1135 views
owned this note
---
title: 案例教學 - 部署 NVIDIA Clara Federated Learning (聯合學習)
description: OneAI 文件
tags: 案例教學, Clara, 聯合學習
---
[OneAI 文件](/s/user-guide)
# 案例教學 - 部署 NVIDIA Clara Federated Learning (聯合學習)
[TOC]
## 前言
聯合學習(Federated Learning,簡稱 FL),又稱「聯邦式學習」或「聯盟學習」,聯合學習可以讓多個參與者能夠在不共享資料的情況下共同構建一個通用的、強大的機器學習模型,從而解決資料的隱私、安全、法規及地域性等問題,以模型共享取代資料共享的方式,藉由不同來源的大量資料及分散式訓練取得最佳的 AI 模型。聯合學習技術已應用於多個領域,包括醫療、電信、物聯網和製藥。
NVIDIA Clara™ Train 是專為醫療影像研究和人工智慧開發推出的應用程式開發架構,Clara Train SDK 支援預訓練模型、遷移學習、聯合學習和 AutoML 等技術。其中的聯合學習技術為多組織協作提供一套 Client-Server 主從架構的分散式訓練方法,每個 Client 負責訓練各自的模型,彼此獨立不共享資料,Server 負責整合多個模型,也可以調整不同 Client 的貢獻權重,來找到最佳的模型,並透過加密技術,保護資料隱私及安全。
<center><img src="/uploads/upload_ff8364b1bafdc0bf82c3e129f6790a5d.png" alt="NVIDIA Clara Train 聯合學習示意圖"></center>
<center>NVIDIA Clara Train 聯合學習示意圖</center>
<center><a href="https://github.com/NVIDIA/clara-train-examples/blob/master/PyTorch/NoteBooks/FL/FederatedLearning.ipynb">(圖片來源:NVIDIA)</a></center>
<br><br>
## 0. 開始使用
TWCC OneAI 提供 GPU 運算資源管理及多種工具,預載 NVIDIA Clara Train SDK,只要透過本範例教學的指引即可快速完成部署與連線,協助您輕鬆使用 Clara Train SDK 聯合學習,快速開發人工智慧模型。
本範例將使用 **OneAI 容器服務** 和 **儲存服務** 部署 Clara Train 聯合學習環境,範例中 FL Server 負責人在 TWCC OneAI 租用一個計畫部署 FL Server;其他家醫院或機構在 OneAI 租用各自的計畫部署 FL Client 加入聯合學習訓練,在此將部署 org1 中的 org1-a 和 org1-b 及 org2 三個 FL Client;FL Admin 可以由聯盟中的首席資料科學家擔任,在 OneAI 上租用另一個計畫部署 FL Admin,不同計畫間各自獨立,彼此不共享資料。為了方便體驗,本範例可以在同一個 OneAI 計畫中操作。
<center><img src="/uploads/upload_21c10541453f31128d93e1a00c71c5a6.png" alt="NVIDIA Clara Train 聯合學習部署架構"></center>
<center>聯合學習部署架構</center>
<br><br>
主要步驟如下:
1. [**Provision**](#1-Provision)
在此階段,計畫主持人規劃參與者的角色、權限及產生安裝包。
2. [**部署 FL Server**](#2-部署-FL-Server)
在此階段,我們將部署 FL Server,FL Server 協調聯合學習訓練,為 FL Client 和 FL Admin 連接的主要樞紐。
3. [**部署 FL Client**](#3-部署-FL-Client)
在此階段,我們將部署 3 個 FL Client,分別為 org1-a、org1-b 和 org2,以及準備每個 FL Client 的訓練資料集。
4. [**部署 FL Admin**](#4-部署-FL-Admin)
在此階段,我們會部署 FL Admin,透過 FL Admin 工具連線到 FL Server 及 FL Client 進行聯合學習的操作。
5. [**執行聯合學習訓練**](#5-執行聯合學習訓練)
在此階段,我們會執行聯合學習訓練,並取得各個 FL Client 的訓練結果及最佳模型。
:::warning
:warning: **注意事項**
1. 開始本範例前請先對 [**NVIDIA Clara Train SDK**](https://docs.nvidia.com/clara/clara-train-sdk/index.html) 有基本瞭解。
2. 本範例基於 [**NVIDIA Clara Train SDK 容器映像檔 V4.0**](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/clara-train-sdk) 及 [**Clara Train Examples**](https://github.com/NVIDIA/clara-train-examples) 範例程式、資料集和模型,使用前請詳閱 NVIDIA 的授權條款。
:::
<br>
## 1. Provision
Provision 階段是計畫主持人規劃參與者的角色、權限及產生安裝包,本章節將使用 Clara 內建的 project.yml 透過 Provision 工具程式產生每個站點的安裝包,請依照下列步驟操作。
### 1.1 預建 FL Server 容器
因為在 Provision 階段需設定 FL Server 所需的 fed_learn_port 和 admin_port 的服務埠,故開始 Provision 前我們先預建一個 FL Server 容器,以取得 FL Server 的兩個對外服務埠。
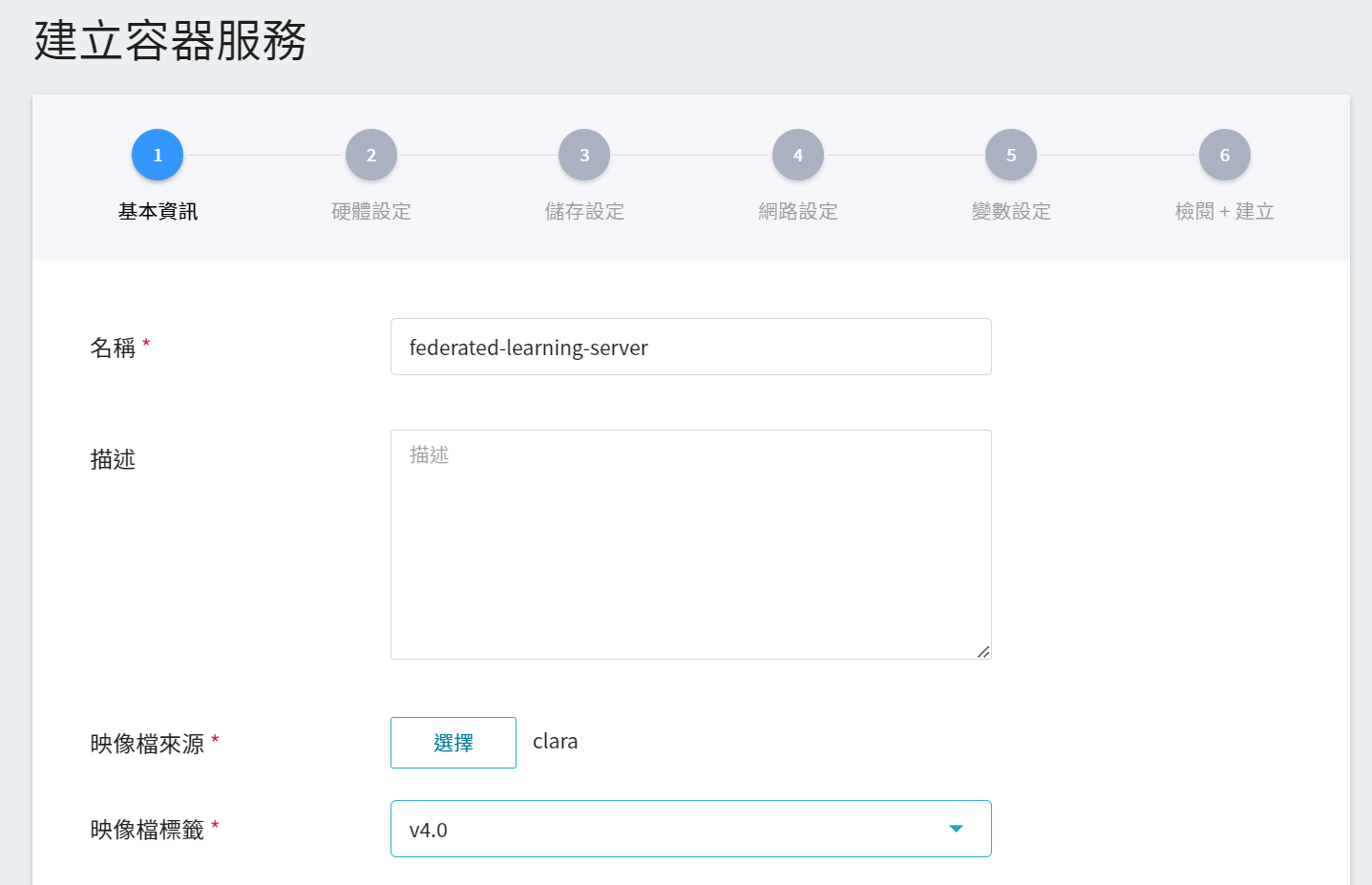
從 OneAI 服務列表選擇「**容器服務**」進入容器服務管理頁面,點擊「**+建立**」,新增一個容器服務。
1. **基本資訊**
請依序輸入 **名稱**,例如:**`federated-learning-server`**、**描述**,**映像檔** 請選擇 `clara:v4.0`。
2. **硬體設定**
選擇硬體規格,可以不用配置 GPU。
3. **儲存設定**
