---
title: AI Maker 案例教學 - 影像分類模型應用
description: OneAI 文件
tags: 案例教學
---
[OneAI 文件](/s/user-guide)
# AI Maker 案例教學 - 影像分類模型應用
[TOC]
<br>
## 0. 部署圖像分類模型
在本範例中,我們將使用 AI Maker 針對圖像分類應用所設計的 **image-classification** 範本,逐步建立一個圖像分類應用。在此範本中定義了從訓練任務到推論服務中所需環境變數、映像檔、程式... 等設定,您只須上傳欲訓練或推論的資料集,並修改相關的設定,即可快速執行訓練與推論服務。
主要步驟如下:
- **資料集準備**
在此階段,我們要著手準備要讓電腦學習的影像集,並將資料集上傳至指定位置。
- **訓練模型**
在此階段,我們將配置訓練任務,以進行神經網路的訓練與擬合,並將訓練好的模型儲存。
- **建立推論服務**
在此階段,我們會將儲存下來的模型部署到服務中,以執行推論。
<br><br>
## 1. 準備資料集並上傳
在正式開始前,請先準備好訓練用資料集,如:貓、狗、花... 等。在本範例中所使用的資料集,是由 Alexander Mamaev 提供於 kaggle 的 [Flowers Recognition(花卉資料集)](https://www.kaggle.com/alxmamaev/flowers-recognition),但為了加速範例的操作我們將類別數目由原先所提供的 5 類刪減至 3 類。
如果您想要使用自有資料集,也請依照下列步驟,將資料集依 **指定的目錄結構** 存放,再上傳至系統所提供儲存服務的儲存體即可。
:::info
:bulb: **提示:資料集大小建議**
每個類別應至少準備 300 張訓練影像與 100 張測試影像,以訓練出具備最低可行精度的模型。
:::
<br>
### 1.1 調整資料集目錄結構
準備好資料集後,請依照下列步驟調整目錄結構。
1. **建立一個名為 `dataset` 的資料夾**
開始調整資料集結構前,請先建立一個名為 **`dataset`** 資料夾,稍後用來存放我們的圖像資料。
2. **準備圖像資料**
進入 **dataset** 資料夾後,請依照留出法(Holdout method)將資料集按固定比例劃分成訓練集與驗證集,並將兩個子資料夾分別命名成 **train** 與 **valid**。再將子資料夾(**train** 與 **valid**)中的圖像依 **標籤** 建立 **資料夾** 進行分類。
完成後,資料集結構如下。其中 `rose`、`sunflower` 與 `tulip` 為要分類的花卉標籤:
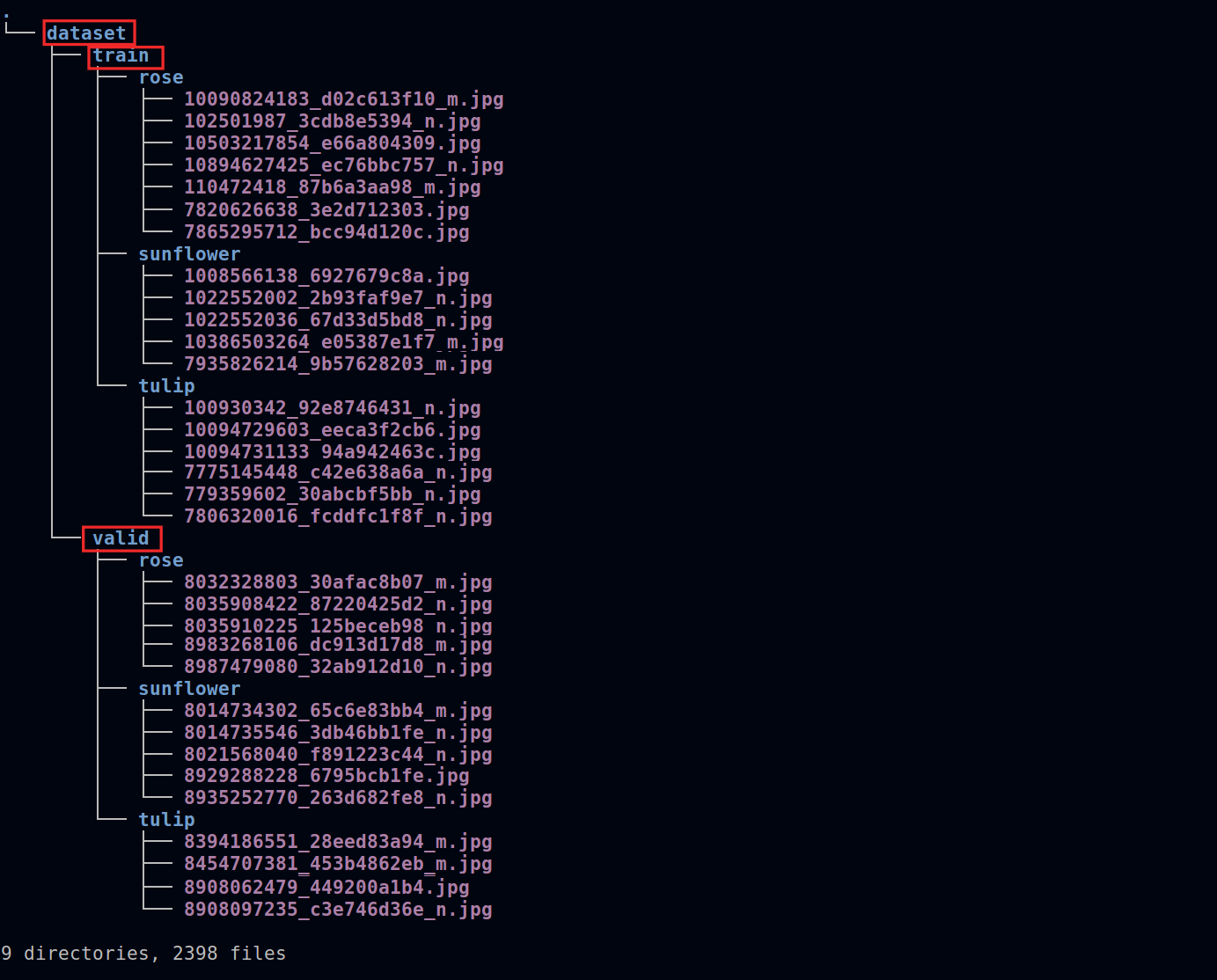
:::warning
:warning: **注意:資料夾名稱請勿更改**
