---
title: AI Maker 案例教學 - Clara 4.0 教學:使用脾臟 CT 資料集訓練 3D 分割技術模型
description: OneAI 文件
tags: 案例教學, Clara, Deprecated
---
[OneAI 文件](/s/user-guide)
# AI Maker 案例教學 - Clara 4.0 教學:使用脾臟 CT 資料集訓練 3D 分割技術模型
:::warning
:warning: **注意:** 因系統或服務更新,此文件已不再維護,新版文件或類似的使用案例,請參考 [**AI Maker 案例教學 - MONAI 1.0 教學:使用脾臟 CT 資料集訓練 3D 分割技術模型**](/s/casestudy-monai)。
:::
[TOC]
## 0. 前言
為了方便您開發醫學影像的相關服務,AI Maker 整合了 **NVIDIA Clara** 醫學影像人工智慧與 HPC 應用程式框架,提供開發訓練流程所需的軟、硬體環境技術,讓您能輕鬆訓練與使用醫學影像模型。
在此範例中,我們將介紹如何使用公開的脾臟電腦斷層掃描(Computed Tomography,CT)資料集,訓練 3D 分割技術模型,以及如何使用訓練好的模型進行辨識。
主要步驟如下:
1. [**準備 MMAR 與資料集**](#1-準備-MMAR-與-資料集)
在此階段,我們將介紹如何取得公開的 MMAR 與資料集,並上傳至指定位置。
2. [**訓練分割技術模型**](#2-訓練分割技術模型)
在此階段,我們將配置相關訓練任務,以進行 Clara 的訓練與擬合,並將訓練好的模型儲存。
3. [**建立推論服務**](#3-建立推論服務)
在此階段,我們會將儲存的模型部署到推論服務中以進行推論。
4. [**AIAA Client**](#4-AIAA-Client---3D-Slicer)
在此階段,我們介紹如何使用 [**3D-Slicer**](#4-AIAA-Client---3D-Slicer) 與 [**Jupyter**](#5-AIAA-Client---Jupyter) 兩種 AIAA (AI Assisted Annotation) Client 與推論服務進行連結以進行推論。
當完成本範例後,您將學會:
1. 熟悉 AI Maker 功能並建立各階段任務。
2. 使用 AI Maker 內建的範本建置相關任務。
3. 使用儲存服務並上傳資料。
4. 如何與 AIAA Server 連結進行推論。
## 1. 準備 MMAR 與 資料集
在此步驟中,我們介紹如何準備 Medical Model Archive (MMAR) 並取得相對的脾臟資料集。
### 1.1 上傳 MMAR
請參照下列步驟準備 MMAR 與資料集。
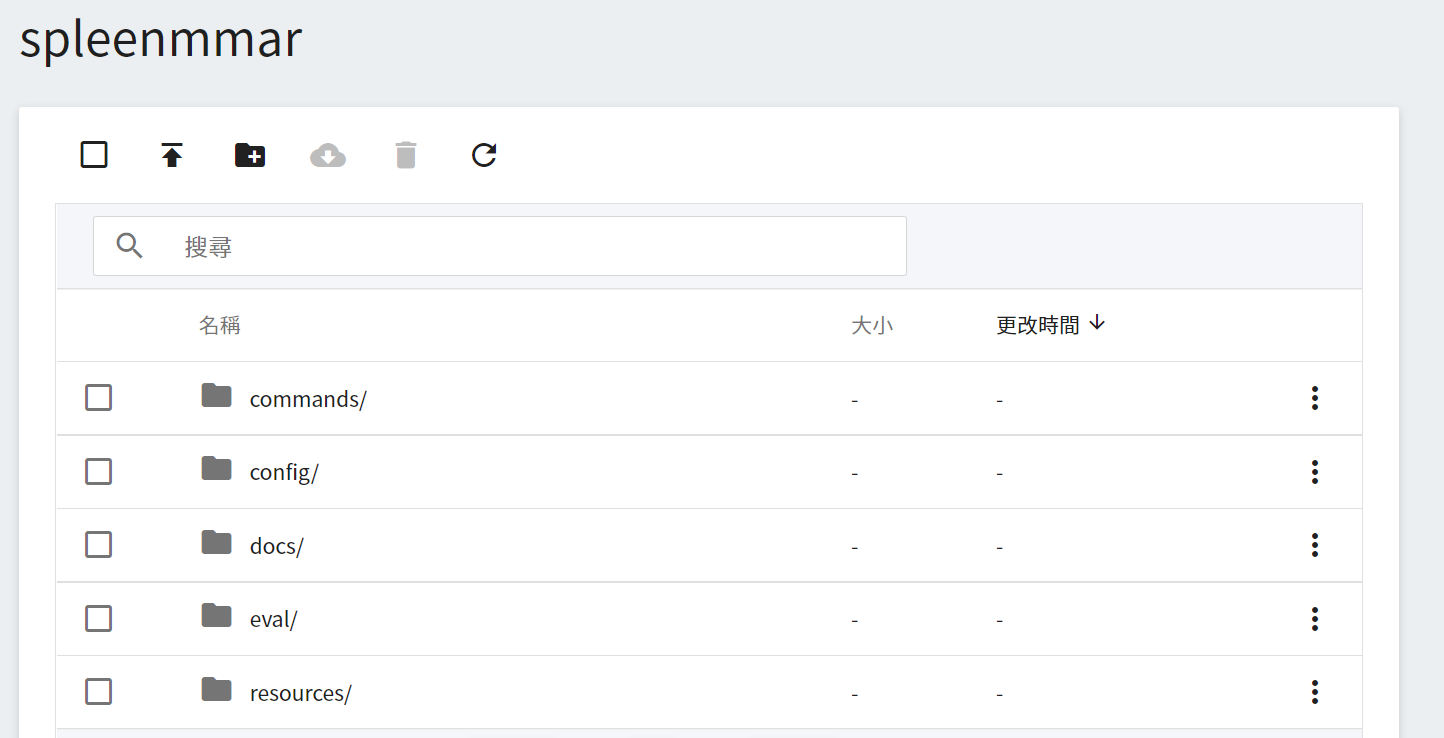
首先我們先準備 Clara 服務中所需的 [Medical Model Archive (MMAR)](https://docs.nvidia.com/clara/tlt-mi_ea/clara-train-sdk-v4.0/nvmidl/mmar.html) 文件,此文件定義了一個標準結構,是 Clara 用來安排開發生命週期中各項工作所需的資料結構,標準的 MMAR 資料結構如下:
```
./Project
├── commands
├── config
├── docs
├── eval
├── models
└── resources
```
其中:
1. **commands**:這會包含所需的 scripts,通常會有 training、多 GPU training、validation、inference 和 TensorRT 轉換... 等。
2. **config**:包含每次訓練所需的 training、validation、AIAA 部署和環境... 等配置 JSON 文件。
3. **docs**:顧名思義,放文件的地方。
4. **eval**:eval 預設結果輸出的目錄。
5. **models**:用來儲存訓練模型的目錄。
其中最重要的目錄有 3 個:**commands**、**config** 和 **models**。
在這份範例中,我們不重頭撰寫 MMAR 文件,而是使用 NGC 提供的從 CT 圖像對脾臟進行 3D 分割的預訓練模型 [**clara_pt_spleen_ct_segmentation**](https://github.com/OneAILabs/ai-template-model/blob/master/clara_pt_spleen_ct_segmentation.zip),並將脾臟資料集上傳至平台所提供的儲存服務中。
1. **建立儲存體**
從 OneAI 服務列表選擇「**儲存服務**」,進入儲存服務管理頁面,接著點擊「**+建立**」,新增一個名為 `spleenmmar` 的儲存體,以用來存放我們的 MMAR 文件。
2. **檢視儲存體**
完成儲存體的建立後,回到「**儲存服務管理**」頁面,此時會看到剛剛新增的儲存體已建立完成。
3. **上傳 MMAR**
點擊建立好的儲存體,然後點選「**上傳**」就可以開始上傳資料集。(請參閱 [**儲存服務說明文件**](/s/_F4C_EzEa))。
MMAR 文件中最核心的檔案,也就是 config 下 config_train.json。在這份 JSON 中,包含定義神經網路所需的所有參數、網路模型的搭建、激活函數、優化器... 等,並分別定義了 Training 與 Validation 所需的設定,詳細的介紹可以參閱 [**NVIDIA 官方文件**](https://docs.nvidia.com/clara/clara-train-sdk/pt/appendix/configuration.html#training-configuration)。
### 1.2 上傳資料集
上傳 MMAR 檔案後,接著需準備相對的脾臟資料集,並將資料集依照 **config_train.json** 的設定,分成 Training Set 與 Validation Set。
我們使用公開資料集 — [**Medical Segmentation Decathlon(醫學分割十項全能)**](http://medicaldecathlon.com/) 來進行訓練,從中下載 **`Task09_Spleen.tar`**。這是一個用於醫學影像進行語義分割的比賽資料集,而這個 Task09 則是脾臟的資料集。
