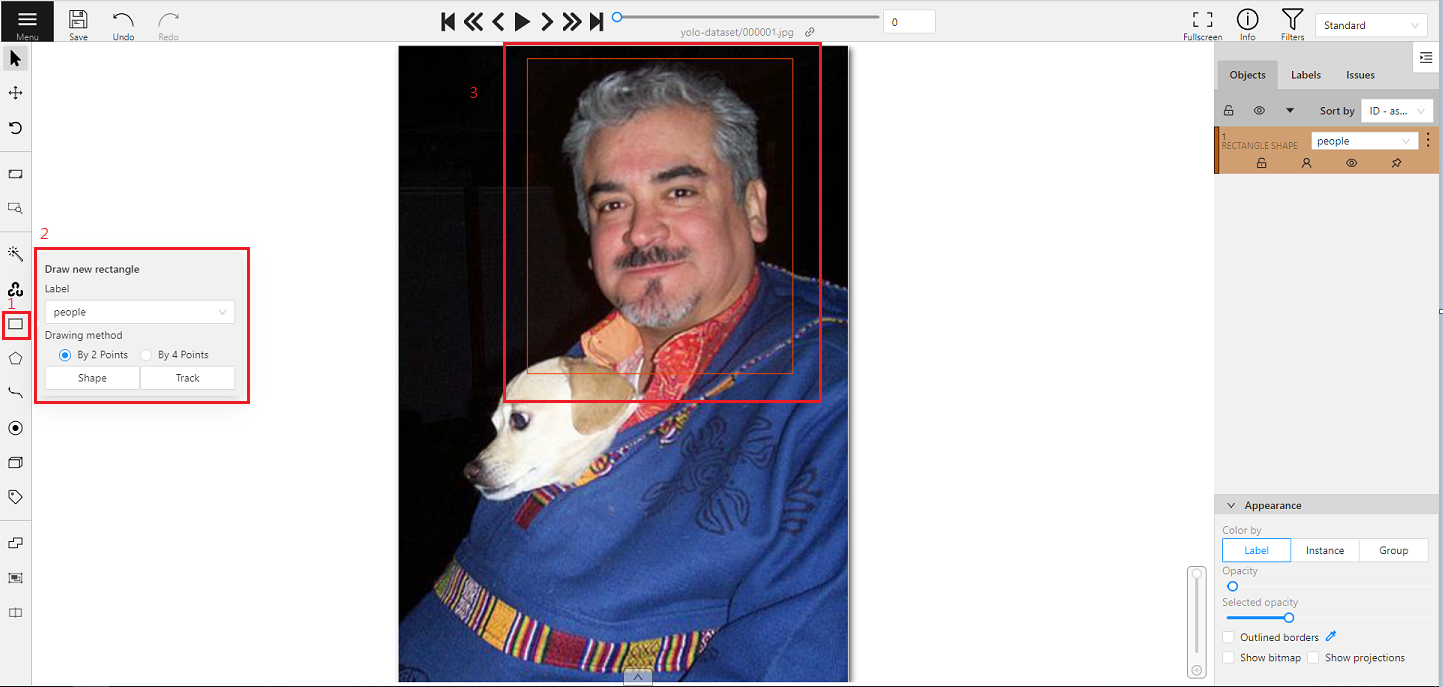
若圖片中存在多個目標物件,請重覆標註動作,直到目標物件皆標註完成。
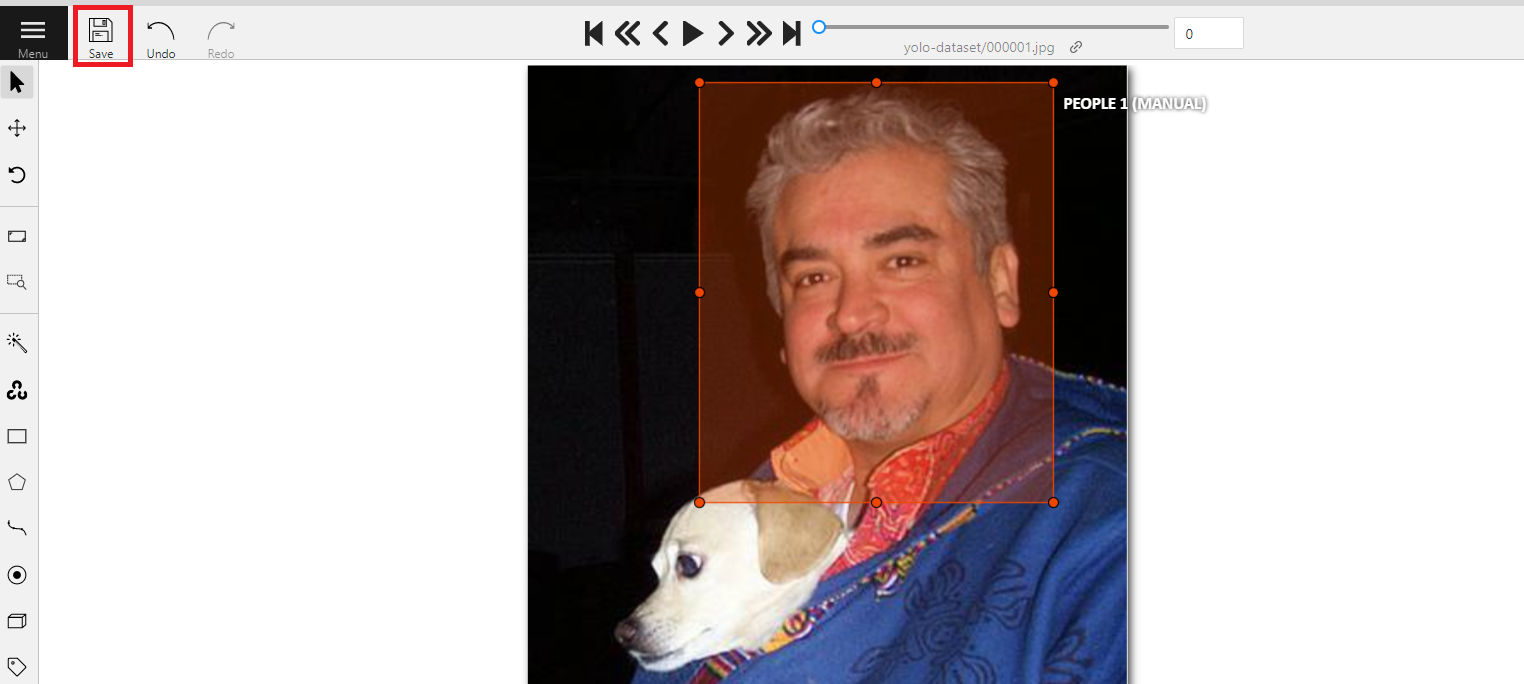
4. **儲存標註結果**
標註數張的圖片後可先點擊左上角「**Save**」儲存標註結果,繼續完成後續的教學。
:::warning
:warning: **注意:** 在標註過程中保持隨時存檔的好習慣,以免因不可抗力之因素,造成做白工。
:::
### 2.4 下載標註資料
標註完成後,可將標註好資料滙出至儲存服務中,再於 AI Maker 中進行模型的訓練。
回到「**Tasks**」頁面,點擊欲下載 Task 右側的 「**Actions**」再點選「**Export task dataset**」。
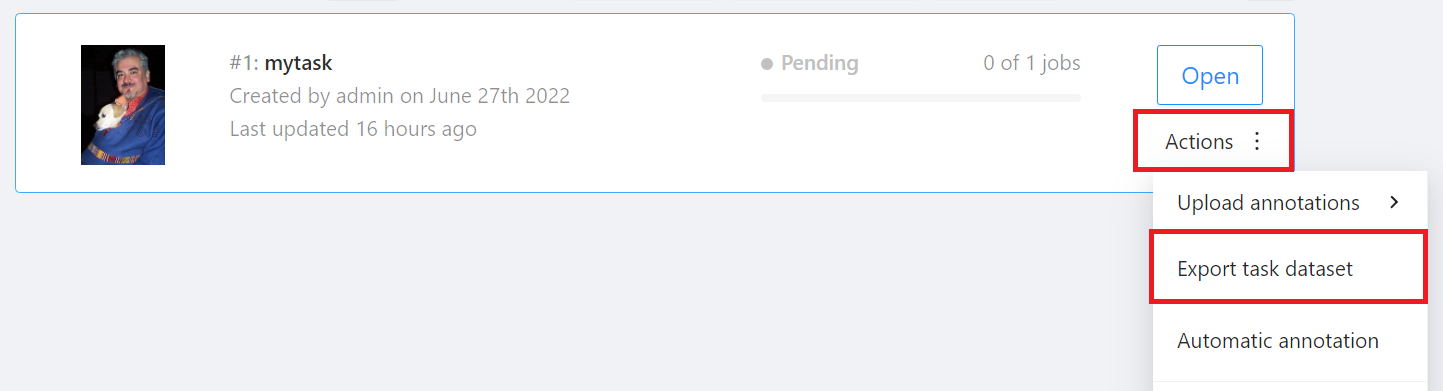
出現 **Export task as a dataset** 視窗後,選取欲滙出的標註資料格式及儲存體。本範例將滙出 **YOLO 1.1** 格式的標註資料到 **`yolo-dataset`** 儲存體中。
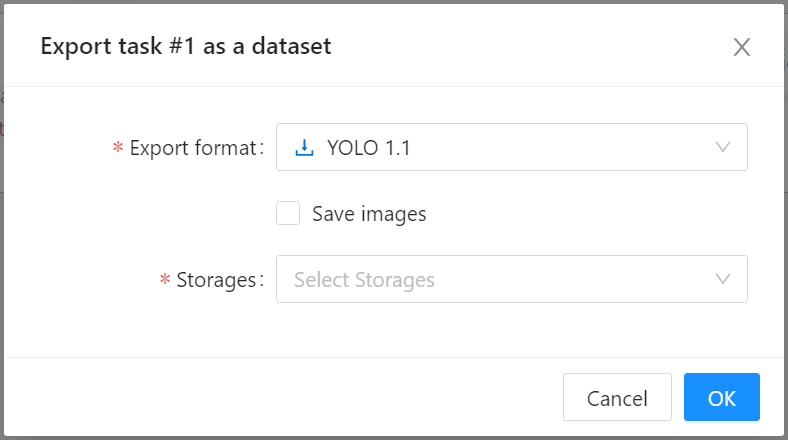
此時回到儲存體 **`yolo-dataset`**,會多出一個 **Export** 的資料夾,下載的標註資料會按照 Task id 及資料格式的路徑存放。本範例 Task id 為 1,格式為 **YOLO 1.1**,所以下載的標註資料會放在 **/Export/1/YOLO 1.1/** 資料夾中。
## 3. 訓練 YOLO 模型
完成資料的 [**準備**](#1-準備資料集) 與 [**標註資料**](#2-標註資料) 後,就可以使用這些資料,來訓練與擬合我們的 YOLO 網路了。
### 3.1 建立訓練任務
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**訓練任務**」,進入訓練任務管理頁面後,切換至「**一般訓練任務**」,接著點擊「**+建立**」,新增一個訓練任務。

#### 3.1.1 一般訓練任務
建立訓練任務可分成五個步驟:
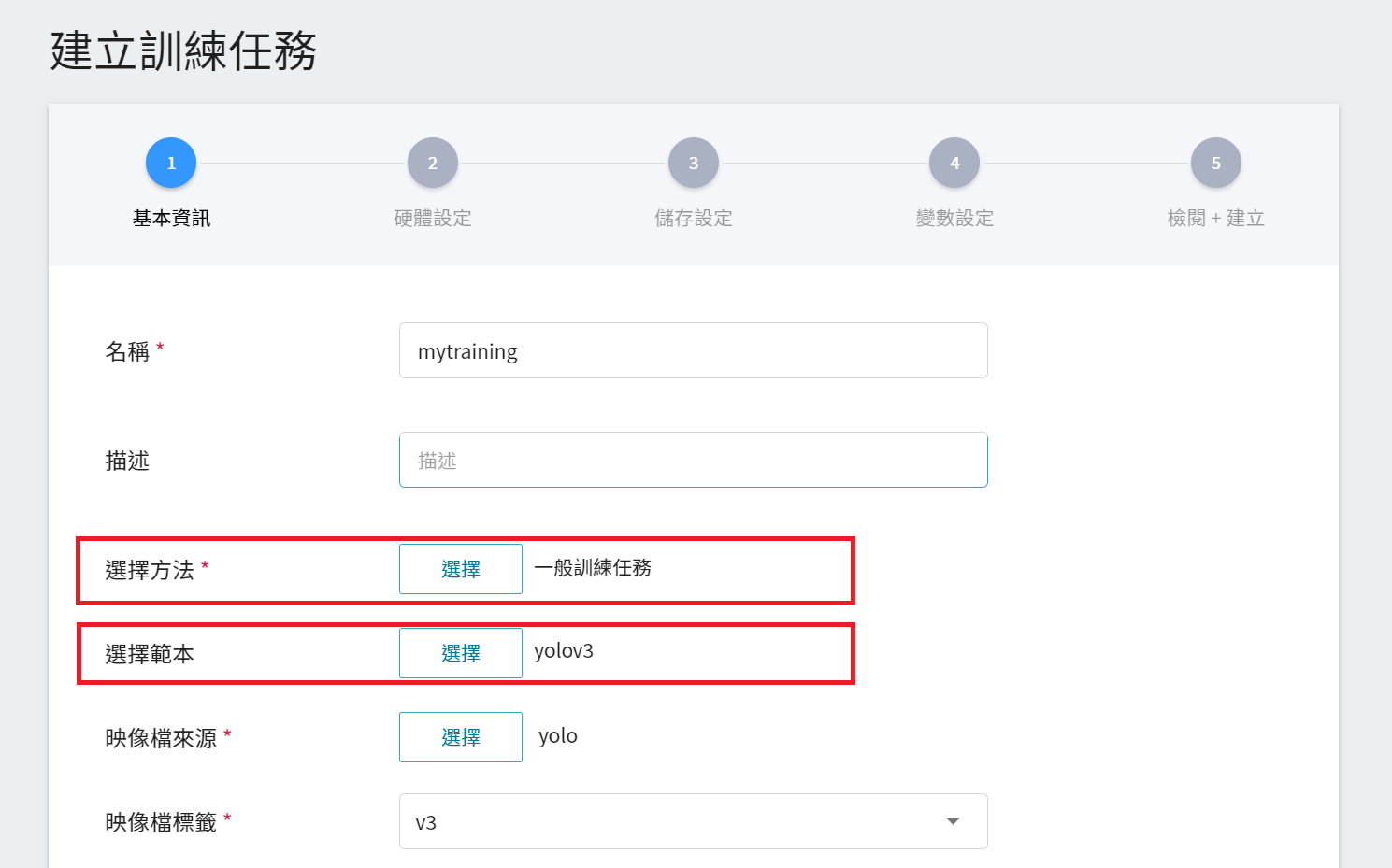
1. **基本資訊**
首先是基本資訊的設定,我們先選擇 **一般訓練任務**,並選用系統內建的 **`yolov3`** 範本,來帶入固定使用的環境變數與設定,設定畫面如下:
2. **硬體設定**
參考目前的可用配額與訓練程式的需求,從列表中選出合適的硬體資源。
3. **儲存設定**
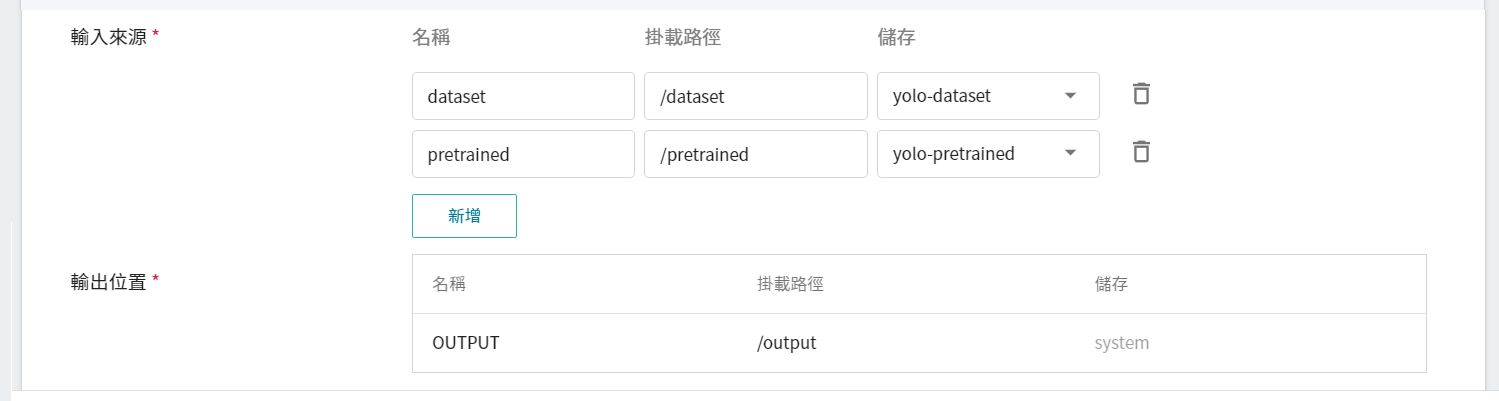
這個階段預設要掛載的儲存體有兩個:
1. **dataset**:是我們存放資料的儲存體 **`yolo-dateset`**。
2. **pretrained**:若您有預訓練的權重檔要導入,請將預訓練權重檔命名為 **`pretrained.weights`** 並放入相對應的儲存體,例如:**`yolo-pretrained`**,再掛載此儲存體;如果您沒有準備預訓練的權重,則可點選後面的刪除圖示,刪除此掛載路徑,AI Maker 會使用系統內建的預訓練權重進行訓練。
<br>
:::info
:bulb: **提示:系統內建的預訓練權重**
為了加快訓練收斂,系統內建使用 COCO datasets 訓練出來的預訓練權重檔 [**yolov3.weights**](https://pjreddie.com/media/files/yolov3.weights " https://pjreddie.com/media/files/yolov3.weights")。
:::
4. **變數設定**
接下來進行環境變數及命令的設定,各欄位的說明如下:
| 欄位名稱 | 說明 |
| ----- | ----- |