請注意 **`dataset`** 、**`train`** 與 **`valid`** 等資料夾名稱,與程式的讀取有關,即上圖紅線所框出的資料夾,請勿任意更換資料夾名稱,以免程式無法順利讀取到資料集。
:::
<br>
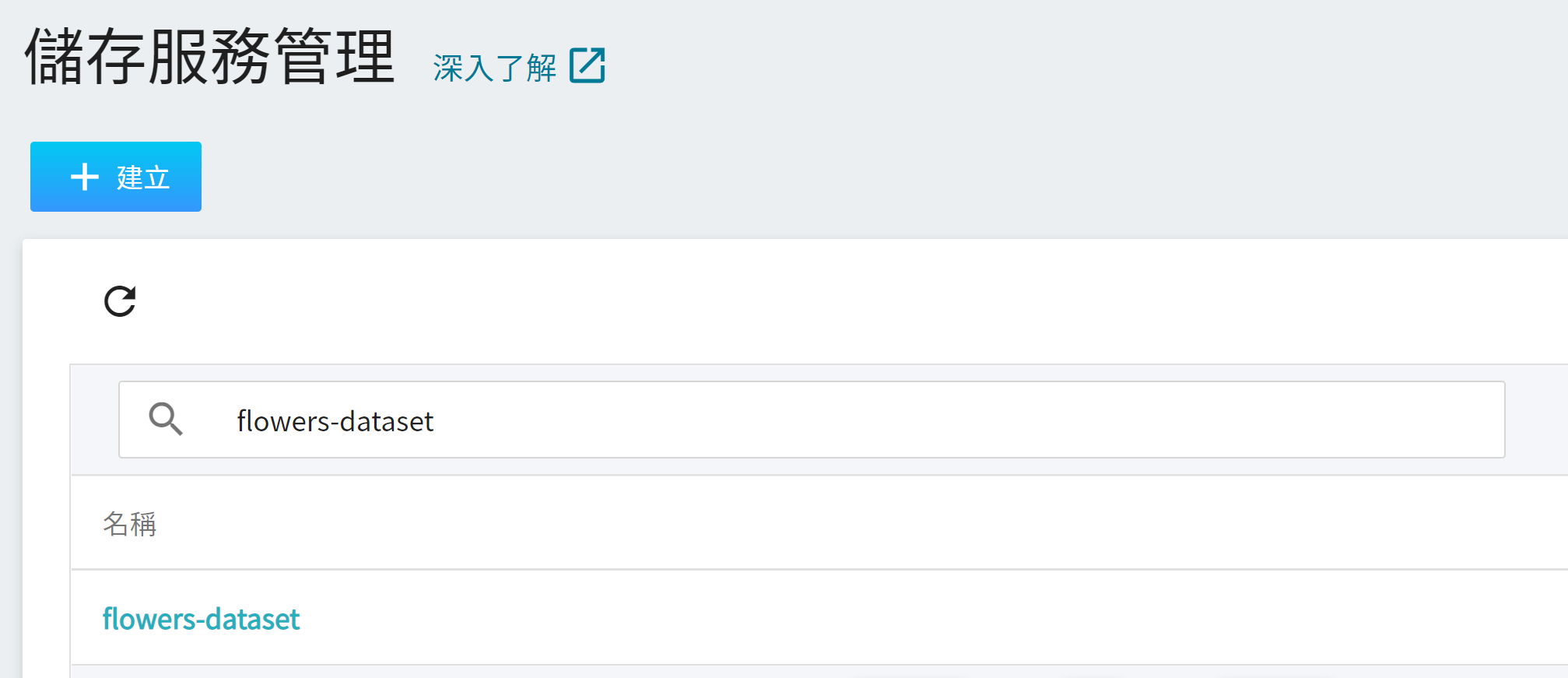
### 1.2 建立儲存體
完成資料集目錄結構的調整後,我們必須先在 **儲存服務** 中建立一個名為 **`flowers-dataset`** 的儲存體,用來存放我們的資料集。
詳細操作步驟,請參考 [**儲存服務 > 建立儲存體**](/s/storage#建立儲存體)。
<br>
### 1.3 上傳資料集
在完成資料集準備與儲存體建立後,我們就可將資料集也就是名為 **`dataset`** 的資料夾,存放到儲存體 **`flowers-dataset`** 中。若資料量不大,可以直接點選上傳,或將整的資料集拖曳上傳。
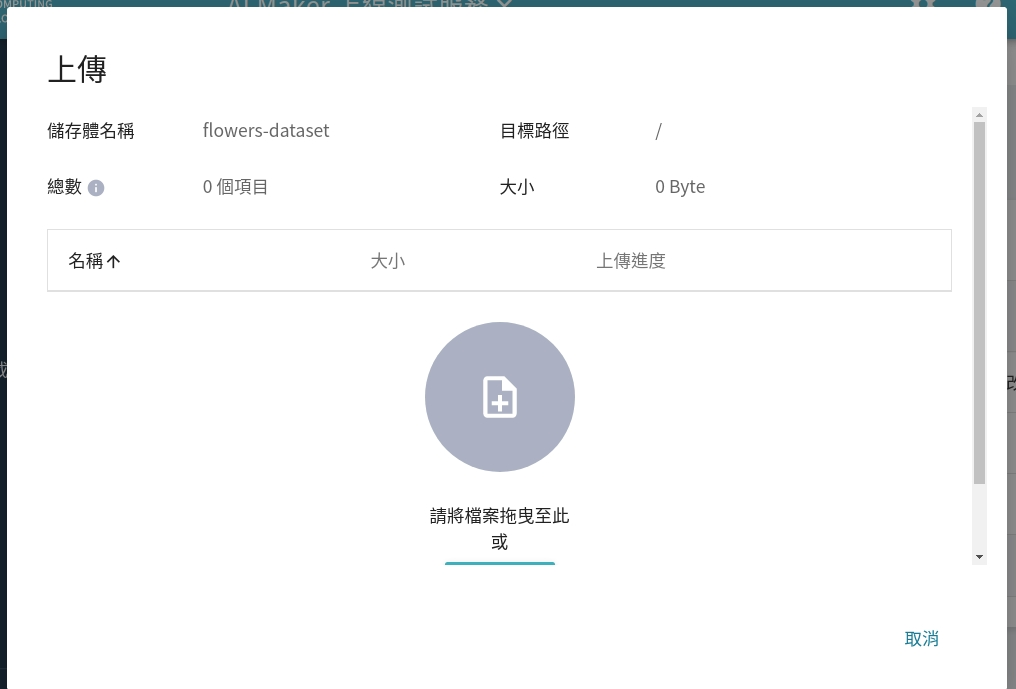
若資料量太大,可以一個個資料夾分批上傳;或是使用第三方軟體如 [**S3 Browser**](http://s3browser.com/) 或 [**Cyberduck**](https://cyberduck.io/) 上傳。
<br>
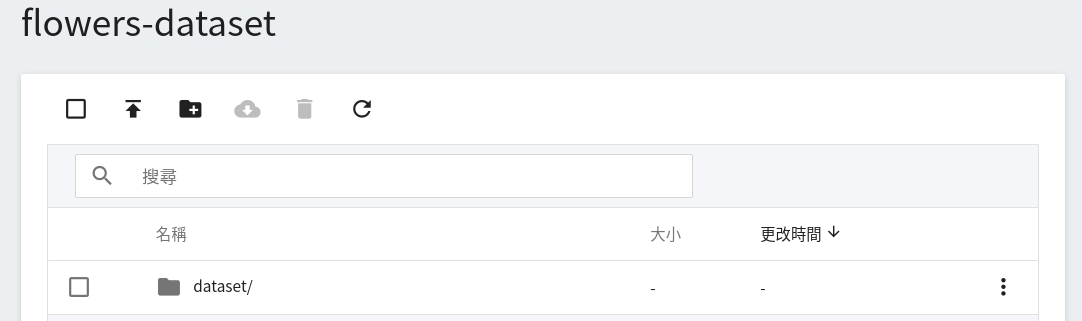
上傳完成後,在頁面上所呈現的結果如下:
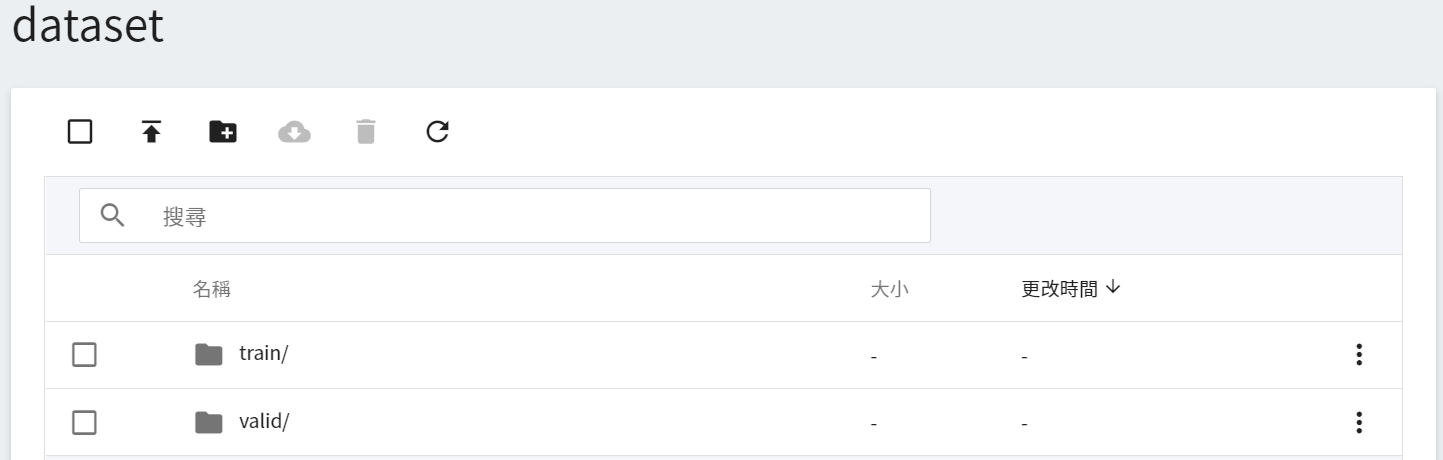
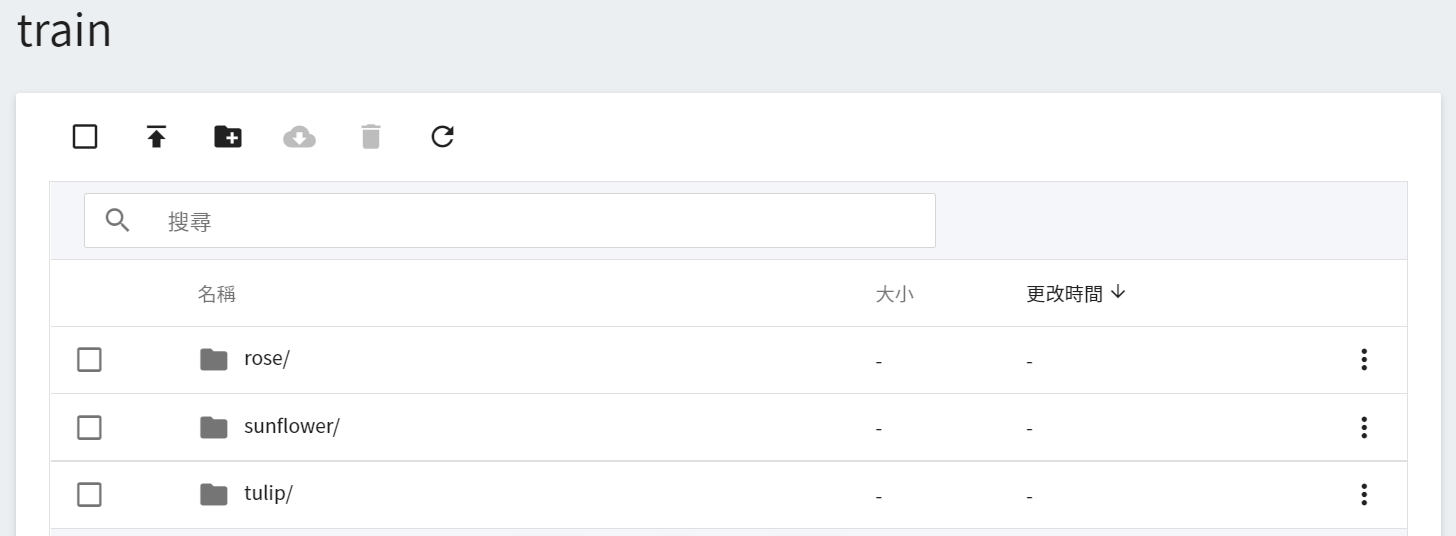
<br><br>
## 2. 訓練分類任務模型
完成 [**資料集的準備**](#1-準備資料集並上傳) 後,就可以使用這些資料,來訓練與擬合我們的分類任務模型。
<br>
### 2.1 建立訓練任務
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**訓練任務**」,進入訓練任務管理頁面。AI Maker 提供 **Smart ML 訓練任務** 與 **一般訓練任務** 兩種訓練方法,訓練方法不同所須設定的參數也有所不同。

- **一般訓練任務**
根據您所給定的訓練參數,執行一次性的訓練。
- **Smart ML 訓練任務**
可自動調整超參數,能夠有效地將計算資源用於多個模型訓練,節省您在分析和調整模型訓練參數上的時間和成本。
<br>
在此範例中我們選用 **一般訓練任務** 來建立一個新的訓練任務。訓練任務的建立步驟如下,詳細說明可參考 [**AI Maker > 訓練任務**](/s/ai-maker#訓練任務)。
1. **基本資訊**
AI Maker 為圖像分類訓練提供 **`image-classification`** 範本,在輸入名稱與描述後,您可以選擇系統所提供的 **`image-classification`** 範本,自動帶出公用映像檔 **`image-classification:v1`** 及後續步驟的各項參數設定。