:::info
:bulb:**提示:** 請詳細閱讀 [**NGC 官網**](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/med/models/clara_pt_spleen_ct_segmentation) 的相關說明,並執行必要的資料前處理。
:::
<center> <img src="/uploads/o33Cg55.png" alt="Spleen 資料集介紹"></center>
<center>Spleen 資料集介紹</center>
<center><a href="http://medicaldecathlon.com/">(圖片來源:Medical Segmentation Decathlon)</a></center>
<br><br>
資料集準備好後,先將資料集分成了 Training Set 與 Validation Set 後,並將它們上傳至儲存服務中:
1. **Training Set 與 Validation Set**
在這資料集中會有一份 **dataset.json**,這份 json 檔中定義了資料集的切割方式。不過,在這文件中僅定義了 Training Set 與 Test Set,因此我們需要從 Training Set 切割出 Validation Set。
我們在 json 中新增一個 **`validation`** 的 key;其 value 值為一陣列,而陣列內容就是我們從 Training Set 移出的資料:
```json
"validation":[
{"image":"./imagesTr/spleen_19.nii.gz","label":"./labelsTr/spleen_19.nii.gz"},
{"image":"./imagesTr/spleen_31.nii.gz","label":"./labelsTr/spleen_31.nii.gz"},
{"image":"./imagesTr/spleen_52.nii.gz","label":"./labelsTr/spleen_52.nii.gz"},
{"image":"./imagesTr/spleen_40.nii.gz","label":"./labelsTr/spleen_40.nii.gz"},
{"image":"./imagesTr/spleen_3.nii.gz","label":"./labelsTr/spleen_3.nii.gz"},
{"image":"./imagesTr/spleen_17.nii.gz","label":"./labelsTr/spleen_17.nii.gz"},
{"image":"./imagesTr/spleen_21.nii.gz","label":"./labelsTr/spleen_21.nii.gz"},
{"image":"./imagesTr/spleen_33.nii.gz","label":"./labelsTr/spleen_33.nii.gz"},
{"image":"./imagesTr/spleen_9.nii.gz","label":"./labelsTr/spleen_9.nii.gz"},
{"image":"./imagesTr/spleen_29.nii.gz","label":"./labelsTr/spleen_29.nii.gz"}],
```
<br>
整份文改完後,完整內容如下:
:::spoiler **dataset.json**
```json
{
"name": "Spleen",
"description": "Spleen Segmentation",
"reference": "Memorial Sloan Kettering Cancer Center",
"licence":"CC-BY-SA 4.0",
"release":"1.0 06/08/2018",
"tensorImageSize": "3D",
"modality": {
"0": "CT"
},
"labels": {
"0": "background",
"1": "spleen"
},
"numTraining": 41,
"numTest": 20,
"training":[
{"image":"./imagesTr/spleen_46.nii.gz","label":"./labelsTr/spleen_46.nii.gz"},
{"image":"./imagesTr/spleen_25.nii.gz","label":"./labelsTr/spleen_25.nii.gz"},
{"image":"./imagesTr/spleen_13.nii.gz","label":"./labelsTr/spleen_13.nii.gz"},
{"image":"./imagesTr/spleen_62.nii.gz","label":"./labelsTr/spleen_62.nii.gz"},
{"image":"./imagesTr/spleen_27.nii.gz","label":"./labelsTr/spleen_27.nii.gz"},
{"image":"./imagesTr/spleen_44.nii.gz","label":"./labelsTr/spleen_44.nii.gz"},
{"image":"./imagesTr/spleen_56.nii.gz","label":"./labelsTr/spleen_56.nii.gz"},
{"image":"./imagesTr/spleen_60.nii.gz","label":"./labelsTr/spleen_60.nii.gz"},
{"image":"./imagesTr/spleen_2.nii.gz","label":"./labelsTr/spleen_2.nii.gz"},
{"image":"./imagesTr/spleen_53.nii.gz","label":"./labelsTr/spleen_53.nii.gz"},
{"image":"./imagesTr/spleen_41.nii.gz","label":"./labelsTr/spleen_41.nii.gz"},
{"image":"./imagesTr/spleen_22.nii.gz","label":"./labelsTr/spleen_22.nii.gz"},