此步驟暫不需設定。
4. **網路設定**
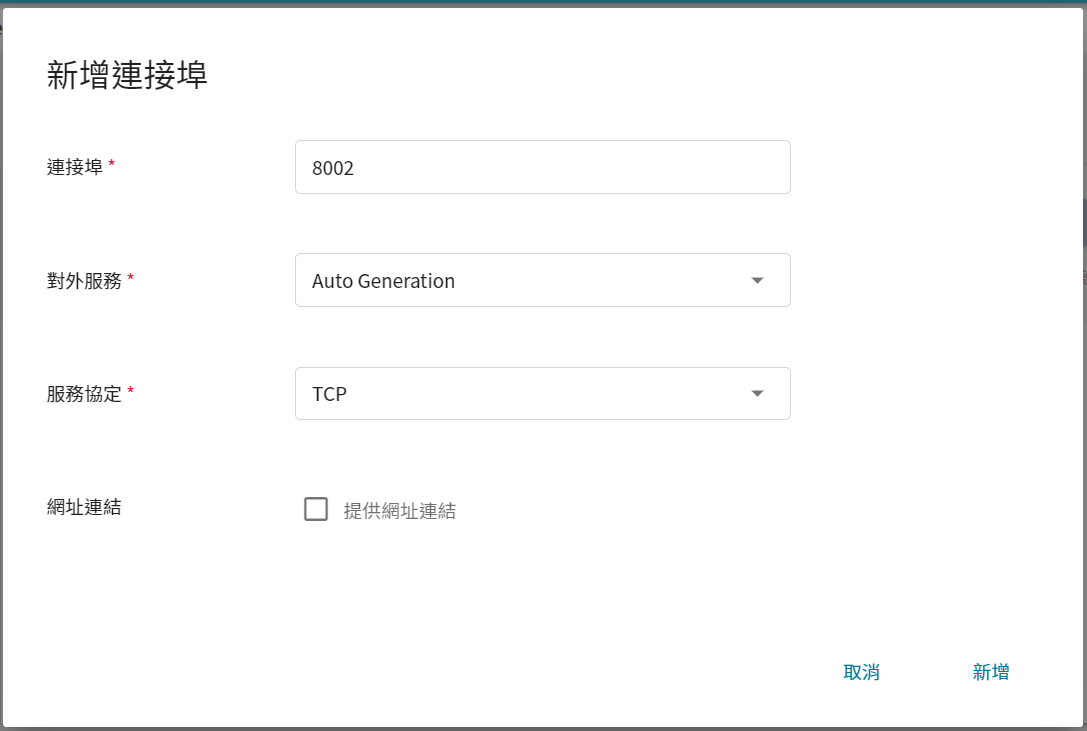
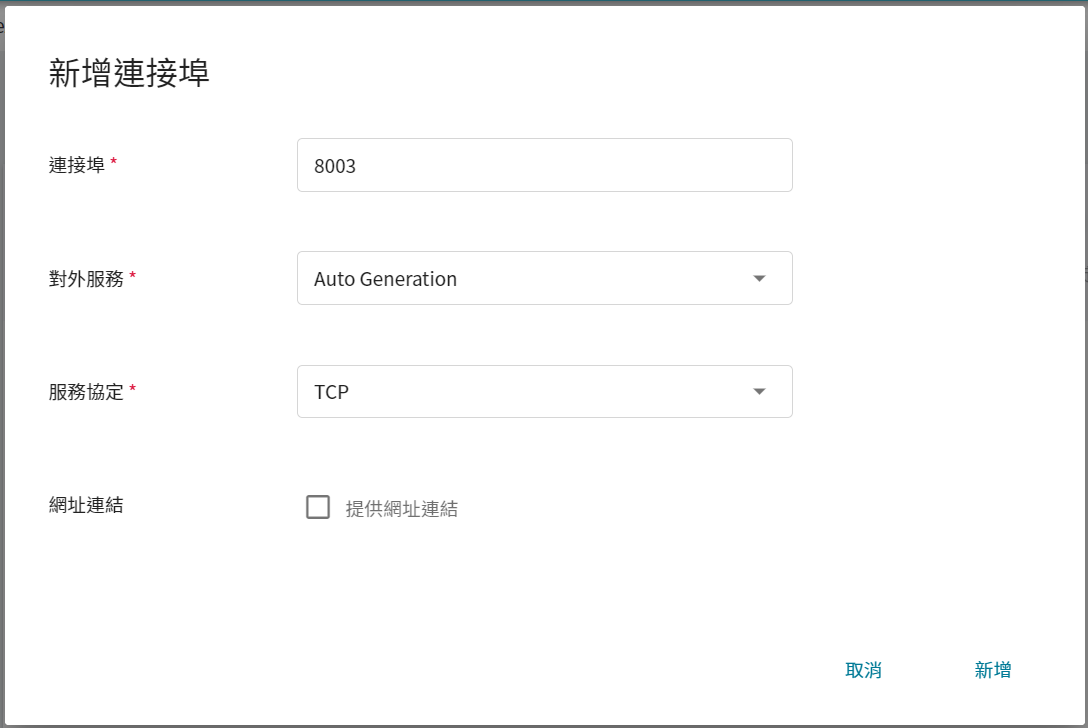
此步驟我們會先預產生兩個 FL Server 需要的對外服務埠,請依下列圖示新增兩個連接埠。
* **fed_learn_port**
* **admin_port**
* 連接埠新增好後的設定畫面如下。

5. **變數設定**
此步驟暫不需設定。
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下「**建立**」。
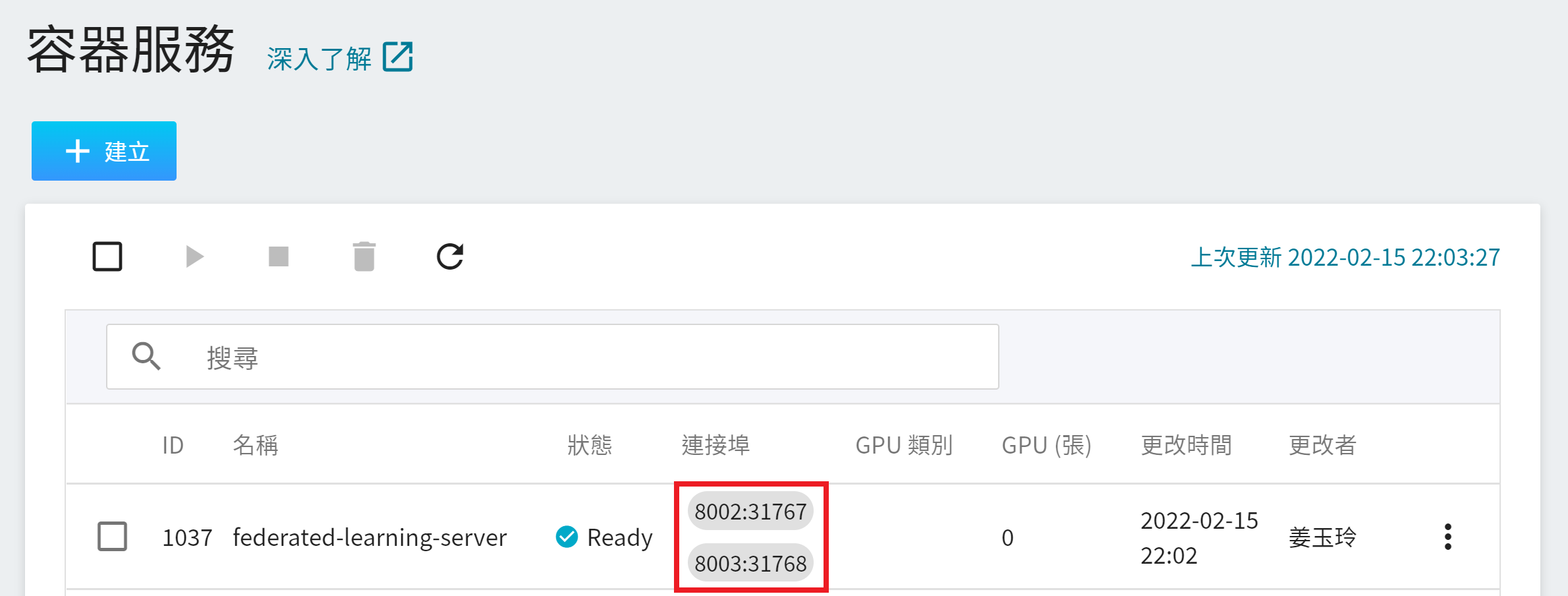
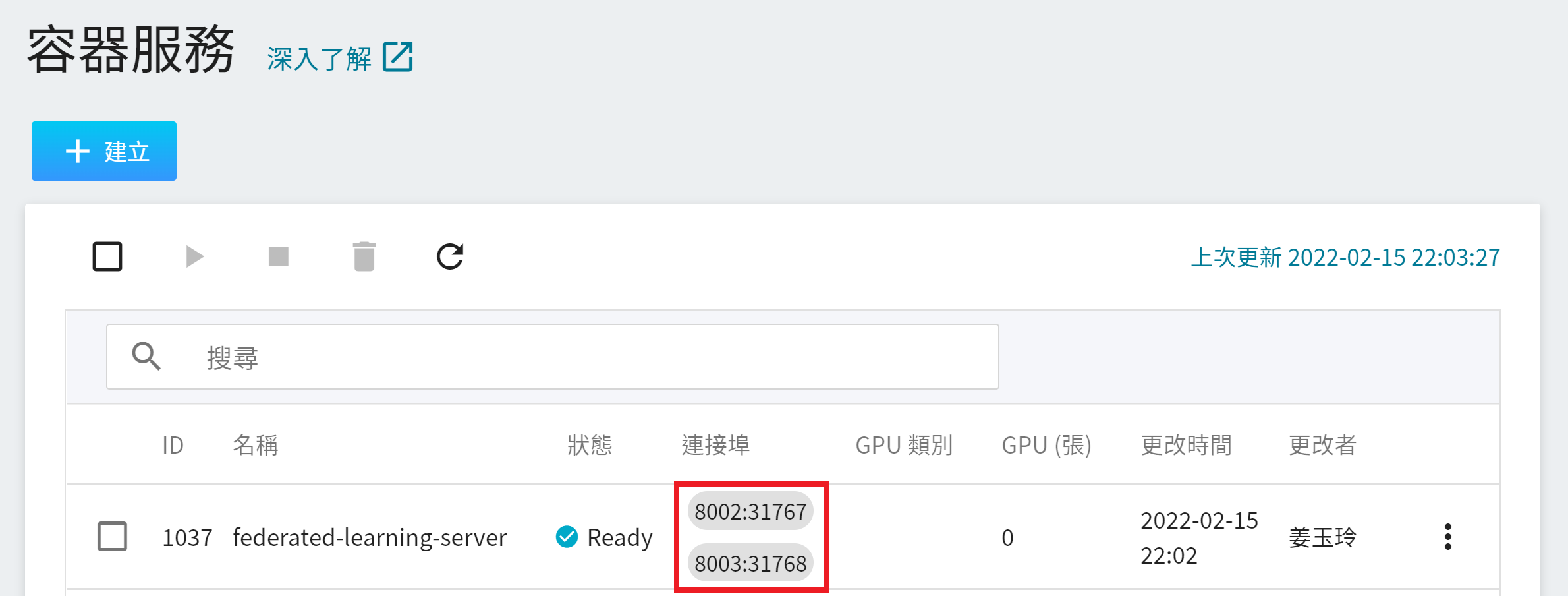
**FL Server** 容器建立後,會出現在容器服務列表中,當容器服務的狀態變成 **`Ready`** 後,在連接埠下方會顯示所設定的連接埠及自動產生的對外埠 **`8002:31767`** 和 **`8003:31768`**,在接下來的步驟中會使用到這兩個對外埠。
### 1.2 建立安裝包存放空間
本步驟將建立存放安裝包的空間。
1. **建立儲存體**
從 OneAI 服務列表選擇「**儲存服務**」進入儲存服務管理頁面,接著點擊「**+建立**」,新增儲存體 **`federated-learning-packages`**。
2. **檢視儲存體**
完成儲存體的建立後,回到儲存服務管理頁面,此時會看到剛剛新增的儲存體已建立完成。
### 1.3 建立 Provision 容器
從 OneAI 服務列表選擇「**容器服務**」進入容器服務管理頁面,點擊「**+建立**」,新增一個容器服務。
1. **基本資訊**
請依序輸入 **名稱**,例如:**`federated-learning-provision`**、**描述**,**映像檔** 請選擇 `clara:v4.0`。
2. **硬體設定**
選擇硬體規格,可以不用配置 GPU。
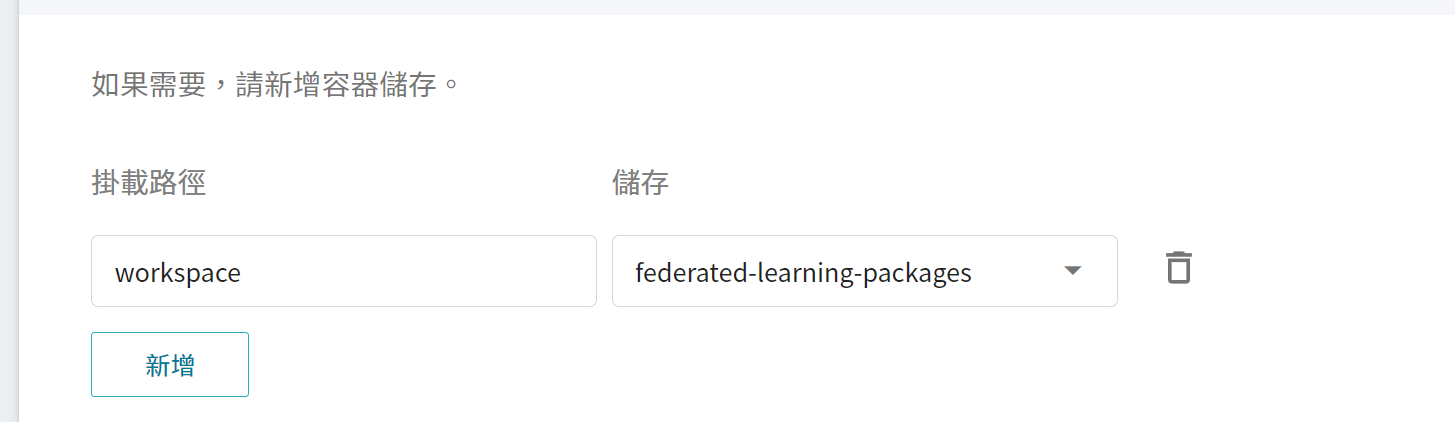
3. **儲存設定**
這個階段需掛載存放安裝包的儲存體,請點擊「**新增**」並設定存放安裝包的儲存體。
**workspace**:**`federated-learning-packages`**。
4. **網路設定**
此步驟無需設定。
5. **變數設定**
此步驟無需設定。
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下「**建立**」。
### 1.4 修改 Provision 配置檔
**Provision** 容器建立後,會出現在容器服務列表中,當容器服務的狀態變成 **`Ready`** 後,請進入該容器服務的詳細資料頁面,點選上方「**終端機**」頁籤連線該容器,並依本範例的環境設定,修改 Provision 配置檔:/opt/conda/lib/python3.8/site-packages/provision/project.yml。
```=
# nano /opt/conda/lib/python3.8/site-packages/provision/project.yml
```
修改處如下:
* **cn**:FL Server 的完整網域名稱(FQDN),本範例設定為 **`federated.oneai.twcc.ai`**。請注意:因本範例將 FL Server 部署於 OneAI,故需設定為 OneAI 為聯合學習特別建立的 **`federated.oneai.twcc.ai`**。
* **fed_learn_port**:配置檔中預設為 **`8002`**,請修改成您的 FL Server 容器服務埠 `8002` 對應的對外服務埠,例如本範例為 `31767` (如下圖)。
* **admin_port**:配置檔中預設為 **`8003`**,請修改成您的 FL Server 容器服務埠 `8003` 對應的對外服務埠,例如本範例為 `31768` (如下圖)。請注意 admin_port 不能跟 fed_learn_port 相同。
:::info
:bulb:**提示:關於 FL Server**
本範例使用的 FL Server FQDN 為 **`federated.oneai.twcc.ai`**,這是 OneAI 為聯合學習提供的 FL Server 服務網址.您可以依照本範例教學,體驗在 OneAI 上部署及執行聯合學習訓練,或是設定成其他的 FL Server FQDN。
:::
```yaml=
....
server:
org: nvidia
# set cn to the server's fully qualified domain name
# never set it to example.com
cn: federated.oneai.twcc.ai <--- 修改 FL Server 的 Domain Name
# replace the number with that all clients can reach out to, and that the server can open to listen to
fed_learn_port: 31767 <--- 修改 fed_learn_port
# again, replace the number with that all clients can reach out to, and that the server can open to listen to
# the value must be different from fed_learn_port
admin_port: 31768 <--- 修改 admin_port,不可與 fed_learn_port 相同
```
:::info
:bulb:**提示:關於 FL Client 和 Admin Client**
本範例僅需修改 FL Server 的設定,如果您想修改 FL Client 和 Admin Client,可自行修改 project.yml 中 fl_clients 和 admin_clients 的設定,如下列說明。更多的資訊請參見 [**Clara Train SDK 說明文件**](https://docs.nvidia.com/clara/clara-train-sdk/federated-learning/fl_provisioning_tool.html#default-project-yml-file)。
<br>
```yaml=
...