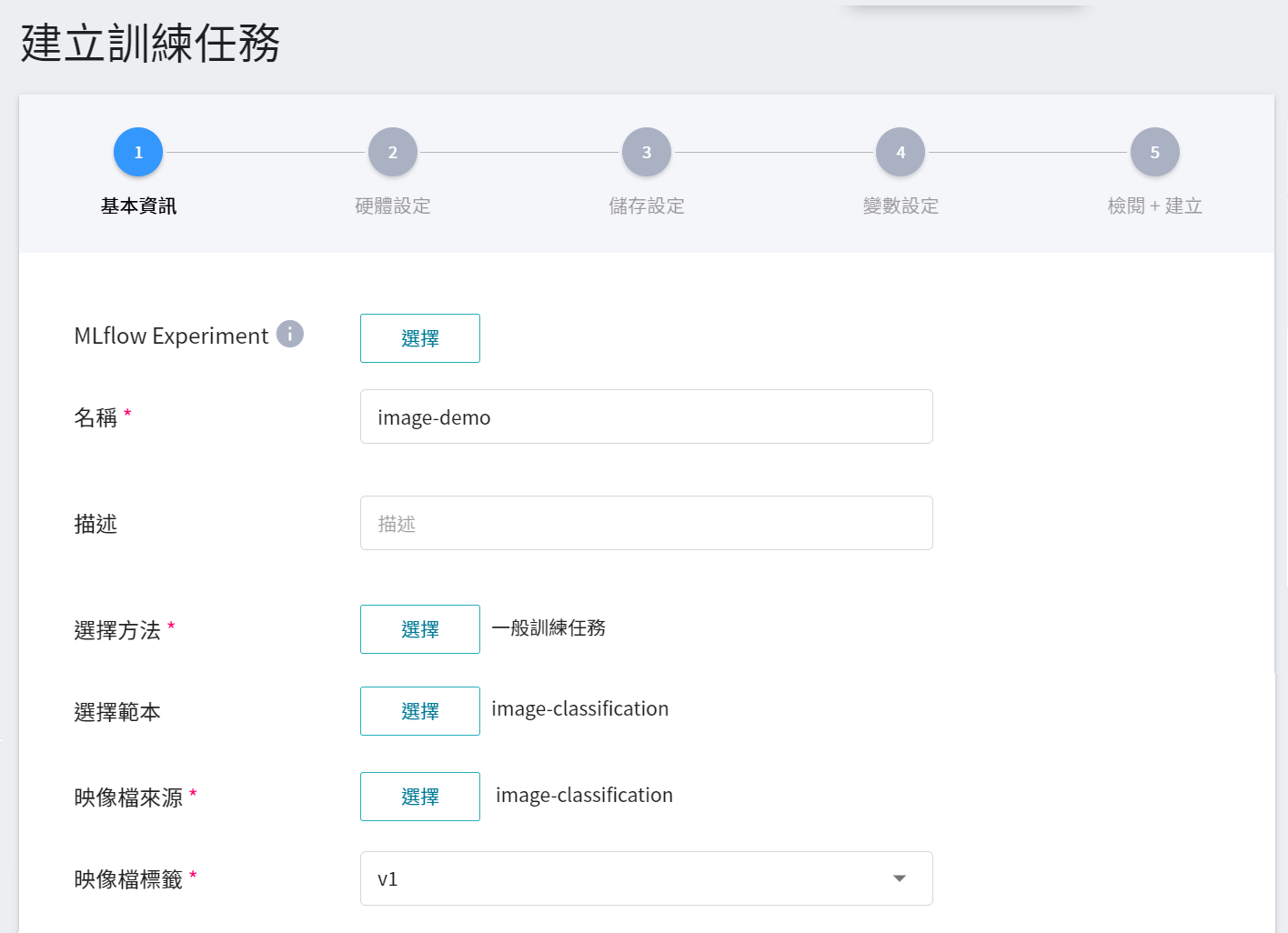
2. **硬體設定**
參考目前的可用配額與訓練程式的需求,從列表中選出合適的硬體資源。但需注意的是本範例的映像檔中所使用的機器學習框架為 **tensorflow-gpu**,因此在挑選硬體時,請選擇包含 **GPU** 的規格。
3. **儲存設定**
這個階段是將我們存放訓練資料的儲存體掛載到容器中。掛載路徑與環境變數的宣告在範本中已經設定完成,這邊只要選擇在 [**建立儲存體**](#12-建立儲存體) 步驟中所建立的儲存體名稱即可。

4. **變數設定**
在此說明映像檔 **`image-classification:v1`** 所提供的參數:
|變數|預設值|介紹|
|--|--|--|
|IS_BINARY_CLASS| false |若當資料類型為**二元分類 (Binary Class)** 時,也就是 Yes/No 問題,則將此值設定為 `1` / `true`;若否,則將此值設為 `0` / `false` ,即表示資料為**多元分類 (Multi Class)**。|
|PRETRAIN_MODEL|Auto|欲使用的欲訓練模型,目前支援 ```MobileNetV3Small、MobileNetV2、NasNetMobile、EfficientNetB0、MobileNetV3Large、DenseNet121、Xception、InceptionV3、ResNet50、InceptionResNetV2、EfficientNetB7、VGG16、VGG19```,共 13 種模型。若選擇 ```Auto```,則會依照資料集大小,從支援列表中挑選模型。|
|BATCH_SIZE|8|每批資料量的大小,不建議大於資料集中圖像的總個數。|
|NUM_EPOCHS|15|指定訓練集中全部樣本訓練的次數。|
|LEARNING_RATE |0.0001|學習率|
當在填寫基本資訊,選擇套用 **`image-classification`** 的範本,上述的變數與慣用的指令會自動帶入,惟有各個變數的設定值需依照開發需求進行調整。
#### **參數補充說明**
1. **IS_BINARY_CLASS**
若依照資料的類型可區分:**二元分類(Binary Class)** 與 **多元分類(Multi Class)** 兩種:
- **二元分類 Binary Class**
主要用來解決只有兩種結果的問題,簡單來說就是一個 **Yes/No** 問題的回答。例如:這是一張貓的圖片嗎?
:::danger
:no_entry_sign: **資料限制**
若將 IS_BINARY_CLASS 為 `1`,即二元分類模式,但所提供資料類別卻有多於兩種時,會強制中斷任務!
:::
- **多元分類 Multi Class**
顧名思義,它可以用來解決有多種回答的問題。當所提供資料類別多於兩個時,請將 `IS_BINARY_CLASS` 此值設定為 `0`。例如:這是一張貓、狗還是花的圖片?
