---
description: OneAI 文件
tags: 案例教學, Clara, MONAI
---
[OneAI 文件](/s/user-guide)
# AI Maker 案例教學 - MONAI 1.0 教學:使用脾臟 CT 資料集訓練 3D 分割技術模型
[TOC]
## 0. 前言
MONAI(Medical Open Network for AI)是一個具有社群支援、基於 PyTorch 的醫學影像深度學習框架。它提供經過領域最佳化的基本功能,可在原生 PyTorch 範例中開發醫學影像訓練工作流程。
下圖為 MONAI 整體的架構與模組,對開發者而言,一般是使用 **Workflow** 與合適的 **基礎 Component** 來組成客製化的任務。
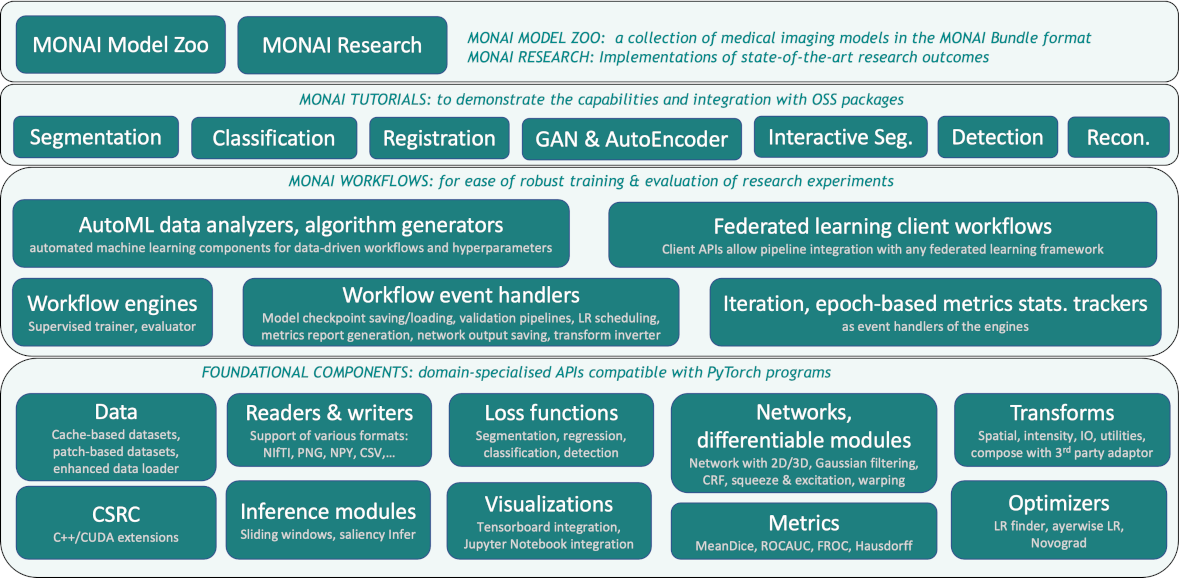
為了方便您開發醫學影像的相關服務,AI Maker 整合了 **MONAI** 醫學影像深度學習框架,提供開發訓練流程所需的軟、硬體環境,讓您能輕鬆訓練與使用醫學影像模型。
### 基礎概念
在開始前,有三個基礎概念需要先了解:
#### 1. MONAI Workflow
MONAI Workflow 是基於 PyTorch-Ignite 建構,關鍵元件為 Engine 和 Event Handler。Engines 是 Trainers、Validators 或 Evaluators,當 Trainer 帶有需要的 Components 和註冊需要的 Handlers,就可以開始訓練循環,過程中會在不同的時間觸發不同事件,呼叫對應的 Handler 執行任務,例如 CheckpointSaver 會負責模型的中繼點紀錄與最佳模型的保存。<br>
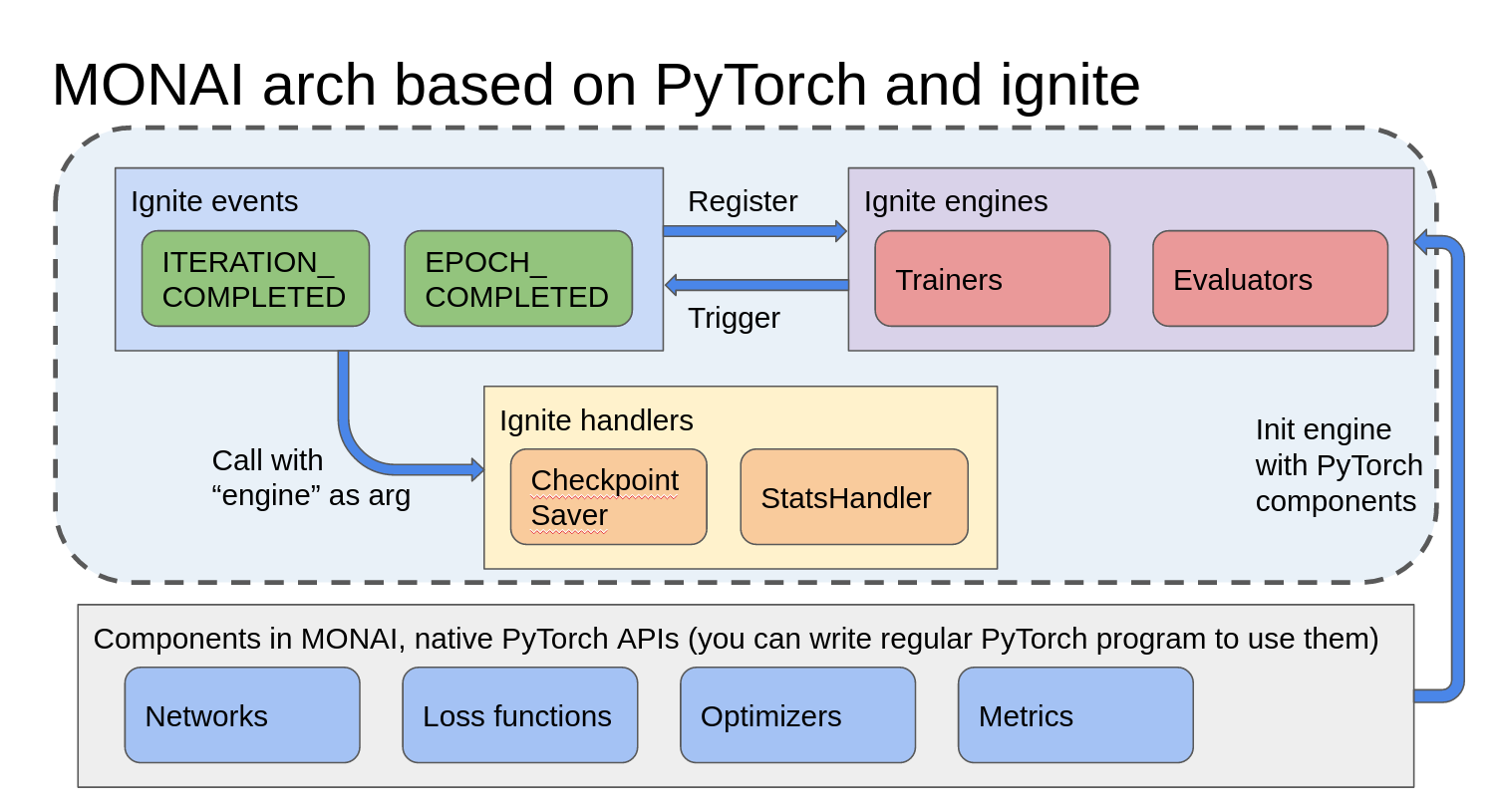
<center>圖片來源:Clara Train SDK
([Clara Train SDK 4.0](https://docs.nvidia.com/clara/clara-train-sdk/pt/essential_concepts.html) 同樣採用 MONAI 框架進行訓練)
</center>
傳統的 PyTorch 訓練任務,像是在施工現場一步一步將房子蓋起,開發者需要控制訓練循環中每一步的動作;PyTorch-Ignit 則是因應需求選擇適合的組合屋設計圖(Trainer),搭配對應的預鑄件(Components),就可搭建出成品。