# Please change them according to the information of actual project.
fl_clients: <--- 這裡設定 fl clients
# client_name must be unique
# email is optional
- org: org1
client_name: org1-a <--- 這裡設定組織 org1 的 client a
- org: org1
client_name: org1-b <--- 這裡設定組織 org1 的 client b
- org: org2
client_name: org2 <--- 這裡設定另一個組織 org2
admin_clients: <--- 這裡設定 admin clients
# email is the user name for admin authentication. Hence, it must be unique ww
ithin the project
- org: nvidia
email: admin@nvidia.com
...
```
:::
### 1.5 執行 Provision 工具產生安裝包
接下來請執行 **`provision`** 命令產生安裝包及密碼。
```
# provision
```
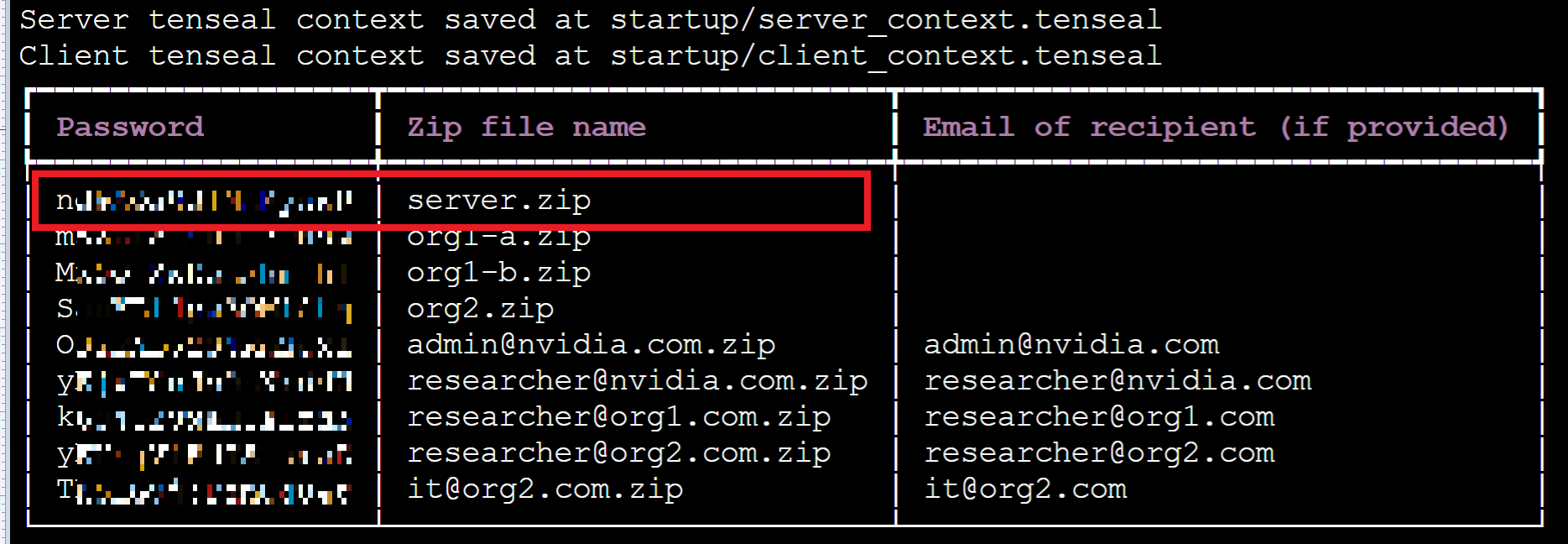
執行成功後,請將畫面上提供的密碼記下來。
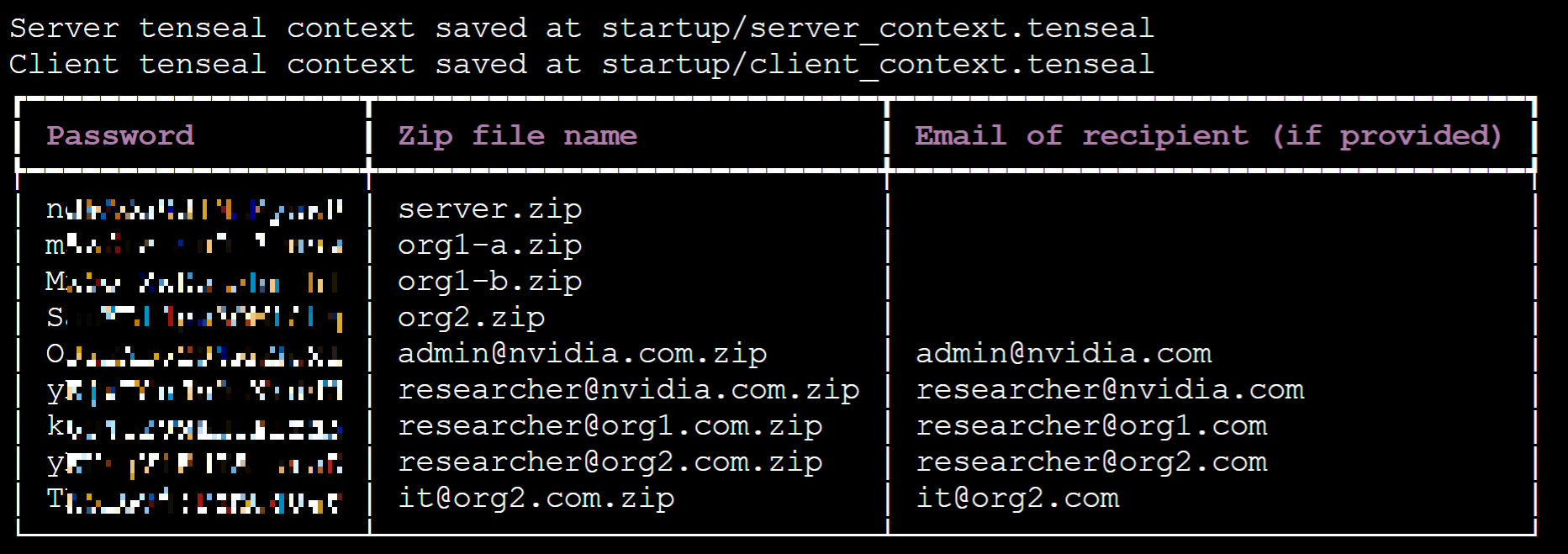
接著從 OneAI 服務列表選擇「**儲存服務**」,進入儲存服務管理頁面,選擇 **`federated-learning-packages`**,將會看到執行 provision 所產生的安裝包,如下圖所示:
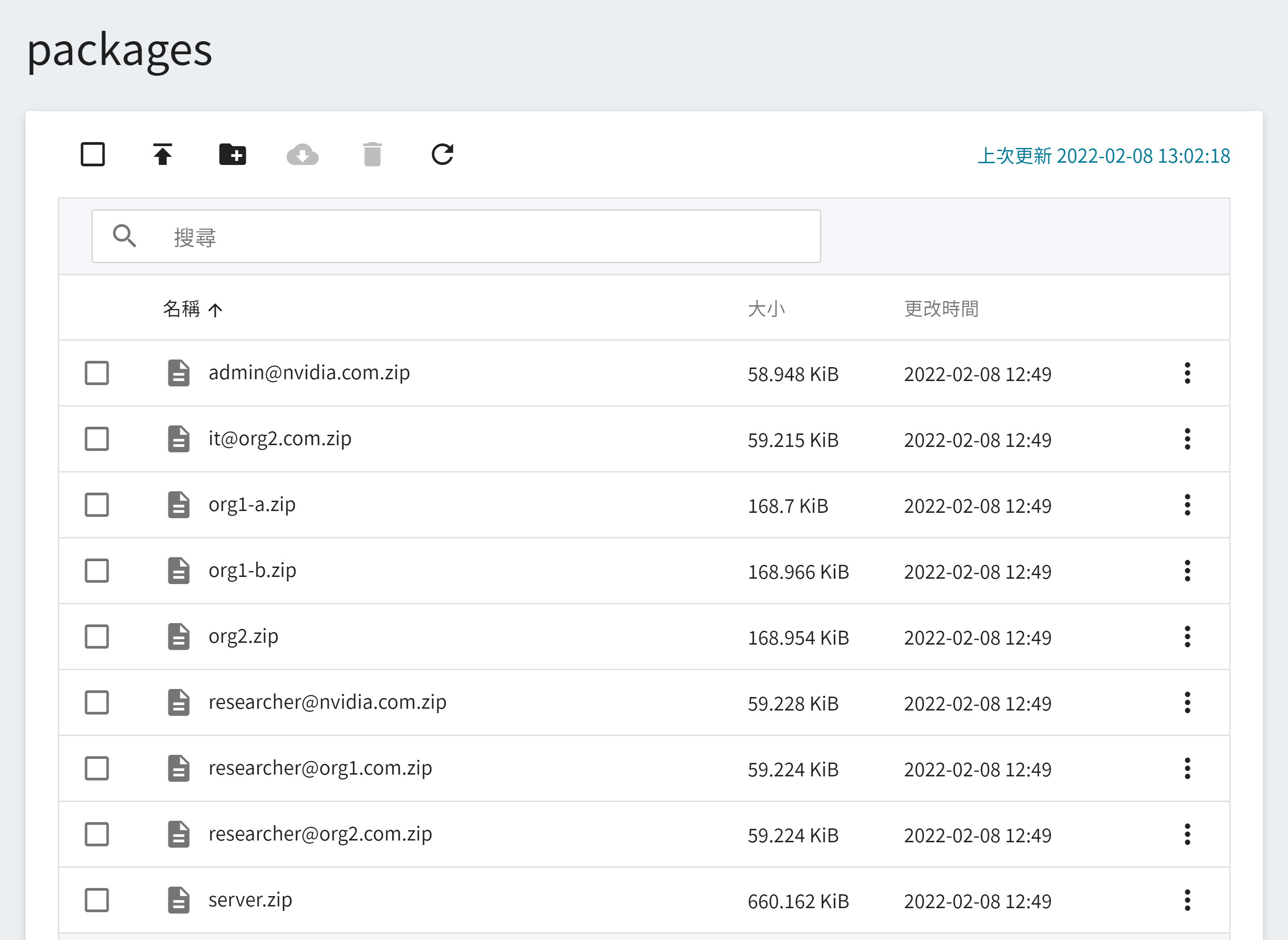
本範例將會使用到以下的安裝包,在實際情境中,每個聯盟的成員只會收到自己的安裝包和解壓縮的密碼。
* server.zip
* org1-a.zip
* org1-b.zip
* org2.zip
* admin@nvidia.com.zip
## 2. 部署 FL Server
FL Server 將協調聯合學習訓練並成為所有 FL Client 和 Admin 連接的主要樞紐,本章節將介紹如何使用 **OneAI 容器服務** 部署 FL Server。
### 2.1 上傳 FL Server 安裝包
首先,請解壓安裝包 server.zip,密碼就是在執行 provision 命令後畫面列表中 server.zip 左邊的 Password。
解開後目錄結構如下:
```=
./startup
├── authorization.json
├── docker.sh
├── fed_server.json
├── log.config
├── readme.txt
├── rootCA.pem
├── server.crt
├── server.key
├── server_context.tenseal
├── signature.pkl
├── start.sh
└── sub_start.sh
```
解開安裝包後請依以下步驟檢查安裝包的資訊:
1. 確認 FL Server 資訊。
開啟 **fed_server.json**,確認此檔案中 **`target`** 設定的 FL Server 的 Domain Name 和 Port 是否正確,例如:
```json=
...