| 環境變數 | 輸入環境變數的名稱及數值。這邊的環境變數除包含訓練執行的相關設定外,也包括了訓練網路所需的參數設定。 |
| 目標參數 | 訓練結束,會回傳一值作為最終結果,這裡為該回傳值設定名稱及目標方向。例如:若回傳的數值為準確率,則可命名為 accuracy,並設定其目標方向為最大值;若回傳的值為錯誤率,則命名為 error,其方向為最小值。 |
| 命令 | 輸入欲執行的命令或程式名稱。例如:`python train.py`。 |
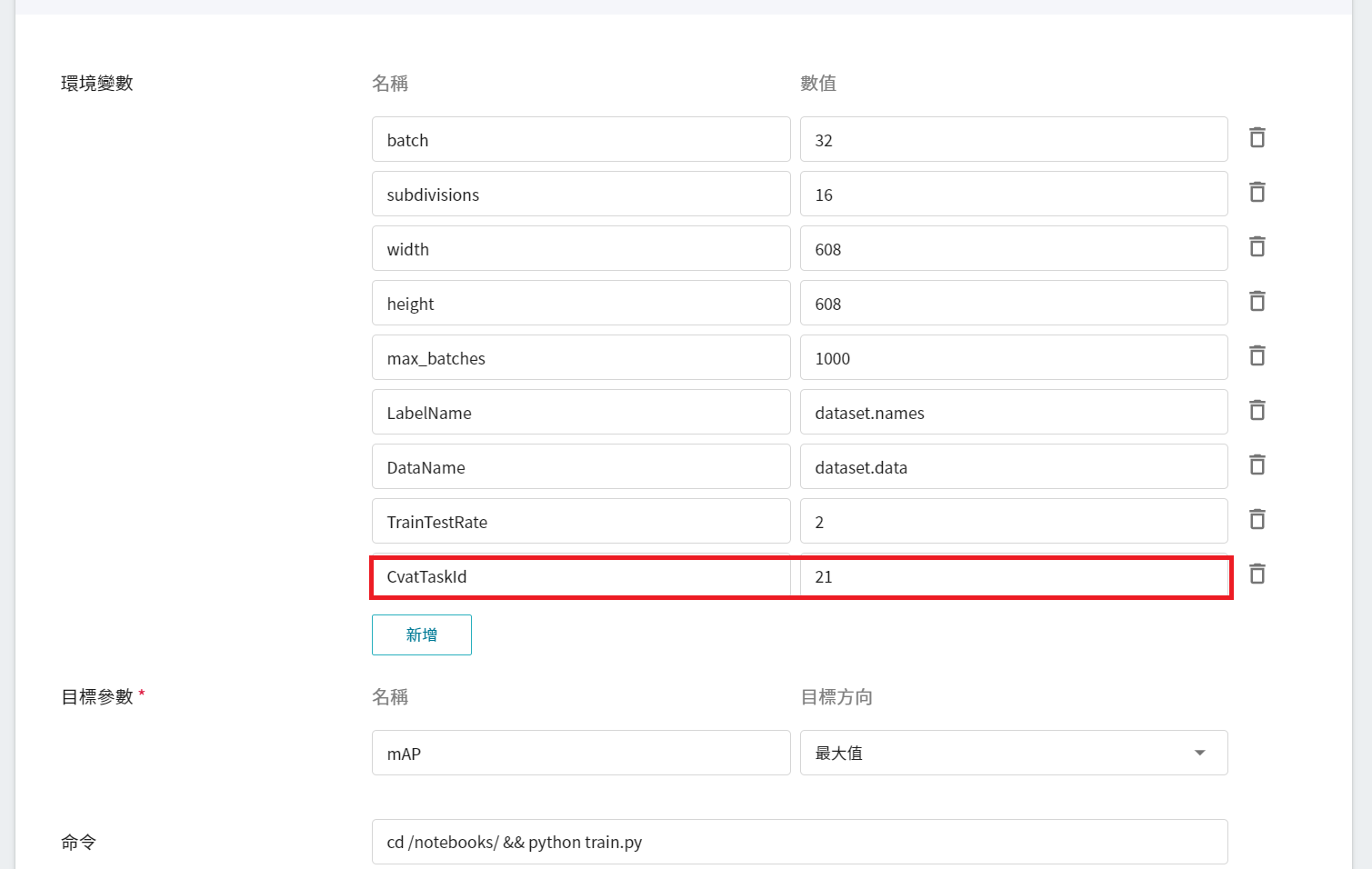
不過因為我們在基本資訊填寫時,已經套用了 **`yolov3`** 範本,這些慣用的指令與參數會自動帶入,但 CvatTaskId 的值需改成步驟 [**2.4 下載標註資料**](#24-下載標註資料) 中下載標註資料的 TaskId 值。
環境變數的設定值可依照您的開發需求進行調整,在此說明各環境變數:
| 變數 | 預設值 | 說明 |
| ----- | -------| ---- |
|batch|32|即 batch size,每個 batch 的大小值,每一個 batch 更新一次模型。|
| subdivisions|16 |根據 GPU 記憶體,調整每個 batch 需要切割成幾份來跑,切割份數越大,所需 GPU 記憶體越小,訓練速度越慢。|
|width|608|設置圖片進入網絡的寬度。|
|height|608|設置圖片進入網絡的高度。|
| max_batches | 1000 | 這次的訓練最多會跑幾個 batch 數目,第一次訓練的話,建議每多一種欲辨識的類別就多 1000 次|
|LabelName|dataset.names | 定義設定檔的名稱;內容為 label 的列表。|
|DataName| dataset.data | 定義設定檔的名稱;內容為 label 數目和各個設定檔以及 weights 目錄。|
|TrainTestRate|2|訓練集與測試集的比例。<br> 2 代表每兩張圖片就有一張當測試集。 |
|CvatTaskId |==CVATTASKID==|請將此參數值修改成欲使用 **CVAT** 標註資料的 **Task ID**,Task ID 可至 CVAT 的 Tasks 頁面查詢。若您使用自有的資料集及標註資料,請設定為 **none**。|
5. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
#### 3.1.2 Smart ML 訓練任務
在 [**上一小節 3.1.1**](#311-一般訓練任務) 中介紹的是 **一般訓練任務** 的建立,這邊來介紹 **Smart ML 訓練任務** 的建立,您可以只選擇任一種訓練方法或比較兩種訓練方法的差異。兩者流程大致相同,但會多出額外參數需要設定,在此僅說明多出的變數:
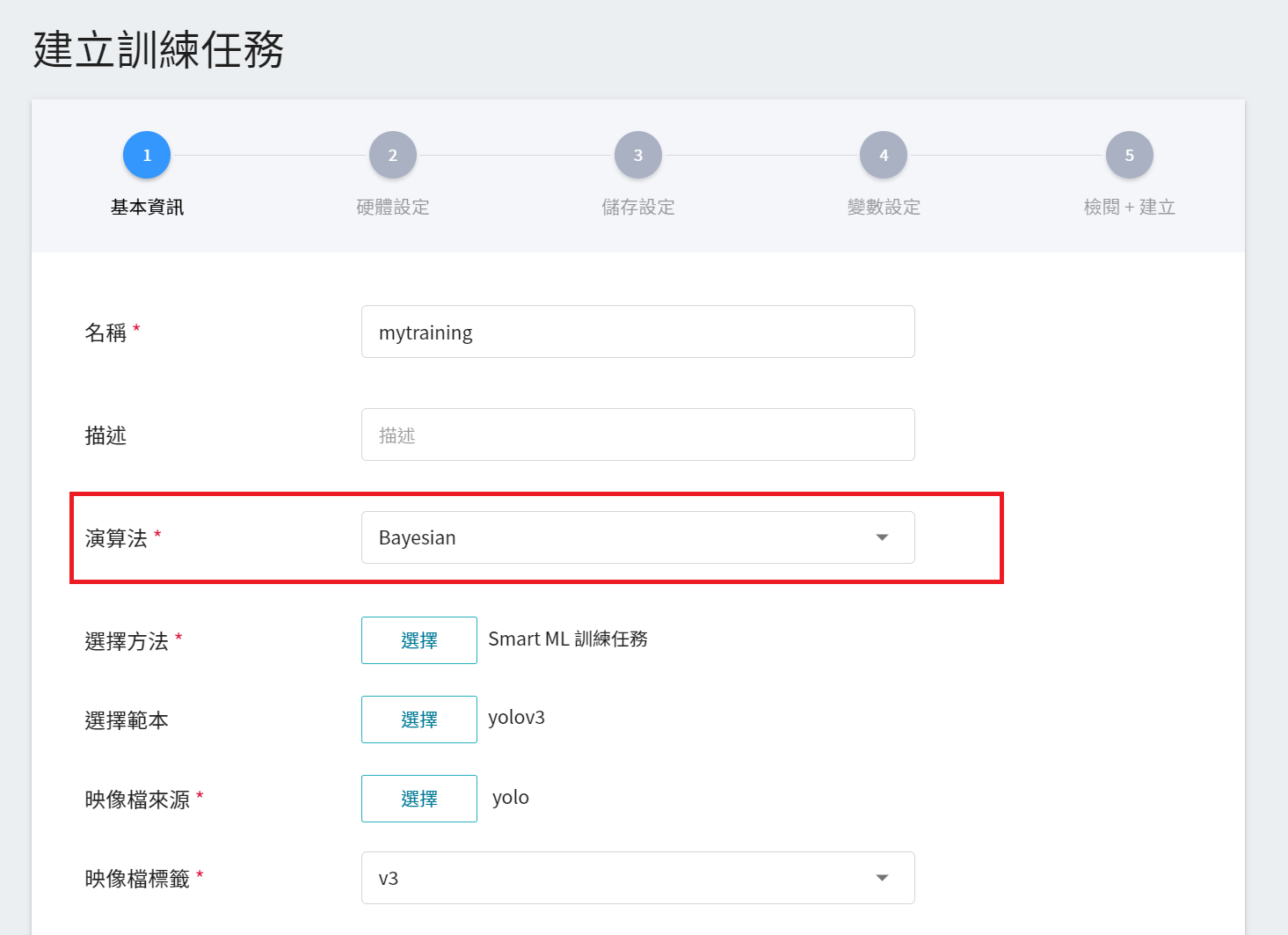
1. **基本資訊**
當設定方法為 Smart ML 訓練任務後,會進一步要求挑選 Smart ML 訓練任務所要使用的 **演算法**,可選擇的演算法如下:
- **Bayesian**:根據環境變數、超參數的設置範圍和訓練的次數,能有效地執行多項訓練任務,以找到更好的參數組合。
- **TPE**:Tree-structured Parzen Estimator,與 Bayesian 演算法類似,可優化高維度超參數的訓練任務。
- **Grid**:經驗豐富的機器學習使用者可以指定超參數的多個值,系統將根據超參數列表的組合執行多個訓練任務,並獲得計算結果。
- **Random**:在指定範圍內隨機選擇用於訓練任務的超參數。
2. **變數設定**
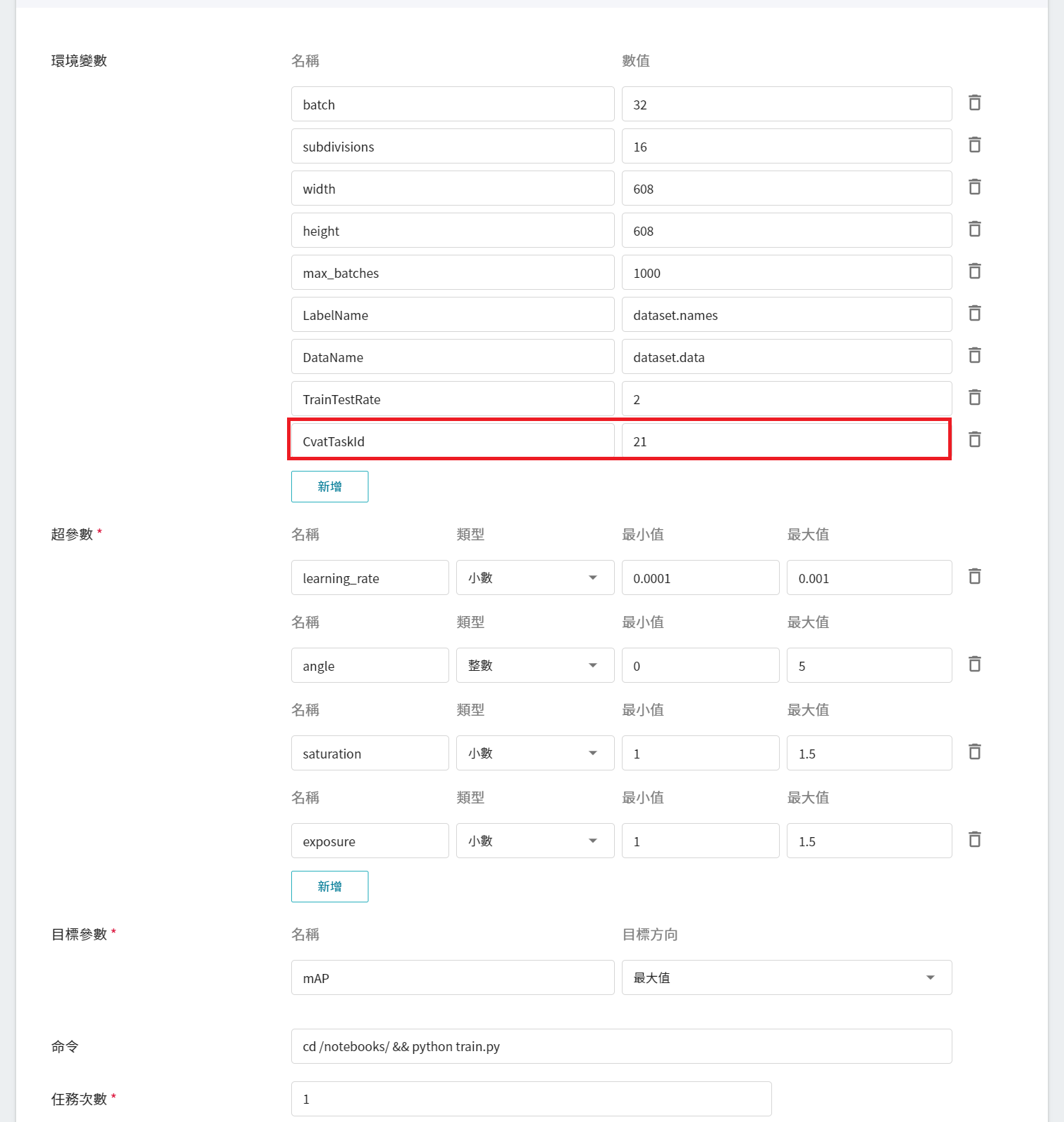
在變數設定的頁面中,會多出 **超參數** 與 **任務次數** 的設定,其中:
- **超參數**
這是告訴任務,有哪些參數需要進行嘗試。每個參數在設定時,須包含參數的名稱、類型及數值(或數值範圍),選擇類型後(整數、小數和陣列),請依提示輸入相對的數值格式。