#### 2. MONAI Bundle(MB):用於訓練任務與推論服務
MB 的目標是用來定義封裝的深度學習網路或模型,方便使用者與程式(MONAI Core)了解模型的使用方式。標準的 MONAI Bundle 資料結構如下:
- **configs**:包含模型相關的詮釋資料 metadata.json,構建訓練、推論和後處理等 JSON 文件。
- **models**:用來儲存訓練模型的目錄。
- **docs**:顧名思義,存放文件的地方。
```
./Project
├── configs
├── models
└── docs
```
configs 內負責訓練任務的是 train.json,也是基於 **MONAI Worklflow** 設計,除了 [**基礎的語法**](https://docs.monai.io/en/latest/config_syntax.html),文件內並沒有特定的保留字,可以簡單的將設定檔內容依用途分為四部分:
1. Script:以 MB CLI(Command-Line Interface)執行時的進入點,會帶起指定的 Trainer。
2. Engine:此處為 Trainer。
3. Components:滿足 Trainer Run 所需的元件。
4. Variables:讓前三者靈活調整用的參數。
<br>

<center>圖示說明:以 CLI 執行 MB 內指定 train.json 的各物件關聯圖,彩框的內容有 _target_ 代表是 Components,若無則是 Variables</center>
<br>
本教學所提供的範本在 **訓練任務** 時使用的就是 MB,並透過 AI Maker 進行一定程度的調整:從 [**MONAI Model Zoo**](https://monai.io/model-zoo.html) 下載的 MB,訓練時是不包含 CheckpointLoader 這個 handler,影響的是訓練開始時不會載入 models 內的 **`model.pt`** 作為 Pretrained Weight,AI Maker 會視環境變數幫忙加入對應的 handler。