{"image":"./imagesTr/spleen_14.nii.gz","label":"./labelsTr/spleen_14.nii.gz"},
{"image":"./imagesTr/spleen_18.nii.gz","label":"./labelsTr/spleen_18.nii.gz"},
{"image":"./imagesTr/spleen_20.nii.gz","label":"./labelsTr/spleen_20.nii.gz"},
{"image":"./imagesTr/spleen_32.nii.gz","label":"./labelsTr/spleen_32.nii.gz"},
{"image":"./imagesTr/spleen_16.nii.gz","label":"./labelsTr/spleen_16.nii.gz"},
{"image":"./imagesTr/spleen_12.nii.gz","label":"./labelsTr/spleen_12.nii.gz"},
{"image":"./imagesTr/spleen_63.nii.gz","label":"./labelsTr/spleen_63.nii.gz"},
{"image":"./imagesTr/spleen_28.nii.gz","label":"./labelsTr/spleen_28.nii.gz"},
{"image":"./imagesTr/spleen_24.nii.gz","label":"./labelsTr/spleen_24.nii.gz"},
{"image":"./imagesTr/spleen_59.nii.gz","label":"./labelsTr/spleen_59.nii.gz"},
{"image":"./imagesTr/spleen_47.nii.gz","label":"./labelsTr/spleen_47.nii.gz"},
{"image":"./imagesTr/spleen_8.nii.gz","label":"./labelsTr/spleen_8.nii.gz"},
{"image":"./imagesTr/spleen_6.nii.gz","label":"./labelsTr/spleen_6.nii.gz"},
{"image":"./imagesTr/spleen_61.nii.gz","label":"./labelsTr/spleen_61.nii.gz"},
{"image":"./imagesTr/spleen_10.nii.gz","label":"./labelsTr/spleen_10.nii.gz"},
{"image":"./imagesTr/spleen_38.nii.gz","label":"./labelsTr/spleen_38.nii.gz"},
{"image":"./imagesTr/spleen_45.nii.gz","label":"./labelsTr/spleen_45.nii.gz"},
{"image":"./imagesTr/spleen_26.nii.gz","label":"./labelsTr/spleen_26.nii.gz"}, {"image":"./imagesTr/spleen_49.nii.gz","label":"./labelsTr/spleen_49.nii.gz"}],
"validation":[
{"image":"./imagesTr/spleen_19.nii.gz","label":"./labelsTr/spleen_19.nii.gz"},
{"image":"./imagesTr/spleen_31.nii.gz","label":"./labelsTr/spleen_31.nii.gz"},
{"image":"./imagesTr/spleen_52.nii.gz","label":"./labelsTr/spleen_52.nii.gz"},
{"image":"./imagesTr/spleen_40.nii.gz","label":"./labelsTr/spleen_40.nii.gz"},
{"image":"./imagesTr/spleen_3.nii.gz","label":"./labelsTr/spleen_3.nii.gz"},
{"image":"./imagesTr/spleen_17.nii.gz","label":"./labelsTr/spleen_17.nii.gz"},
{"image":"./imagesTr/spleen_21.nii.gz","label":"./labelsTr/spleen_21.nii.gz"},
{"image":"./imagesTr/spleen_33.nii.gz","label":"./labelsTr/spleen_33.nii.gz"},
{"image":"./imagesTr/spleen_9.nii.gz","label":"./labelsTr/spleen_9.nii.gz"},
{"image":"./imagesTr/spleen_29.nii.gz","label":"./labelsTr/spleen_29.nii.gz"}],
"test":["./imagesTs/spleen_15.nii.gz",
"./imagesTs/spleen_23.nii.gz",
"./imagesTs/spleen_1.nii.gz",
"./imagesTs/spleen_42.nii.gz",
"./imagesTs/spleen_50.nii.gz",
"./imagesTs/spleen_54.nii.gz",
"./imagesTs/spleen_37.nii.gz",
"./imagesTs/spleen_58.nii.gz",
"./imagesTs/spleen_39.nii.gz",
"./imagesTs/spleen_48.nii.gz",
"./imagesTs/spleen_35.nii.gz",
"./imagesTs/spleen_11.nii.gz",
"./imagesTs/spleen_7.nii.gz",
"./imagesTs/spleen_30.nii.gz",
"./imagesTs/spleen_43.nii.gz",
"./imagesTs/spleen_51.nii.gz",
"./imagesTs/spleen_36.nii.gz",
"./imagesTs/spleen_55.nii.gz",