2. **環境變數與超參數**
根據在 [**建立訓練任務**](#21-建立訓練任務) 時所選擇的訓練方法不同,即 **Smart ML 訓練任務** 與 **一般訓練任務**,變數設定會稍有不同:
|欄位名稱|說明|
| --------|--------- |
| 環境變數 | 輸入環境變數的名稱及數值。這邊的環境變數除了包含訓練執行的相關設定外,也包括了訓練網路所需的參數設定。 |
| 超參數<sup style="color:red"><b>\*</b></sup> | **(Smart ML 訓練任務)** 這是告訴任務,有哪些參數需要進行嘗試。每個參數在設定時,須包含參數的名稱、類型及數值(或數值範圍),選擇類型後(整數、小數和陣列),請依提示輸入相對的數值格式。 |
| 目標參數<sup style="color:red"><b>\*</b></sup> | **(Smart ML 訓練任務)** 在使用 **`Bayesian`** 或 **`TPE`** 演算法時,會基於 **目標參數** 的結果來反覆調校出合適參數來為作為下次訓練任務的基準。 訓練結束,會回傳一值做為最終結果,這邊須為該值設定名稱及目標方向。例如:若回傳的數值為準確率,則可命名為 accuracy,並設定其目標方向為最大值;若回傳的值為錯誤率,則命名為 error ,其方向為最小值。 |
| 命令 | 輸入欲執行的命令或程式名稱。根據此映像檔所提供的指令為:`python /workspace/train.py`。|
| 任務次數<sup style="color:red"><b>\*</b></sup> | **(Smart ML 訓練任務)** 即訓練次數設定,讓訓練任務執行多次,以找到更好的參數組合。|
其中,**環境變數** 與 **超參數** 可以互相移動。若您想固定該參數,則可將該參數從超參數區域中移除,新增至環境變數區域,並給定固定值;反之,若想將該參數加入嘗試,則將它從環境變數中移除,加入至下方的超參數區域。
請注意,若參數同時存在環境變數區域與超參數區域,超參數區域的參數值會覆蓋環境變數區域的參數值。
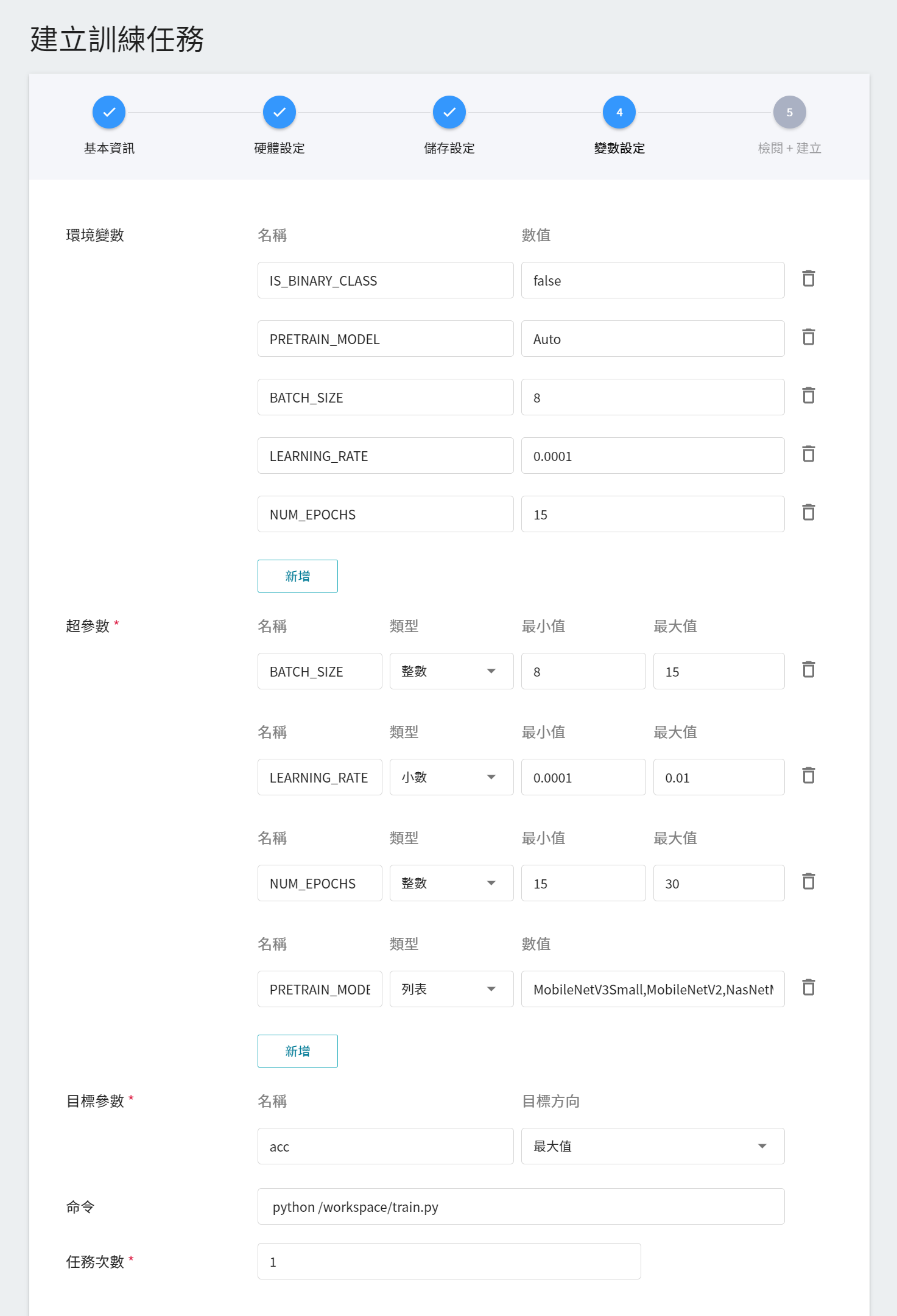
5. **檢閱 + 建立**
最後,確認填寫的資訊無誤後,就可按下建立。
<br>
### 2.2 啟動訓練任務
完成訓練任務的設定後,回到「**訓練任務管理**」頁面,可以看到剛剛建立的任務。點擊該任務,可檢視訓練任務的詳細設定。若此時任務的狀態顯示為 **`Ready`** ,即可點擊 **啟動** 圖示,執行訓練任務。
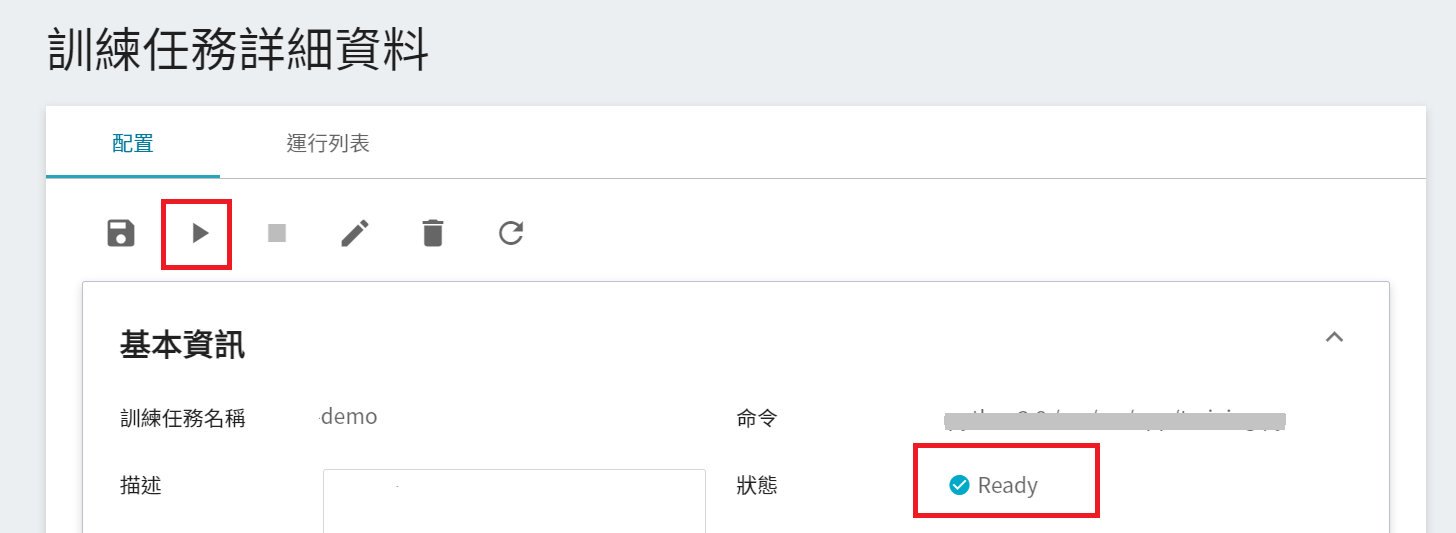
啟動後,點擊上方的「**運行列表**」頁籤,可以在列表中查看該任務的執行狀況。在訓練進行中,可以點擊任務右方清單中的「**查看日誌**」或「**查看詳細狀態**」,來得知目前執行的詳細資訊。
<br>
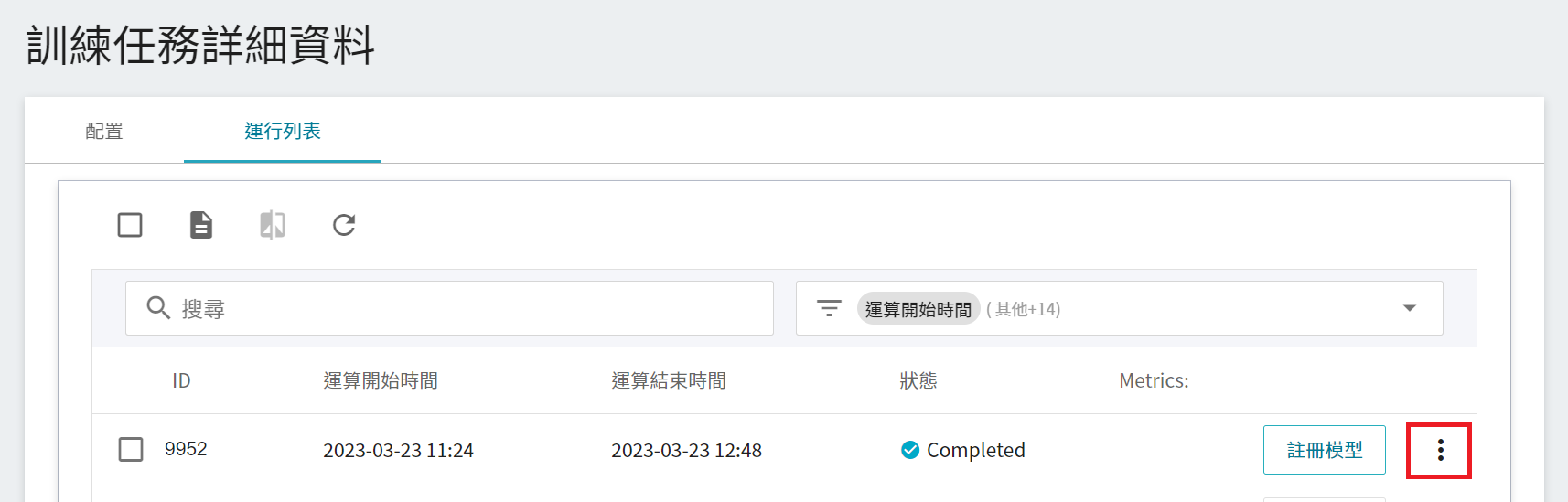
### 2.3 檢視訓練結果
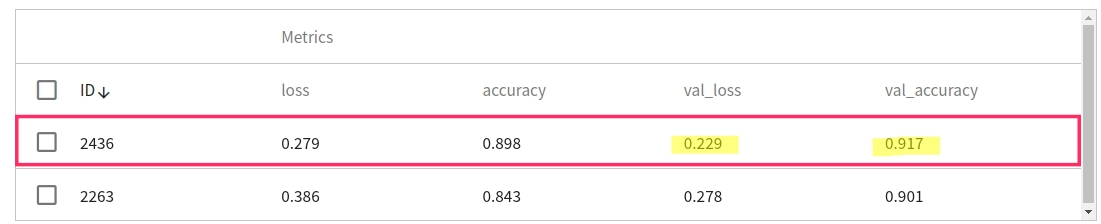
請參閱 [**AI Maker > 檢視訓練結果**](/s/ai-maker#檢視訓練結果) 文件,點擊「**運行列表**」可查看所有透過 MLflow 記錄的 Metrics 結果。