目前 [**MONAI Model Zoo**](https://monai.io/model-zoo.html) 存放的醫學影像模型皆為 MB 格式,來源除了 MONAI 團隊,也有開發社群裡其他組織的貢獻,也定義了完整的貢獻指南,預期 MB 將成為最新醫療模型的分享方式。
#### 3. MONAI Label:用於推論服務
MONAI Label 是利用 AI 輔助達成互動式醫學影像標註的 Server-Client 系統,它將互動用的 REST API 都實作完畢,開發者僅需要完善模型訓練與推論的處理,並且提供了不同的領域的 Sample App 供用戶快速入門。
MONAI Label 主要由三個部分組成:
* MONAI Label Server:載入模型,定義訓練與推論所需的前處理、後處理以提供服務。
* Datastore:儲存已標註或未標註的醫學影像。
* Client/GUI:不同領域對應的 Tool 也不同,如 Radiology 是 3D Slicer/OHIF Viewer。
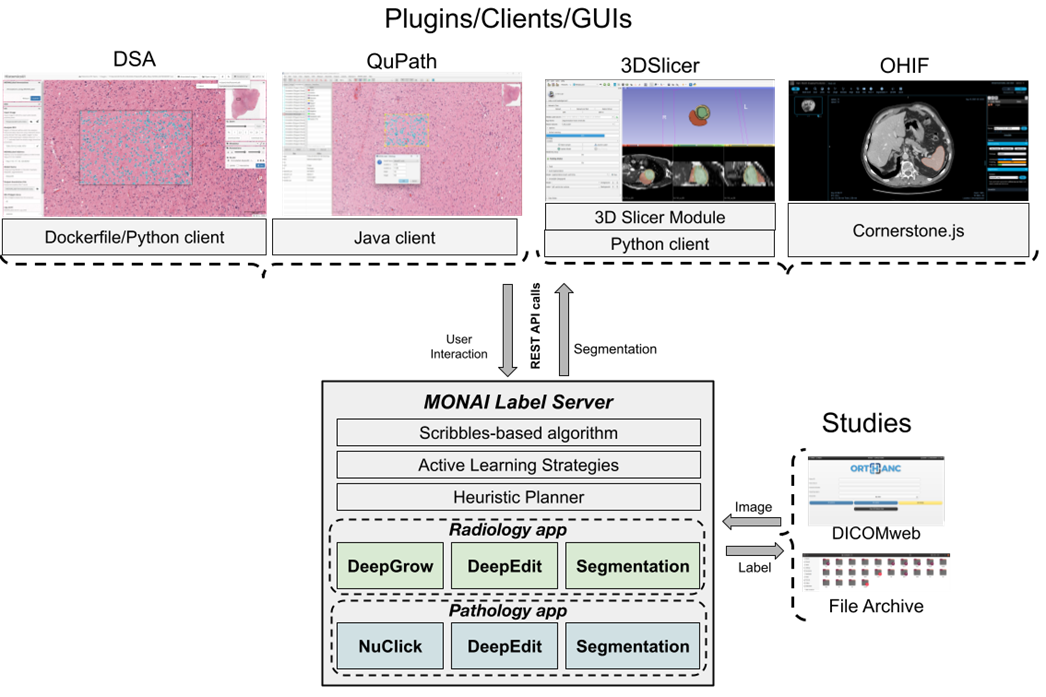
截至 MONAI Label v0.5.1,官方一共提供了四種 Sample App:[**radiology**](https://github.com/Project-MONAI/MONAILabel/tree/0.5.1/sample-apps/radiology)、[**pathology**](https://github.com/Project-MONAI/MONAILabel/tree/0.5.1/sample-apps/pathology)、[**endoscopy**](https://github.com/Project-MONAI/MONAILabel/tree/0.5.1/sample-apps/endoscopy) 和 [**monaibundle**](https://github.com/Project-MONAI/MONAILabel/tree/0.5.1/sample-apps/monaibundle),前三者都是在程式碼內就定義好使用的網路模型以及訓練或推論時需要的前處理、後處理,MONAI Label Bundle App 則是從 MB 封裝的設定檔取得前述的資訊。
本範例選擇 **MONAI Label Bundle App** 作為 **推論服務** 使用,可以很好的接續前面利用 MB 訓練出來的網路模型,也可以直接套用 MONAI Model Zoo 分享的 MB。