"service": {"target": "federated.oneai.twcc.ai:31767"
...
```
2. 檢查安裝包檔案是否有異常,以防止拿到來路不明的檔案。
檢查無誤後,接著將此安裝包上傳至 OneAI 的儲存服務中。
1. **建立儲存體**
從 OneAI 服務列表選擇「**儲存服務**」進入儲存服務管理頁面,接著點擊「**+建立**」,新增儲存體 **`federated-learning-server-startkit`**,用來存放 Server 安裝包。
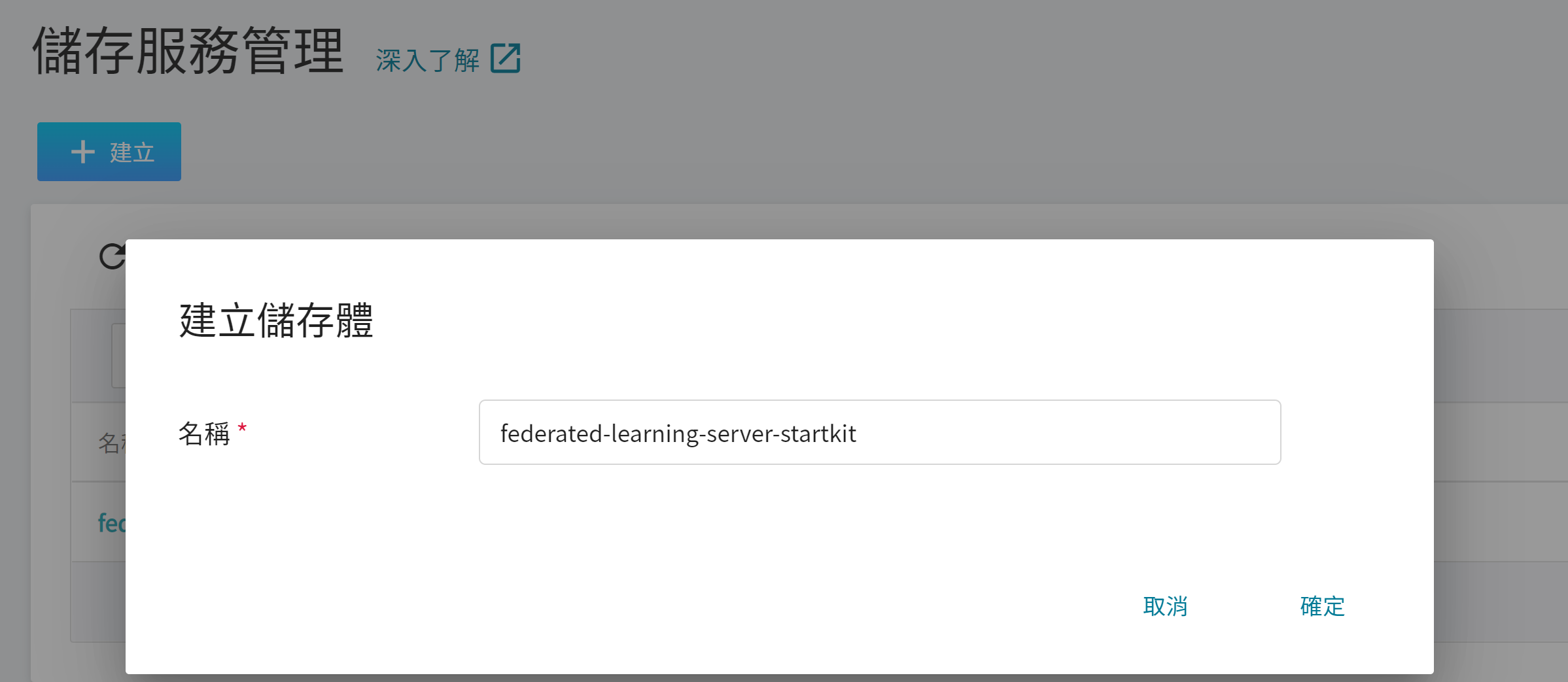
2. **檢視儲存體**
完成儲存體的建立後,回到儲存服務管理頁面,此時會看到剛剛新增的儲存體已建立完成。
3. **上傳 FL Server 安裝包**
點擊建立好的儲存體,然後上傳整個 FL Server 安裝包目錄 **startup**。(請參閱 [**儲存服務說明文件**](/s/storage))。
### 2.2 修改 FL Server 容器
從 OneAI 服務列表選擇「**容器服務**」,進入容器服務管理頁面,點擊剛建立的 **`federated-learning-server`** 容器服務。
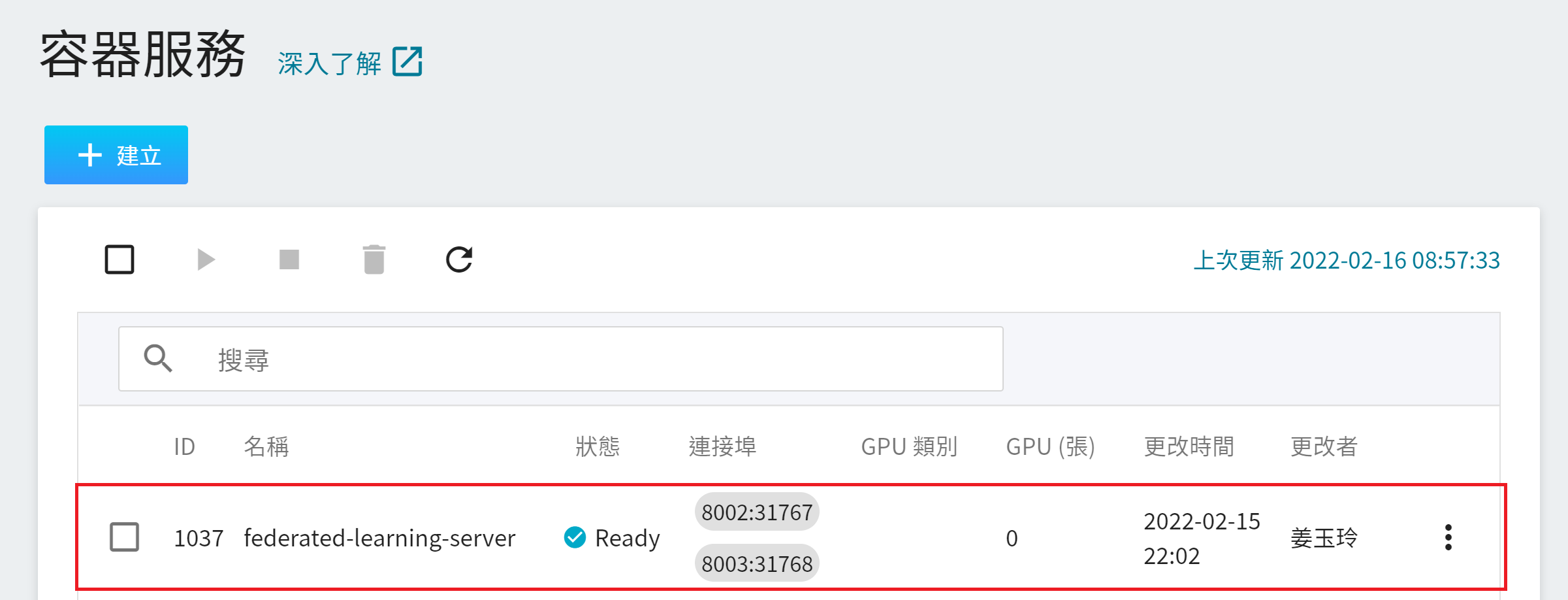
進入「**容器服務詳細資料**」頁面後,點擊上方的 **停止** 圖示停止容器服務。
進入「**容器服務詳細資料**」頁面後,點擊上方的 **編輯** 圖示。
接著依下列步驟修改 FL Server 的容器服務設定。
1. **基本資訊**
此步驟無需修改。
2. **硬體設定**
此步驟無需修改。
3. **儲存設定**
此步驟將掛載存放 FL Server 安裝包的儲存體,請點擊「**新增**」並設定存放安裝包的儲存體。
* **workspace**:**`federated-learning-server-startkit`**。
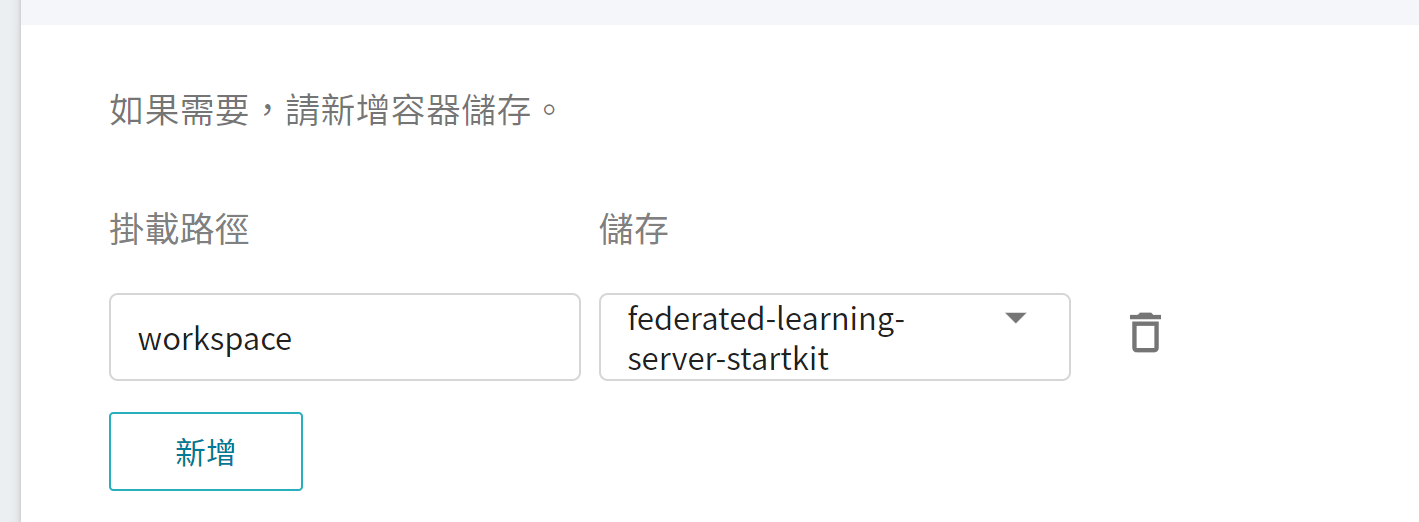
4. **網路設定**
在此我們需將之前建立的連接埠修改成與系統自動分配的對外埠一致。
:::info
:bulb:**提示:** 因為 FL Server 的 Listen Port 要與 FL Client 的連接埠一致。
:::
點擊列表右側的 **編輯** 圖示。
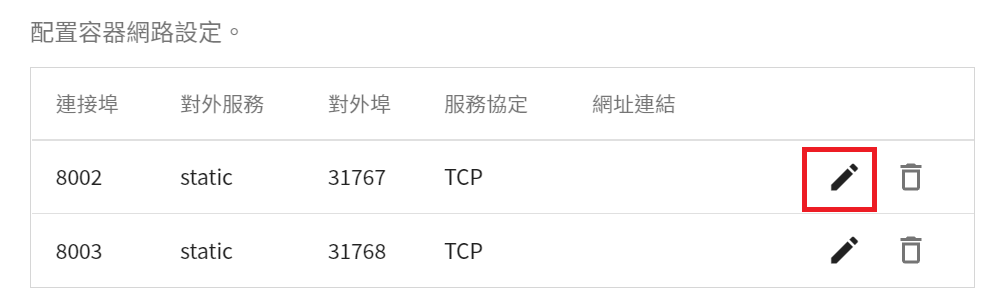
將連接埠 `8002` 改成下方的 **對外埠**,如下圖。
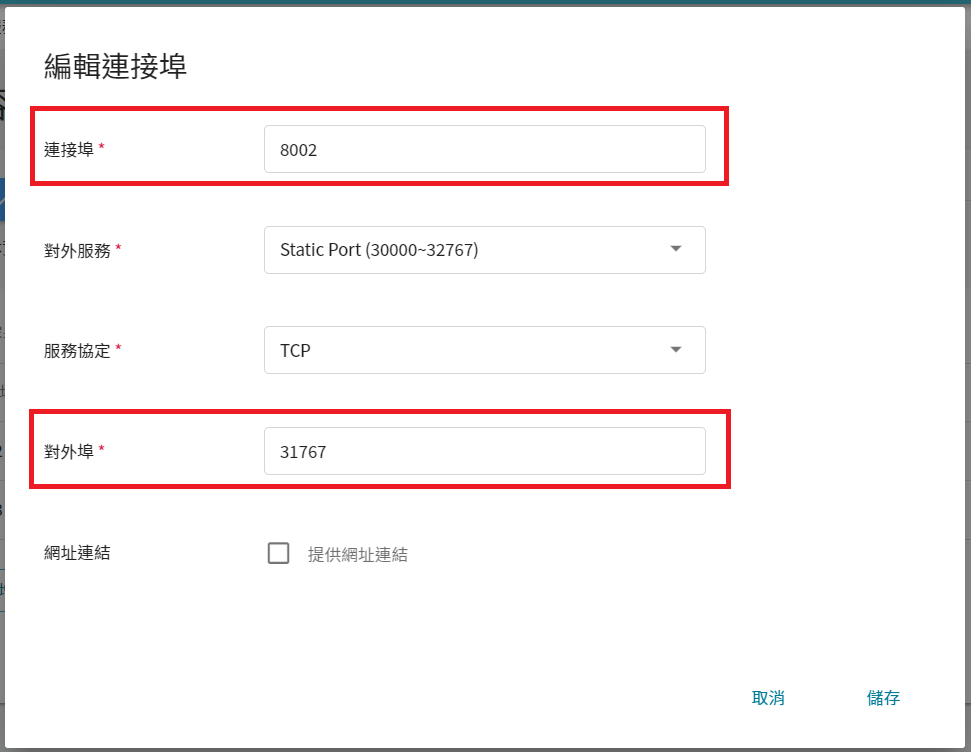
修改好後點擊「**儲存**」。
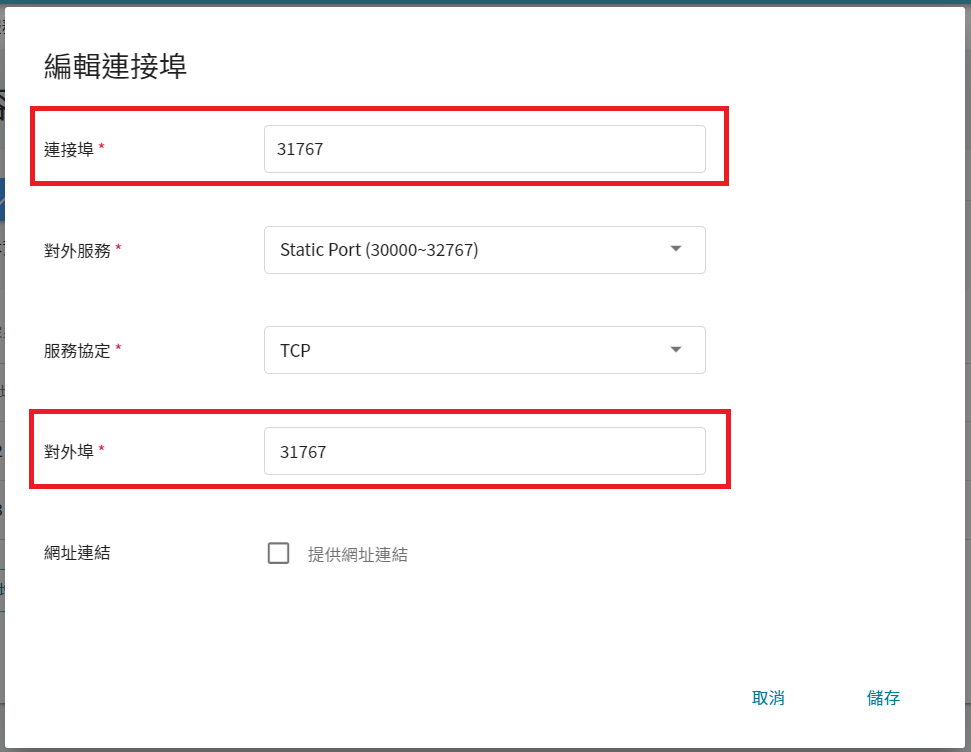
重覆同樣步驟,將連接埠 `8003` 改成對應的對外埠,修改完後請確認 **連接埠** 是否與 **對外埠** 一致。
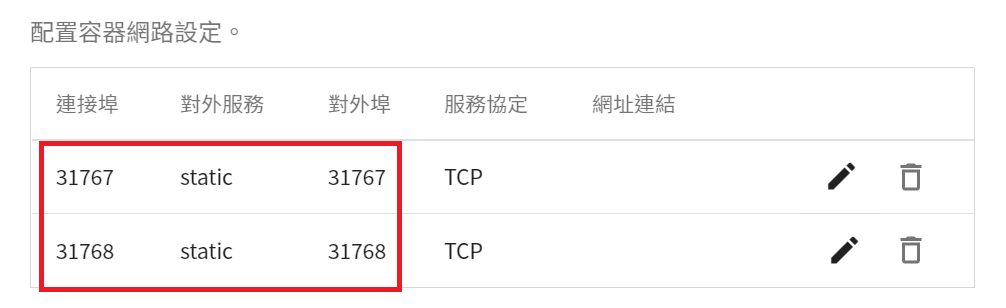
5. **變數設定**
* **環境變數**
此步驟可依您的需求,自行選擇是否要設定下列變數。
* **START**:設定是否要自動自動執行 **`start.sh`**,數值設定為 **`AUTO`** 時,將會在容器啟動後自動執行 **`start.sh`** 啟動 FL Server,如不想自動啟動 FL Server 請不要設定 START 變數。
* **命令**
請貼上以下指令:
```=