| 名稱 | 數值範圍 | 說明 |
| ---- | ---- | ---- |
| learning_rate | 0.0001 ~ 0.001 | **學習速度** 的參數,在模型學習初期時,可以設定大一點,加速訓練。在學習後期,需要設定小一點,避免發散。 |
| angle | 0 ~ 5 | 透過調整圖片的 **角度**,設定為 5 表示圖片將會旋轉 -5 ~ 5 度來得到更多的樣本數。|
| saturation | 1 ~ 1.5 | 透過調整圖片的 **飽和度**,設定為 1.5 表示飽和度可以從 1 ~ 1.5 中調整圖片來得到更多的樣本數。|
| exposure | 1 ~ 1.5 | 透過調整圖片的 **曝光度**,設定為 1.5 表示曝光度可以從 1 ~ 1.5 中調整圖片來得到更多的樣本數。 |
當然 **超參數** 中部份的訓練參數是可以移動至 **環境變數**;反之亦然。若您想固定該參數,則可將該參數從 **超參數** 區域中移除,新增至 **環境變數** 區域,並給定固定值;反之,若想將該參數加入嘗試,則將它從環境變數中移除,加入至下方的超參數區域。
- **任務次數**
即訓練次數設定,讓訓練任務執行多次,以找到更好的參數組合。
### 3.2 啟動訓練任務
完成訓練任務的設定後,回到訓練任務管理頁面,可以看到剛剛建立的任務。
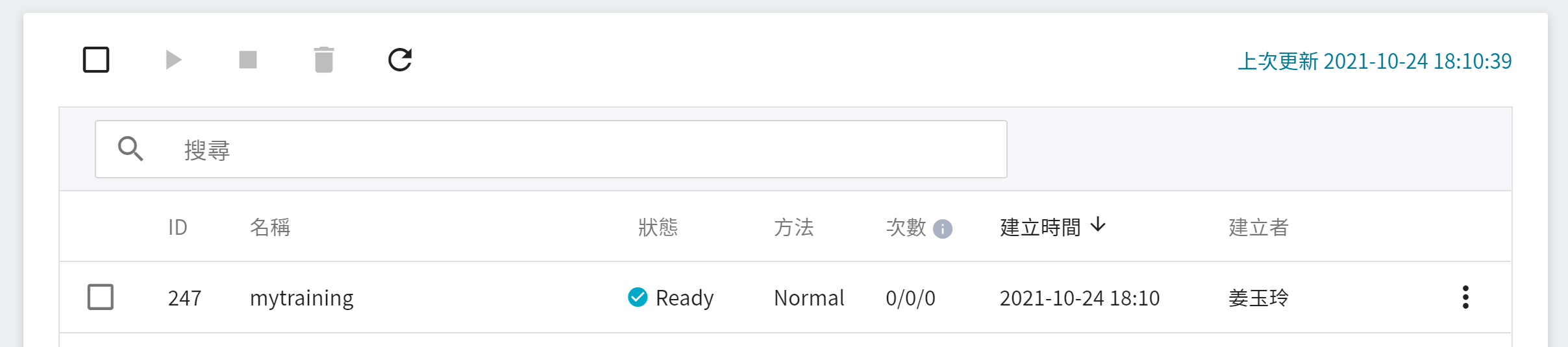
點擊該任務,可檢視訓練任務的詳細設定。在命令列中,有 **儲存(儲存為範本)**、**啟動**、**停止**、**編輯**、**删除** 及 **重新整理** 6 個圖示。若此時任務的狀態顯示為 **`Ready`**,即可點擊 **啟動**,執行訓練任務。
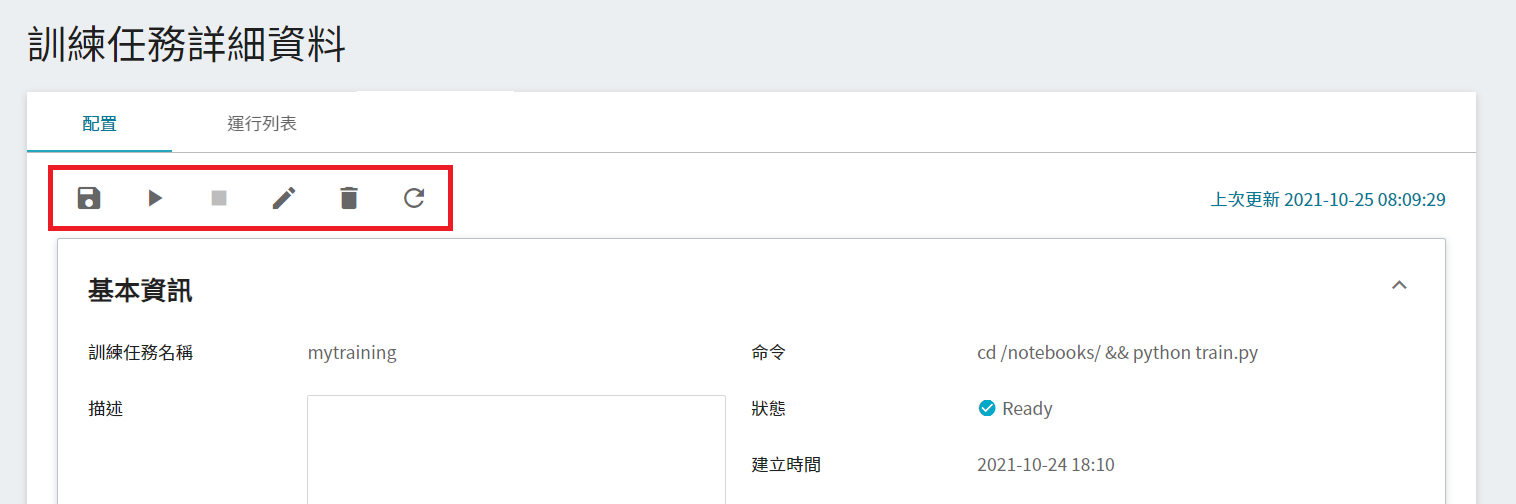
啟動後,點擊上方的「**運行列表**」頁籤,可以在列表中查看該任務的執行狀況與排程。在訓練進行中,可以點擊任務右方清單中的 **查看日誌** 或 **查看詳細狀態**,來得知目前任務執行的詳細資訊。
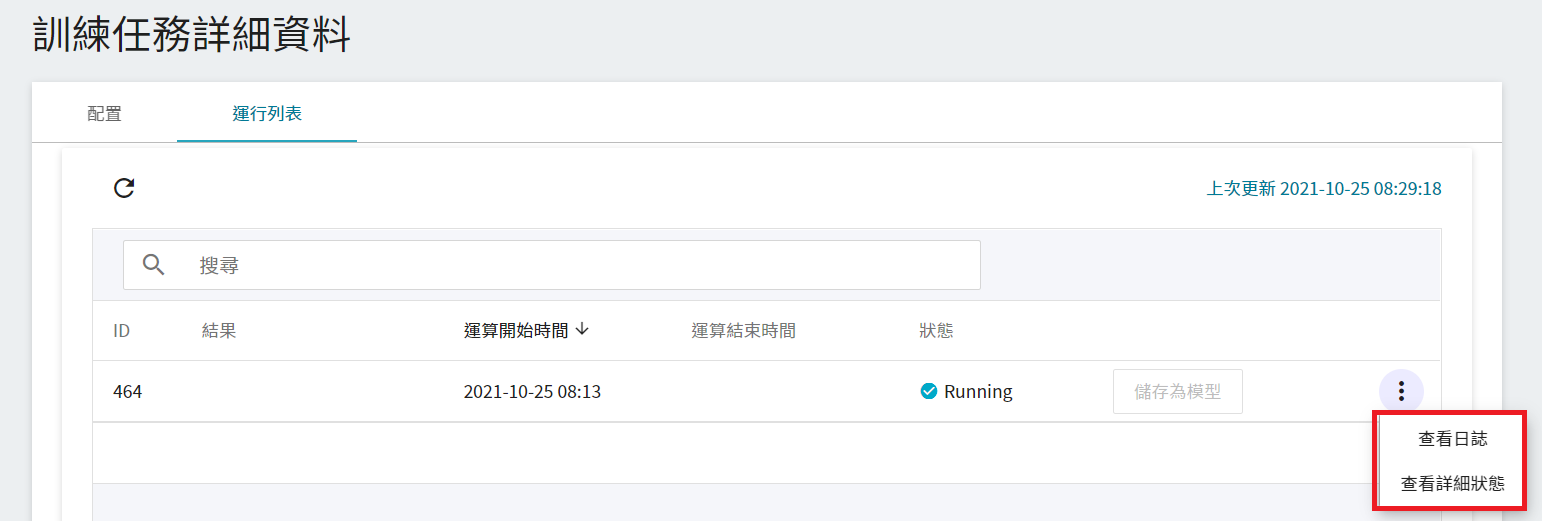
若是在進行 Smart ML 訓練任務,清單中會多出 **查看超參數**,此選項可以讓您查看此訓練任務所使用的參數組合。
### 3.3 檢視訓練結果並儲存模型
訓練任務運算完成後,在運行列表中的該工作項目會變成 **`Completed`**,並顯示運算結果。
:::info
:bulb:**提示:將訓練結果傳回至 AI Maker**
透過 AI Maker 提供的函數可將訓練結果傳回至 AI Maker,本範例教學所使用的訓練程式已包含此段程式,若是使用自行開發的程式,請參考以下範例:
* **ai.sendUpdateRequest({result})**:回傳訓練結果(單一值),例如 error_rate 或 accuracy,型態必須為 int 或 float ( Numpy 型態之 int,float 不可接受)。
範例如下:
```=
import AIMaker as ai
// your code
ai.sendUpdateRequest({result})
```
:::
觀察列表中的分數,從中挑選出符合預期結果,在將其儲存至模型儲存庫中;若無符合預期結果,則重新調整環境變數與超參數的數值或數值範圍。
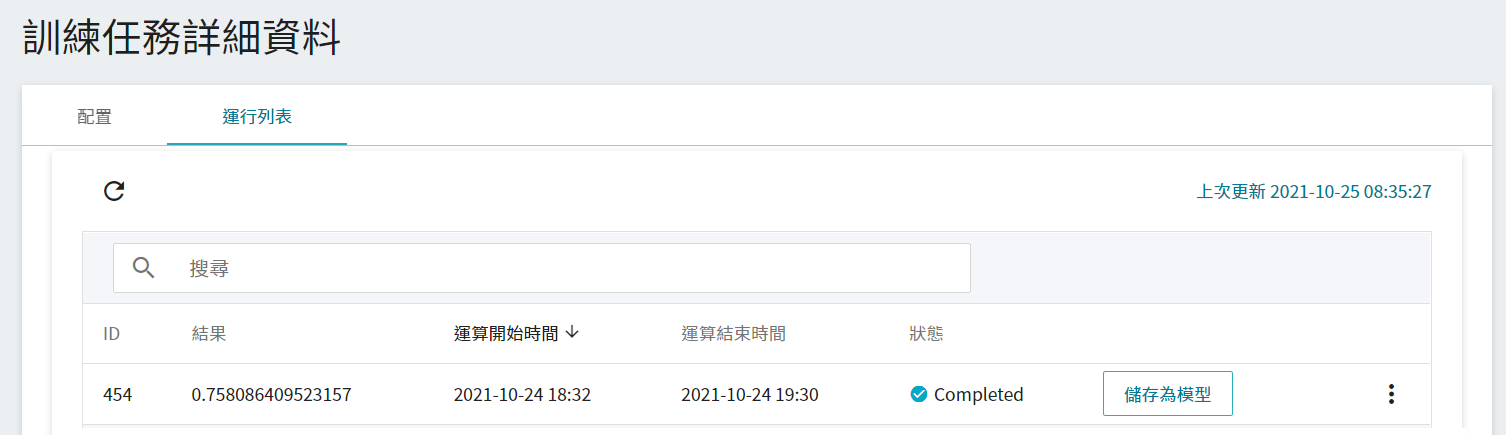
接下來介紹如何將達到預期的模型儲存至模型儲存庫。
1. **點選儲存為模型**
點擊欲儲存的訓練結果右側的「**儲存為模型**」按鈕。
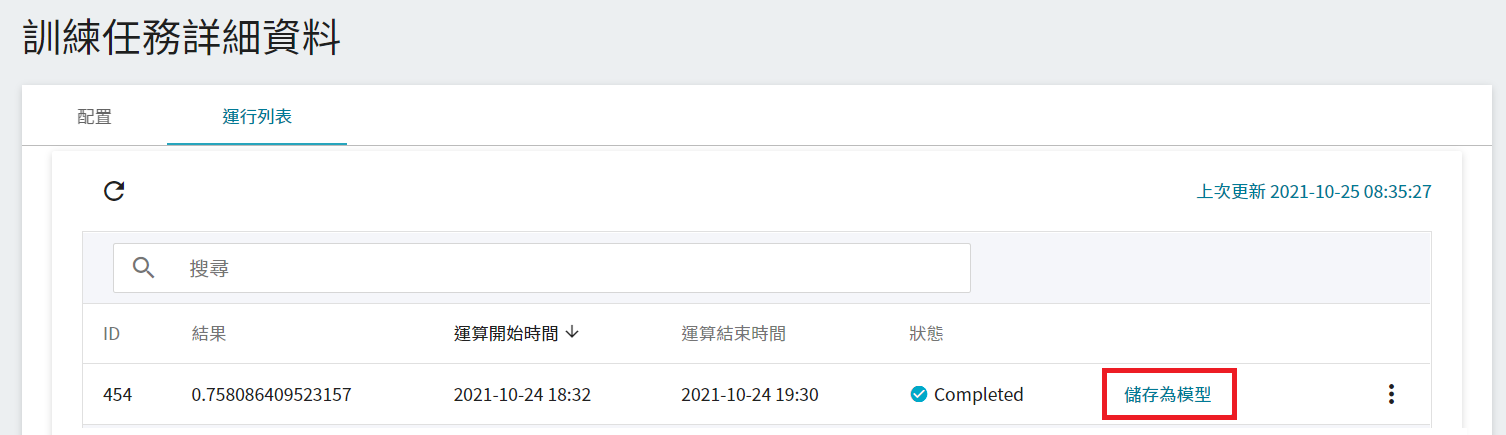
2. **輸入模型名稱與版號**
接著會出現一個對話框,請依照指示輸入模型名稱和版本,完成後點擊確定。
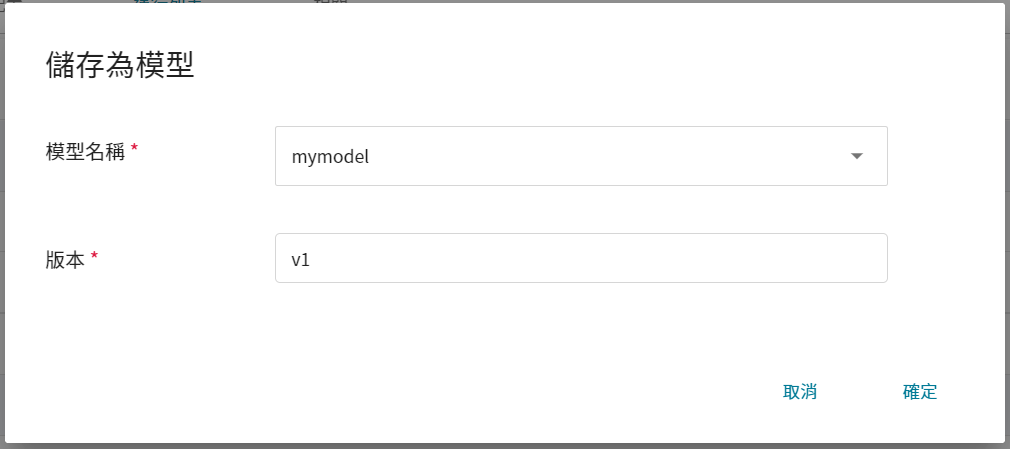