Metrics 中分別紀錄了在訓練集上與驗證集上的 loss 與 accuracy。在本範例中,優先選擇在驗證集表現較佳的結果,也就是 **val_loss 越低、 val_accuracy 越高** 的結果,因為通常訓練集與驗證集的表現會是成正比;但若兩者結果成反比,可能發生 Overfit 的現象,建議調整參數後重新訓練。
<br>
### 2.4 註冊模型
從一或多個結果中挑選出符合預期的運行列表,再點選右側「**註冊模型**」,將之儲存至模型管理中;若無符合預期結果,則重新調整環境變數與超參數的數值或數值範圍。
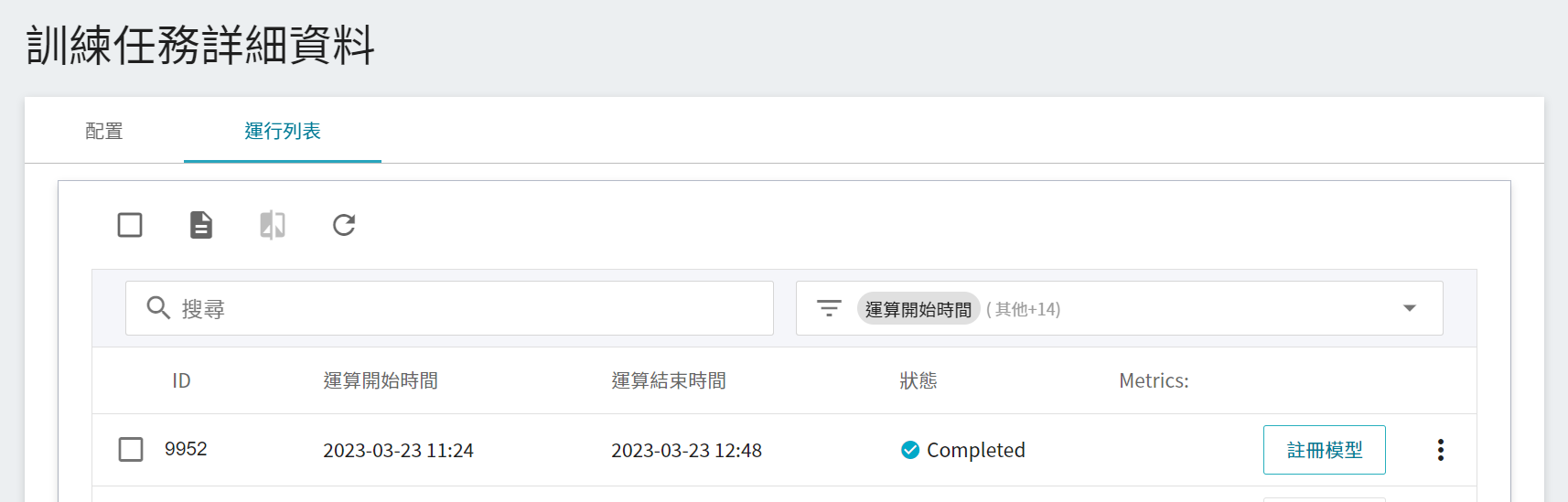
在註冊模型視窗中,點擊 **模型目錄** 右側選單可輸入欲建立的模型目錄名稱,例如:`flower` 或選擇既有的模型目錄。
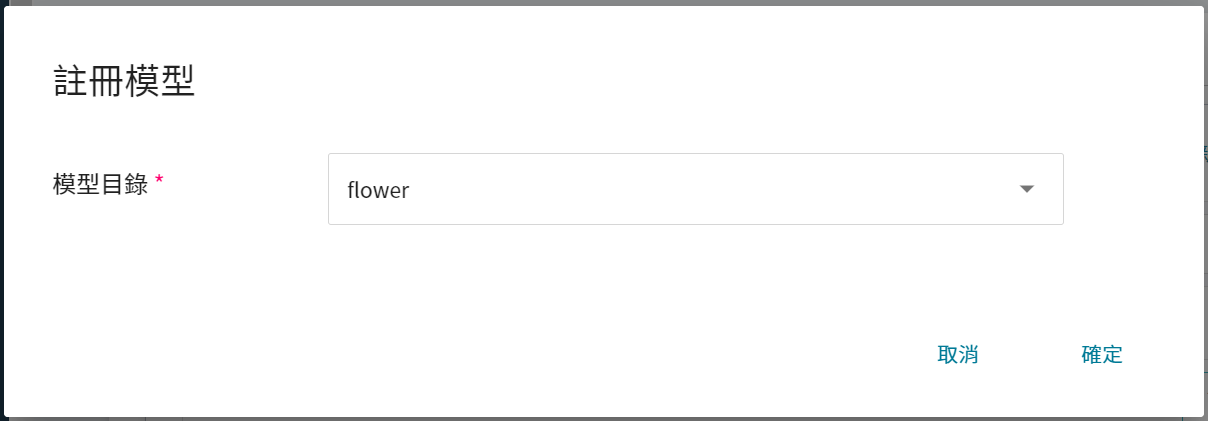
<br>
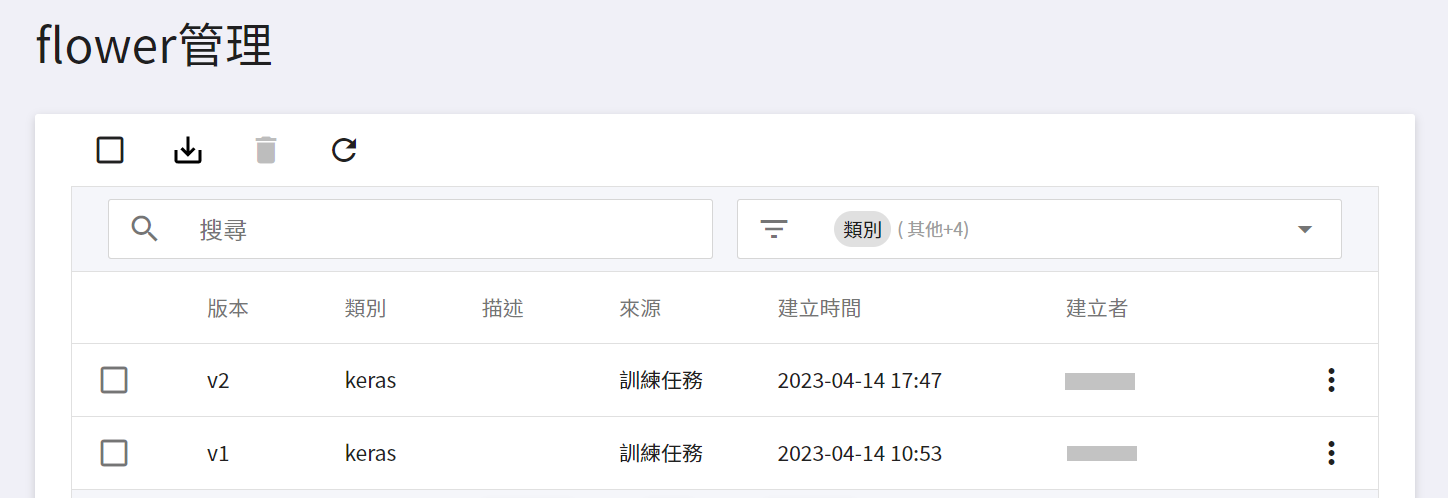
註冊模型後,會進入模型版本管理頁面。在列表中可看到儲存模型的所有版本、描述、來源與結果等資訊。
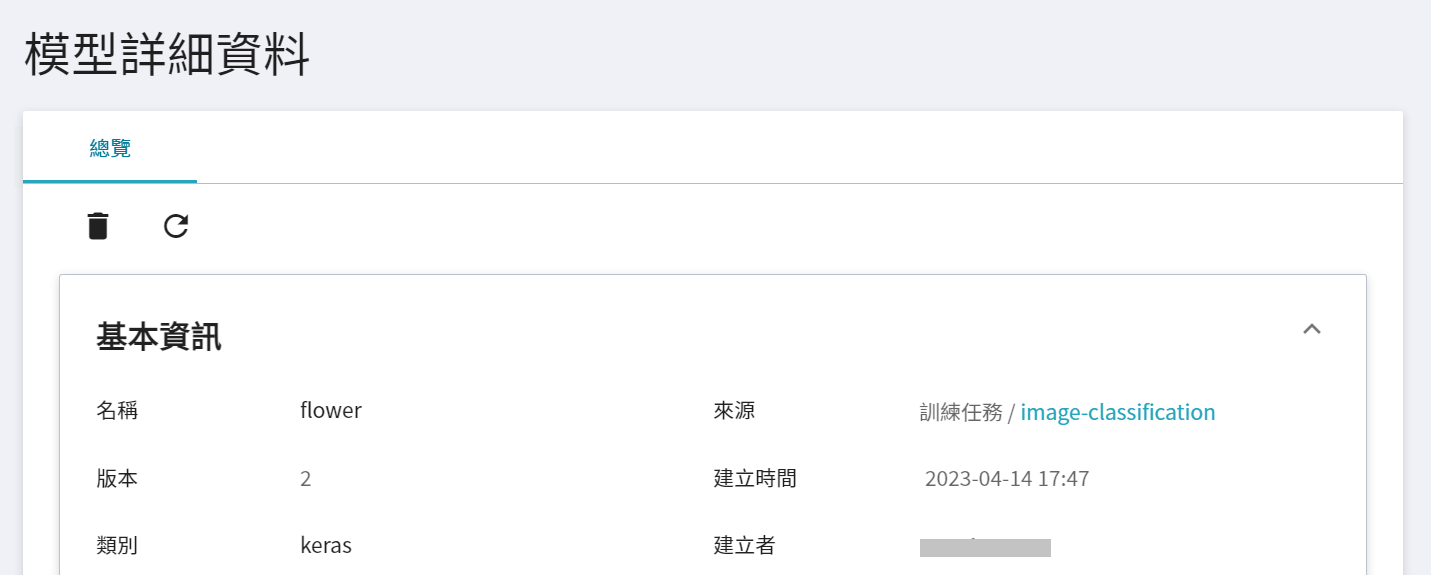
點擊版本列表,會顯示該模型版本的詳細資訊,如:模型框架、映像檔、環境變數... 等。其中 **模型框架** 會在註冊模型時由系統自動判別,並顯示在 **類別** 欄位,本範例的實作框架是採用 tf.keras,故類別顯示為 keras。
<br><br>
## 3. 建立推論服務
當您訓練好圖像分類任務網路,並儲存訓練好的模型後,即可藉由 **推論** 功能將其部署至應用程式或服務執行推論。
<br>
### 3.1 建立推論任務
請參閱 AI Maker 使用手册中的 [**推論服務**](/s/ai-maker#推論),以開始推論服務的建立,並針對本範本進行微調。
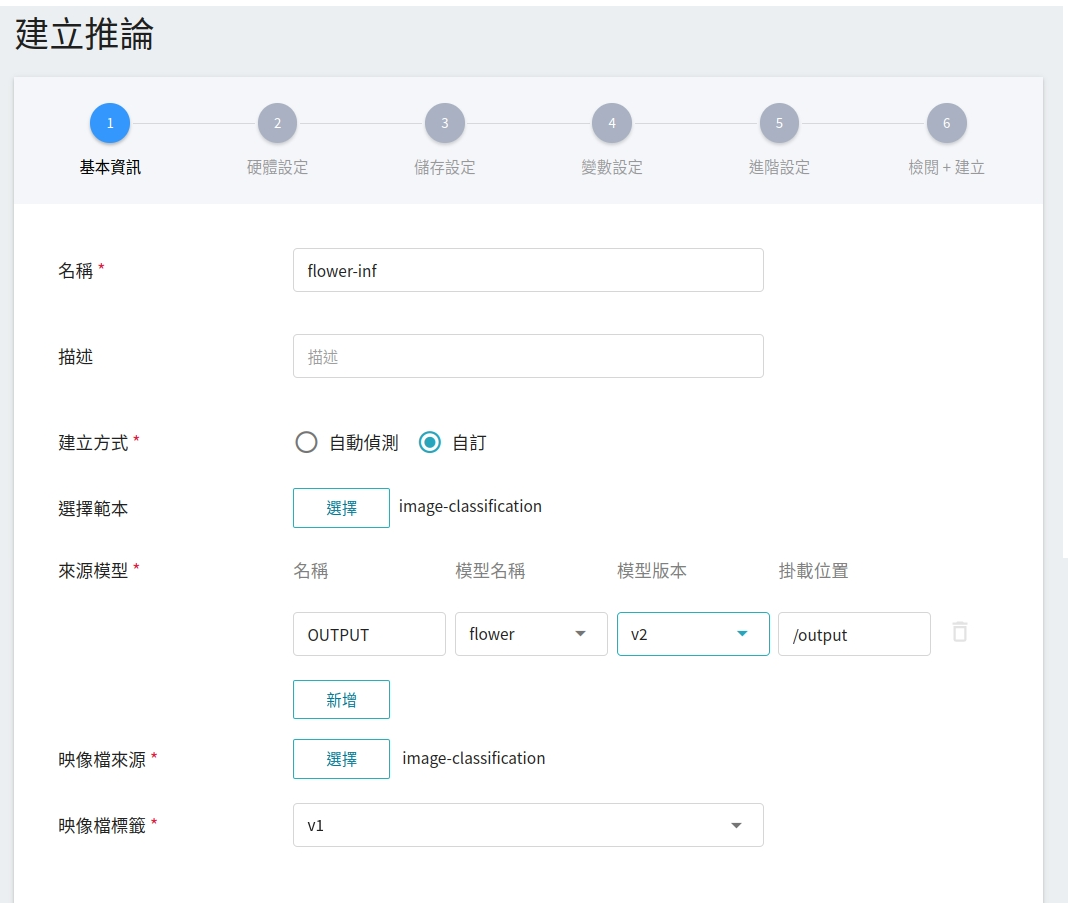
1. **基本資訊**
首先先將 **建立方式** 改成 **自訂**,以套用公用範本 **`image-classification`** 載入預設設定,將模型部署成推論 REST 端點。不過雖藉由範本載入預設設定,但所要載入的模型名稱與版號仍須使用者手動設定。
- **名稱**
載入後模型的檔案名稱,與程式進行中的讀取有關。這值會由 `image-classification` 推論範本設定。
- **模型名稱**
所要載入模型的名稱,即我們在 [**2.4 註冊模型**](#24-註冊模型) 中所儲存的模型。
- **版本**
所要載入模型的版號,亦是 [**2.4 註冊模型**](#24-註冊模型) 中所設定的版號。
- **掛載位置**
載入後模型所在位置,與程式進行中的讀取有關。這值會由 `image-classification` 推論範本設定。
2. **硬體設定**
參考目前的可用配額與需求,從列表中選出合適的硬體資源。但因本範例的映像檔中所使用的機器學習框架為 **tensorflow-gpu**,因此在挑選硬體時,請選擇包含 **GPU** 的規格。
3. **儲存設定**
此步驟無須設定。
4. **變數設定**
在變數設定步驟,這些慣用的指令與參數,會在套用範本時自動帶入。
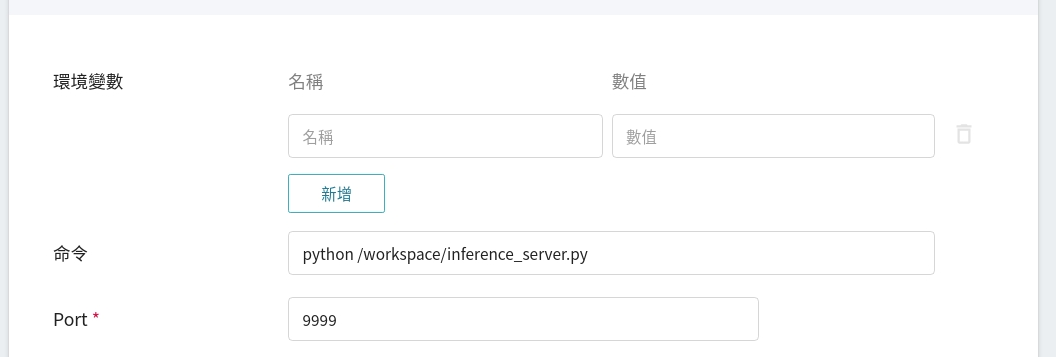