MONAI Label 將推論流程拆分成網路模型、前處理、推論、後處理等工作讓開發者自行定義,因此 MONAI Label Bundle App 在解析 MB 的 inference.json 時,並不會照前面的 MONAI Workflow 方式以 Engine 作為主體,而是僅 **透過 Parser 取得需要的 Components** 載入。
由於推論結束到 Client 中間仍有些轉換流程要進行,MONAI Label Bundle App 對 MONAI Model Zoo 提供的 MB 仍做不到完全相容,實際 **支援清單** 可參見 [**官方網站**](https://github.com/Project-MONAI/MONAILabel/tree/0.5.1/sample-apps/monaibundle)。
### 案例教學流程
在此案例教學中,我們將介紹如何使用公開的脾臟電腦斷層掃描(Computed Tomography,CT)資料集,訓練 3D 分割技術模型,以及如何使用訓練好的模型進行辨識。
主要步驟如下:
1. [**準備 MONAI Bundle 與資料集**](#1-準備-MONAI-Bundle-與-資料集)
在此階段,我們將介紹如何取得公開的 MONAI Bundle 與資料集,並上傳至指定位置。
2. [**訓練分割技術模型**](#2-訓練分割技術模型)
在此階段,我們將配置相關訓練任務,以進行 MONAI 的訓練與擬合,並將訓練好的模型儲存。
3. [**建立推論服務**](#3-建立推論服務)
在此階段,我們會將儲存的模型部署到推論服務中以進行推論。
4. [**MONAI Label Client**](#4-MONAI-Label-Client---3D-Slicer)
在此階段,我們介紹如何使用 [**3D Slicer**](#4-MONAI-Label-Client---3D-Slicer) 作為 MONAI Label Client 與推論服務進行連結以進行推論。
當完成本範例後,您將學會:
1. 熟悉 AI Maker 功能並建立各階段任務。
2. 使用 AI Maker 內建的範本建置相關任務。
3. 使用儲存服務並上傳資料。
4. 如何與 MONAI Label Server 連結進行推論。