3. **查看模型**
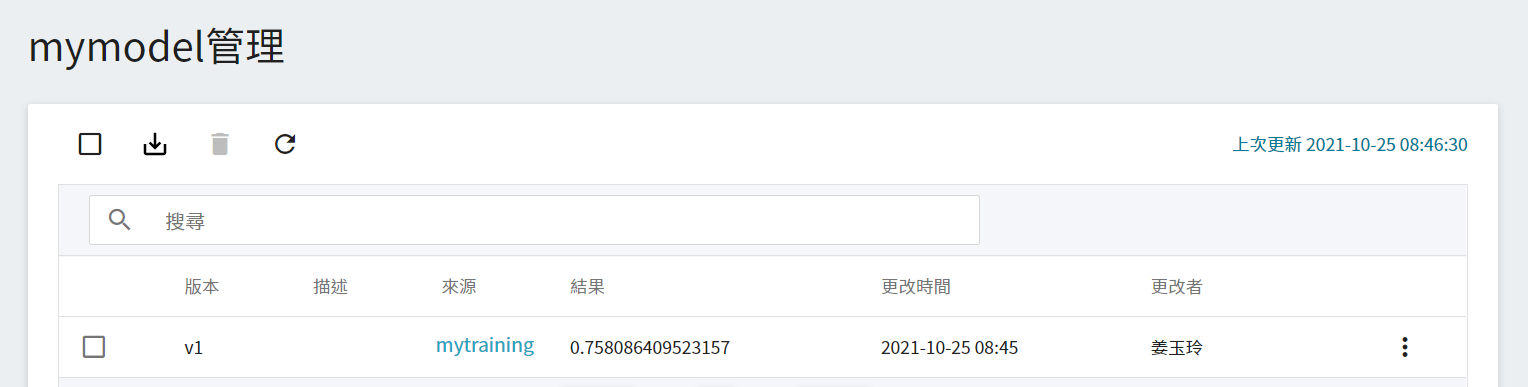
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**模型**」,進入模型管理頁面後,可在列表中找到該模型。
點擊該模型進入模型的版本列表,可以看到此模型的版本、描述、來源、結果... 等資訊。
## 4. 建立推論服務
當您訓練好 YOLO 網路後,並儲存訓練好的模型,這時您可藉由 **推論** 功能將其部署至應用程式或服務以執行推論。
### 4.1 建立推論
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**推論**」,進入推論管理頁面,並按下「**+建立**」,建立一個推論服務。推論服務的建立步驟說明如下:
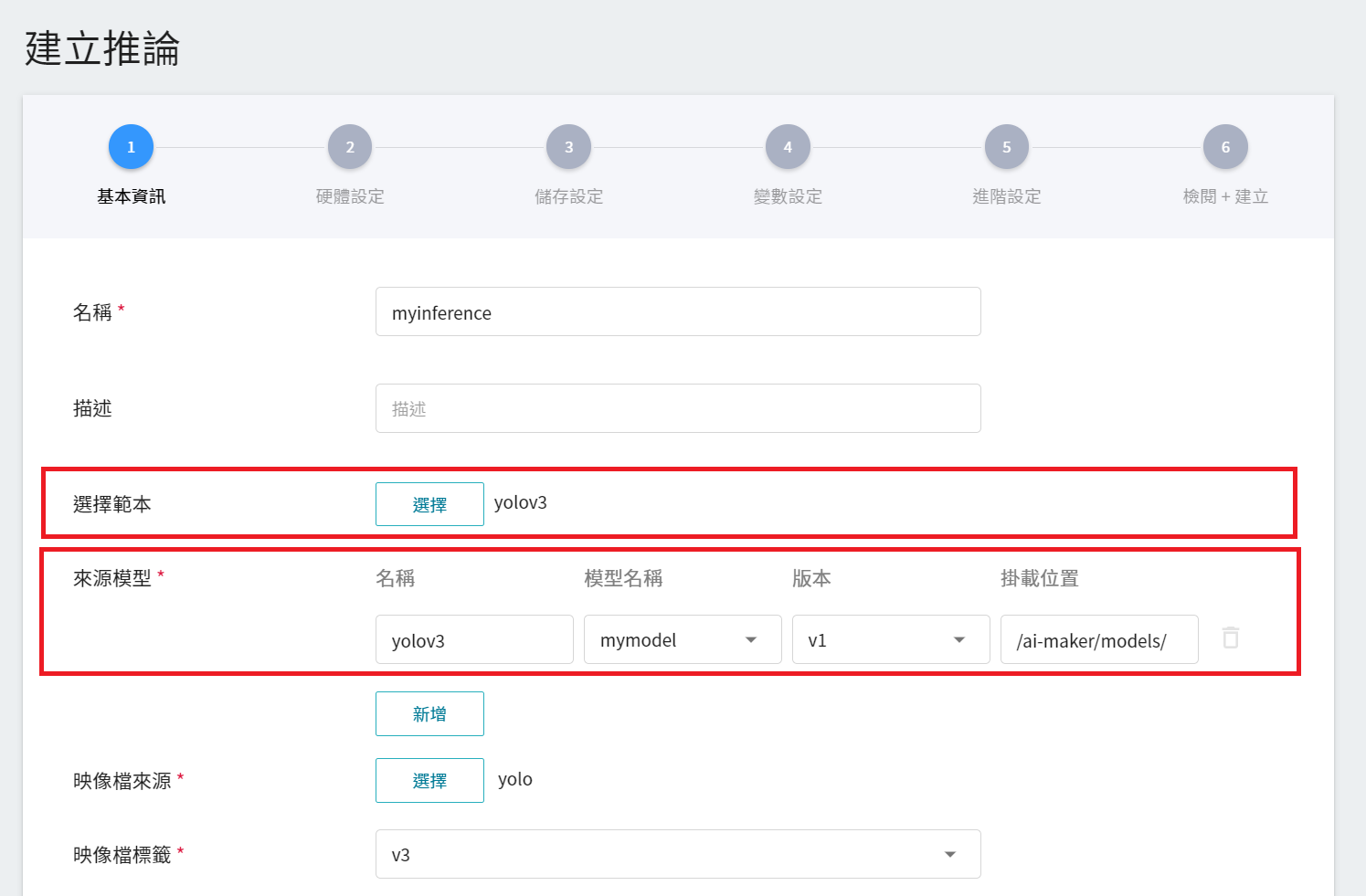
1. **基本資訊**
與訓練任務的基本資訊的設定相似,我們也是使用 **`yolov3`** 的推論範本,方便快速設定。不過,所要載入的模型名稱與版號仍須手動設定:
- **名稱**
載入後模型的檔案名稱,與程式進行中的讀取有關,這值會由 `yolov3` 推論範本設定。
- **模型名稱**
所要載模型的名稱,即我們在 [**3.3 檢視訓練結果並儲存模型**](#33-檢視訓練結果並儲存模型) 中所儲存的模型。
- **版本**
所要載入模型的版號,亦是 [**3.3 檢視訓練結果並儲存模型**](#33-檢視訓練結果並儲存模型) 中所設定的版號。
- **掛載位置**
載入模型所在位置,與程式進行中的讀取有關,這值會由 **`yolov3`** 推論範本設定。
2. **硬體設定**
參考目前的可用配額與訓練程式的需求,從列表中選出合適的硬體資源
3. **儲存設定**
此步驟無須設定。
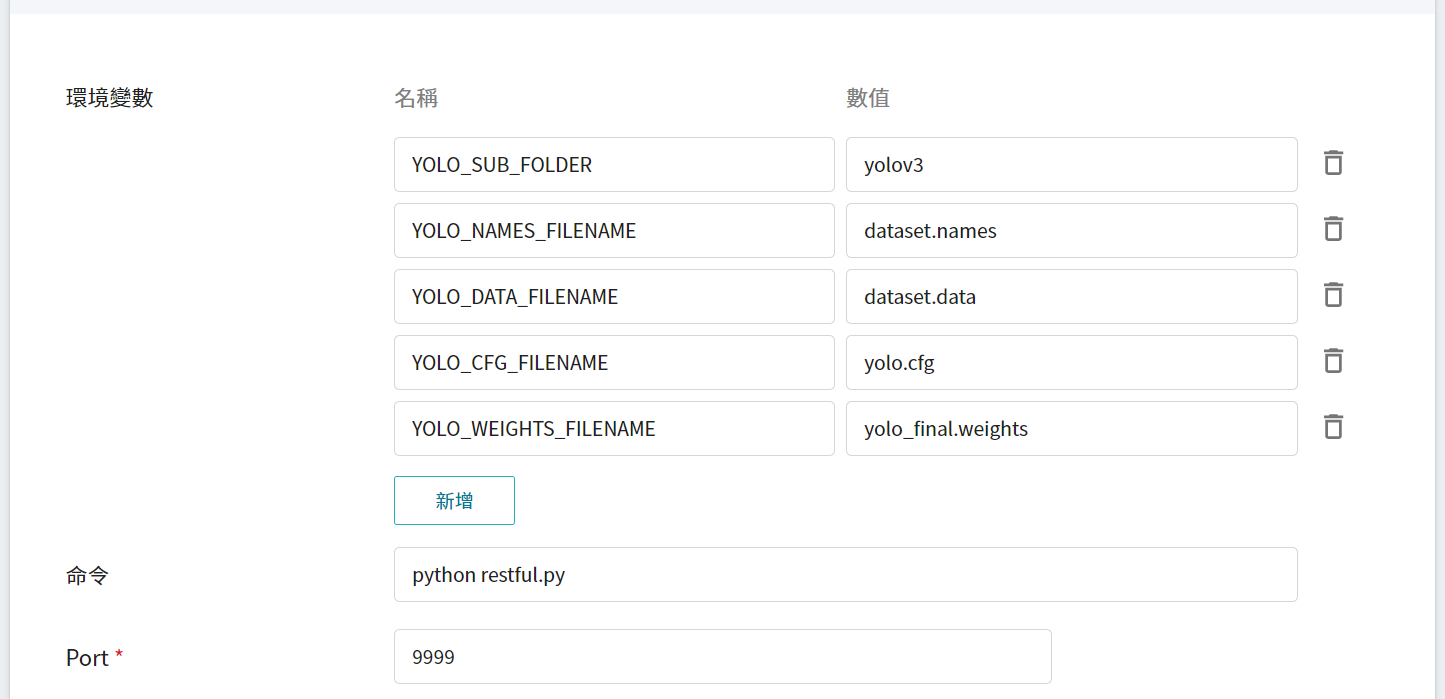
4. **變數設定**
在變數設定頁面,這些指令與參數,會在套用 **`yolov3`** 的範本時自動帶入。
5. **進階設定**
* **監控資料**
此監控用途在於觀測推論服務一段時間內,API 呼叫次數以及推論結果所呈現的統計資訊。
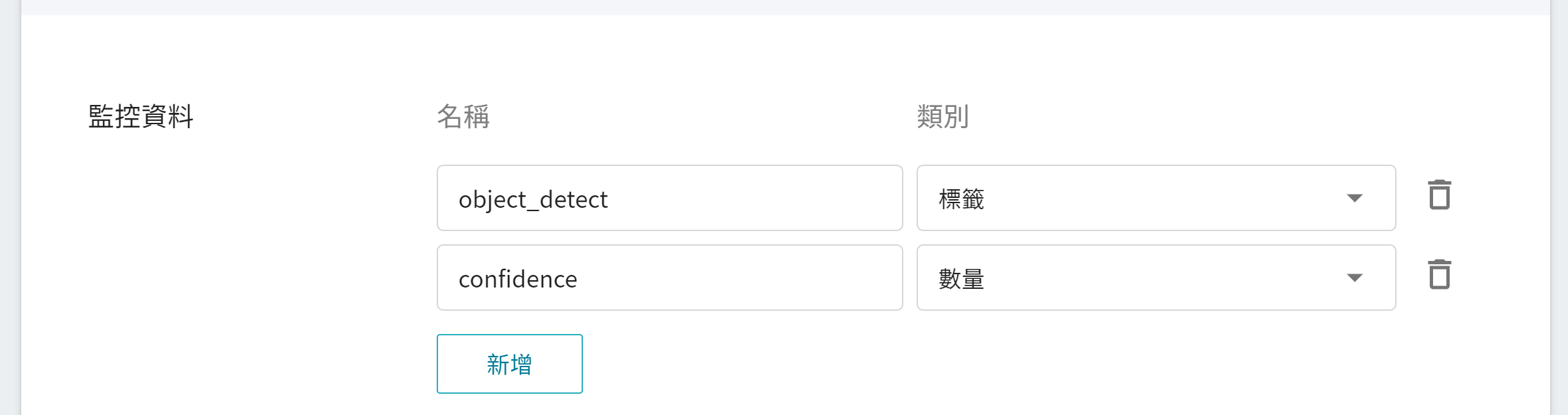
| 名稱 | 類別 |說明 |
|-----|-----|------------|
| object_detect | 標籤 | 在指定的時間區間內,該物件被偵測出所累計的總次數。<br>換言之,可看出各類別在一段時間內的分佈狀況。<br>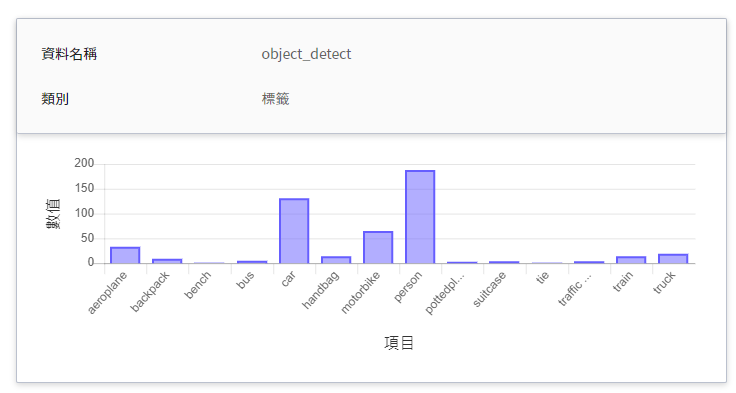|
| confidence | 數量 | 在某個時間點呼叫推論 API 一次,該物件被偵測出的信心值。<br>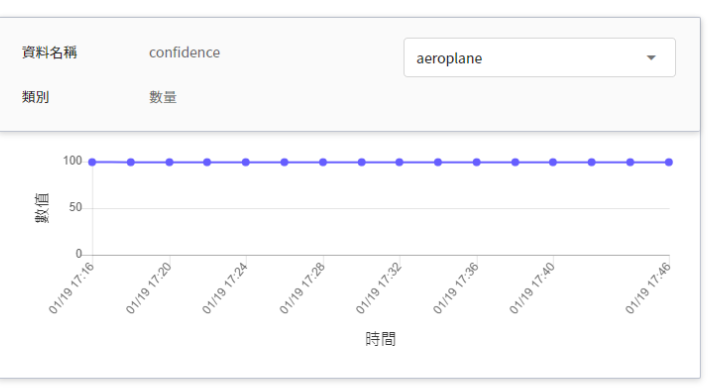|
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
### 4.2 進行推論
完成推論服務的設定後,回到推論管理頁面,可以看到剛剛建立的任務,點擊該列表,可檢視該服務的詳細設定。當服務的狀態顯示為 **`Ready`** 時,即可以開始連線到推論服務進行推論。
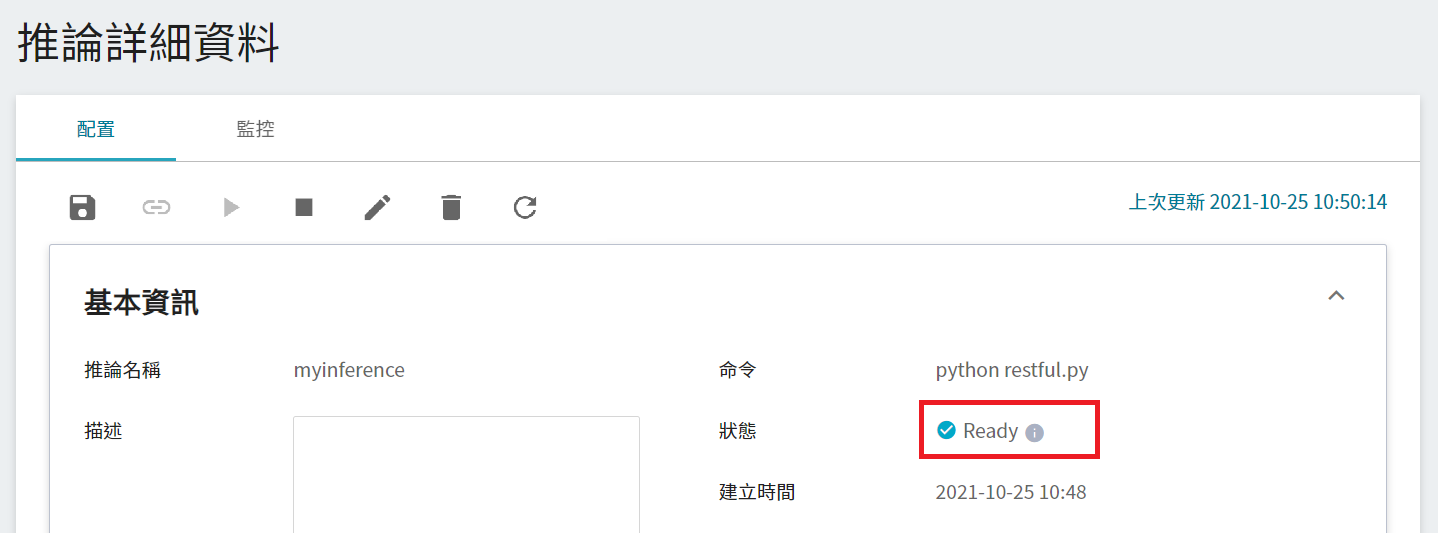
在詳細設定中值得注意的是「**網址**」,由於目前推論服務為了安全性的考量沒有開放對外的服務埠,但我們可以透過「**容器服務**」來跟我們的已經建立好的推論服務溝通,溝通的方式就是透過推論服務提供的「**網址**」,在下一章節會說明如何使用。
:::info
:bulb: **提示:** 文件中的網址僅供參考,您所取得的網址可能會與文件中的不同。
:::
若要查看推論監控,可點擊「**監控**」頁籤,即可在監控頁面看到相關資料,如下圖所示。
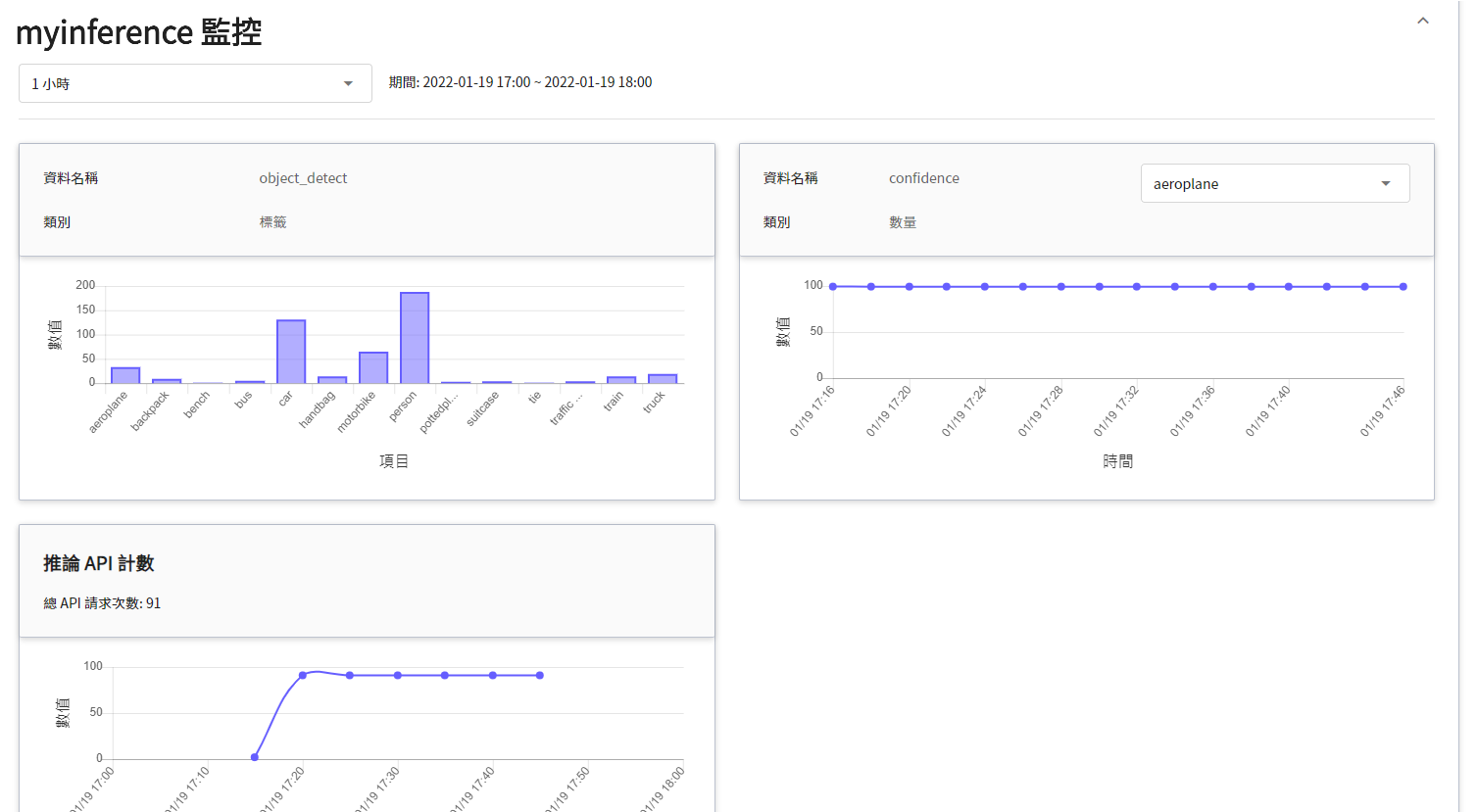