"./imagesTs/spleen_57.nii.gz",
"./imagesTs/spleen_34.nii.gz"]
}
```
:::
2. **建立儲存體**
接下來,與建立 **`spleenmmar`** 儲存體的步驟相似,我們建立一個名為 **`spleendataset`** 的儲存體,在這個儲存體中我們會用來放置脾臟資料集。
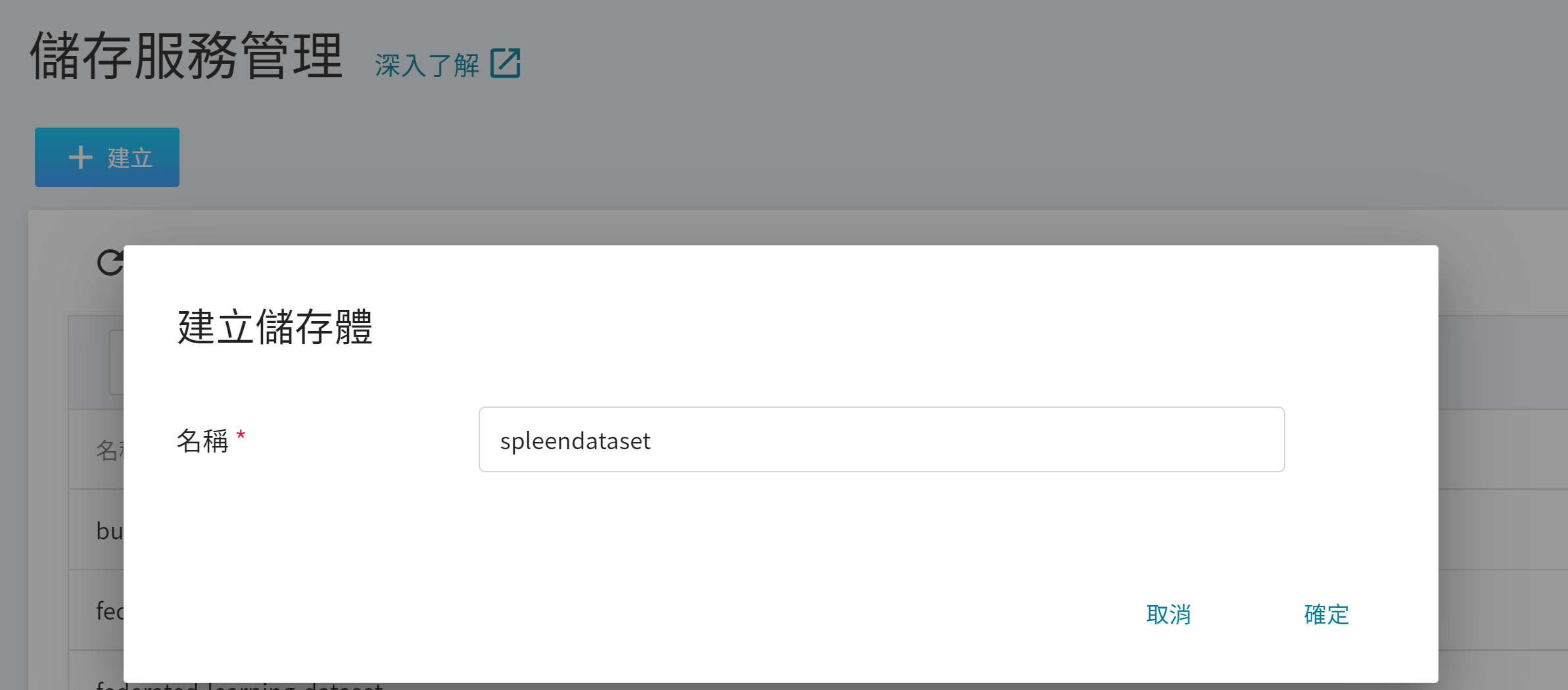
3. **上傳資料集**
接下來,將準備好的資料集,上傳至 **`spleendataset`** 儲存體。
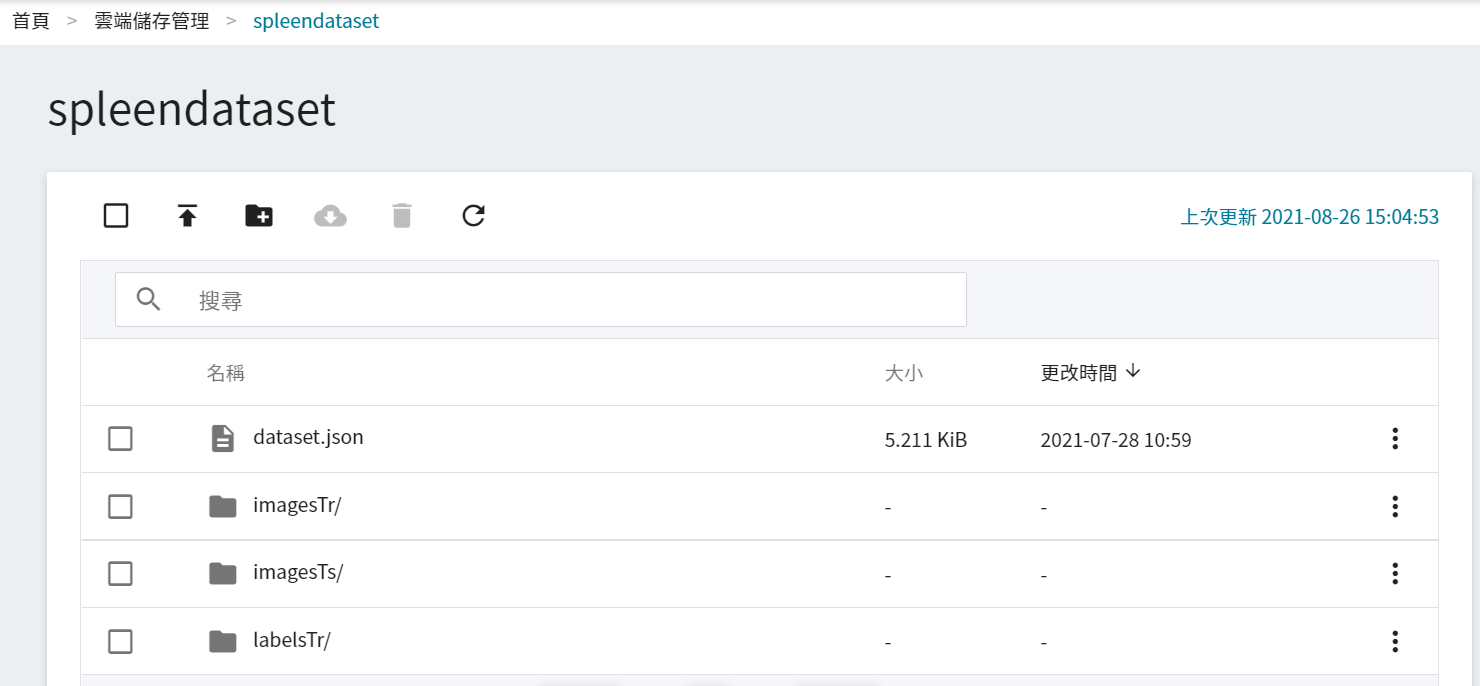
## 2. 訓練分割技術模型
完成 [**MMAR**](#12-上傳-MMAR) 與 [**資料集**](#13-上傳資料集) 的上傳後,我們就可以使用此資料集進行遷移學習的訓練。
### 2.1 建立訓練任務
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**訓練任務**」,進入訓練任務管理頁面後,點擊「**+建立**」,新增一個訓練任務。

#### 2.1.1 一般訓練任務
建立訓練任務可分成五個步驟:
1. **基本資訊**
第一步是基本資訊的設定,請依序輸入**名稱**、**描述**,並 **選擇方法**,在這一小節中,我們先選擇 **`一般訓練任務`** 來進行設定。除此之外,其餘的資訊可以透過 **選擇範本** 的功能,選取已經建立的範本,快速帶入各設定。
AI Maker 針對 Clara 4.0 的訓練與使用,提供了一套 **`clara-v4`** 的範本,定義了各階段任務所需使用的變數與設定,方便開發者迅速開發屬於自己的網路。在這階段,我們選用系統內建的 **`clara-v4`** 的範本,來帶入各項設定。
2. **硬體設定**
參考目前的可用配額與訓練程式的需求,從列表中選出合適的硬體資源。
:::info
:bulb: **提示:** 建議選擇具有 **共享記憶體** 的硬體,以免因為資源不足而導致訓練失敗。
:::
3. **儲存設定**
這個階段須掛載的儲存體有兩個:
1. **dataset**:是我們存放資料的儲存體 **`spleendataset`**。
2. **mmar**:**`spleenmmar`**。
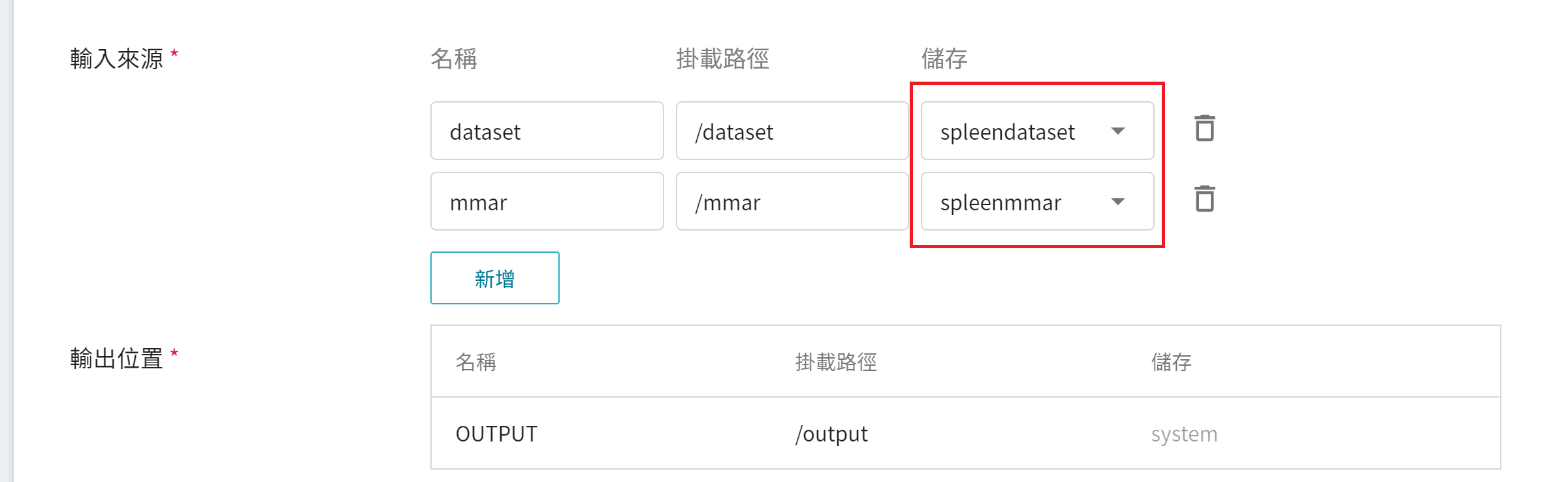
4. **變數設定**
變數設定步驟是設定環境變數及命令,各欄位的說明如下:
| 欄位名稱 | 說明|
| ------- | ----- |
| 環境變數 | 輸入環境變數的名稱及數值。這邊的環境變數除包含訓練執行的相關設定外,也包括了訓練網路所需的參數設定。 |
| 目標參數 | 訓練結束,會回傳一值做為最終結果,這裡為該回傳值設定名稱及目標方向。例如:若回傳的數值為準確率,則可命名為 accuracy,並設定其目標方向為最大值;若回傳的值為錯誤率,則命名為 error ,其方向為最小值。 |
| 命令 | 輸入欲執行的命令或程式名稱。例如:`python train.py`。|
不過因為我們在基本資訊填寫時,已經套用了 **`clara-v4`** 範本,這些指令與參數會自動帶入:
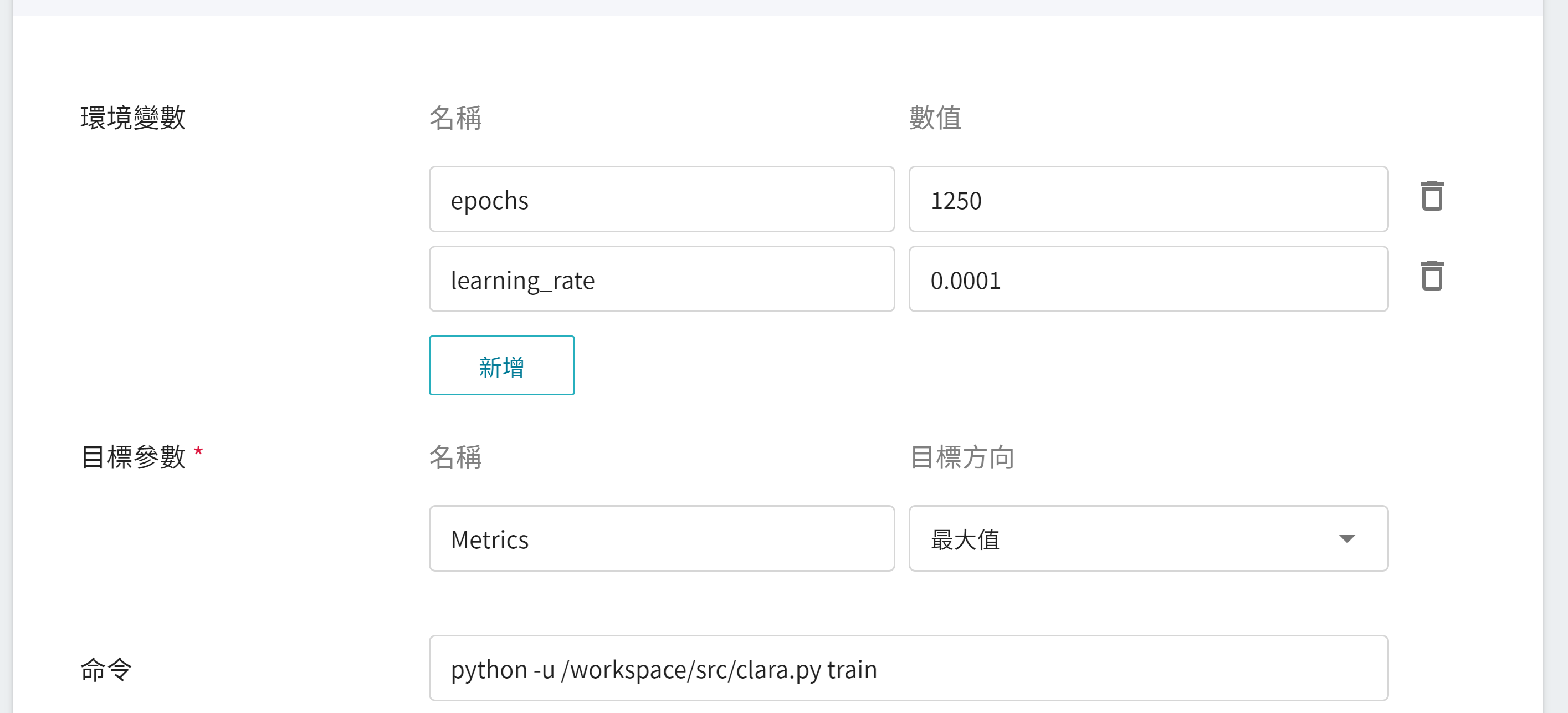
環境變數的設定值可依照您的開發需求進行調整,在此說明各環境變數:
| 變數 | 預設值 | 說明 |
| ------------- | ---------- | ---- |
| epochs | 由 config_train.json 所定義 | 一個時期=所有訓練樣本的一個正向傳遞和一個反向傳遞。|
| learning_rate | 由 config_train.json 所定義 | **學習速度**的參數,在模型學習初期時,可以設定大一點,加速訓練。在學習後期,需要設定小一點,避免發散。 |
另外,MMAR 中的神經網路參數、優化器... 等設定,也可以透過環境變數調整,例如:
1. 如欲修改網路損失函數,按照 MMAR 的 **config_train.json** 的架構,我們可以使用 **`train.loss.name`** 作為環境變數來指定。
2. 如欲修改網路優化器,環境變數可以使用 **`train.optimizer.name`** 來指定。
環境變數中,各變數的值的選擇,請參考 [**NVIDIA 的 MMAR 文件說明**](https://docs.nvidia.com/clara/tlt-mi_ea/clara-train-sdk-v4.0/nvmidl/appendix/configuration.html)。
5. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
#### 2.1.2 Smart ML 訓練任務
在 [上一小結 2.1.1](#211-一般訓練任務) 中介紹的是 **一般訓練任務** 的建立,這邊來介紹 **Smart ML 訓練任務** 的建立,您可以只選擇任一種訓練方法或比較兩種訓練方法的差異。兩者流程大致相同,但會多出額外參數需要設定,在此僅說明多出的變數:
1. **基本資訊**
當設定方法為 Smart ML 訓練任務後,會進一步要求挑選 Smart ML 訓練任務所要使用的 **演算法**,可選擇的演算法如下:
- **Bayesian**:根據環境變數、超參數的設置範圍和訓練的次數,能有效地執行多項訓練任務,以找到更好的參數組合。
- **TPE**:Tree-structured Parzen Estimator,與 Bayesian 演算法類似,可優化高維度超參數的訓練任務。
- **Grid**:經驗豐富的機器學習使用者可以指定超參數的多個值,系統將根據超參數列表的組合執行多個訓練任務,並獲得計算結果。
- **Random**:在指定範圍內隨機選擇用於訓練任務的超參數。
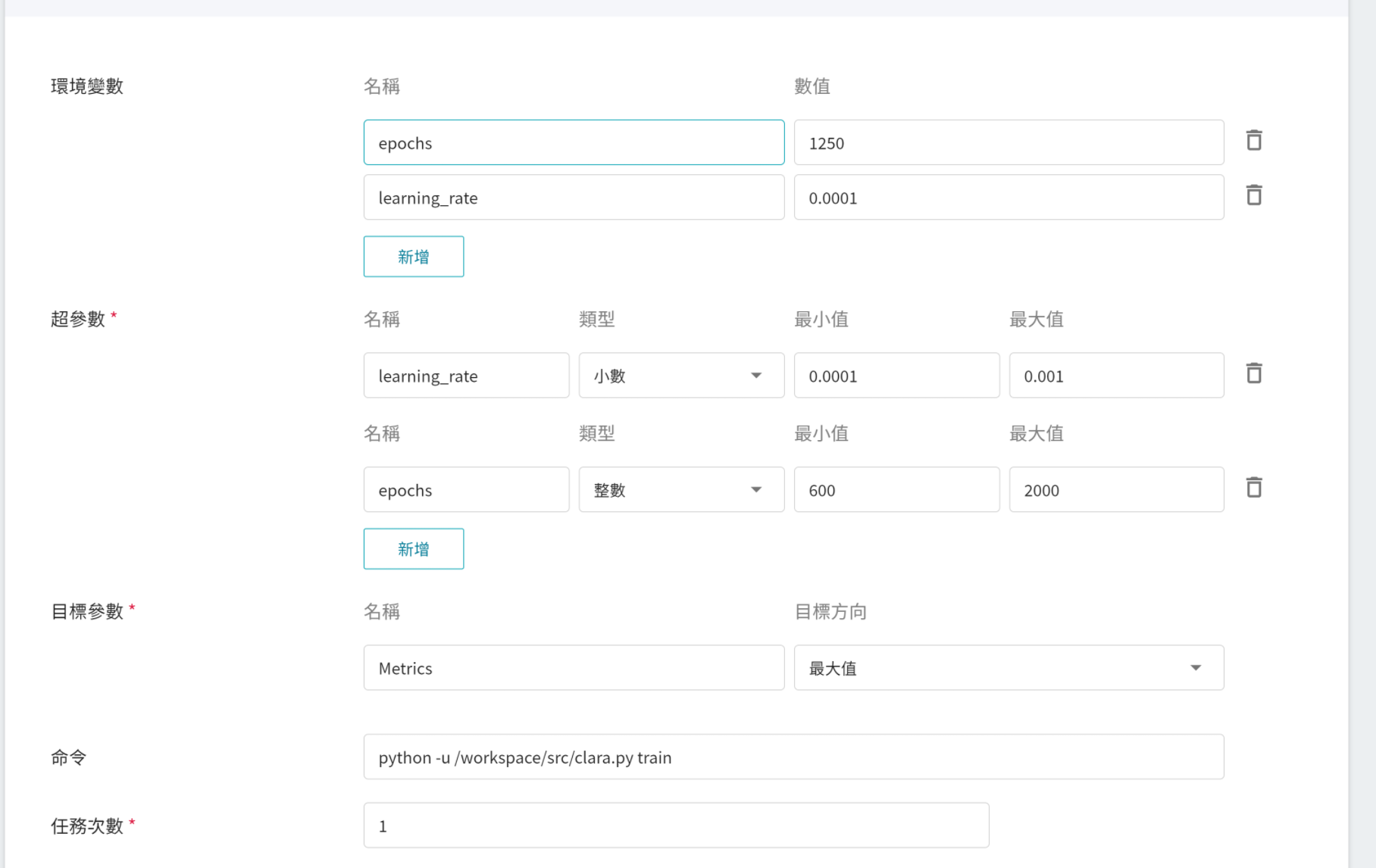
2. **變數設定**
在變數設定的頁面中,會多出 **超參數** 與 **任務次數** 的設定,其中:
- **超參數**
這是告訴任務,有哪些參數需要進行嘗試。每個參數在設定時,須包含參數的名稱、類型及數值(或數值範圍),選擇類型後(整數、小數和陣列),請依提示輸入相對的數值格式。
- **任務次數**
即訓練次數設定,讓訓練任務執行多次,以找到更好的參數組合。