git clone https://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@github.com/asus-ocis/fl-script.git /fl-script && sleep 1 &&/bin/bash /fl-script/nvclara40.sh
```
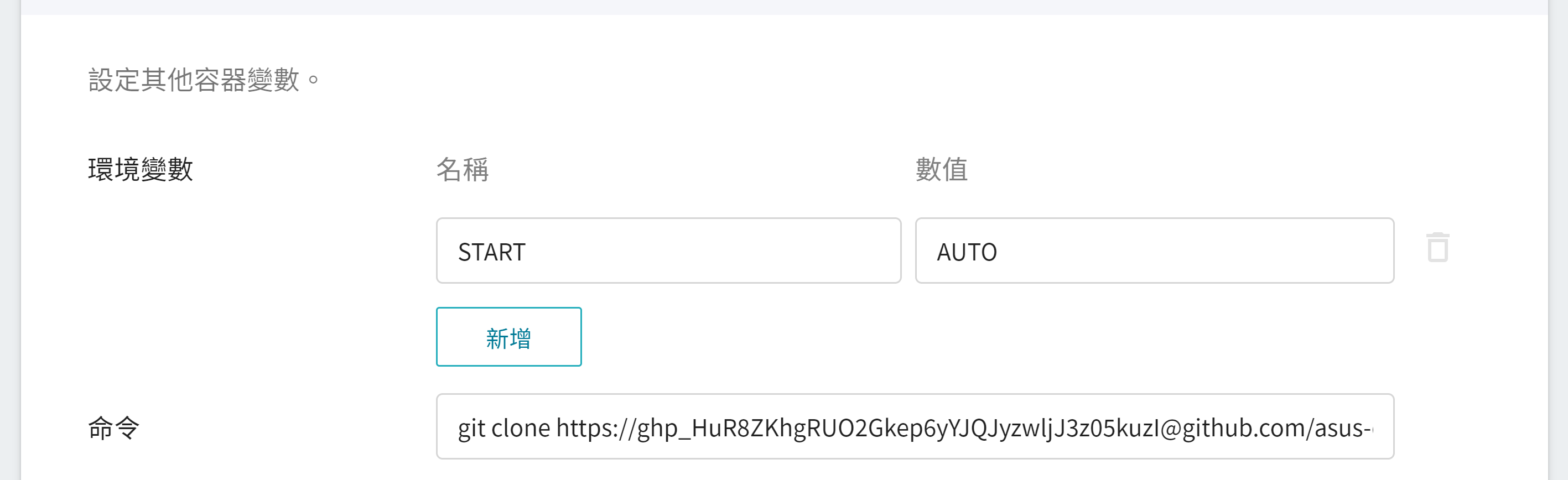
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
修改完成後,請點擊上方的 **啟動** 圖示,重新啟動容器服務。
### 2.3 啟動 FL Server
如果您在 **變數設定** 有設定 **START:AUTO**,在 **容器服務** 建立好後,系統將自動執行 **./startup/start.sh** 啟動 FL Server。當容器服務的狀態顯示為 **`Ready`** 後,請進入該容器服務的詳細資料頁面,點選上方「**終端機**」頁籤,執行以下命令查看 log 檔。
```=
cat /workspace/log.txt
```
:::info
:bulb:**提示**
如果您在 **變數設定** 步驟沒有設定 START:AUTO,進入「**終端機**」頁面後,請先手動執行啟動命令 **`./startup/start.sh`**。
:::
看到下列訊息,表示 FL Server 成功啟動。
```=
2022-01-20 07:00:55,351 - FederatedServer - INFO - starting secure server at federated.oneai.twcc.ai:31767
deployed FL server trainer.
2022-01-20 07:00:55,358 - FedAdminServer - INFO - Starting Admin Server federated.oneai.twcc.ai on Port 31768
2022-01-20 07:00:55,358 - root - INFO - Server started
```
## 3. 部署 FL Client
在本範例中有 3 個 Client,分別為 org1-a、org1-b 和 org2,以下說明如何部署 org1-a 的安裝包和資料集。接著,請依此類推,完成 org1-b 和 org2 的部署。
### 3.1 上傳 FL Client 安裝包
首先在本地端解壓縮 org1-a 的安裝包 org1-a.zip,解壓縮後目錄結構如下:
```=
./startup
├── client.crt
├── client.key
├── client_context.tenseal
├── docker.sh
├── fed_client.json
├── log.config
├── readme.txt
├── rootCA.pem
├── signature.pkl
├── start.sh
└── sub_start.sh
```
解開安裝包後請依以下步驟檢查安裝包的資訊:
1. 確認 FL Server 資訊。
開啟 **fed_client.json**,確認此檔案中 **`target`** 設定的 FL Server 的 Domain Name 和 Port 是否正確。
```json=
...
"service": {"target": "federated.oneai.twcc.ai:31767"
...