5. **進階設定**
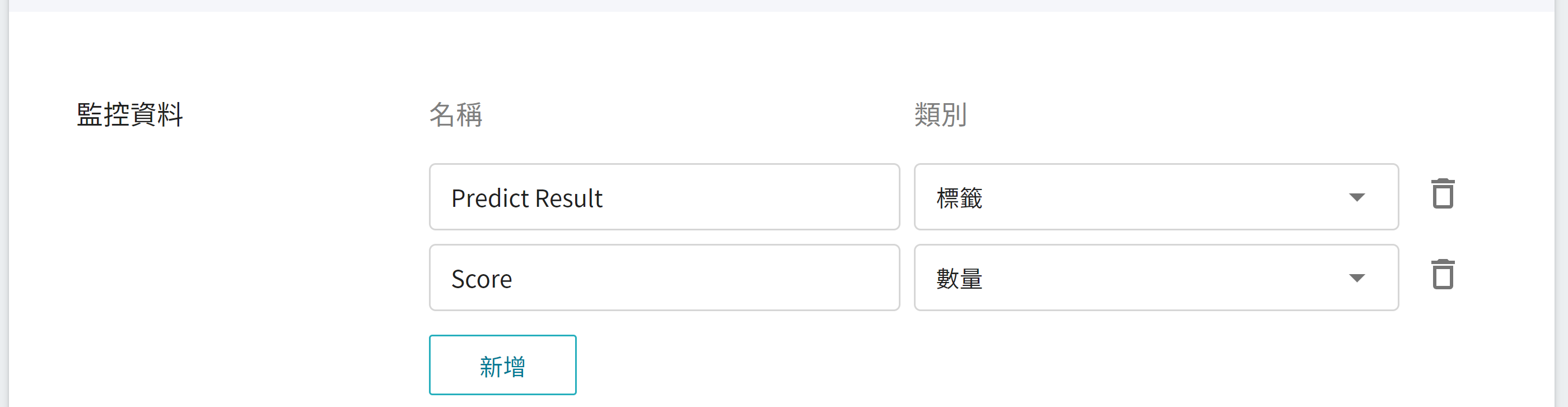
在進階設定中會設定 **監控資料**,以用於觀測推論服務一段時間內,API 呼叫次數以及推論結果所呈現的統計資訊。
<br>
| 名稱 | 類別 |說明 |
|-----|-----|------------|
|Predict Result | 標籤 | 在指定的時間區間內,該物件被偵測出所累計的總次數。<br>換言之,可看出各類別在一段時間內的分佈狀況。<br> 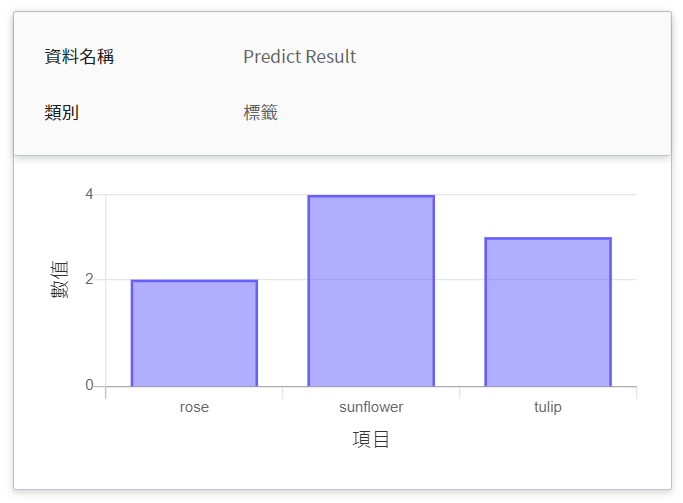
|Score| 數量 | 在某個時間點呼叫推論 API 一次,該物件被偵測出的信心值。<br>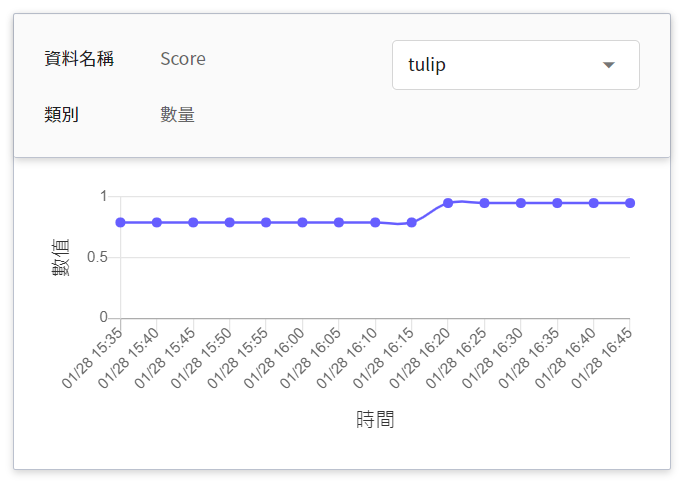|
<br>
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
<br>
### 3.2 啟動推論服務
設置任務完成後,請到該服務的推論詳細設定確認是否成功啟動。當服務的狀態顯示為 **Ready** 時,即可以開始連線到推論服務進行推論。
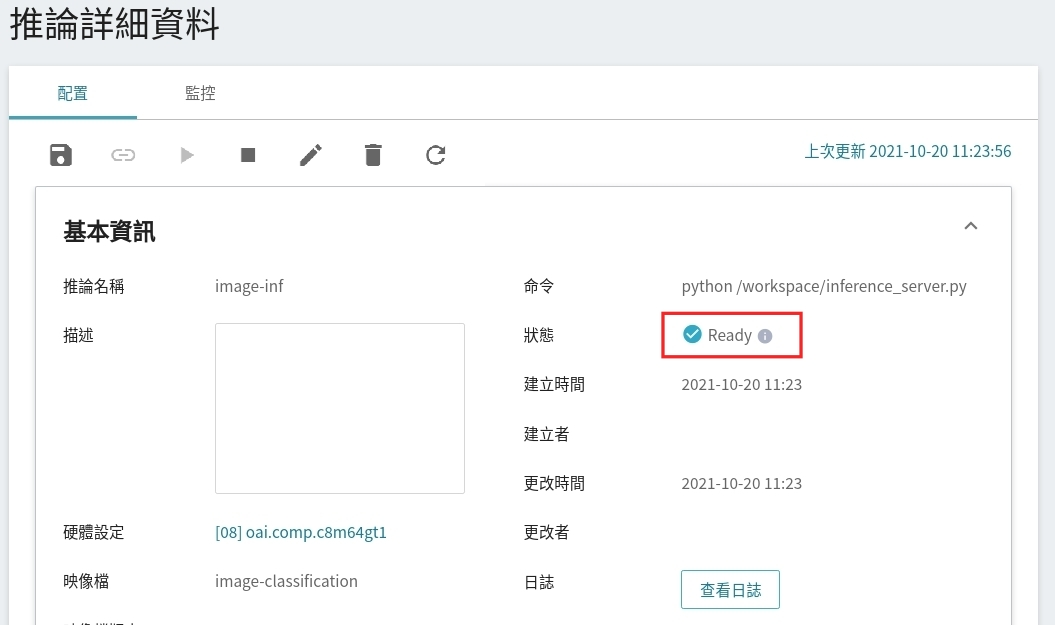
也可點擊「**查看日誌**」,若在日誌中有看到以下訊息,表示推論服務已經在運作中。
> * Running on http://{ip}:{port}/ (Press CTRL+C to quit)

<br>
此處須注意的是日誌中所顯示的網址 `http://{ip}:{port}` 只是推論服務的內部網址,並無法從外部存取。由於目前推論服務為了安全性考量沒有開放對外埠服務,但我們可以透過 **筆記本服務** 來跟已經建立好的推論服務溝通,溝通的方式就是靠「**推論詳細資料**」頁面下方 **變數資訊** 中所顯示的網址。
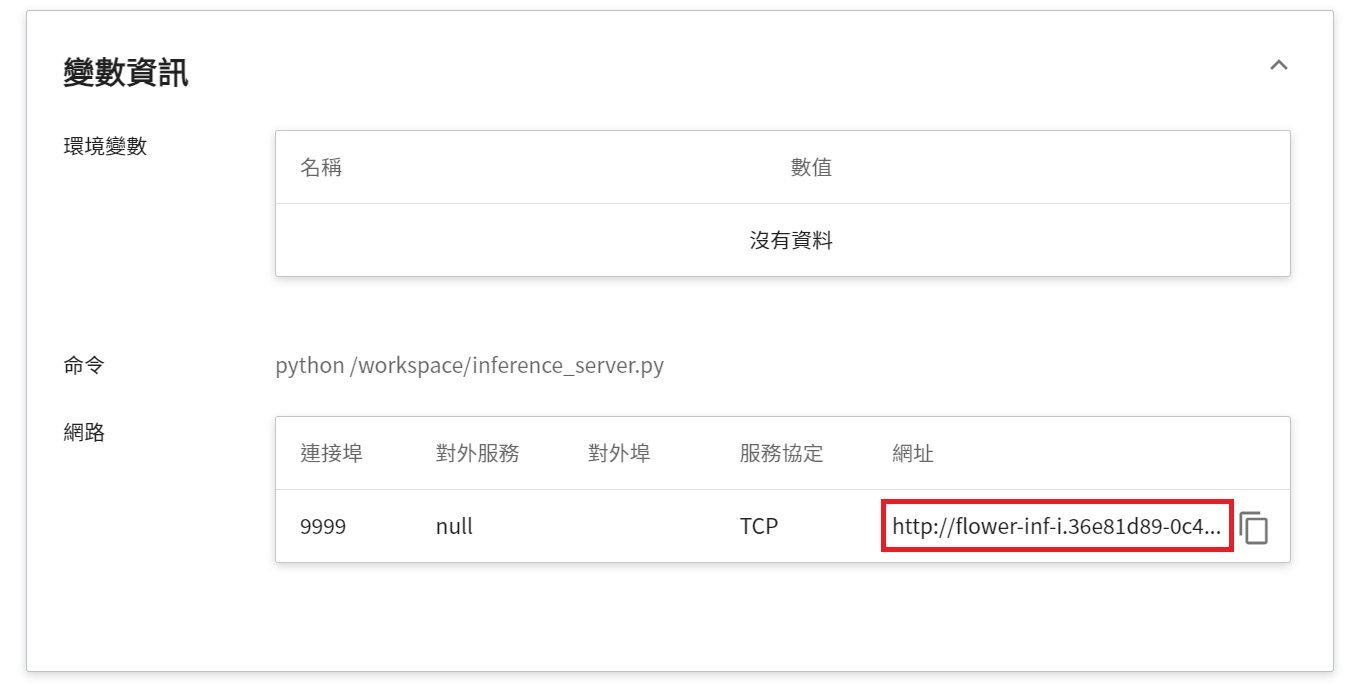
:::info
:bulb: **提示:推論服務網址**
- 文件中的網址僅供參考,您所取得的網址可能會與文件中的不同。
- 為安全性考量,目前推論服務提供的 **網址** 僅能在系統的內部網路中使用,無法透過外部的網際網路存取。
- 若要對外提供此推論服務,請參考 [**AI Maker > 對外提供服務**](/s/ai-maker#進行推論) 說明。
:::
<br>
若要查看推論監控,可點擊「**監控**」頁籤,即可在監控頁面看到相關資料,下圖為經過一段時間後的推論結果。
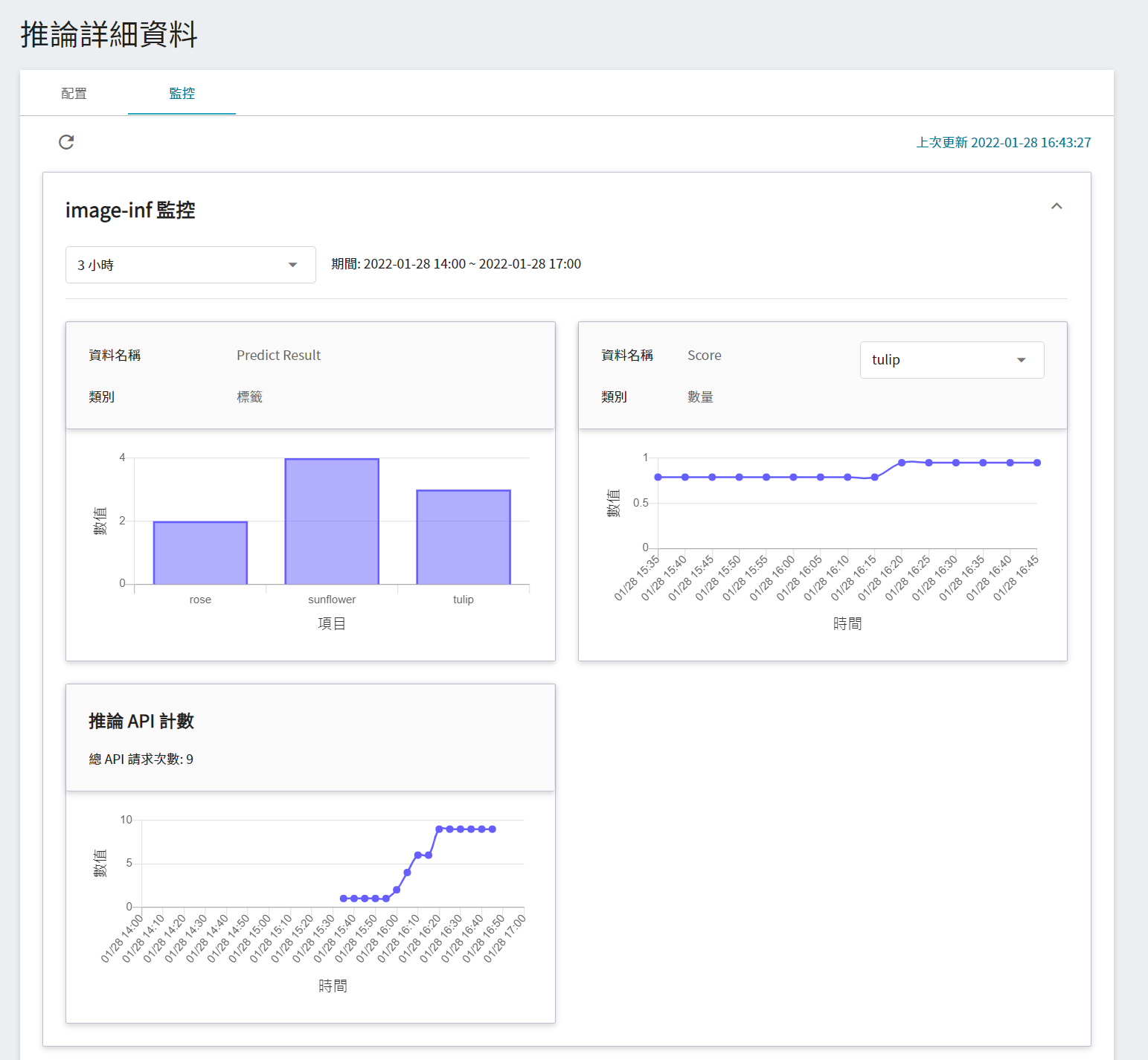
點選期間選單可篩選特定期間呼叫推論 API 的統計資訊,例如:1 小時、3 小時、6 小時、12 小時、1 天、7 天、14 天、1 個月、3 個月、6 個月、1 年或自訂。

:::info
:bulb: **關於觀測期間的起始與結束時間**
例如當前時間為 15:10,則:
- **1 小時** 的範圍是指 15:00 ~ 16:00(並非指過去一小時 14:10 ~ 15:10)
- **3 小時** 的範圍是指 13:00 ~ 16:00
- **6 小時** 的範圍是指 10:00 ~ 16:00
- 以此類推
:::
<br>
### 3.3 執行推論
啟動推論服務後,可透過 [**筆記本服務**](/s/notebook) 建立 client 端進行推論。