## 1. 準備 MONAI Bundle 與 資料集
在此步驟中,我們介紹如何準備 MONAI Bundle 並取得相對的脾臟資料集。
### 1.1 上傳 MONAI Bundle
請參照下列步驟準備 MONAI Bundle 與資料集。
首先我們先準備 MONAI 訓練所需的 [**MONAI Bundle (MB)**](https://docs.monai.io/en/latest/mb_specification.html) 文件,在這份範例中,將使用 MONAI 提供的從 CT 圖像對脾臟進行 3D 分割的 MONAI Bundle config 與預訓練模型 [**Spleen ct segmentation**](https://github.com/Project-MONAI/model-zoo/releases/download/hosting_storage_v1/spleen_ct_segmentation_v0.3.2.zip),並將脾臟資料集上傳至平台所提供的儲存服務中。
:::info
:bulb: **提示:** 此範例需要將下載的 MB 檔解壓縮待用,並額外修改 **train.json** 的 **`dataset_dir`**,從預設值 **`/workspace/data/Task09_Spleen`** 改為 **`/dataset/Task09_Spleen`** 以符合檔案實際位置。
<br>
```json=
{
"imports": [
"$import glob",
"$import os",
"$import ignite"
],
"bundle_root": "/workspace/data/spleen_ct_segmentation",
"ckpt_dir": "$@bundle_root + '/models'",
"output_dir": "$@bundle_root + '/eval'",
"dataset_dir": "/dataset/Task09_Spleen", <--- 本範例需修改此處
...
```
:::
1. **建立儲存體**
從 OneAI 服務列表選擇「**儲存服務**」,進入儲存服務管理頁面,接著點擊「**+建立**」,新增一個名為 **`bundle`** 的儲存體,以用來存放我們的 MONAI Bundle 文件。