```
2. 檢查安裝包檔案是否有異常,以防止拿到來路不明的檔案。
檢查無誤後,接著將此安裝包上傳至 OneAI 的儲存服務中。
1. **建立儲存體**
從 OneAI 服務列表選擇「**儲存服務**」進入儲存服務管理頁面,接著點擊「**+建立**」,新增儲存體 `federated-learning-org1-a-startkit`,用來存放 org1-a 的安裝包檔案。
2. **檢視儲存體**
完成儲存體的建立後,回到儲存服務管理頁面,此時會看到剛剛新增的儲存體已建立完成。
3. **上傳 FL Client 安裝包**
點擊建立好的儲存體,然後上傳整個 org1-a 安裝包目錄 **startup**。(請參閱 [**儲存服務說明文件**](/s/storage))。
### 3.2 上傳訓練資料集
接著需上傳訓練用的資料集,本範例使用 NVIDIA 提供的脾臟資料集:[clara-train-examples/PyTorch/NoteBooks/Data/sampleData/](https://github.com/NVIDIA/clara-train-examples/tree/master/PyTorch/NoteBooks/Data/sampleData)。如前一步驟,請建立另一個存放資料集的儲存體,例如:`federated-learning-dataset`,並將資料集上傳至此儲存體。
### 3.3 在 OneAI 容器服務部署 FL Client
從 OneAI 服務列表選擇「**容器服務**」進入容器服務管理頁面,點擊「**+建立**」,新增一個容器服務。
1. **基本資訊**
請依序輸入 **名稱**,例如:**`federated-learning-org1-a`**、**描述**,**映像檔** 請選擇 `clara:v4.0`。
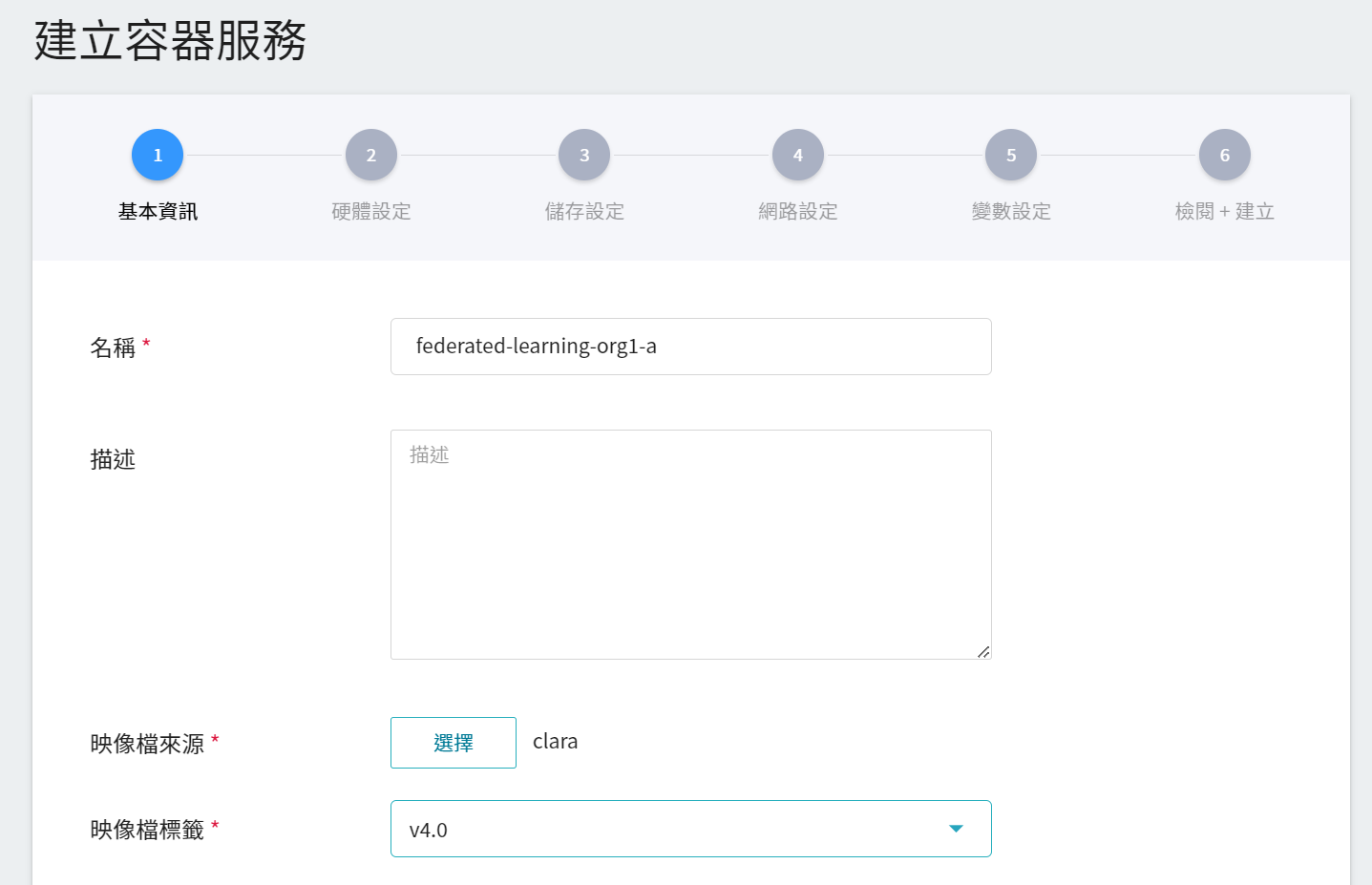
2. **硬體設定**
FL Client 需執行 FL 訓練任務,請選擇至少有 1 張 GPU,記憶體 25 GB 的硬體選項。
3. **儲存設定**
此步驟須掛載的儲存體有兩個,請點擊「**新增**」並設定以下內容:
* **workspace**:存放 Client 安裝包的儲存體,請選擇 **`federated-learning-org1-a-startkit`**。
* **data**:存放訓練資料集的儲存體,請選擇 **`federated-learning-dataset`**。

4. **網路設定**
此步驟無需設定。
5. **變數設定**
* **環境變數**
* **`START`**
設定是否自動執行 **`start.sh`**,數值設定為 **`AUTO`**,將會在 FL Client 容器啟動後自動執行 **`start.sh`**,並自動加入 FL Server。
* **命令**
請貼上以下指令:
```=
git clone https://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@github.com/asus-ocis/fl-script.git /fl-script && sleep 1 &&/bin/bash /fl-script/nvclara40.sh
```
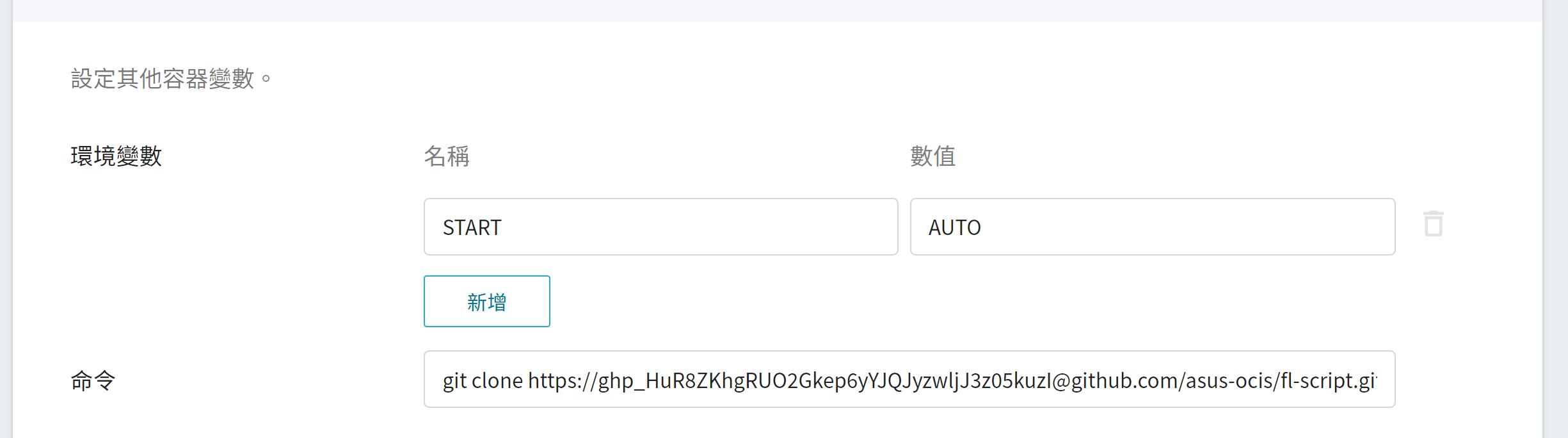
:::info
:bulb:**提示**
如果您的 FL Server 不是公開的,可以透過設定 **`FLSERVER`** 和 **`FLSERVERIP`** 環境變數,讓系統自動修改 /etc/hosts。
* **`FLSERVER`**
設定您的 FL Server Domain Name (非對外公開),系統會自動修改 /etc/hosts。例如 `myflserver.com` (需與 **fed_client.json** 的 "target" 欄位一致)。
* **`FLSERVERIP`**
設定 FL Server 的 IP,需與 **`FLSERVER`** 搭配使用,例如 `203.145.220.166`。
:::
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下「**建立**」。
### 3.4 啟動 FL Client
如果您在 **變數設定** 有設定 **START:AUTO**,系統將自動執行 **./startup/start.sh**,當 FL Client 容器服務的狀態顯示為 **`Ready`** 後,請進入該容器服務的詳細資料頁面,點選上方「**終端機**」頁籤,執行以下命令查看 log 檔。
```=
cat /workspace/log.txt
```
:::info
:bulb:**提示**
如果您在 **變數設定** 步驟沒有設定 START:AUTO,進入「**終端機**」頁面後,請先手動執行啟動命令 **`./startup/start.sh`**。
:::
當 FL Client 成功連接 FL Server 後,將會出現如以下的資訊:
```=
...
2022-02-11 09:15:13,611 - FederatedClient - INFO - Successfully registered client:org1-a for example_project. Got token:...
created /tmp/fl/org1-a/comm/training/x
created /tmp/fl/org1-a/comm/training/y
created /tmp/fl/org1-a/comm/training/t
```
### 3.5 部署其他 FL Clients
請重覆 org1-a 的部署步驟,使用 org1-b.zip 及 org2.zip 安裝包,部署並啟動 org1-b 和 org2。
## 4. 部署 FL Admin
FL Admin 是聯合學習的控制核心,負責監督及調控整個深度學習模型訓練過程。當 FL Server 和 FL Clients 啟動後,就可以透過 FL Admin 管理及運行聯合學習。此章節將說明如何部署 FL Admin 並使用 Admin Tool 操作聯合學習。
### 4.1 上傳 FL Admin 安裝包
首先在本地端解壓縮安裝包 admin@nvidia.com.zip,解開後目錄結構如下:
```=
startup/
├── clara_hci-4.0.0-py3-none-any.whl
├── client.crt
├── client.key
├── docker.sh
├── fl_admin.sh
├── readme.txt
├── rootCA.pem
└── signature.pkl
```
解開安裝包後請依以下步驟檢查安裝包的資訊:
1. 確認 FL Server 資訊。
開啟 **fl_admin.sh**,確認此檔案中 **`target`** 設定的 FL Server 的 Domain Name 和 Port 是否正確。
```json=
...
"service": {"target": "federated.oneai.twcc.ai:31768"
...
```
2. 檢查安裝包檔案是否有異常,以防止拿到來路不明的檔案。
檢查無誤後,接著將此安裝包上傳至 OneAI 的儲存服務中。
1. **建立儲存體**
從 OneAI 服務列表選擇「**儲存服務**」進入儲存服務管理頁面,接著點擊「**+建立**」,新增一個名稱為 `federated-learning-admin-startkit` 的儲存體,用來存放 Admin 安裝包。
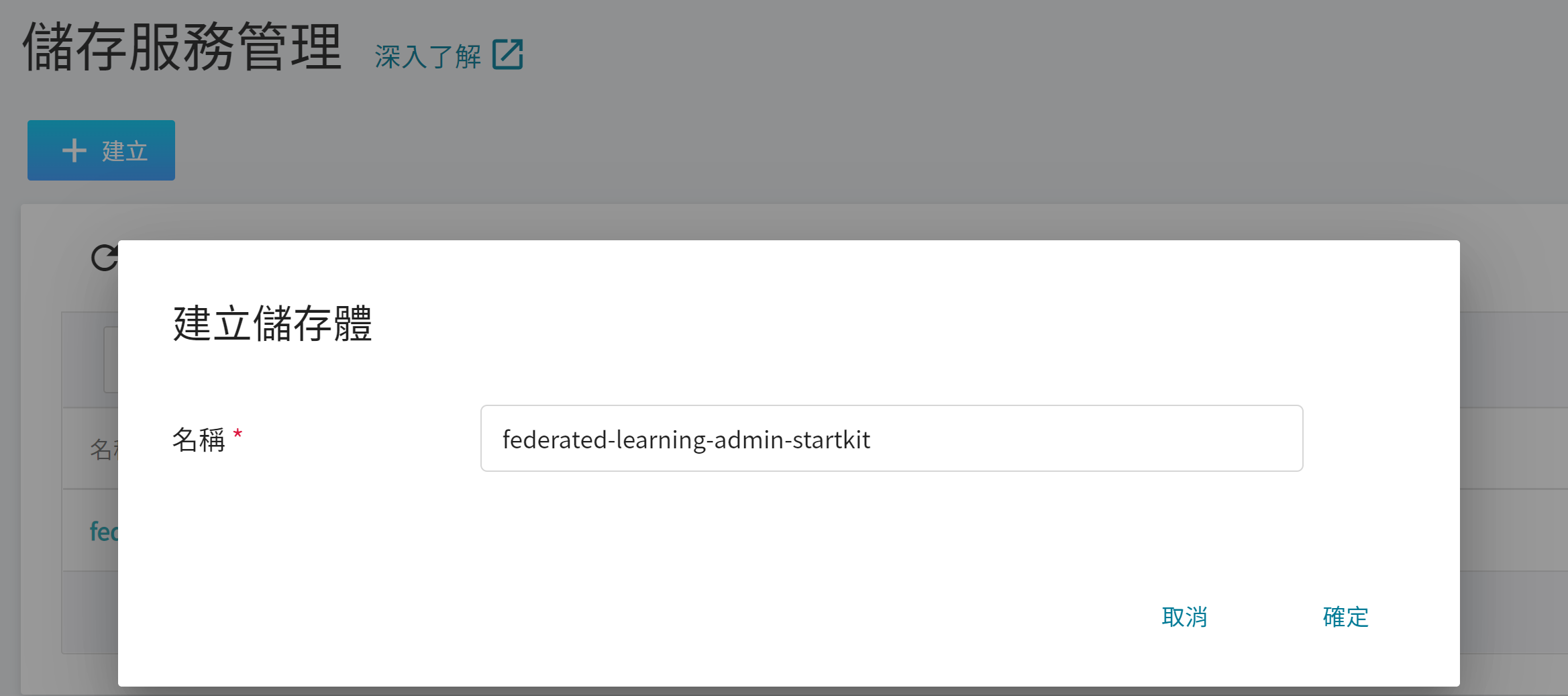
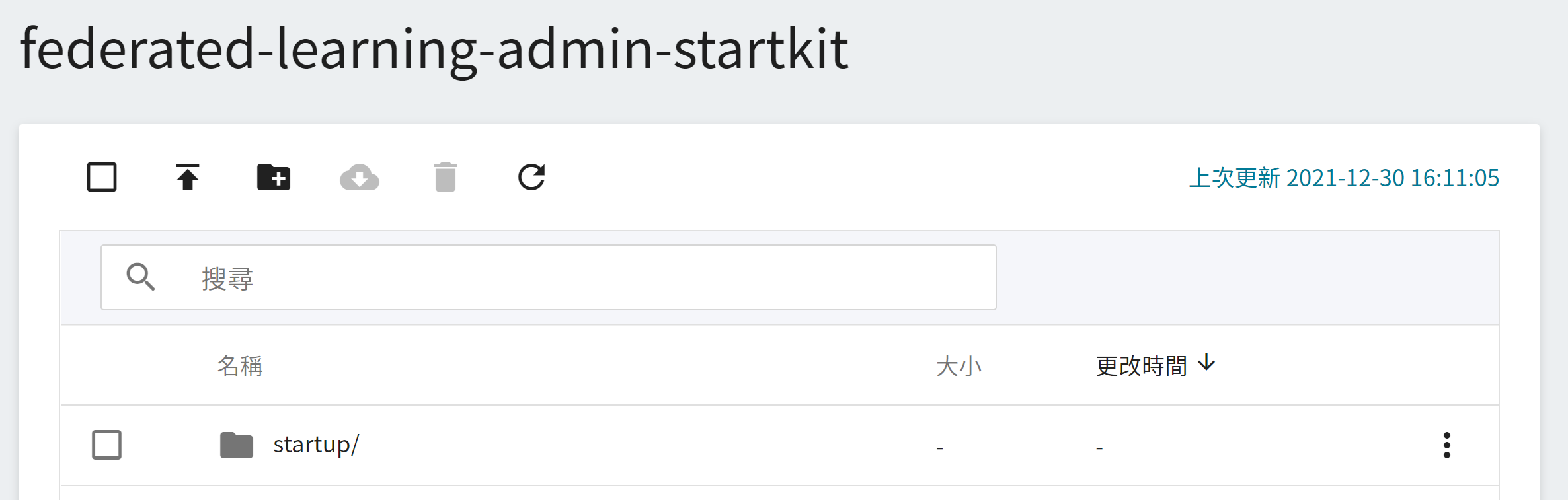
2. **檢視儲存體**
完成儲存體的建立後,回到儲存服務管理頁面,此時會看到剛剛新增的儲存體已建立完成。
3. **上傳 FL Admin 安裝包**
點擊建立好的儲存體,然後上傳整個 Admin 安裝包目錄 **startup**。(請參閱 [**儲存服務說明文件**](/s/storage))。
### 4.2 在 OneAI 容器服務部署 FL Admin
從 OneAI 服務列表選擇「**容器服務**」進入容器服務管理頁面,點擊「**+建立**」,新增一個容器服務。