在建立筆記本服務時,請套用 **py3** 的環境,例如:TensorFlow-22.08-tf2-py3、PyTorch-21.02-py3,並將要進行推論的資料集掛載入筆記本中:
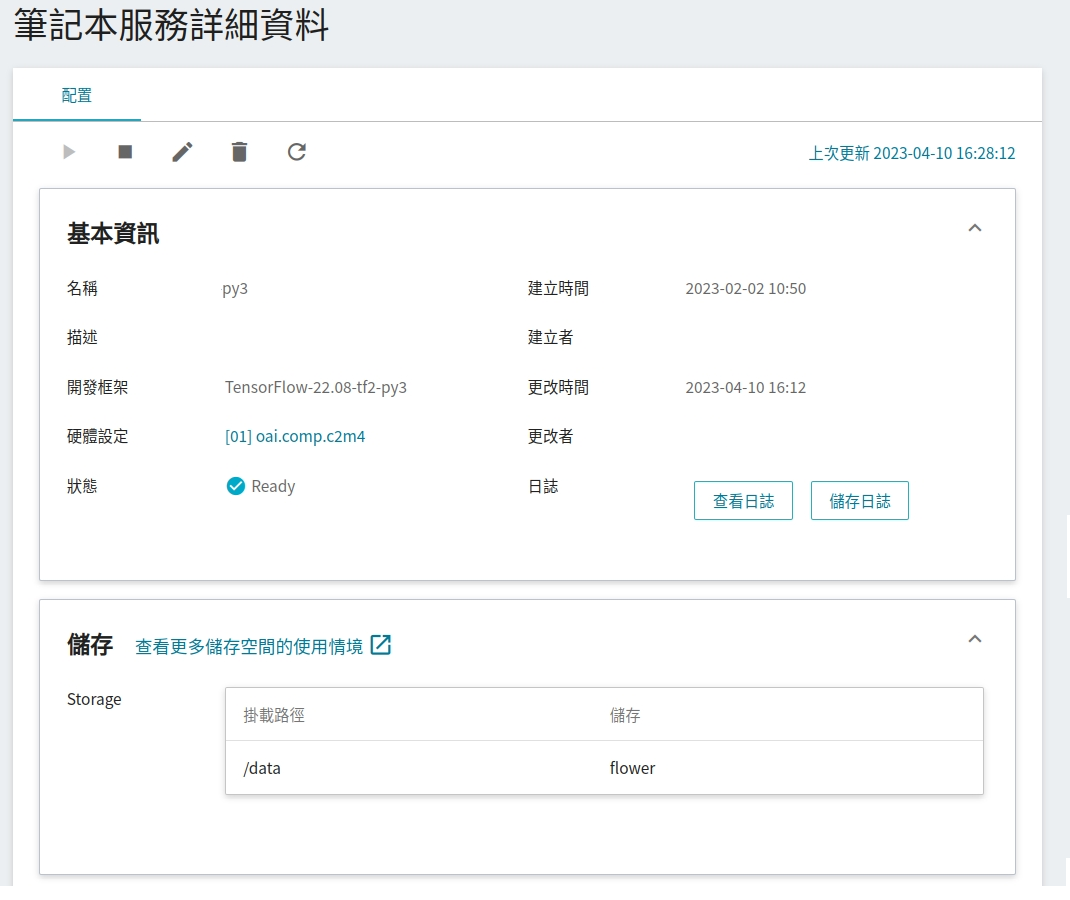
完成 Jupyter 筆記本啟動後,有兩種方法可以進行推論:
1. **使用 curl 指令測試推論服務**
一是藉由 Jupyter 的 Terminal 搭配 curl 進行推論。
```bash=
curl -X GET {推論服務網址}/hello
```
其中 `{推論服務網址}`,就是在「**推論詳細資料**」頁面下方 **網路** 資訊中所顯示的網址。依照取得的詳細資訊,替換各參數後執行,可以看到回傳的文字訊息:
```bash=
$> curl -X GET http://flower-inf-i.36e81d89-0c43-4e89-a7d8-a58705042436:9999/hello
Hello World!
```
實際執行結果如下:

<br>
若服務啟動成功,可以呼叫 `predict` 的 API,來進行推論:
```bash
$> curl -X POST {推論服務網址}/predict \
-H 'Content-Type: multipart/form-data' \
-F file=@{欲傳遞的圖片在本地端的位置}
```
當 server 端收到圖片後會進行 predict,最終返回該圖片在各類別的信心分數:

若是二元分類,則返回 Label 0、1 的標籤意義與信心分數,一般來說信心分數大於 0.5 會視為 Label 1、小於 0.5 會視為 Label 0。但該門檻值並非絕對,可依照資料集特性進行調整。

實際執行結果如下:

2. **使用 Python 程式執行推論服務**
除了使用 Terminal 連線外,也可以直接啟動 Notebook 與推論服務來進行連線,本教學的附件中提供一份 Jupyter 程式碼,您可以直接透過這份程式碼進行推論。附件程式碼的說明如下:
1. **發送請求**
在這邊使用 requests 模組產生 HTTP 的 POST 請求,並將圖片上傳。
```python=
INFE_URL = "http://flower-inf-i.36e81d89-0c43-4e89-a7d8-a58705042436:9999"
URL_BASE = "{url}".format(url=INFE_URL)
ROUTE = "/predict"
url = "{base}{route}".format(
base=URL_BASE,
route=ROUTE)
image_path = "/input/dataset/train/rose/7865295712_bcc94d120c.jpg"
image_file_descriptor = open(image_path, 'rb')
res = requests.post(url, files={'file': image_file_descriptor})
image_file_descriptor.close()
```
其中 `INFE_URL` 需要填入推論服務網址。`image_path` 則是所要推論的圖片位置。
2. **取回結果**