點選期間選單可篩選特定期間呼叫推論 API 的統計資訊,例如:1 小時、3 小時、6 小時、12 小時、1 天、7 天、14 天、1 個月、3 個月、6 個月、1 年或自訂。

:::info
:bulb: **提示:關於觀測期間的起始與結束時間**
例如當前時間為 15:10,則:
- **1 小時** 的範圍是指 15:00 ~ 16:00(並非指過去一小時 14:10 ~ 15:10)
- **3 小時** 的範圍是指 13:00 ~ 16:00
- **6 小時** 的範圍是指 10:00 ~ 16:00
- 以此類推
:::
## 5. 進行影像辨識
在這一章節,我們將說明如何使用 Jupyter Notebook 來調用推論服務。
### 5.1 啟動 Jupyter Notebook
這節主要介紹如何使用「**容器服務**」來啟動 Jupyter Notebook。
#### 5.1.1 **建立容器服務**
從 OneAI 服務列表選擇「**容器服務**」,在容器服務管理頁面點擊「**+建立**」。
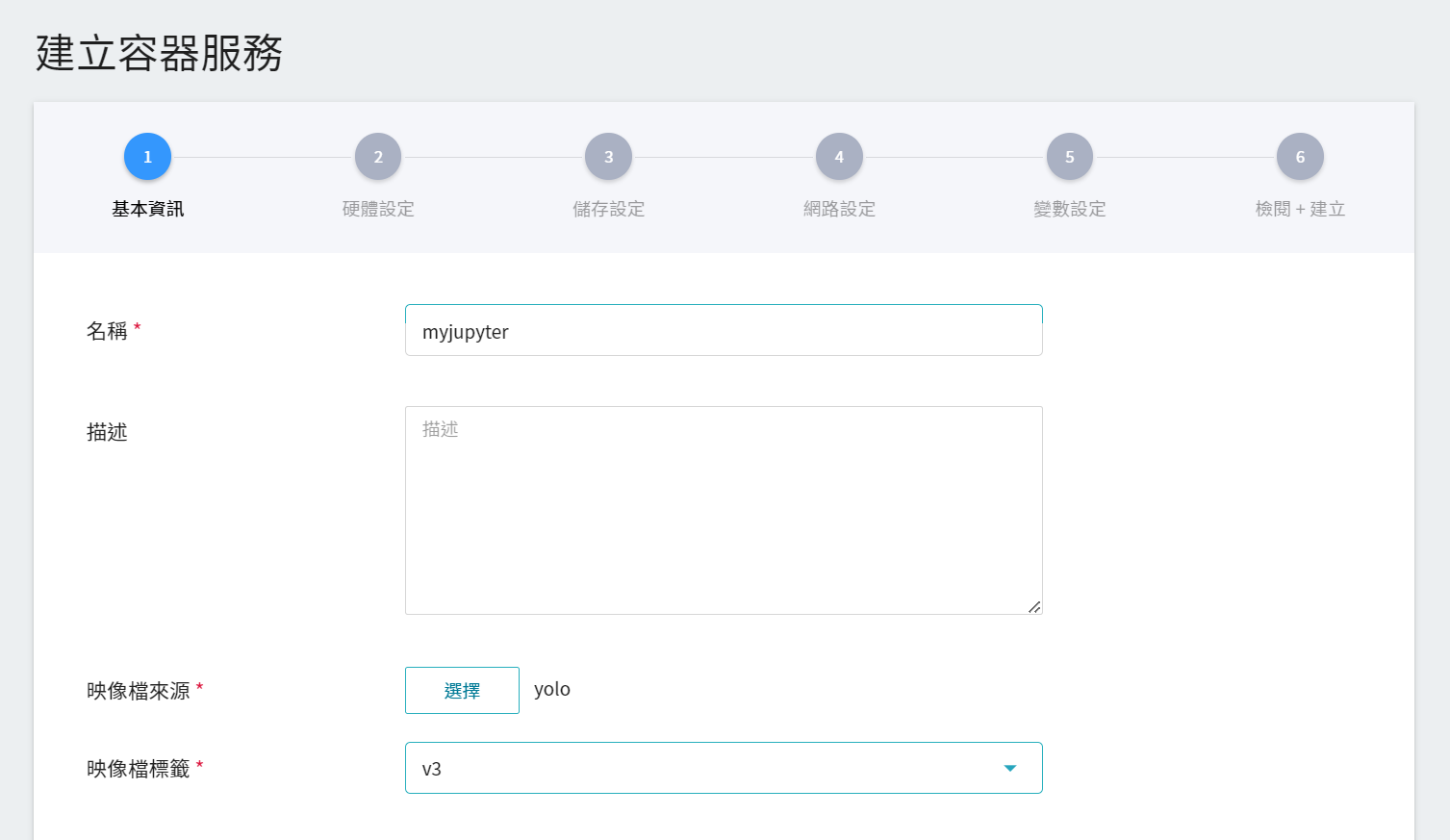
1. **基本資訊**
在建立容器服務時,可以直接挑選 **`yolo:v3`** 映像檔,在這份映像檔中我們已經提供 Jupyter Notebook 的相關環境。
2. **硬體設定**
參考目前的可用配額與程式需求,從列表中選出合適的硬體資源,此處可以不用配置 GPU。
3. **儲存設定**
此步驟可略過。
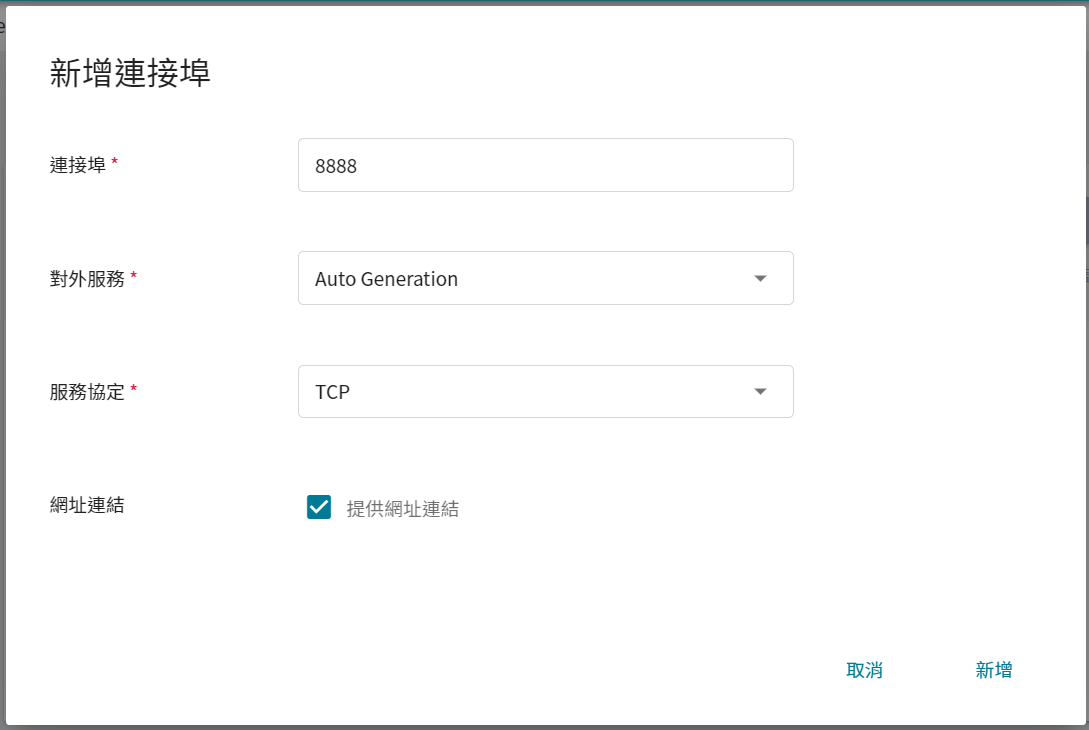
4. **網路設定**
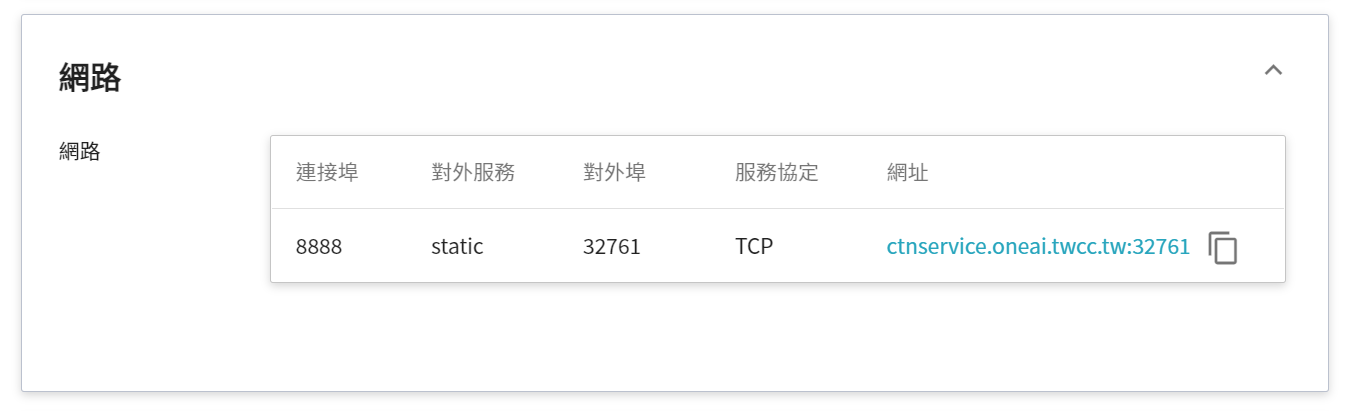
在使用 Jupyter Notebook 服務時,預設會運行在 `8888` 的連接埠,為了能順利從外部尋訪使用 Jupyter Notebook,因此需要設定對外公開的服務埠,這邊選擇讓它自動產生對外服務的 Port,並且勾選提供網址連結。
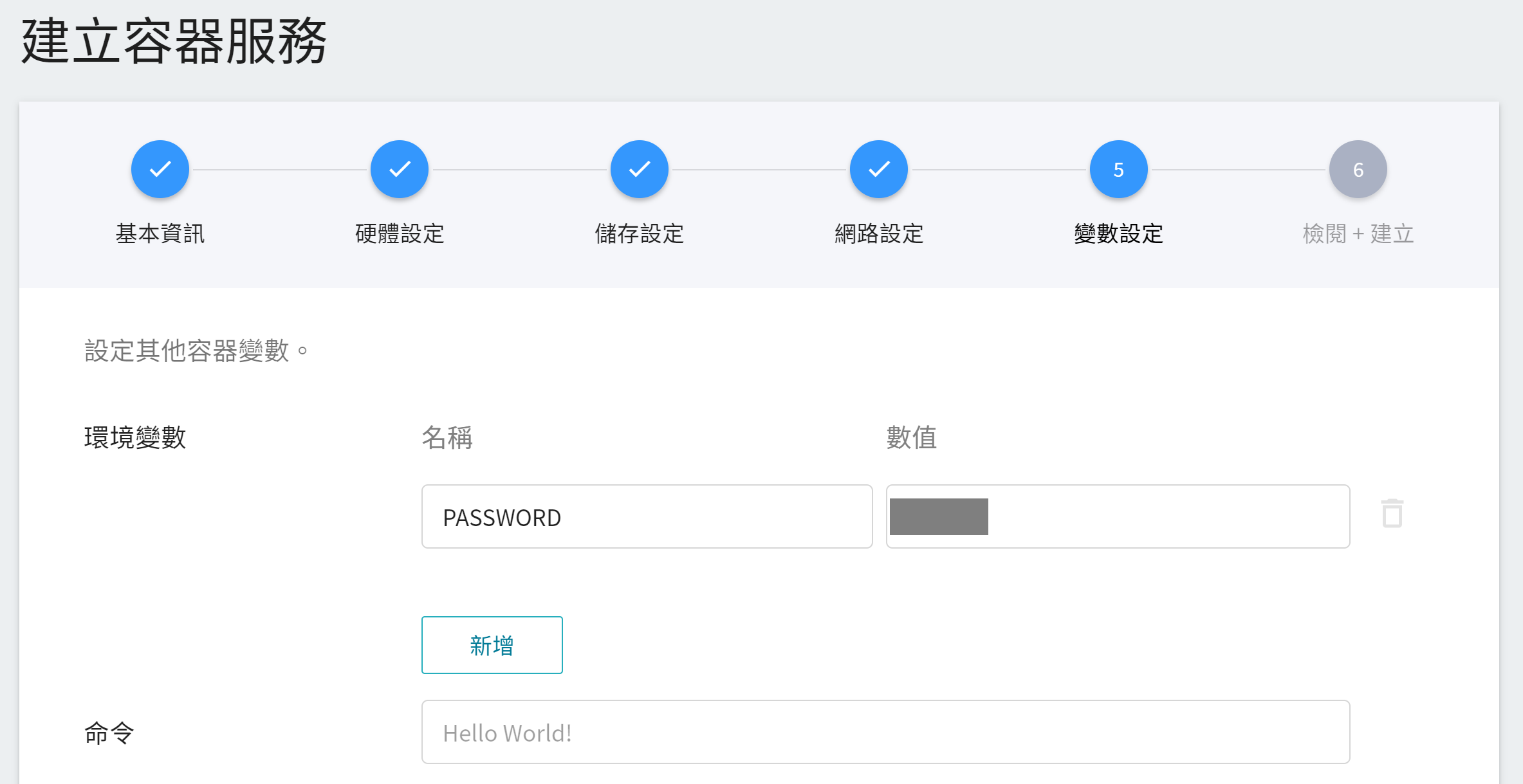
5. **變數設定**
在使用 Jupyter Notebook 時,會需要輸入密碼,此步驟請使用在映像檔中所預設的環境變數 **`PASSWORD`** 來設定您自己的密碼。
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
#### 5.1.2 **使用 Jupyter Notebook**
完成容器服務的建立後,回到容器服務管理列表,點擊該服務可以取得詳細資訊。

在詳細資料頁面中,需要特別注意的是 **網路** 區塊,在這區塊中有 Jupyter Notebook 服務埠 `8888` 的對外埠,點擊右側的網址連結即可在瀏覽器中開啟 Jupyter Notebook 服務。
出現 Jupyter 服務的登入頁面後,請輸入在 **變數設定** 步驟中設定的 **`PASSWORD`** 變數值。

至此我們就完成了 Jupyter Notebook 的啟動。
### 5.2 進行推論
開啟 Jupyter Notebook 後,可以看到一份名為 **`inference_client.ipynb`** 的程式檔,請依您的環境,修改此份程式碼進行推論,程式碼說明如下。
1. **發送請求**
本範例使用 requests 模組產生 HTTP 的 POST 請求,並將圖片與參數作為一個字典結構遞給 JSON 參數。
```python=1
# 預設的 dataset 路徑
datasetPath = "./test/"
# 推論服務的 endpoint & port
inferenceIP = "myinference-i"
inferencePort = "9999"
# 取得所有檔案與子目錄名稱
files = listdir(datasetPath)
for f in files:
fullpath = join(datasetPath, f)