當然 **超參數** 中部份的訓練參數是可以移動至 **環境變數**;反之亦然。若您想固定該參數,則可將該參數從超參數區域中移除,新增至環境變數區域,並給定固定值;反之,若想將該參數加入嘗試,則將它從環境變數中移除,加入至下方的超參數區域。
### 2.2 啟動訓練任務
完成訓練任務的設定後,回到訓練任務管理頁面,可以看到剛剛建立的任務。
點擊該任務,可檢視訓練任務的詳細設定。在命令列中,有 6 個圖示,若此時任務的狀態顯示為 **`Ready`** ,即可點擊 **啟動** 執行訓練任務。
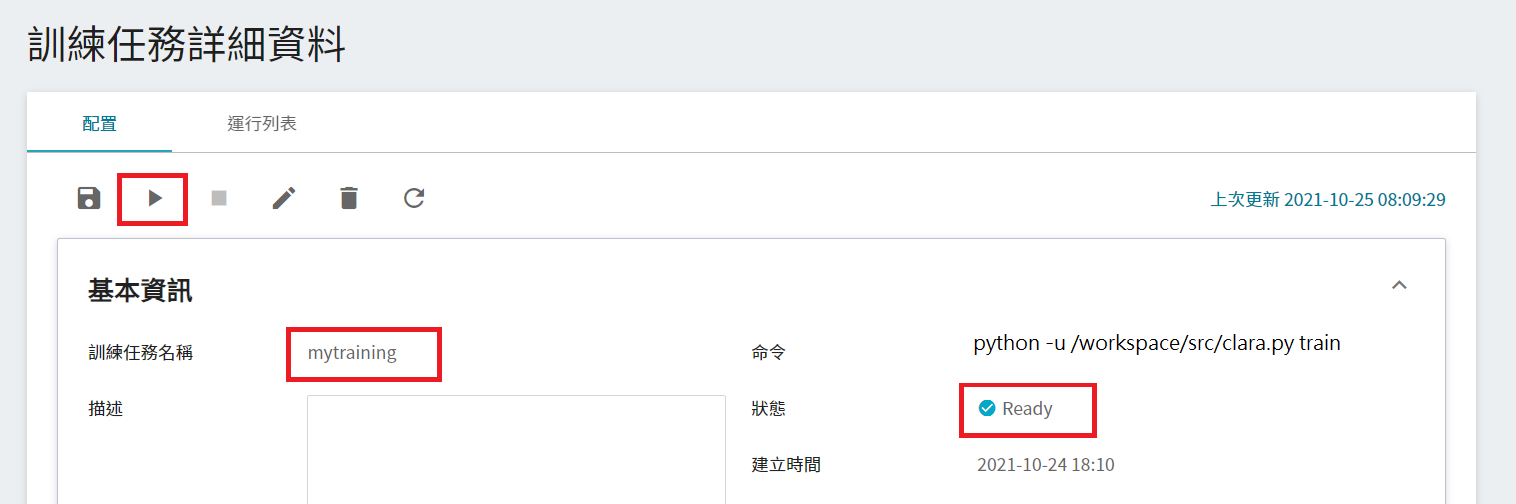
啟動後,點擊上方的「**運行列表**」頁籤,可以在列表中查看該任務的執行狀況與排程。在訓練進行中,可以點擊任務右方清單中的 **查看日誌** 或 **查看詳細狀態**,來得知目前任務執行的詳細資訊。
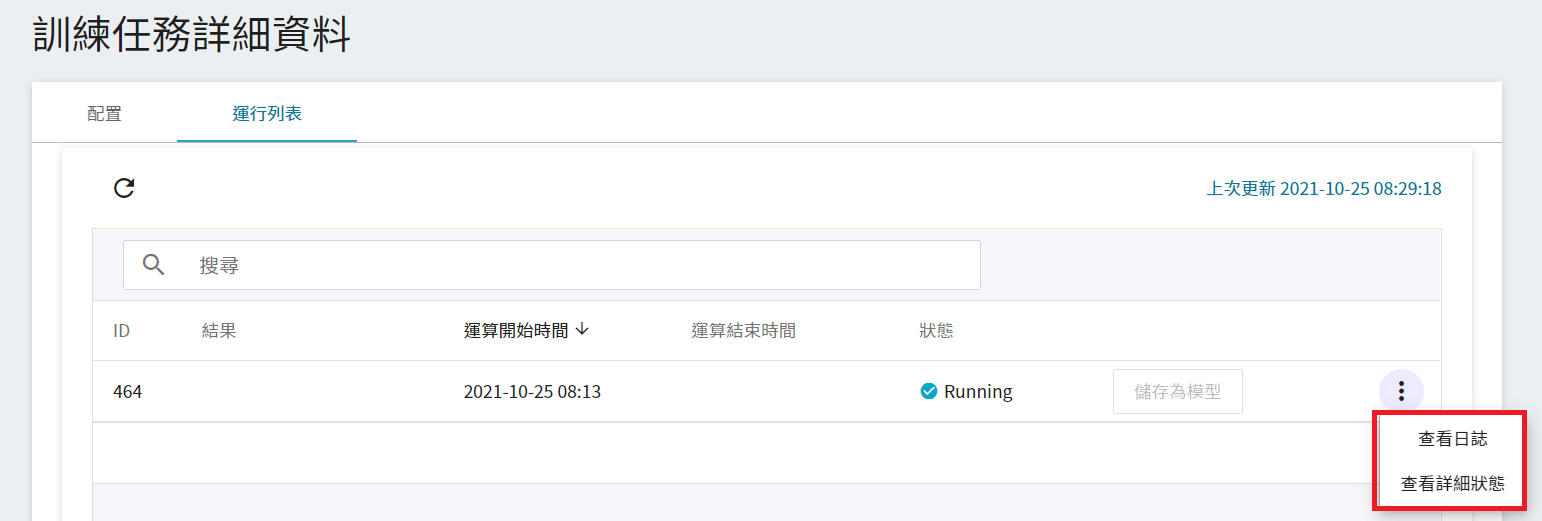
### 2.3 檢視訓練結果並儲存模型
訓練任務運算完成後,在運行列表中的該工作項目會變成 **`Completed`**,並會顯示運算結果。
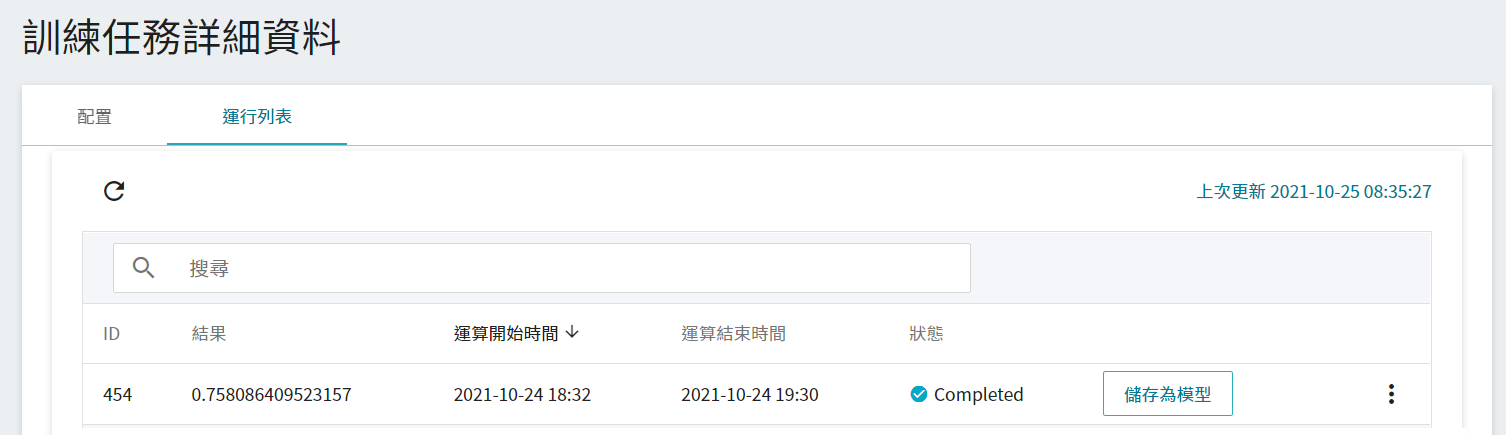
訓練完畢後,將符合預期分數的模型儲存至 **模型儲存庫** 中;若分數不盡理想,則重新調整環境變數與超參數的數值或數值範圍,直到出現合適的模型。
接下來介紹如何將達到預期的模型儲存至模型儲存庫:
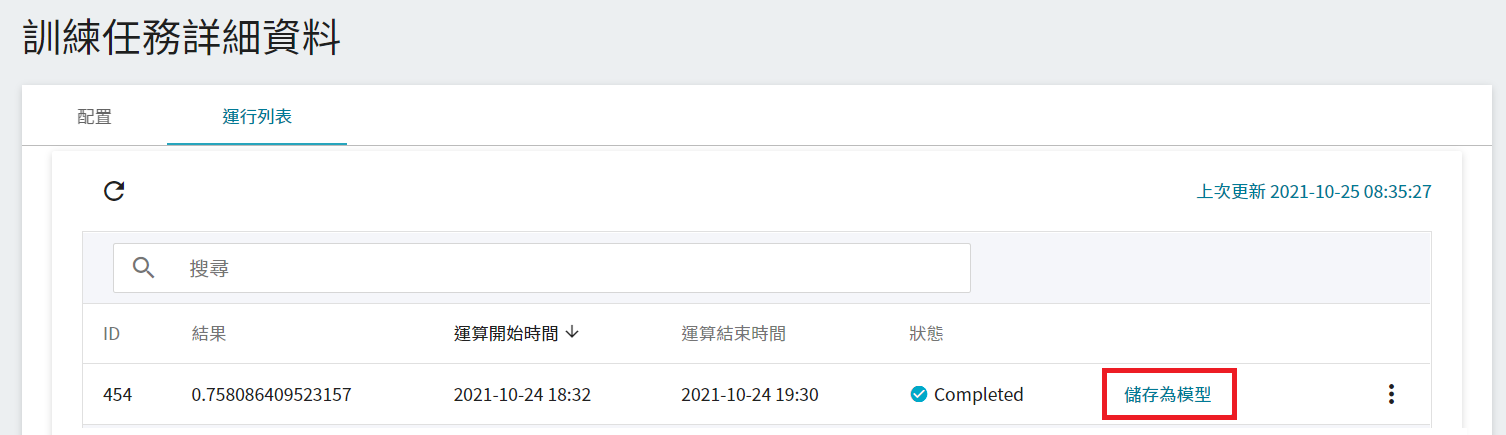
1. **點選儲存為模型**
點擊欲儲存的訓練結果右側的「**儲存為模型**」按鈕。
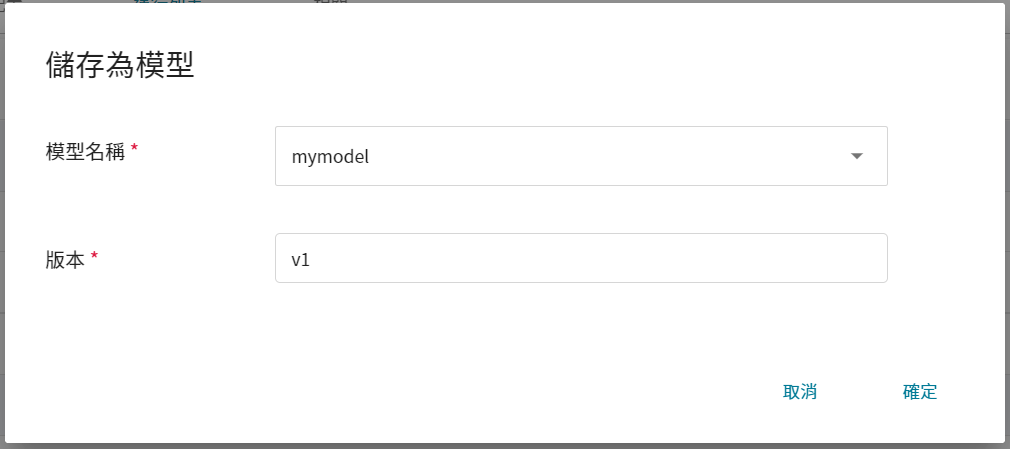
2. **輸入模型名稱與版號**
接著會出現一個對話框,請依照指示輸入模型名稱和版本,完成後點擊確定。
:::info
:alarm_clock: **小提醒:** 此訓練的模型略大,儲存需要點時間,請稍等一下。
:::
3. **查看模型**
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**模型**」,進入模型管理頁面後,可在列表中找到該模型。
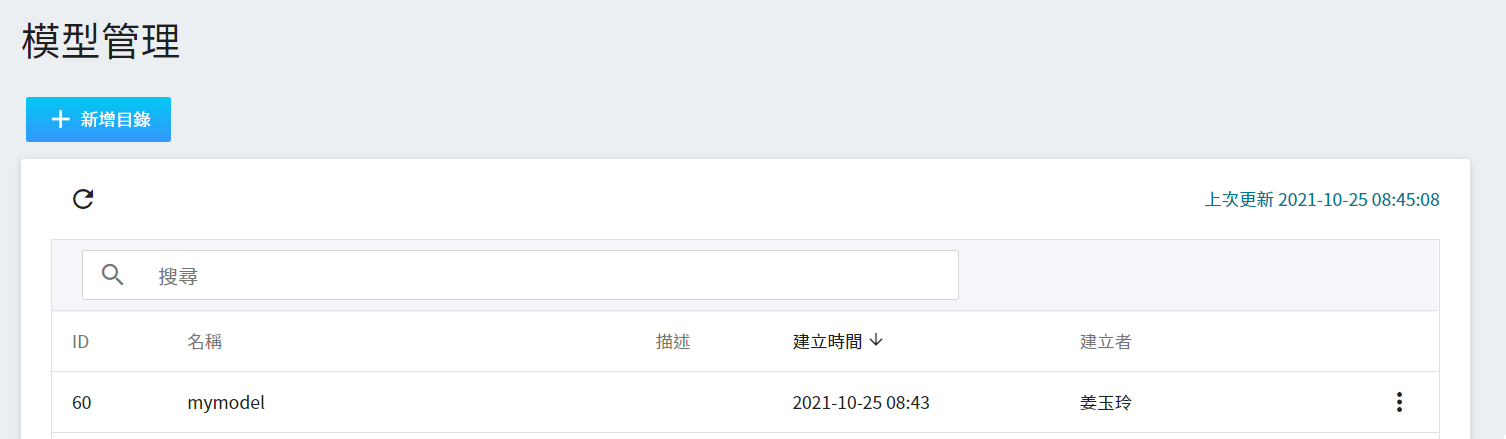
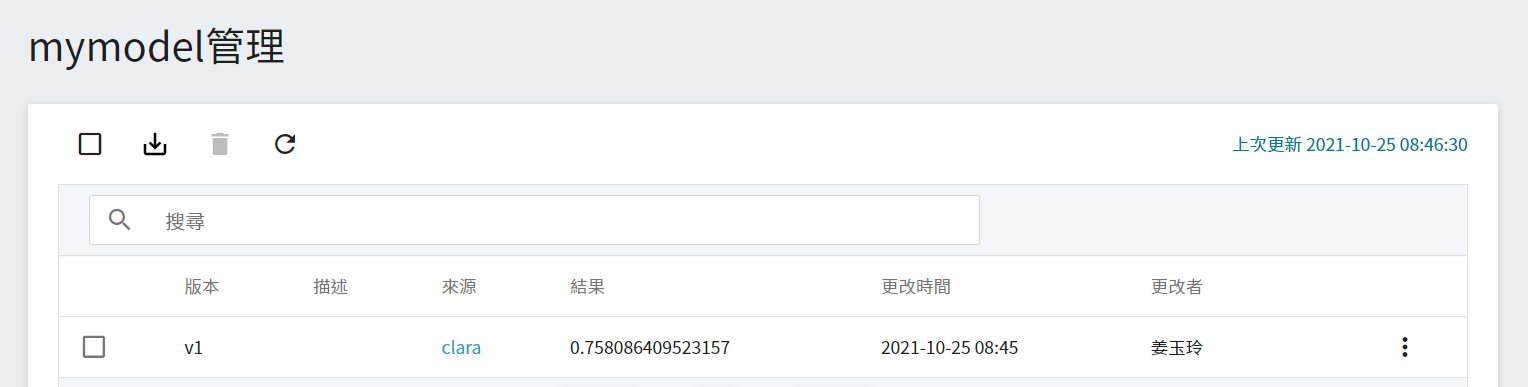
點擊該模型進入模型的版本列表,在這裡可以看到所儲存模型的所有版號,與其相對的訓練任務與結果… 等資訊。
## 3. 建立推論服務
當您完成分割技術模型的訓練後,我們可以部署 **推論功能** 以架設 AIAA Server(AIAA-AI Assisted Annotation Server)。
<center> <img src="/uploads/WIPLz1J.png" alt="AIAA"></center>
<center>AIAA(圖片來源: NVIDIA)</center>
<br>
### 3.1 建立推論
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**推論**」,進入推論管理頁面,並按下「**+建立**」,建立一個推論任務。
推論服務的建立步驟說明如下:
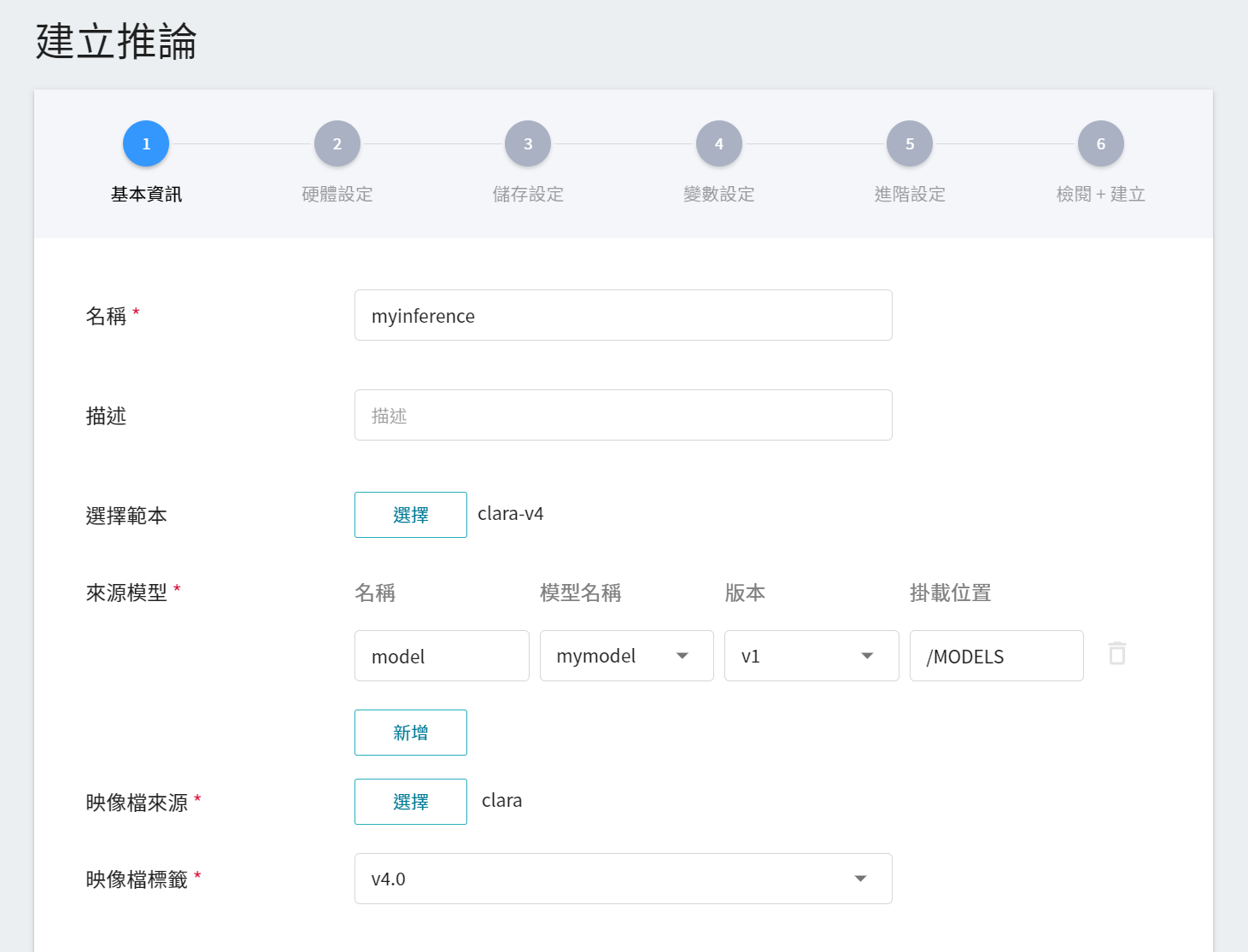
1. **基本資訊**
與訓練任務的基本資訊的設定相似,我們也是使用 **`clara-v4`** 的推論範本,方便開發者快速設定。但是,所要載入的模型名稱與版號仍須使用者手動設定:
- **名稱**
載入後模型的檔案名稱,與程式進行中的讀取有關。這值會由 **`clara-v4`** 推論範本設定。
- **模型名稱**
所要載入的模型名稱,即我們在 [**2.3 檢視訓練結果並儲存模型**](#23-檢視訓練結果並儲存模型) 中所儲存的模型。
- **版本**
所要載入模型的版號,亦是 [**2.3 檢視訓練結果並儲存模型**](#23-檢視訓練結果並儲存模型) 中所設定的版號。
- **掛載位置**
載入後模型所在位置,與程式進行中的讀取有關,這值會由 **`clara-v4`** 推論範本設定。
2. **硬體設定**
參考目前的可用配額與訓練程式的需求,從列表中選出合適的硬體資源。
3. **儲存設定**
此步驟無須設定。
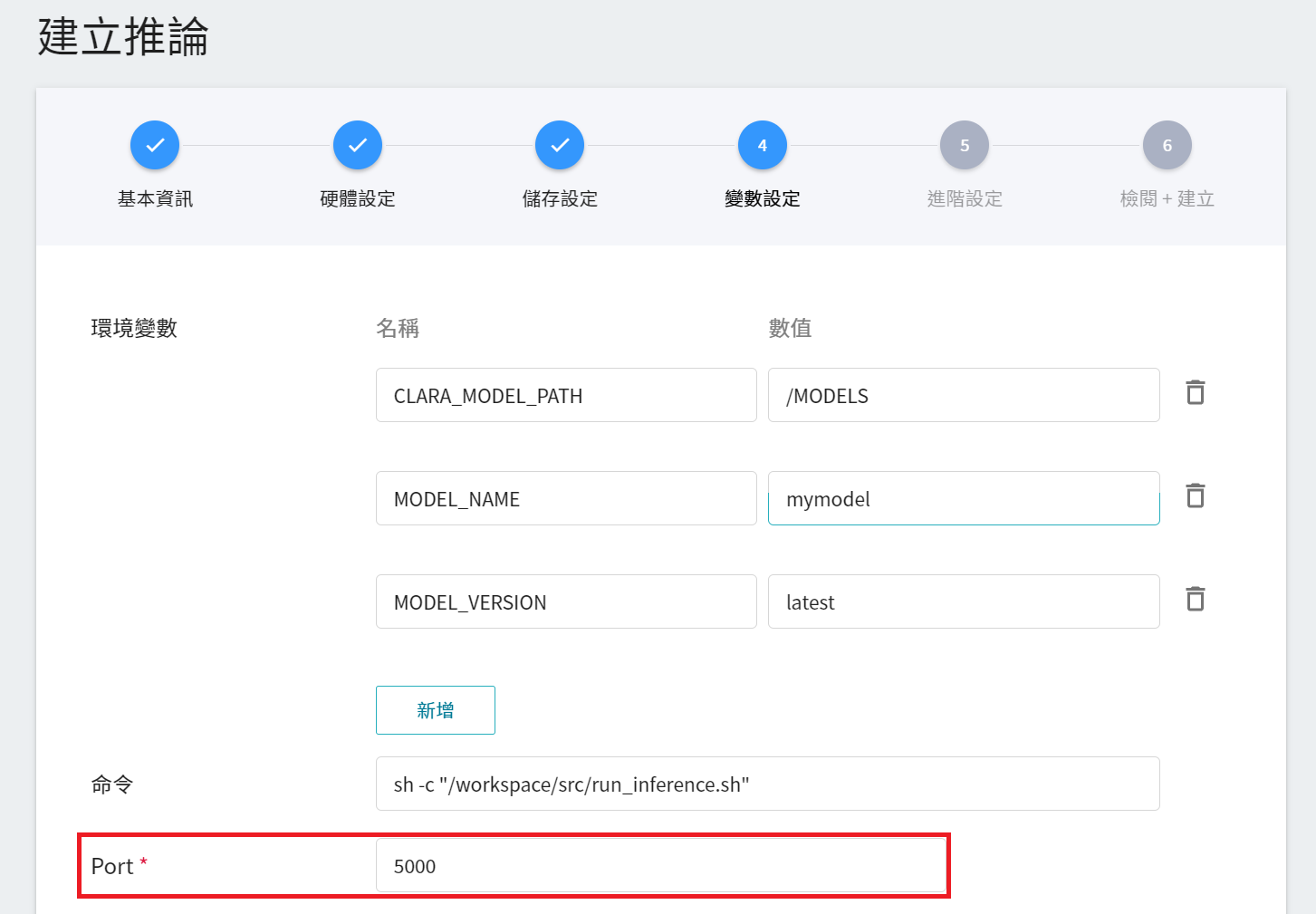
4. **變數設定**
在變數設定步驟,相關變數會由 **`clara-v4`** 範本自動帶入,**`Port`** 請設定為 5000。
5. **進階設定**
此步驟無須設定。
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
### 3.2 查詢推論資訊
建立完成推論任務後,返回推論管理頁面,點擊剛剛建立的任務,檢視該服務的詳細設定。當服務的狀態顯示為 **`Ready`** 時,即可以開始使用 AIAA Client 進行推論。不過在這些詳細資料中,有些資訊需請您留意,之後在使用 AIAA Client 時會用到這些資訊:
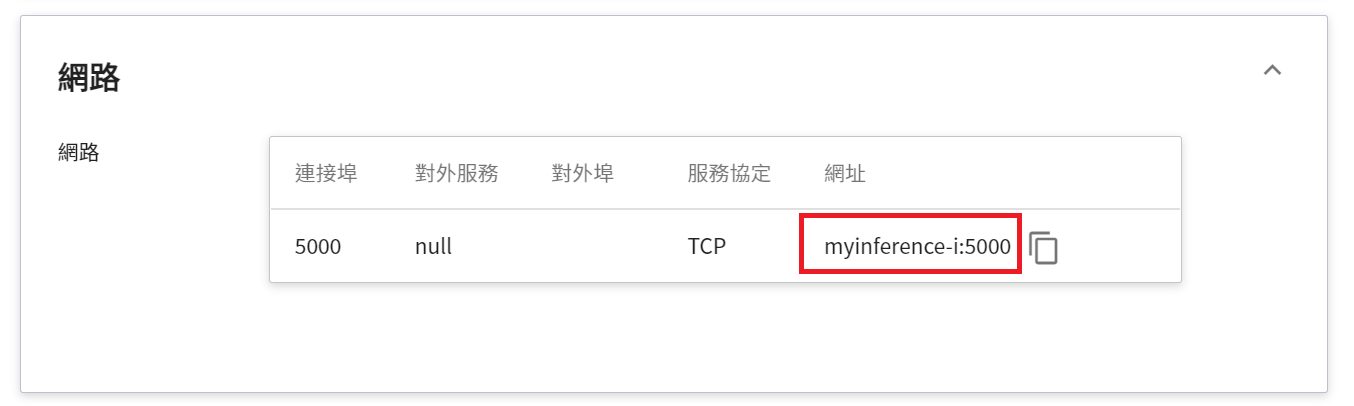
1. **網路**
由於目前推論服務為了安全性的考量沒有開放對外的服務埠,但我們可以透過「**容器服務**」來跟我們的已經建立好的推論服務溝通,溝通的方式就是透過推論服務提供的「**網址**」,在下一章節會說明如何使用。
:::info
:bulb: **提示:** 文件中的網址僅供參考,您所取得的網址可能會與文件中的不同。
:::
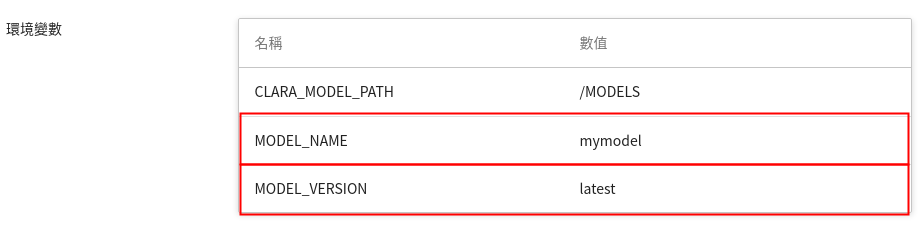
2. **模型**
另外一個需要注意的是,在環境變數中的 **MODEL_NAME** 與 **MODLE_VERSION**,是在程式中,或說是服務內部,對我們所匯入的模型與版號的稱呼。
## 4. AIAA Client - 3D Slicer
當您完成推論服務的啟動時,也就完成 AIAA Server 的啟動,如此一來就可以在本地端的 AIAA Client 進行相關工作。
這邊使用 [**3D Slicer**](https://www.slicer.org/) 作為操作範例,示範如何與推論服務進行串接。若您有 3D Slicer 的下載與安裝的疑問,請參考 [**3D Slicer 官網**](https://download.slicer.org/)。
### 4.1 **建立容器服務**
由於推論服務為了安全性的考量所以沒有開放對外的服務埠,所以我們需要透過容器服務跟建立好的推論服務溝通。