完成物件偵測後,結果將以 JSON 格式回傳,包含預測結果與分數。
```python=
img = mpimg.imread(image_path)
imgplot = plt.imshow(img)
plt.show()
status_code = res.status_code
content = json.loads(res.content)
content = json.dumps(content, indent=4)
print("[code]:\t\t{code}\n[content]:\n{text}".format(code=status_code,text=content))
```

#### **附件程式碼**
:::spoiler **程式碼**
```python=1
import requests
import json
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
INFE_URL = "http://flower-inf-i.36e81d89-0c43-4e89-a7d8-a58705042436:9999"
## Case1、Connect test
URL_BASE = "{url}".format(url=INFE_URL)
res = requests.get(URL_BASE)
print("[code]:\t\t{code}\n[content]:\t{text}".format(code=res.status_code,text=res.text))
# Case2、Hello World
ROUTE = "/hello"
url = "{base}{route}".format(
base=URL_BASE,
route=ROUTE)
res = requests.get(url)
print("[code]:\t\t{code}\n[content]:\t{text}".format(code=res.status_code,text=res.text))
# Case3、Predict
ROUTE = "/predict"
url = "{base}{route}".format(
base=URL_BASE,
route=ROUTE)
image_path = "/input/dataset/train/rose/7865295712_bcc94d120c.jpg"
image_file_descriptor = open(image_path, 'rb')
res = requests.post(url, files={'file': image_file_descriptor})
image_file_descriptor.close()
img = mpimg.imread(image_path)
imgplot = plt.imshow(img)
plt.show()
status_code = res.status_code
content = json.loads(res.content)
content = json.dumps(content, indent=4)
print("[code]:\t\t{code}\n[content]:\n{text}".format(code=status_code,text=content))
```
:::