if isfile(fullpath):
OUTPUT = join(resultPath, f)
with open(fullpath, "rb") as inputFile:
data = inputFile.read()
body = {"image": base64.b64encode(data).decode("utf-8"), "thresh": 0.5, "getImage": False}
res = requests.post("http://" + inferenceIP +":" + inferencePort + "/darknet/detect", json=body)
detected = res.json()
objects = detected.get('results')
```
其中有幾個變數需特別注意:
* **`inferenceIP`** 以及 **`inferencePort`** 需要填入推論服務的 網址連結。
本範例 **`inferenceIP`** 為 **myinference-i**,**`inferencePort`** 為 **9999**。
* **`thresh`** 是指當預測出來的信心值必須大於該值才能被歸類為該類別。<br><br>
2. **取回結果**
完成物件偵測後,結果將以 JSON 格式回傳:
- **`results`**:為一物件陣列,包含一個或多個偵測物件結果。若無法偵測到任何物件,則回傳空陣列。
- **`results.bounding`**:每個偵測物件的結果,其中還包含:
- **`height`**:bounding box 的高。
- **`width`**:bounding box 的寬。
- **`x`**:bounding box 的中心點 x 座標。
- **`y`**:bounding box 的中心點 y 座標。
- **`results.name`**:該物件的分類結果。
- **`results.score`**:該物件分類的信心分數。
當取得這些資訊後,我們可以按此繪製 bounding。

根據這兩段程式,即可向推論服務發送請求,並取回偵測結果,繪製到原圖上。
### 5.3 附件程式碼
:::spoiler **程式碼**
```python=1
import numpy as np
import base64
import io
import requests
import json
from PIL import Image as Images,ImageFont,ImageDraw
from IPython.display import Image, clear_output, display
import cv2
%matplotlib inline
from matplotlib import pyplot as plt
import time
from os import listdir
from os.path import isfile, isdir, join
datasetPath = "./test/"
resultPath = "./result/"
inferenceIP = "myinference-i"
inferencePort = "9999"
#Font setup
fontpath = "/notebooks/cht.otf"
color = (255, 0, 0)
font = ImageFont.truetype(fontpath, 20)
def arrayShow(imageArray):
resized = cv2.resize(imageArray, (500, 333), interpolation=cv2.INTER_CUBIC)
ret, png = cv2.imencode('.png', resized)
return Image(data=png)
# 取得所有檔案與子目錄名稱
files = listdir(datasetPath)