從 OneAI 服務列表點選「**容器服務**」進入容器服務管理頁面後,點擊「**+建立**」。
1. 基本資訊
在建立容器服務時,可以直接挑選 **`clara-nginx`** 映像檔。
2. **硬體設定**
選擇硬體設定,在資源的選擇時,考慮到資源的使用狀況,可以不用配置 GPU。
3. **儲存設定**
此步驟無須設定。
4. **網路設定**
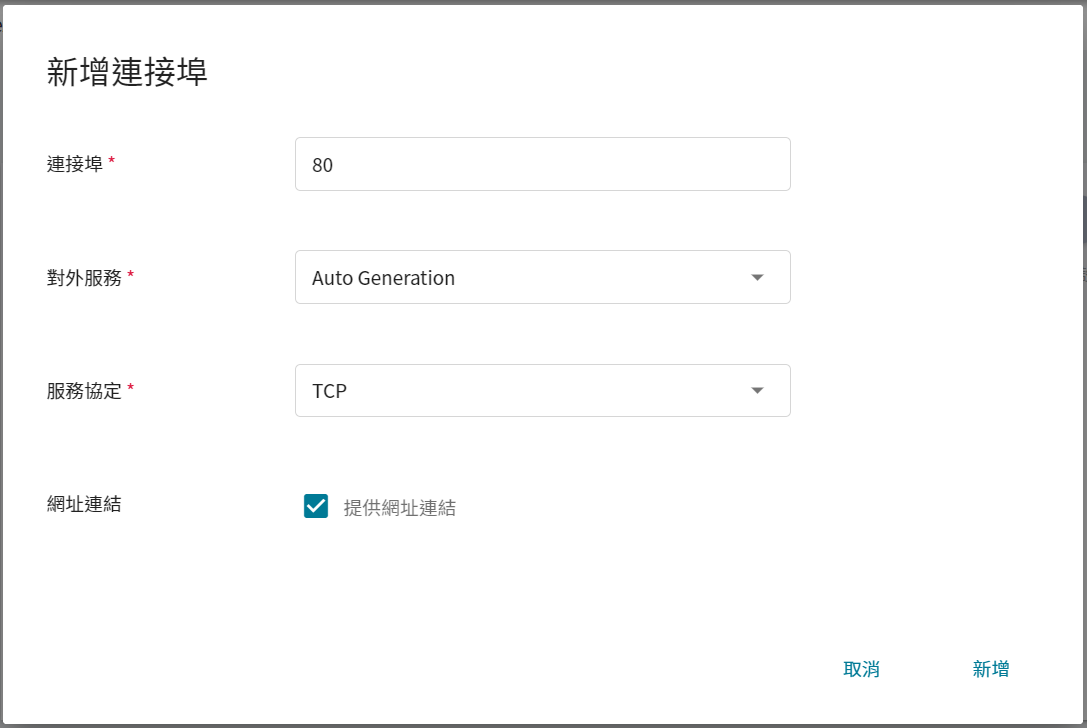
**連接埠** 請設定為 **80**,讓它自動產生對外的服務埠,並且勾選 **提供網址連結**。
5. **變數設定**
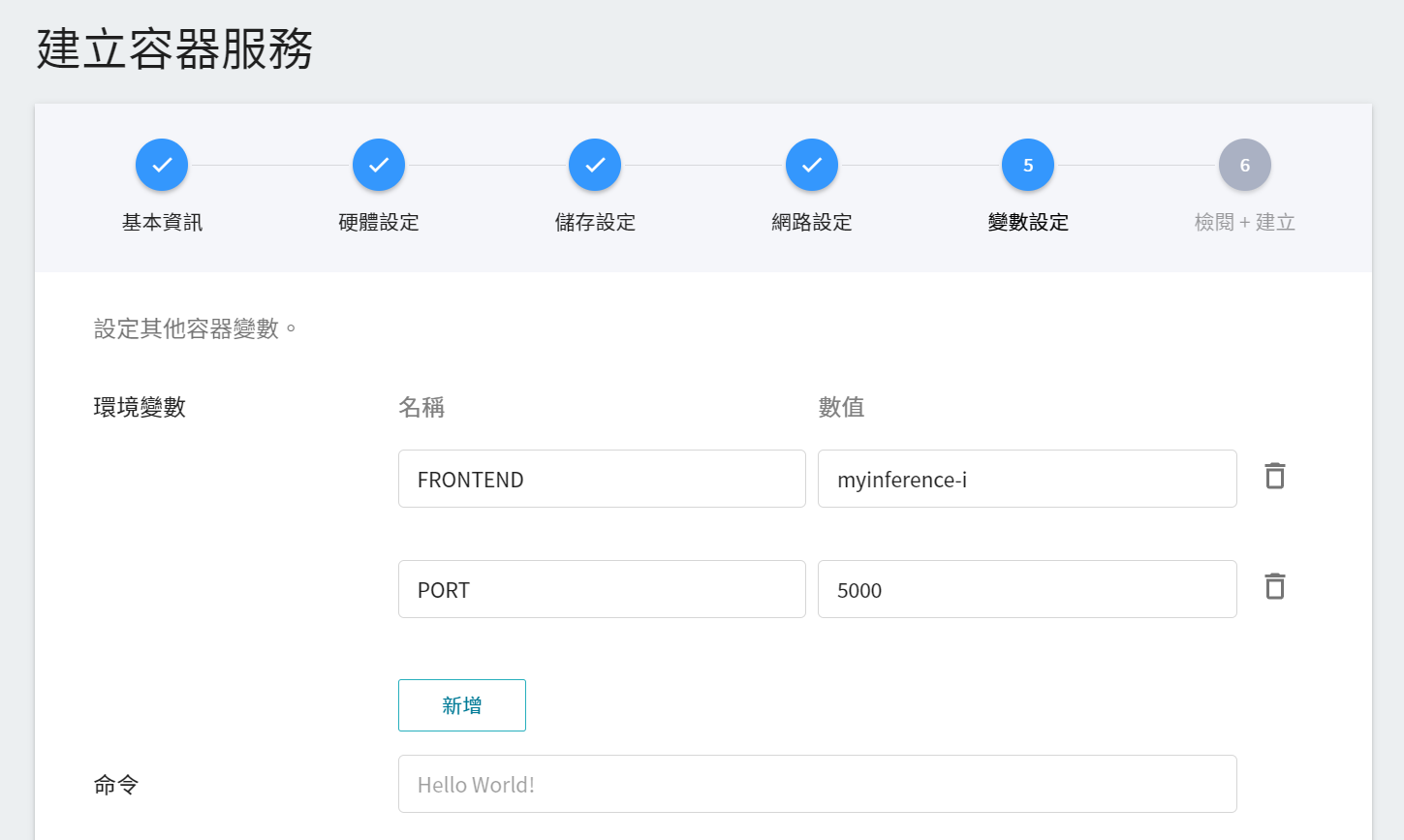
新增兩個環境變數 **`FRONTEND`** 以及 **`PORT`**,並依推論服務取得的網址設定。本範例 **`FRONTEND`** 為 **`myinference-i`**,**`PORT`** 為 `5000`。
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
7. **查看對外服務**
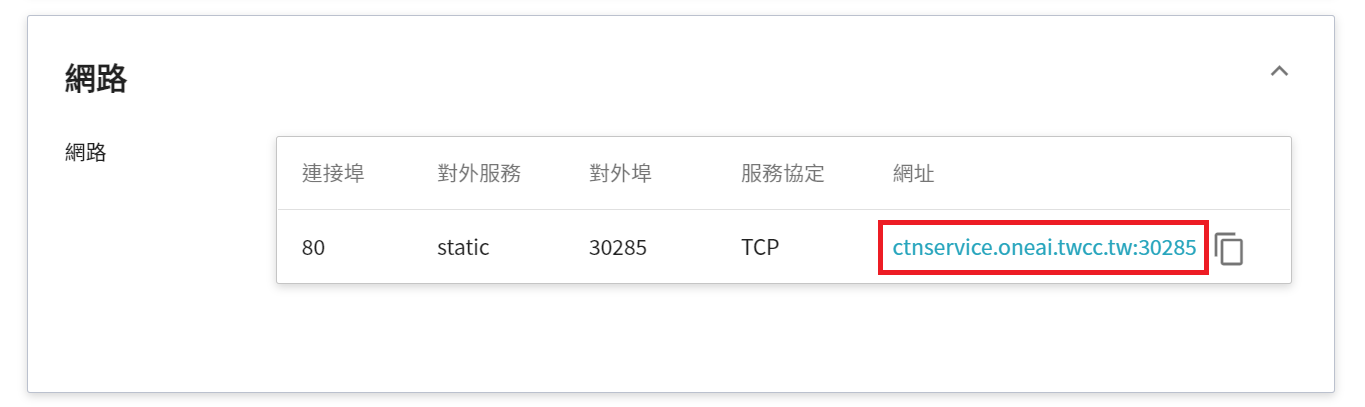
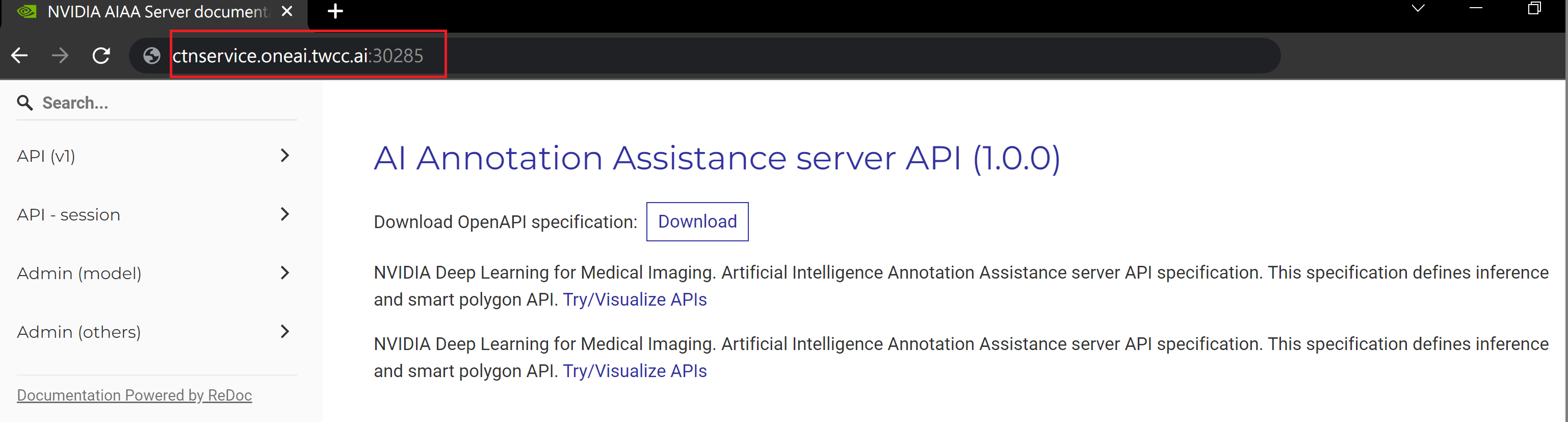
完成容器服務的建立後,回到容器服務管理列表頁面,點擊該服務可以取得詳細資訊。請注意下圖紅框中的網址,此為 **NVIDIA AIAA Server** 對外服務的網址,點擊此網址連結可在瀏覽器分頁中確認 NVIDIA AIAA Server 服務是否正常啟動;點擊右側的 **複製** 圖示可複製此網址連結,接下來會介紹如何 **使用 3D Slicer**。
### 4.2 **使用 3D Slicer**
:::info
:bulb:**提示:** 以下 3D Slicer 設定畫面以 4.11 版本為例,若使用其他版本,請參照 [**3D Slicer 官網說明**](https://www.slicer.org/)。
:::
1. **安裝 NVIDIA Plug-in**
在開始前需要先安裝 NVIDIA Plug-in,才能進行後面步驟的操作。開啟 3D Slicer 後請先點選 **`View` > `Extension Manager`**。
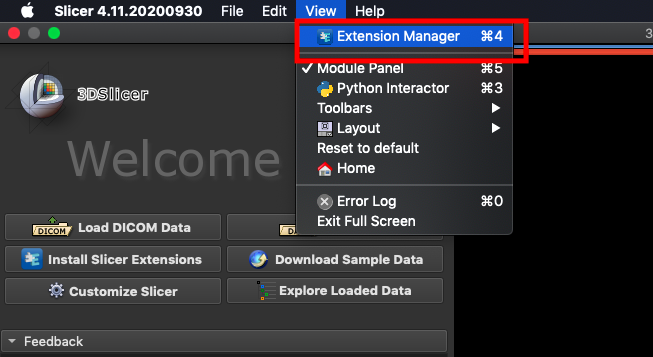
點擊 **`Install Extensions`** 並搜尋 `nvidia`。此時,會出現 NVIDIA Clara 的 AI-Assisted Annotation Extension,請點選安裝,並重新開啟 3D Slicer。
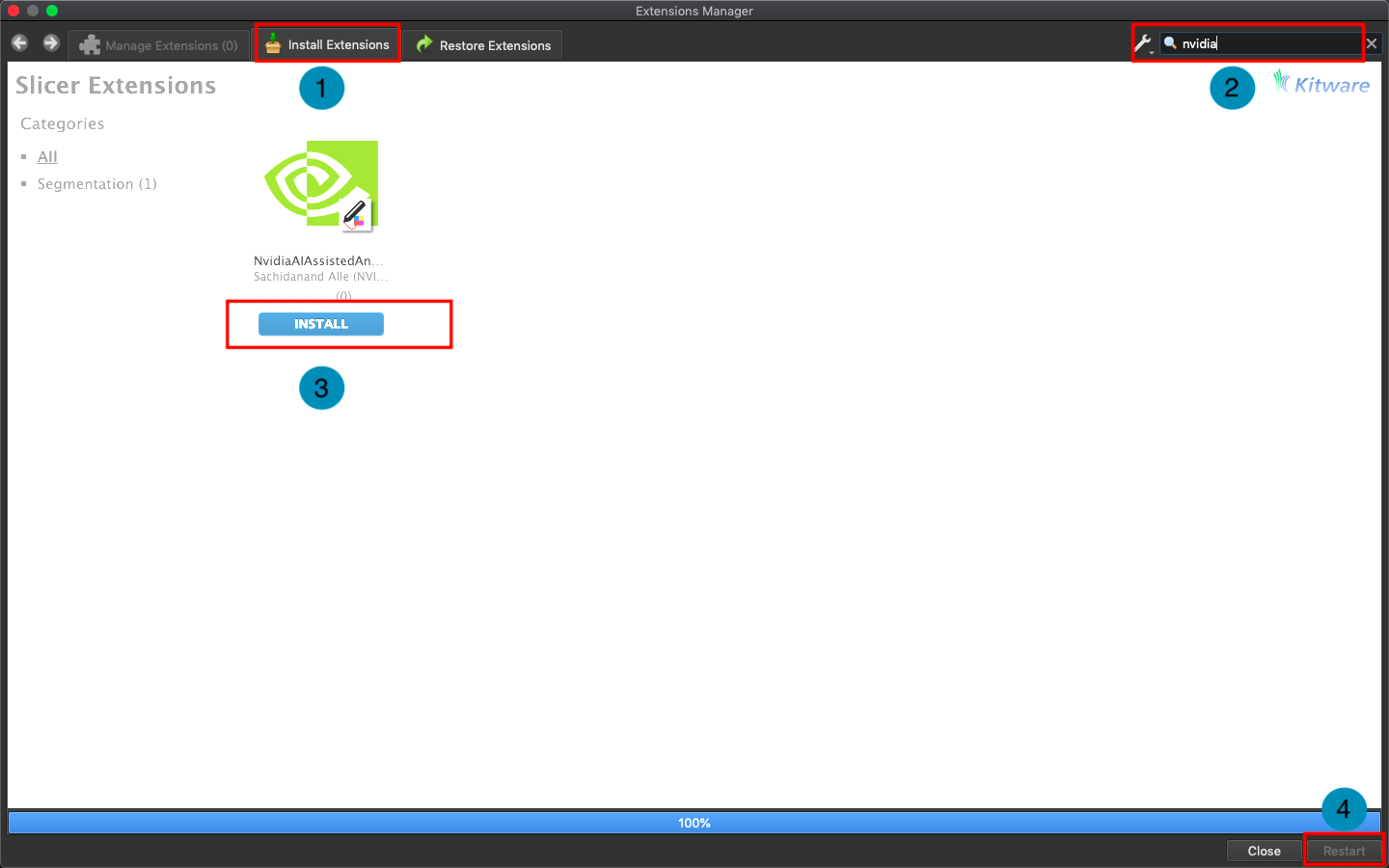
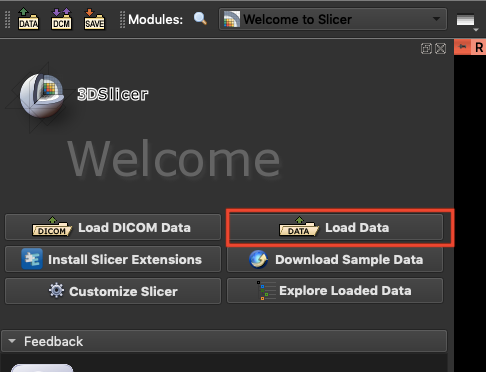
2. **載入欲切割的資料**
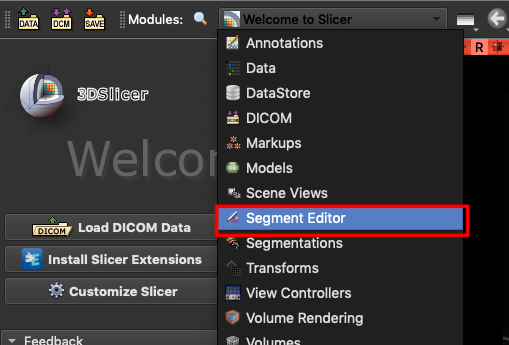
接下來點選 **`Load Data`**,載入我們要切割的脾臟資料。
並調出 **`Segment Editor`**。
3. **連接推論服務**
在 **`Effects`** 區域中,選擇 **`Nvidia AIAA`**。
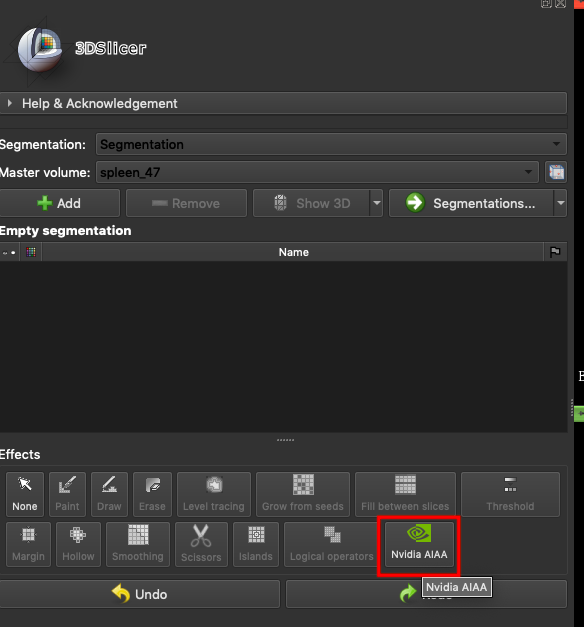
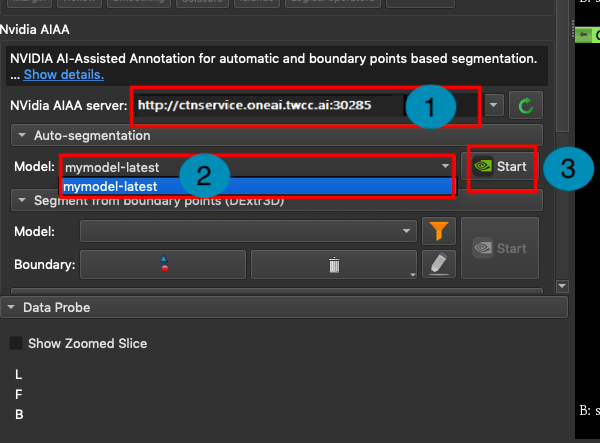
在 **NVIDIA AIAA server** 欄位中需填入上一小節中複製的 **NVIDIA AIAA server** 網址,例如:**`http://ctsservice.oneai.twcc.ai:30285`**。另一個需要設定的是 **Model** 欄位,若 NVIDIA AIAA server 服務設定正確,從 **Model** 下拉選單中會出現在前一步驟環境變數中所定義的名稱與版號,例如:**mymodel-latest**,選取後點擊「**Start**」按鈕即可開始進行推論。
:::info
:bulb: **提示:** 文件中的網址僅供參考,您所取得的網址可能會與文件中的不同。
:::
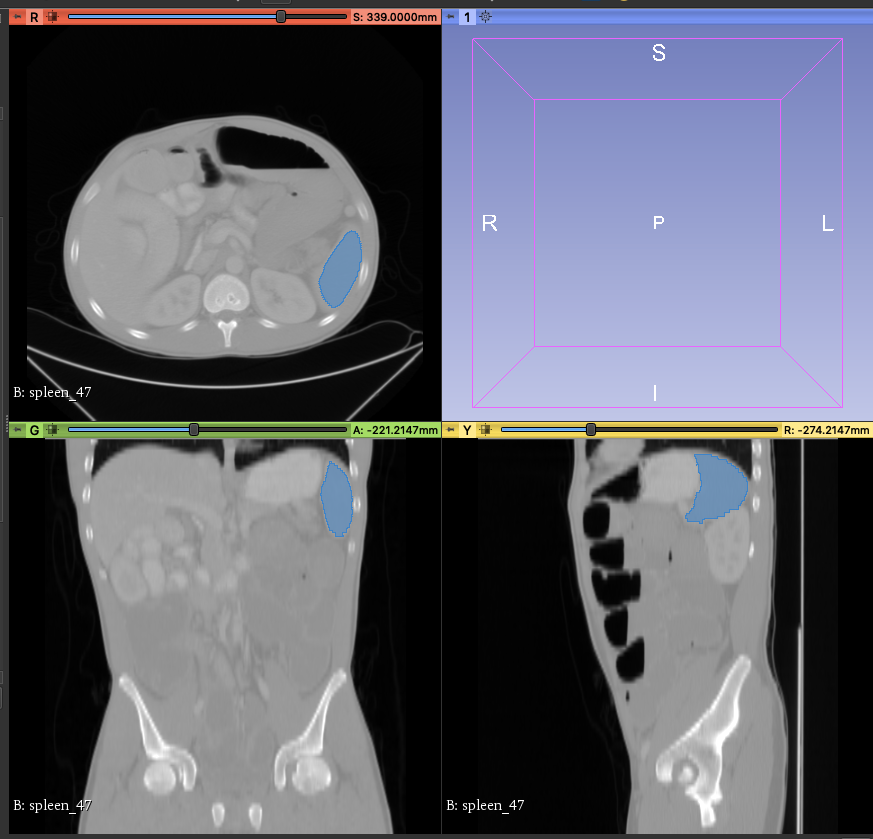
4. **標註輔助**
此時您會看到,CT 影像中多了藍色標註的區域,這些藍色區域即是您選擇的模型推論出來的脾臟位置結果。
## 5. AIAA Client - Jupyter
若您沒有安裝如:**3D Slicer** 或是 OHIF 等醫學影像處理軟體,可以使用 **Jupyter Notebook** 來調用推論服務。
### 5.1 啟動 Jupyter Notebook
這節主要介紹如何使用 「**容器服務**」來啟動 Jupyter Notebook。
#### 5.1.1 建立容器服務
從 OneAI 服務列表中點選「**容器服務**」進入容器服務管理頁面後,點擊「**+建立**」。
1. **基本資訊**
在建立容器服務時,可以直接挑選 **`clara:v4.0`** 映像檔,在這份映像檔中我們已經提供 Jupyter Notebook 的相關環境。
2. **硬體設定**
選擇硬體設定,在資源的選擇時,考慮到資源的使用狀況,可以不用配置 GPU。
3. **儲存設定**
為了方便後續取得脾臟的 CT 影像進行推論,在儲存步驟中,我們直接選取原來的脾臟資料集儲存體作為推論之用。

4. **網路設定**
在使用 Jupyter Notebook 服務時,預設會運行在 8888 的連接埠,為了能順利從外部尋訪使用 Jupyter Notebook,因此需要設定對外公開的服務埠。另外,為了方便起見我們將 SSH 所使用的連接埠 22 也一併開啟。
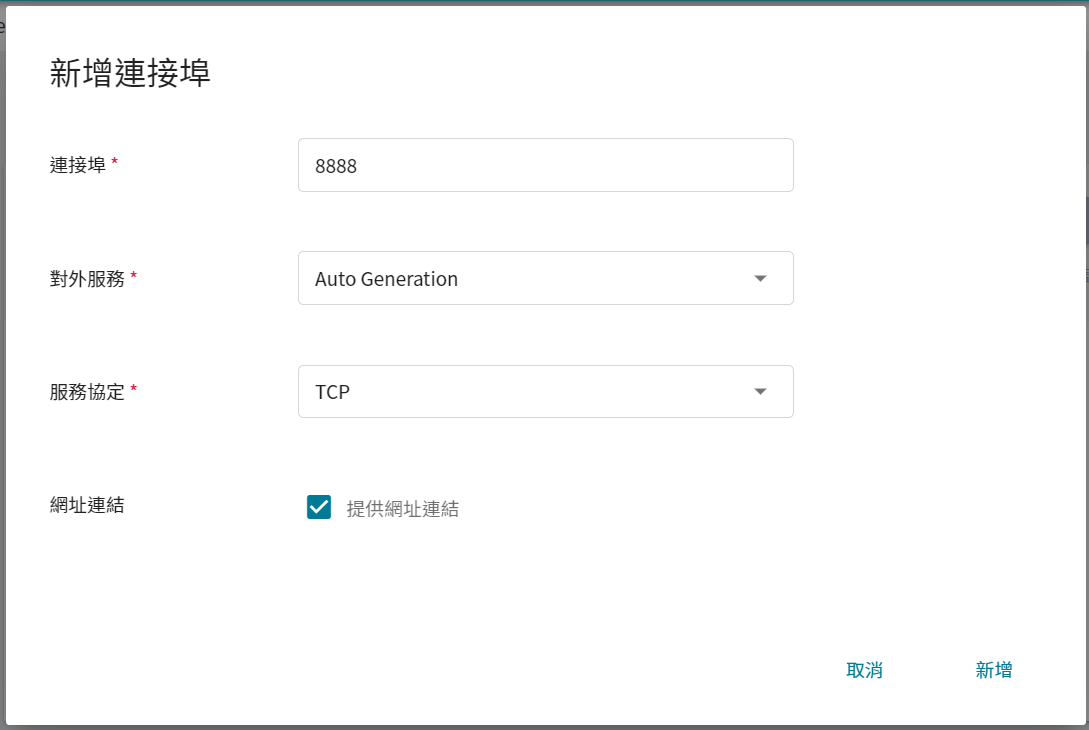

5. **變數設定**
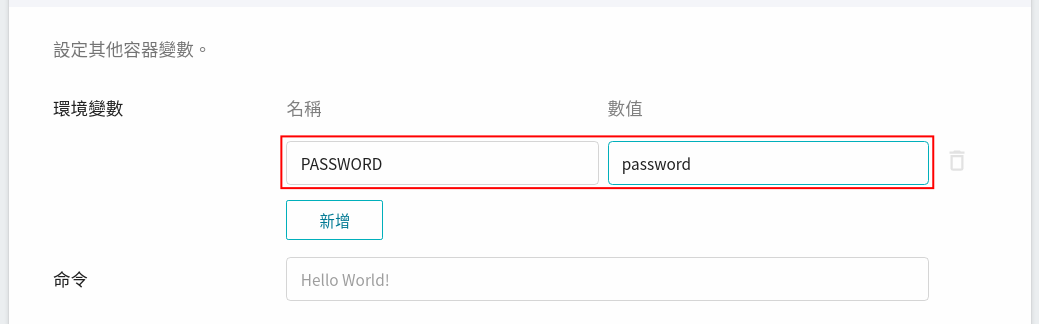
在使用 Jupyter Notebook 時,會需要輸入密碼,因此在這邊,可以使用我們在映像檔中所設定的環境變數,來設定密碼。
6. **建立**
完成以上的設定後,最後檢閱確認所填寫的資訊,就可按下建立。
#### 5.1.2 **使用 Jupyter Notebook**
完成容器服務的建立後,回到容器服務管理列表頁面,點擊該服務可以取得詳細資訊:
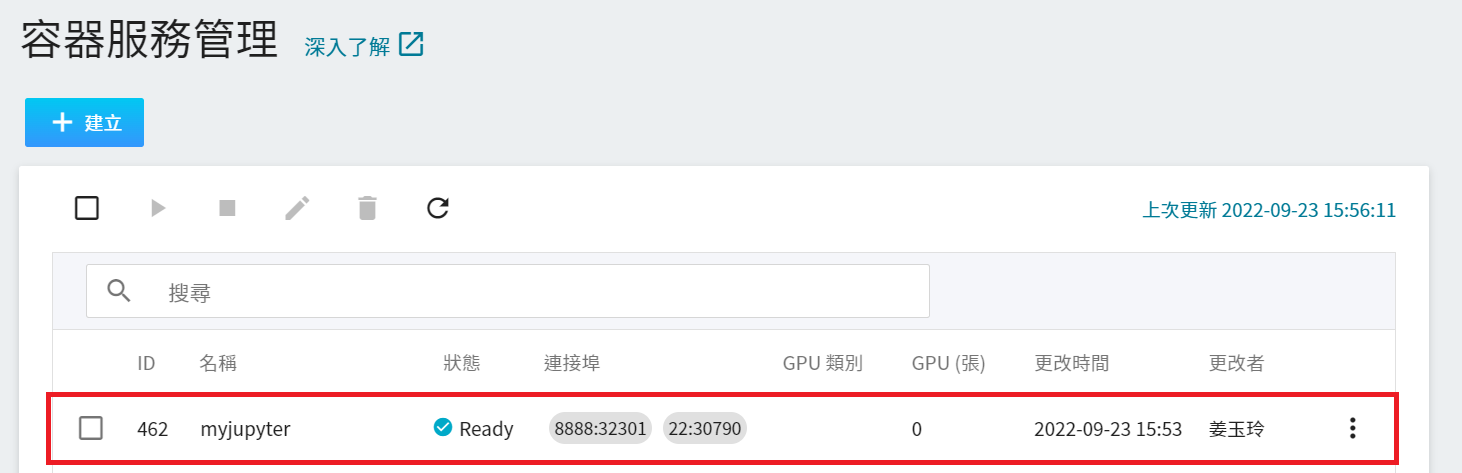