1. **基本資訊**
請依序輸入 **名稱**,例如:**`federated-learning-admin`**、**描述**,**映像檔** 請選擇 `clara:v4.0`。
2. **硬體設定**
選擇硬體規格,可以不用配置 GPU。
3. **儲存設定**
此步驟須掛載存放安裝包的空間,請點擊「**新增**」並設定存放安裝包的儲存體。
* **workspace**:存放 Admin 安裝包的儲存體,請選擇 `federated-learning-admin-startkit`。
4. **網路設定**
此步驟無需設定。
5. **變數設定**
* **環境變數**
本範例的 FL Server 無需設定環境變數。
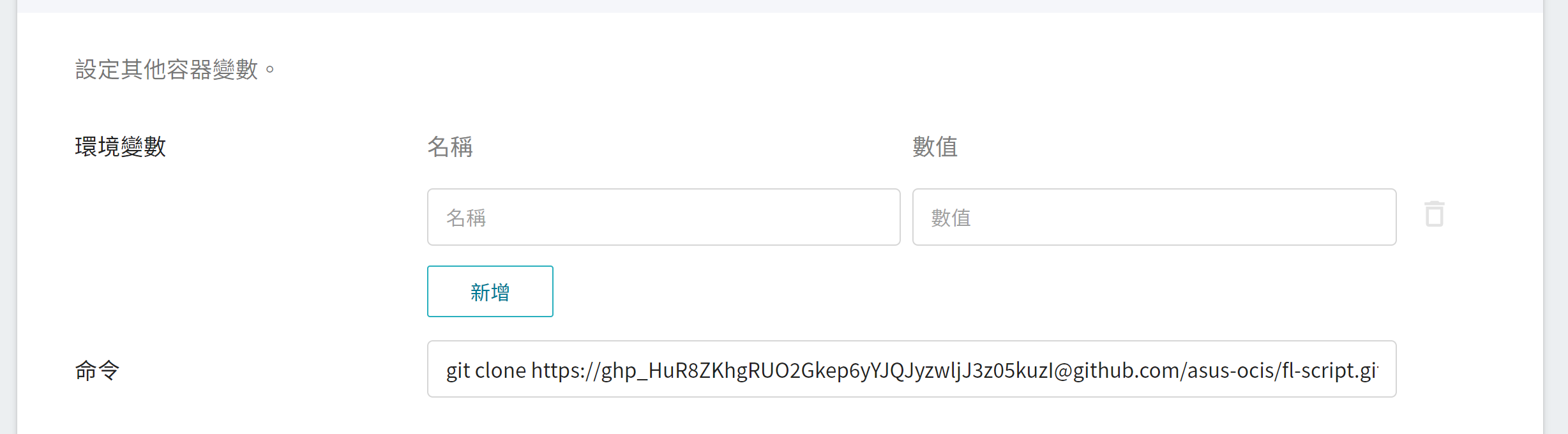
* **命令**
請貼上以下指令:
```
git clone https://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@github.com/asus-ocis/fl-script.git /fl-script && sleep 1 &&/bin/bash /fl-script/nvclara40.sh
```
:::info
:bulb:**提示**
如果您的 FL Server 不是公開的,可以透過設定 **`FLSERVER`** 和 **`FLSERVERIP`** 環境變數,讓系統自動修改 /etc/hosts。
* **`FLSERVER`**
設定您的 FL Server Domain Name (非對外公開),系統會自動修改 /etc/hosts。例如 **`myflserver.com`**。 (需與 **`fl_admin.sh`** 的 `--host` 設定一致)。
* **`FLSERVERIP`**
設定 FL Server 的 IP,需與 **`FLSERVER`** 搭配使用,例如 `203.145.220.166`。
:::
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下「**建立**」。
### 4.3 啟動 Admin
Admin 容器服務建立後,請進入該容器服務的詳細資料頁面,點選 上方「**終端機**」頁籤,執行 **`/startup/fl_admin.sh`** 命令啟動 Admin Server。
```=
# ./startup/fl_admin.sh
```
畫面出現 **`User Name:`** 提示後請輸入 **`admin@nvidia.com`** 並按下 Enter 鍵登入。
```=
# ./startup/fl_admin.sh
Admin Server: federated.oneai.twcc.ai on port 31768
User Name: admin@nvidia.com
Type ? to list commands; type "? cmdName" to show usage of a command.
>
```
### 4.4 Admin Tool 的操作
此章節將說明如何使用 Admin Tool 操作聯合學習。
#### 4.4.1 查詢 Server、Client 的狀態
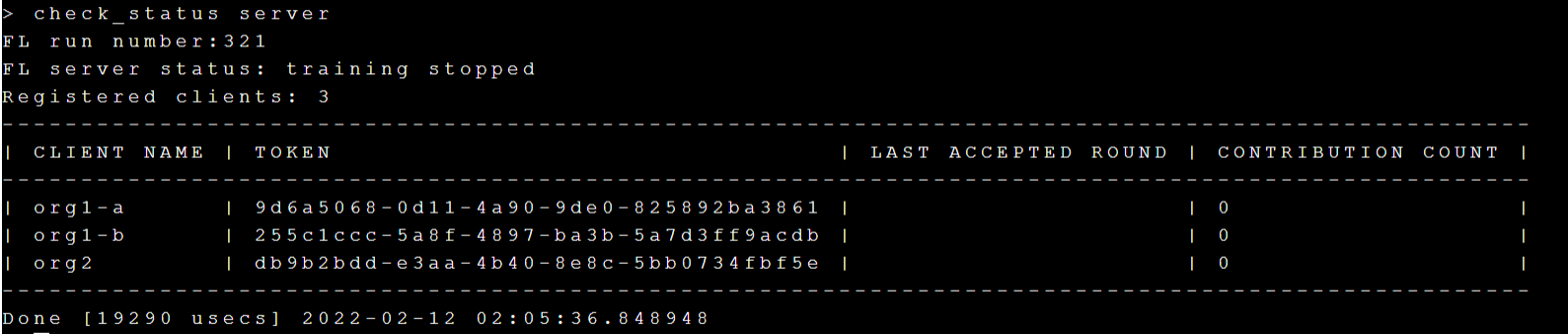
執行 **`check_status server`** 命令查詢 FL Server 的狀態。
執行 **`check_status client`** 命令查詢 FL Client 的連線狀態。

#### 4.4.2 上傳訓練 adminMMAR
接下來我們要開始部署 MMAR,請先下載 NVIDIA 提供的 [**adminMMAR**](https://github.com/NVIDIA/clara-train-examples/tree/master/PyTorch/NoteBooks/FL/adminMMAR)。
下載後請修改檔案內容以符合本範例的測試環境。
:::info
:bulb:**提示:** 詳細 MMAR 設定請參考 [**NVIDIA MMAR 文件說明**](https://docs.nvidia.com/clara/clara-train-sdk/pt/mmar.html#configuration)。
:::
1. 請修改檔案 adminMMAR/config/environment.json 的部分內容:
```json=
{
"DATA_ROOT": "/data/", <-- 請更改為 /data
"DATASET_JSON": "/data/dataset_FLclient.json", <-- 請更改為 /data
"PROCESSING_TASK": "segmentation",
"MMAR_EVAL_OUTPUT_PATH": "eval",
"MMAR_CKPT_DIR": "models"
}
```
2. 請修改檔案 adminMMAR/config/config_train.json 的部分內容:
```json=
...
"dataset": {
"name": "CacheDataset",
"data_list_file_path": "{DATASET_JSON}",
"data_file_base_dir": "{DATA_ROOT}",
"data_list_key": "training", <---請找到這裡
"args": {
"cache_num": 1,
"cache_rate": 1.0,
"num_workers": 0 <---這裡請設定 0, 不使用 share memory
}
},
"dataloader": {
"name": "DataLoader",
"args": {
"batch_size": 1, <---這裡請設定 1
"shuffle": true,
"num_workers": 0 <---這裡請設定 0, 不使用 share memory
}
},
...
{
"name": "CheckpointSaver", <--- 請找到這裡
"rank": 0,
"args": {
"save_dir": "{MMAR_CKPT_DIR}",
"save_dict": ["model", "optimizer", "lr_scheduler", "train_conf"], <---這裡請加 "train_conf"
"save_final": true,
"save_interval": 50
}
},
...
"dataset": {
"name": "CacheDataset",
"data_list_file_path": "{DATASET_JSON}",
"data_file_base_dir": "{DATA_ROOT}",
"data_list_key": "validation", <-- 請找到這裡
"args": {
"cache_num": 9,
"cache_rate": 1.0,
"num_workers": 0 <-- 這裡請設定 0, 不使用 share memory
}
},
"dataloader": {
"name": "DataLoader",
"args": {
"batch_size": 1, <--- 這裡請設定 1
"shuffle": false,
"num_workers": 0 <--- 這裡請設定 0, 不使用 share memory
}
},
...
{
"name": "CheckpointSaver", <-- 請找到這裡
"rank": 0,
"args": {
"save_dir": "{MMAR_CKPT_DIR}",
"save_dict": ["model", "train_conf"], <-- 這裡請設定 "train_conf"
"save_key_metric": true
}
}
...
```
3. 請修改檔案 adminMMAR/config/config_validation.json 的部分內容:
```json=
...
"dataloader": { <---請找到這裡
"name": "DataLoader",
"args": {
"batch_size": 1, <---請設定 1
"shuffle": false,
"num_workers": 0 <---這裡請設定 0, 不使用 share memory
}
},
...