for f in files:
fullpath = join(datasetPath, f)
if isfile(fullpath):
OUTPUT = join(resultPath, f)
with open(fullpath, "rb") as inputFile:
data = inputFile.read()
body = {"image": base64.b64encode(data).decode("utf-8"), "thresh": 0.5, "getImage": False}
res = requests.post("http://" + inferenceIP +":" + inferencePort + "/darknet/detect", json=body)
detected = res.json()
objects = detected.get('results')
#print(detected)
for obj in objects:
bounding = obj.get('bounding')
name = obj.get('name')
height = bounding.get('height')
width = bounding.get('width')
score = obj.get('score')
detect_log = 'class:{!s} confidence:{!s}'.format(str(name), str(score))
#print(detect_log)
#Image(filename=FILE, width=600)
oriImage = cv2.imread(fullpath)
img_pil = Images.fromarray(cv2.cvtColor(oriImage, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
for obj in objects:
bounding = obj.get('bounding')
name = obj.get('name')
height = bounding.get('height')
width = bounding.get('width')
left = bounding.get('x') - (width/2)
top = bounding.get('y') - (height/2)
right = bounding.get('x') + (width/2)
bottom = bounding.get('y') + (height/2)
pos = (int(left), int(max((top - 10),0)))
box = (int(left), int(top)), (int(right), int(bottom))
draw.text(pos, name, font = font, fill = color)
draw.rectangle(box,outline="green")
cv_img = cv2.cvtColor(np.asarray(img_pil),cv2.COLOR_RGB2BGR)
cv2.imwrite(OUTPUT, cv_img)
img = arrayShow(cv_img)
clear_output(wait=True)
display(img)
#plt.imshow(oriImage)
#Image(filename=OUTPUT, width=600)
time.sleep(1)
```
:::
## 6. CVAT 輔助標註
CVAT 提供輔助標註功能,可以大幅度降低人工標註的時間。由於使用 CVAT 提供輔助標註功能需要有深度學習模型,這部分可以參考 [**訓練 YOLO 模型**](#3-訓練-YOLO-模型),訓練出自己的深度學習模型,本章節將介紹如何在 CVAT 標註工具中使用訓練好的深度學習模型進行的影像資料的輔助標註。