在詳細資料頁面中,需要特別注意的是 **網路** 區塊,在這區塊中有 Jupyter Notebook 服務埠 `8888` 的對外埠,點擊網址連結即可在瀏覽器中開啟 Jupyter Notebook 服務。
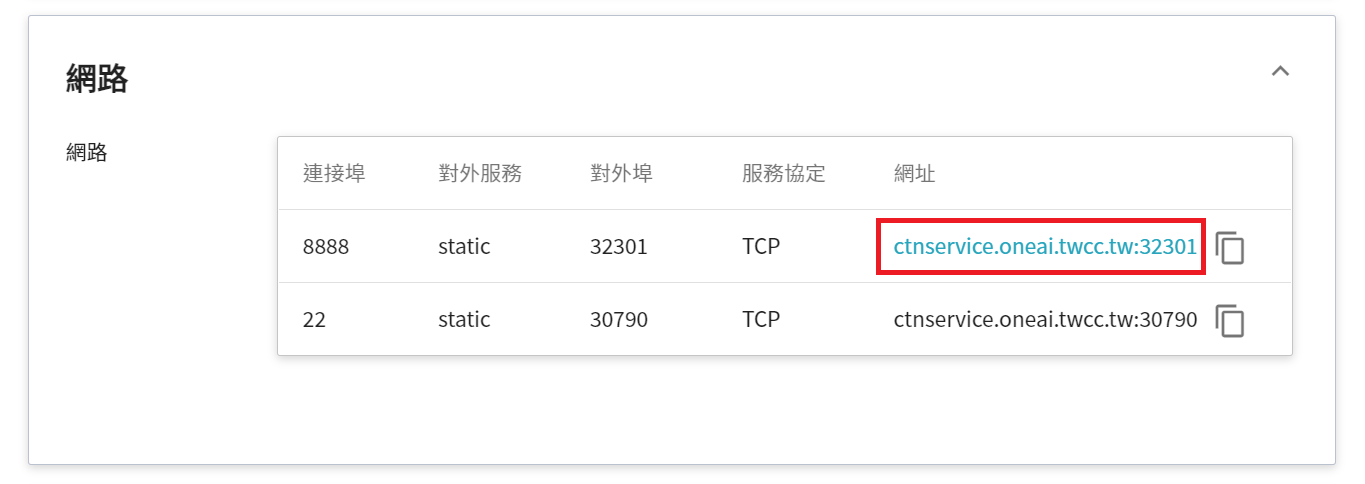
出現 Jupyter 服務的登入頁面後,請輸入在 **變數設定** 步驟中設定的 **`PASSWORD`** 變數值。

至此我們就完成了 Jupyter Notebook 的啟動。
### 5.2 進行推論
若您是使用容器服務所建立的 Jupyter Notebook,在 `src` 目錄下的 `inference` 資料夾中,可以看到已經存在一份名為 `inference.ipynb` 的程式檔,您可以直接修改這份程式碼中的 url 再進行推論。
本範例是使用 NVIDIA 所提供 [NVIDIA AI-Assisted Annotation Client](https://github.com/NVIDIA/ai-assisted-annotation-client/tree/71dee28405f58b3d2db001644c480550a9b3f0ba/py_client) 來實作,如需更多資訊,請參閱 [**NVIDIA AI-Assisted Annotation Client 官方文件**](https://docs.nvidia.com/clara/aiaa/sdk-api/docs/index.html)。
1. **AIAA Client object**
先使用 API 取回一個 AIAA Client 的構造器,這個構造器會包括一些 server 的訊息。 url 的值請改成在 [**3.2 查詢推論資訊**](#32-查詢推論資訊) 步驟取得的網址。
:::info
:bulb: **提示:** 文件中的網址僅供參考,您所取得的網址可能會與文件中的不同。
:::
```python
import client_api
#user config
url = "http://myinference-i:5000"
client = client_api.AIAAClient(server_url=url)
```
<br>
例如用 `model_list` 可以取回一些所支援模型的資訊。
```python
models = client.model_list()
[{'name': 'mymodel-latest', 'labels': ['spleen'], 'description': 'A pre-trained model for volumetric (3D) segmentation of the spleen from CT image', 'version': '2', 'type': 'segmentation'}]
```
<br>
3. **segmentation**
由於我們訓練的模型適用於分割技術,在選擇執行方法的時要要選用 `segmentation`,在呼叫時須傳入選用的模型與圖片,並指定醫學影像,最後告知切割結果寫出的位置。
這邊稍微注意一下,指定要使用的模型名稱,這裡所使用的模型名稱是我們在 [**3.2 小節**](#32-查詢推論資訊) 建立推論服務時所宣告的環境變數 - **MODEL_NAME** 與 **MODLE_VERSION**,分別是 **mymodel** 與 **latest**。當然您也可以用 `model_list` 看到這些資訊。
```python
model_name = "mymodel-latest"
image_in = '/dataset/imagesTr/spleen_47.nii.gz'
image_out = '/tmp/spleen_inf.nii.gz'
client.segmentation(
model= model_name,
image_in=image_in,
image_out=image_out)
```
<br>
當取回結果時,可繪製影像標註區塊。
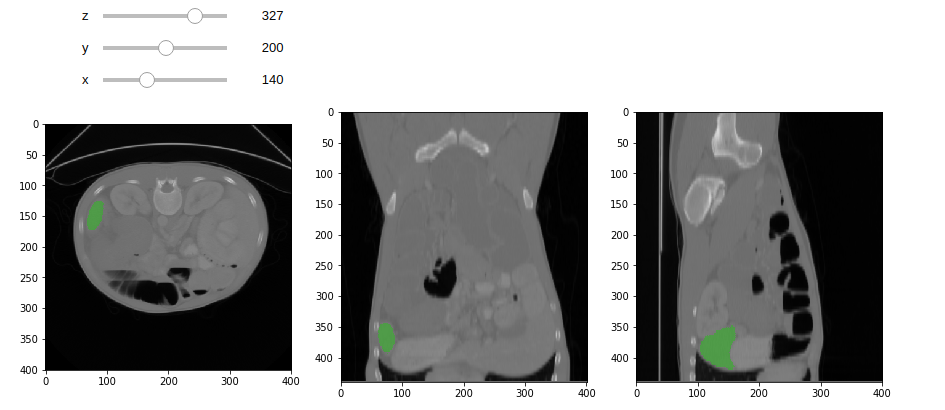
<br>
### 5.3 附件程式碼
1. :::spoiler **inference.ipynb**
```python=1
import client_api
#user config
url = "http://myinference-i:5000"
client = client_api.AIAAClient(server_url=url)
model_name = "mymodel-latest"
image_in = '/dataset/imagesTr/spleen_47.nii.gz'
image_out = '/tmp/spleen_inf.nii.gz'
models = client.model_list()
print(models)
client.segmentation(
model= model_name,
image_in=image_in,
image_out=image_out)
%matplotlib inline
import matplotlib.pyplot as plt
import SimpleITK as sitk
from myshow import myshow, myshow3d
rawImage = sitk.ReadImage(image_in)
# 讀取影像標註檔案
anoImage = sitk.ReadImage(image_out)
# 將影像轉為 8 位元無號整數
rawImageUint8 = sitk.Cast(sitk.RescaleIntensity(rawImage,
outputMinimum=0, outputMaximum=255), sitk.sitkUInt8)
# 套疊標註影像
overlay = sitk.LabelOverlay(rawImageUint8, anoImage, opacity=0.4)
myshow(overlay)
```
:::
2. :::spoiler **myshow.ipynb**
```python=1
import SimpleITK as sitk
import matplotlib.pyplot as plt
from ipywidgets import interact, interactive
from ipywidgets import widgets