```
以上內容修改完後,請到「**儲存服務**」的 **`federated-learning-admin-startkit`** 儲存體建立 **transfer** 目錄,並將 **adminMMAR** 上傳至 **transfer** 目錄下,如下圖所示:
## 5. 執行聯合學習訓練
adminMMAR 準備好後,此章節將介紹如何部署 adminMMAR 到 FL Server 與 FL Client,並開始啟動訓練。
### 5.1 設定訓練任務的 run number
使用 **`set_run_number`** 命令可以設定本次訓練任務的代號,這裡我們設定 `321`。
執行 **`set_run_number 321`**,如下圖:

### 5.2 Admin 上傳 adminMMAR 到 FL Server
執行 **`upload_folder adminMMAR`** 命令將 adminMMAR 上傳到 FL server 的 transfer 暫存目錄,如下圖:

### 5.3 部署 adminMMAR 到 FL Server 和 FL Client
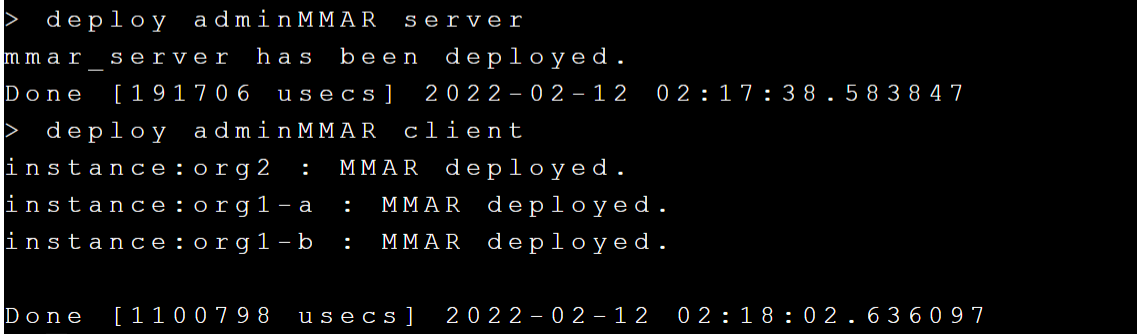
接下來執行 **`deploy adminMMAR server`** 和 **`deploy adminMMAR client`** 將 adminMMAR 從 transfer 暫存目錄部署到 FL Server 和 FL Client,如下圖:
### 5.4 啟動訓練
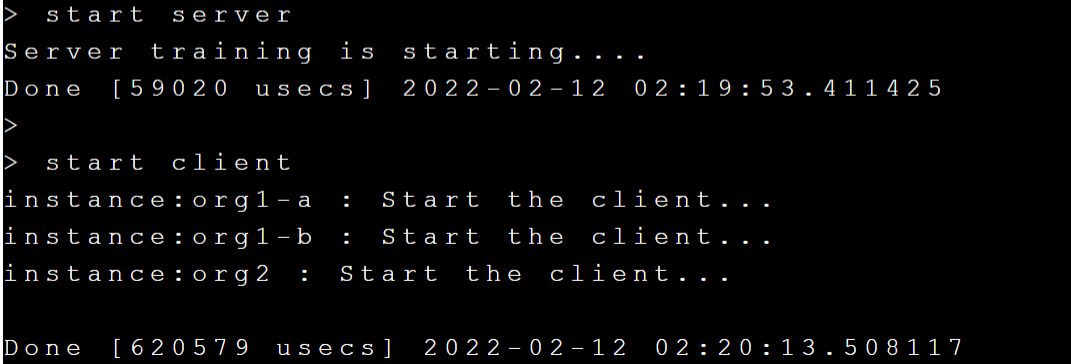
部署 adminMMAR 後就可以開始進行訓練,請執行 **`start server`** 和 **`start client`** 啟動訓練,如下圖:
接下來執行 **`check_status server`** 和 **`check_status client`** 命令來檢查 FL Server 與 FL Client 的狀態是否為 **`training started`**,如下圖:
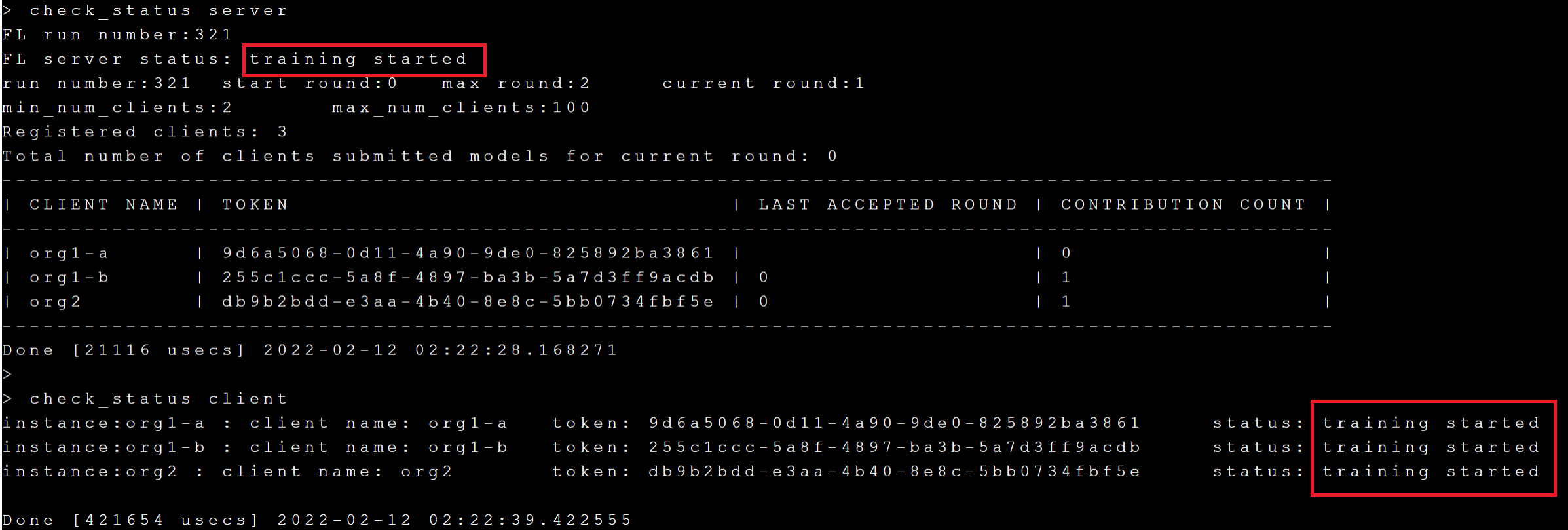
透過 **`check_status`** 可以得知目前訓練的 current round 與 max round,訓練完成後 Server 與 Client 的狀態將變成 **`training stopped`**。
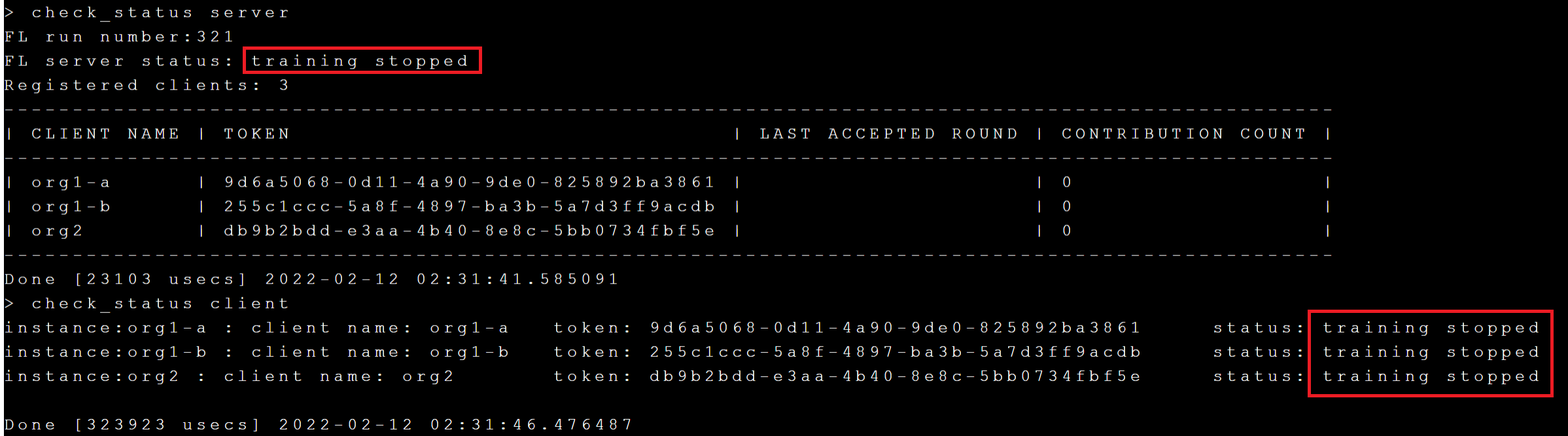
### 5.5 取得訓練結果和模型
訓練完成後可以透過 **`validate all`** 命令取得訓練結果,如下圖:
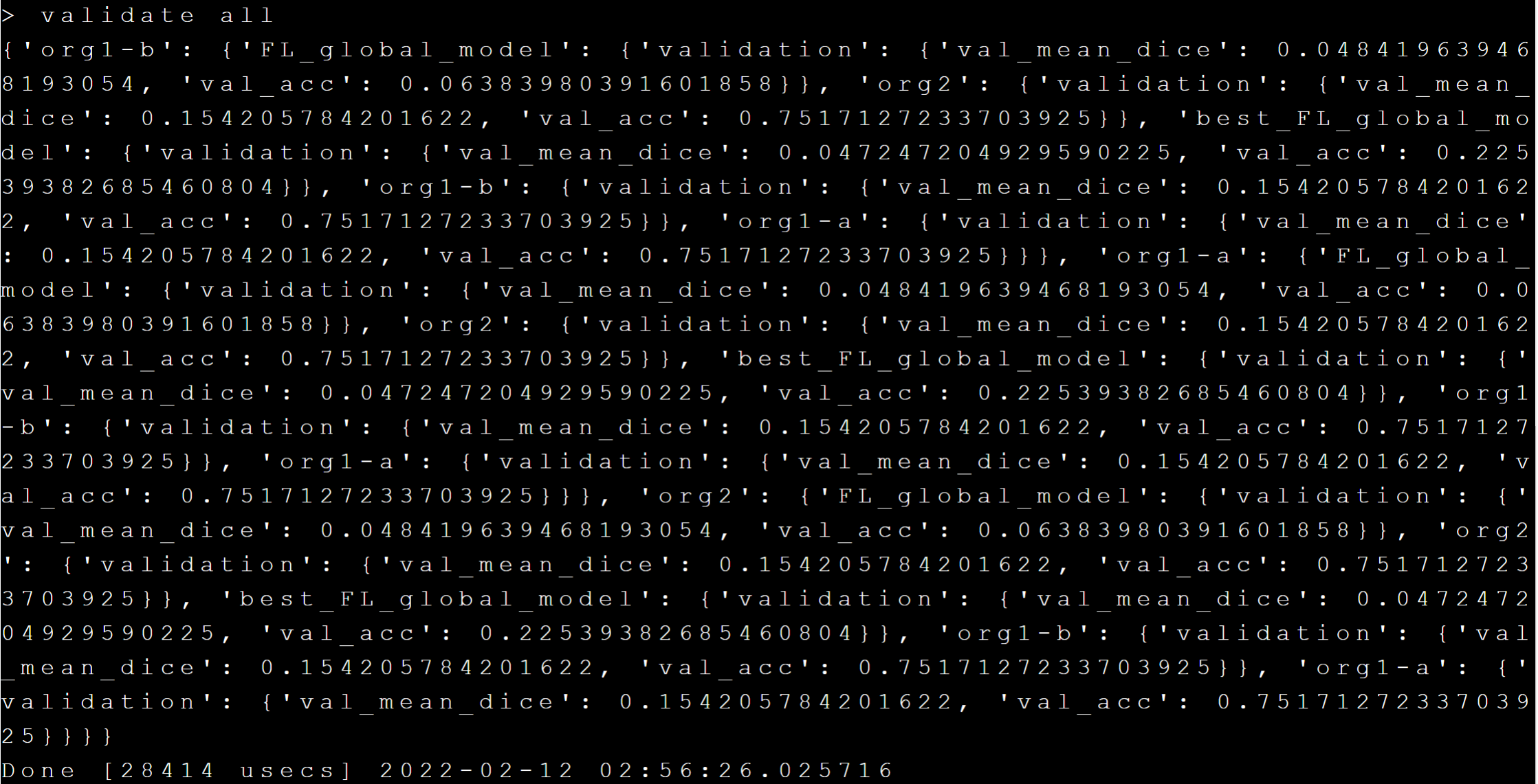
訓練完成後的模型(global model)存放在 Server 的 **run_321/mmar_server/models** 路徑下,可以執行 **`ls server run_321/mmar_server/models`** 命令查看,結果如下:

**FL_global_model.pt** 和 **best_FL_global_model.pt** 就是聯合學習成功訓練出來的模型。