### 6.1. 建立 YOLOv3 輔助標註服務
使用 AI Maker 系統提供 **yolov3-cvat** 推論範本,可以讓您快速建立 **yolov3 model** 的輔助標註推論服務。
首先點選左側「**推論**」,進入「**推論管理**」頁面,並按下「**+建立**」,建立一個推論服務。
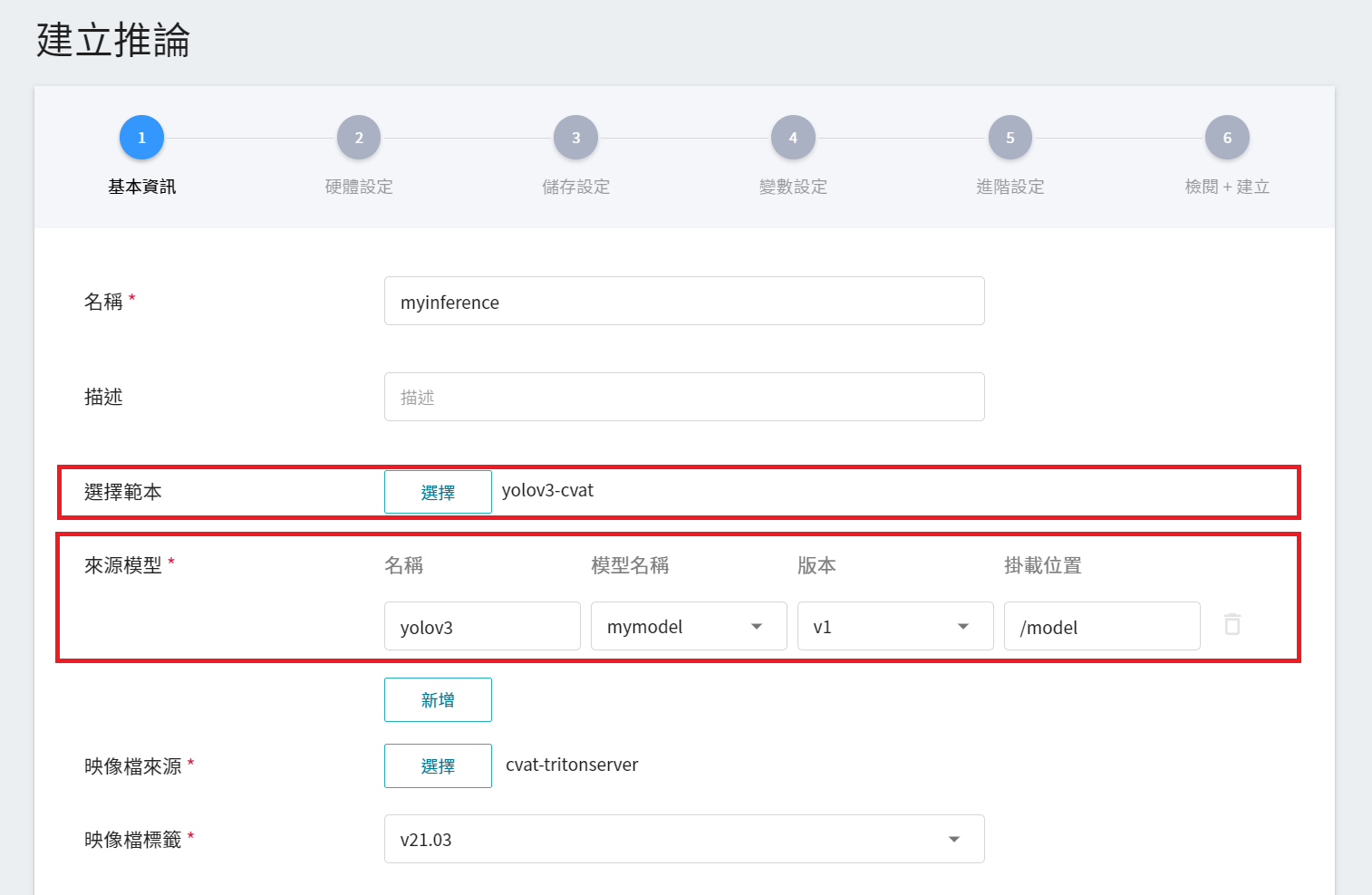
1. **基本資訊**
輸入推論服務基本資訊,請選擇 **`yolov3-cvat`** 範本,並在「**來源模型**」中選擇要用來執行輔助標註的模型名稱及版本。
2. **硬體設定**
參考目前的可用配額與訓練程式的需求,從列表中選出合適的硬體資源。
:::info
:bulb: **提示:** 為了有更好更快速的輔助標註功能體驗,硬體設定請選擇有 GPU 的硬體選項。
:::
3. **儲存設定**
此步驟無須設定。
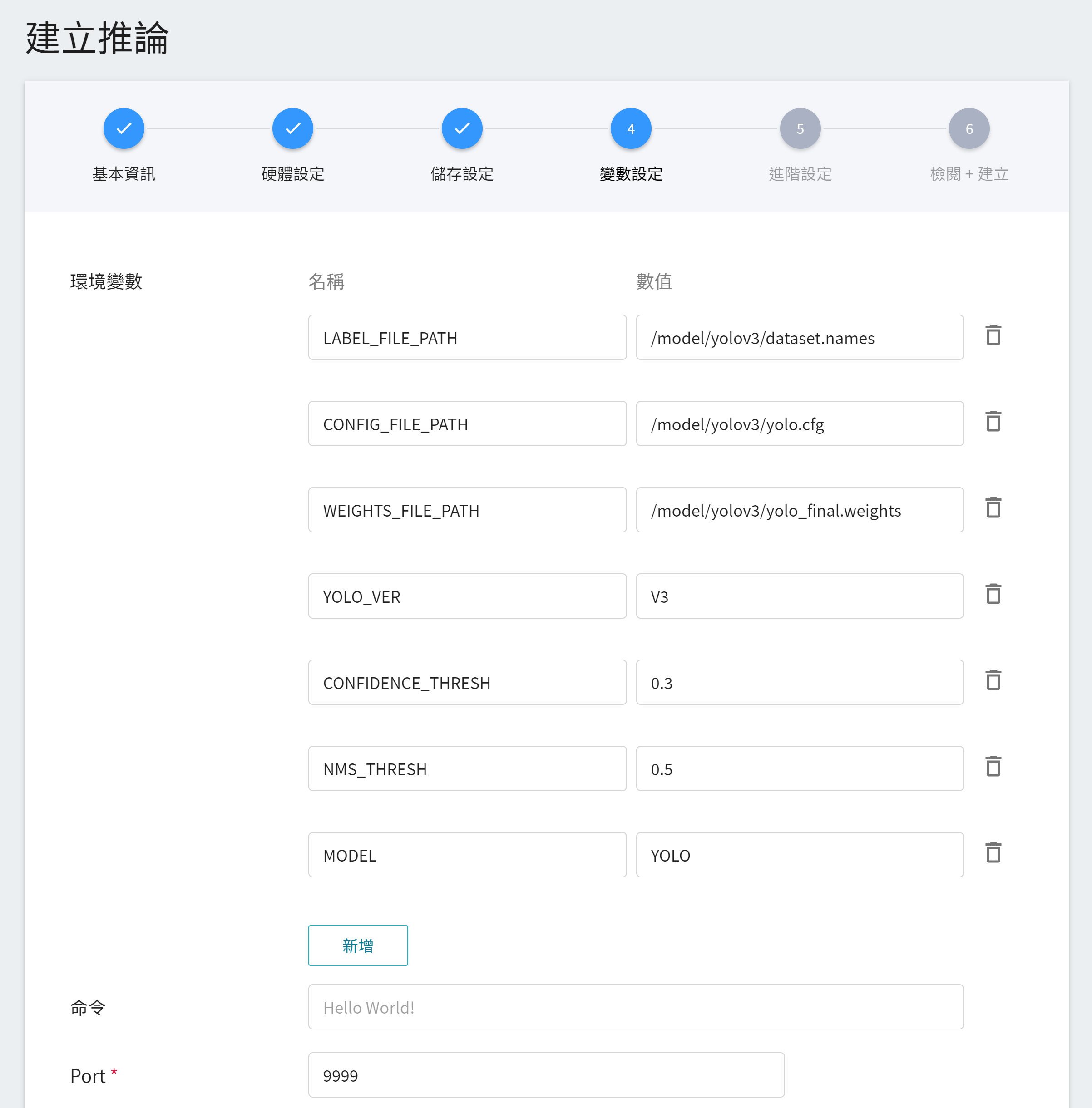
4. **變數設定**
在變數設定頁面,這些慣用的指令與參數,會在套用 **`yolov3-cvat`** 的範本時自動帶入。
5. **後續步驟**
後續步驟與其他任務的步驟相似,這邊就不再贅述。
### 6.2. 連結至 CVAT
當您建立好一個 YOLOv3 輔助標註推論服務後,還需要再一步驟讓您的推論服務連結至 CVAT。AI Maker 的推論服務中連結至 CVAT 服務的設定有三個地方:
1. 「**CVAT 管理**」頁面
點選左側功能列之「**標註工具**」,進入 CVAT 服務首頁。第一次使用需先點擊「**啟用 CVAT 服務**」,每個專案只能開啟一套 CVAT 服務。
進入「**CVAT 管理**」頁面後,點擊 **連結推論服務至 CVAT** 區塊下方的「**新增**」按鈕,若已有推論服務連結至 CVAT,則此按鈕會變成「**編輯**」。
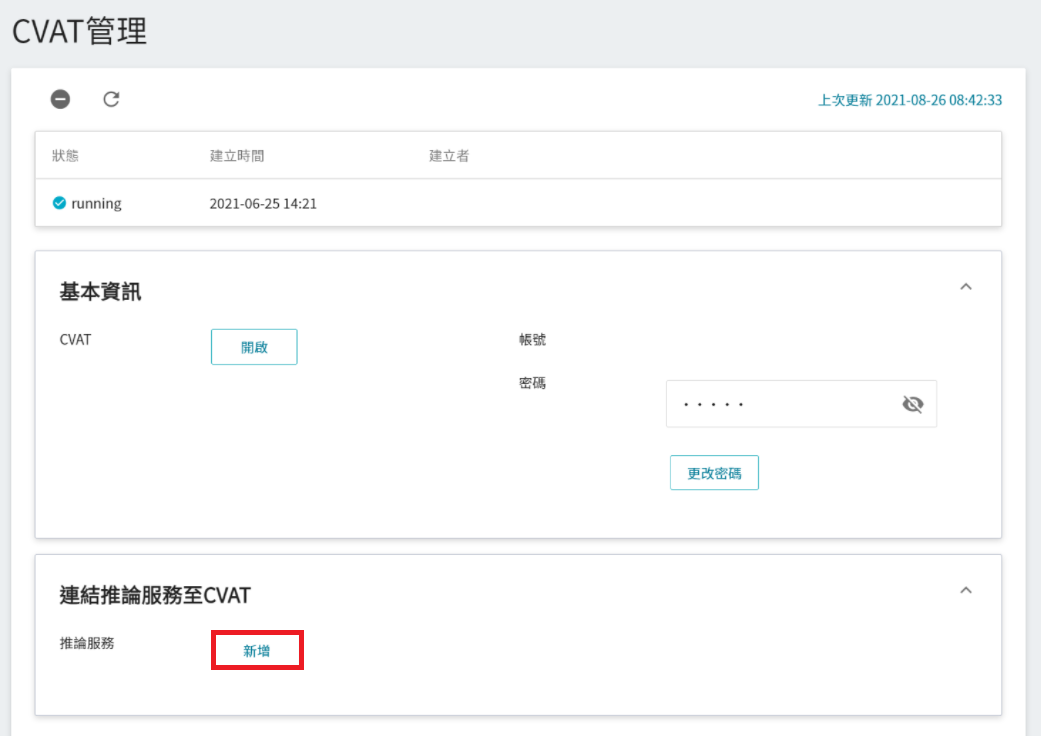
出現 「**連結推論服務至CVAT**」視窗後,再選擇欲連結的推論服務。

2. 「**推論管理**」頁面
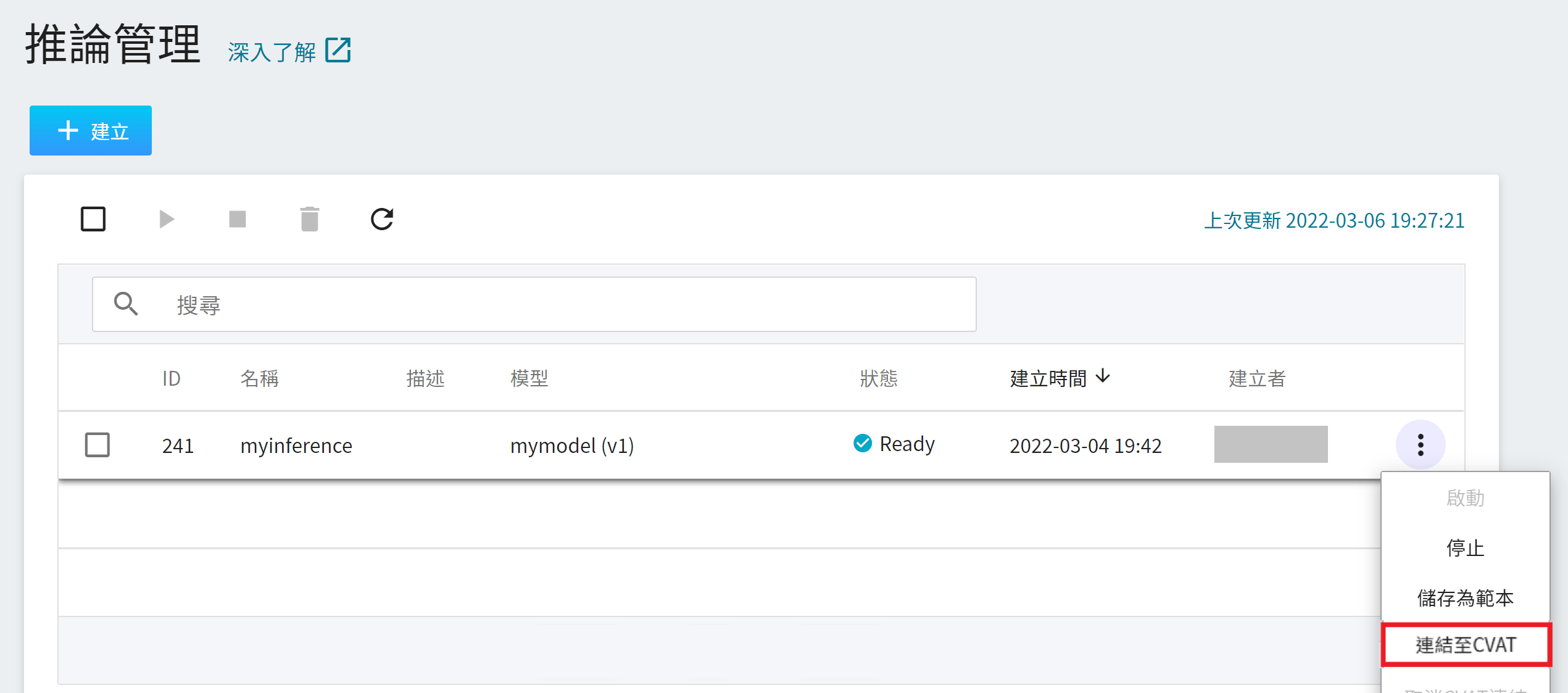
點選左側功能列「**推論**」進入「**推論管理**」,將滑鼠移動到欲進行自動標註的任務右側的更多選項圖示,接著點選「**連結至 CVAT**」。
3. 「**推論詳細資料**」頁面
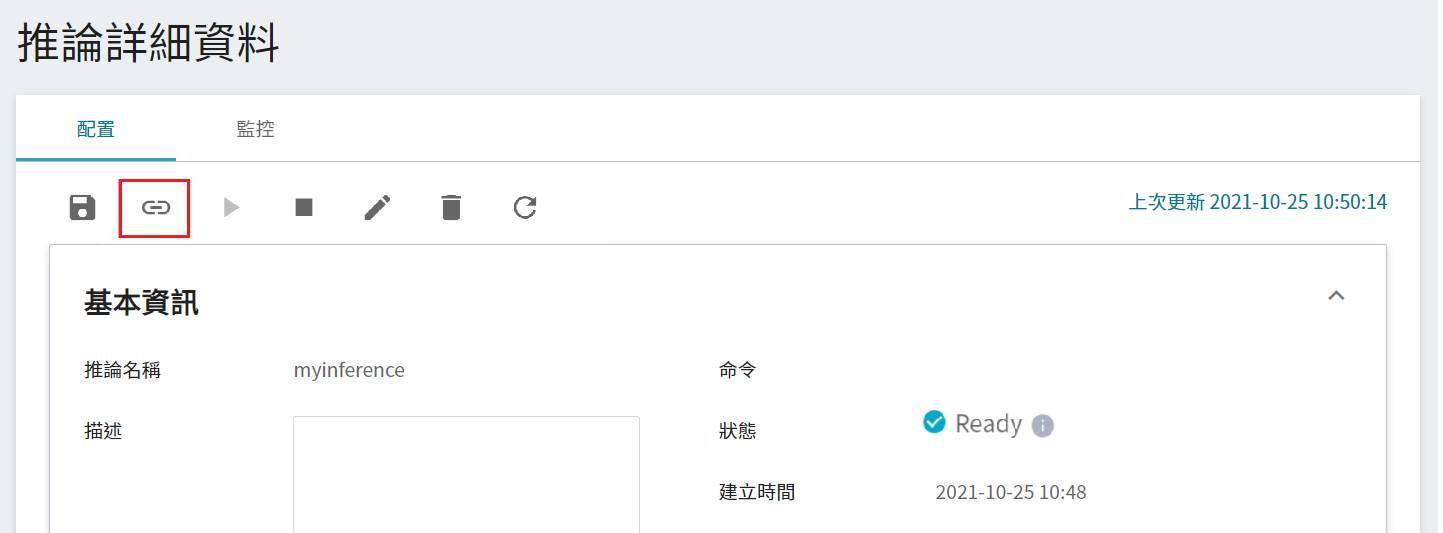
點擊欲連接 CVAT 的推論任務列表,進入「**推論詳細資料**」頁面,再點擊上方「**連接至 CVAT**」圖示。
### 6.3. 使用 CVAT 輔助標註功能
當您完成了上述的步驟,接下來就可以登入 CVAT 使用輔助標註功能。使用步驟請參考下列說明:
1. 查看 CVAT Model
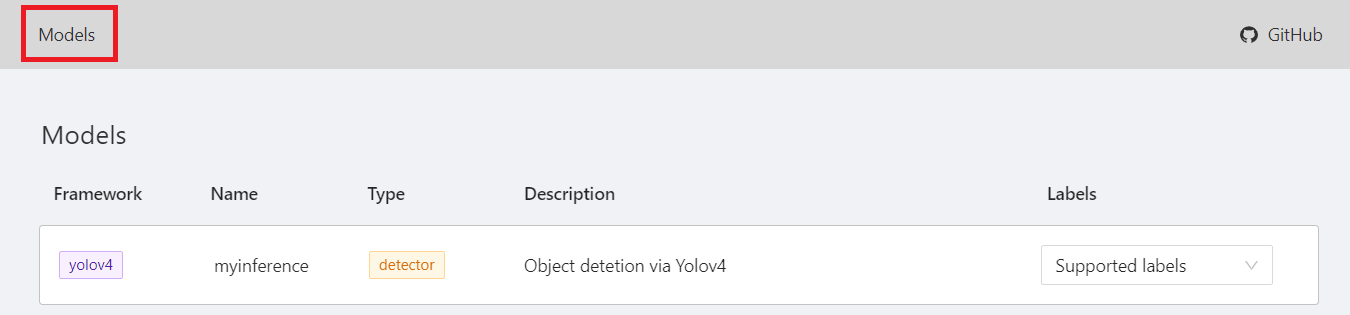
進入 CVAT 服務頁面後點選上方的 「**Models**」,就可以看到您剛剛連結至 CVAT 的推論服務。
2. 啟用輔助標註功能
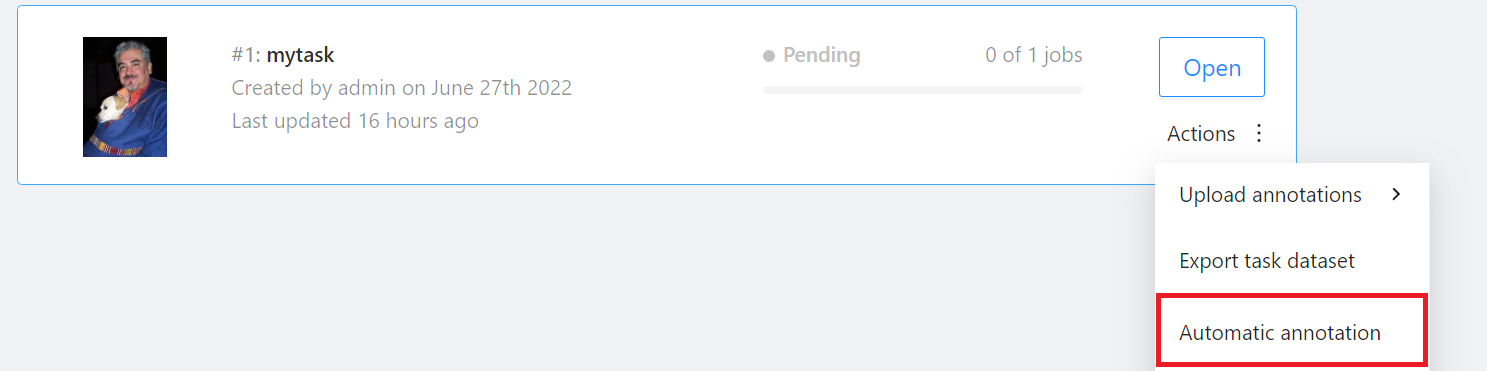
進入「**Tasks**」頁面後找到要標註的 Task,然後將滑鼠移動到欲進行自動標註的任務右側「**Actions**」的更多選項圖示,接著點選「**Automatic annotation**」。
出現「**Automatic annotation**」視窗後點擊「**Model**」下拉選單,選取已連結的推論任務。
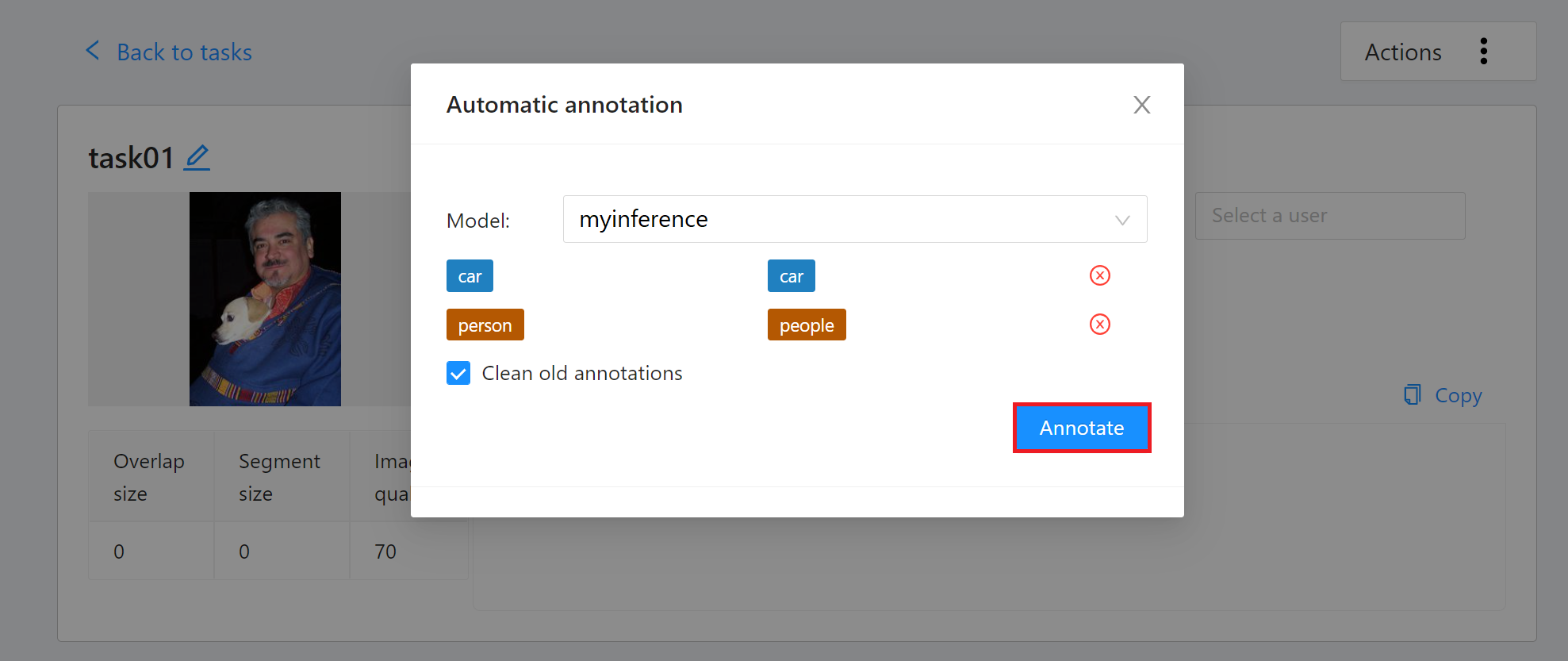
接著設定模型與任務 Label 對應,最後點擊「**Annotate**」執行自動標註。
自動標註任務開始後,可以看到完成的百分比,標註大量的資料會需要一些時間,標註完成後畫面上會出現標註完成的提示。

標註完成後,進入 CVAT 標註工具頁面檢視自動標註的結果,若對自動標註的結果不滿意,可再進行人工標註校正或重新訓練優化模型。