def myshow(img, title=None, margin=0.05, dpi=80 ):
nda = sitk.GetArrayFromImage(img)
spacing = img.GetSpacing()
slicer = False
if nda.ndim == 3:
# fastest dim, either component or x
c = nda.shape[-1]
# the the number of components is 3 or 4 consider it an RGB image
if not c in (3,4):
slicer = True
elif nda.ndim == 4:
c = nda.shape[-1]
if not c in (3,4):
raise RuntimeError("Unable to show 3D-vector Image")
# take a z-slice
slicer = True
if (slicer):
ysize = nda.shape[1]
xsize = nda.shape[2]
else:
ysize = nda.shape[0]
xsize = nda.shape[1]
# Make a figure big enough to accomodate an axis of xpixels by ypixels
# as well as the ticklabels, etc...
figsize = (1 + margin) * ysize / dpi, (1 + margin) * xsize / dpi
def mycallback(z=None,y=None,x=None):
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
plt.set_cmap("gray")
axs[0].imshow(nda[z,:,:],interpolation=None)
axs[1].imshow(nda[:,y,:],interpolation=None)
axs[2].imshow(nda[:,:,x],interpolation=None)
plt.show()
def callback(z=None,y=None,x=None):
extent = (0, xsize*spacing[1], ysize*spacing[0], 0)
fig = plt.figure(figsize=figsize, dpi=dpi)
# Make the axis the right size...
ax = fig.add_axes([margin, margin, 1 - 2*margin, 1 - 2*margin])
plt.set_cmap("gray")
if z is None:
ax.imshow(nda,extent=extent,interpolation=None)
else:
ax.imshow(nda[z,...],extent=extent,interpolation=None)
if title:
plt.title(title)
plt.show()
if slicer:
interact(mycallback, z=(0,nda.shape[0]-1),y=(0,nda.shape[1]-1),x=(0,nda.shape[2]-1))
else:
callback()
def myshow3d(img, xslices=[], yslices=[], zslices=[], title=None, margin=0.05, dpi=80):
size = img.GetSize()
img_xslices = [img[s,:,:] for s in xslices]
img_yslices = [img[:,s,:] for s in yslices]
img_zslices = [img[:,:,s] for s in zslices]
maxlen = max(len(img_xslices), len(img_yslices), len(img_zslices))
img_null = sitk.Image([0,0], img.GetPixelID(), img.GetNumberOfComponentsPerPixel())
img_slices = []
d = 0
if len(img_xslices):
img_slices += img_xslices + [img_null]*(maxlen-len(img_xslices))
d += 1
if len(img_yslices):
img_slices += img_yslices + [img_null]*(maxlen-len(img_yslices))
d += 1
if len(img_zslices):
img_slices += img_zslices + [img_null]*(maxlen-len(img_zslices))
d +=1
if maxlen != 0:
if img.GetNumberOfComponentsPerPixel() == 1:
img = sitk.Tile(img_slices, [maxlen,d])
#TODO check in code to get Tile Filter working with VectorImages
else:
img_comps = []
for i in range(0,img.GetNumberOfComponentsPerPixel()):
img_slices_c = [sitk.VectorIndexSelectionCast(s, i) for s in img_slices]
img_comps.append(sitk.Tile(img_slices_c, [maxlen,d]))
img = sitk.Compose(img_comps)
myshow(img, title, margin, dpi)
```
:::
3. :::spoiler **client_api**
[原始碼](https://github.com/NVIDIA/ai-assisted-annotation-client/blob/71dee28405f58b3d2db001644c480550a9b3f0ba/py_client/client_api.py)
:::
<style>
mark {
background-color: pink;
color: black;
}
</style>