2. **檢視儲存體**
完成儲存體的建立後,回到「**儲存服務管理**」頁面,此時會看到剛剛新增的儲存體已建立完成。
3. **上傳 MONAI Bundle**
點擊建立好的儲存體,然後點選「**上傳**」就可以開始上傳檔案。(請參考 [**儲存服務說明**](/s/storage))。
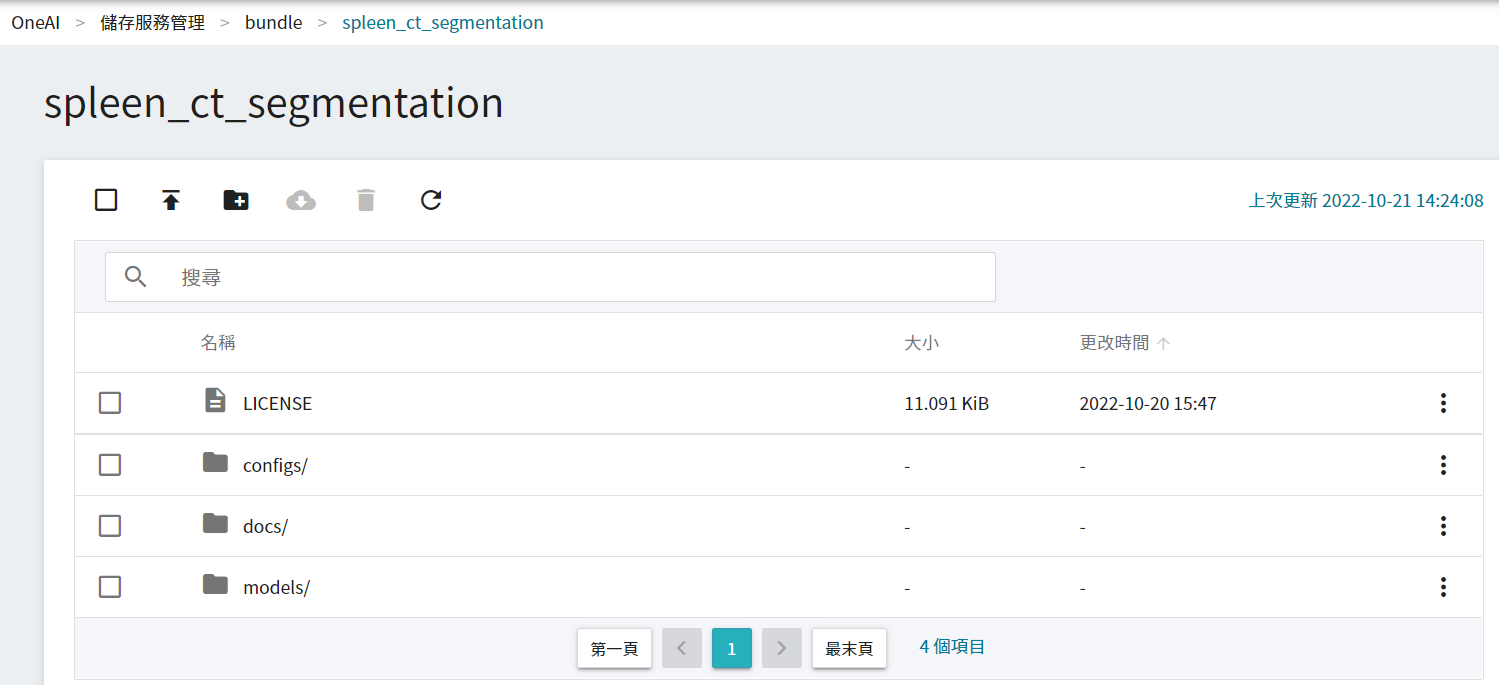
MONAI Bundle 文件中對訓練任務最關鍵的檔案,也就是 configs 下的 train.json。在這份 JSON 中,包含定義神經網路所需的所有參數、網路模型的搭建、激活函數、優化器... 等,並分別定義了 Training 與 Validation 所需的設定,詳細的介紹可以參考 [**MONAI 官方文件**](https://docs.monai.io/en/latest/config_syntax.html)。
### 1.2 上傳資料集
1. **下載公開資料集**
上傳 MONAI Bundle 檔案後,接著需準備相對的脾臟資料集,我們使用公開資料集 — [**Medical Segmentation Decathlon(醫學分割十項全能)**](http://medicaldecathlon.com/) 來進行訓練,從中下載 **`Task09_Spleen.tar`**。這是一個用於醫學影像進行圖像分割的比賽資料集,而這個 Task09 則是脾臟的資料集。資料集下載後,請進行解壓縮的動作,並準備將它們上傳至儲存服務中。
<center> <img src="/uploads/o33Cg55.png" alt="Spleen 資料集介紹"></center>
<center>Spleen 資料集介紹</center>
<center><a href="http://medicaldecathlon.com/">(圖片來源:Medical Segmentation Decathlon)</a></center>
<br><br>
2. **建立儲存體**
接下來,與建立 **`bundle`** 儲存體的步驟相似,我們建立一個名為 **`dataset`** 的儲存體,在這個儲存體中我們會用來放置脾臟資料集。
3. **上傳資料集**
接下來,將 **`Task09_Spleen.tar`** 解壓縮後的資料夾上傳至儲存體。
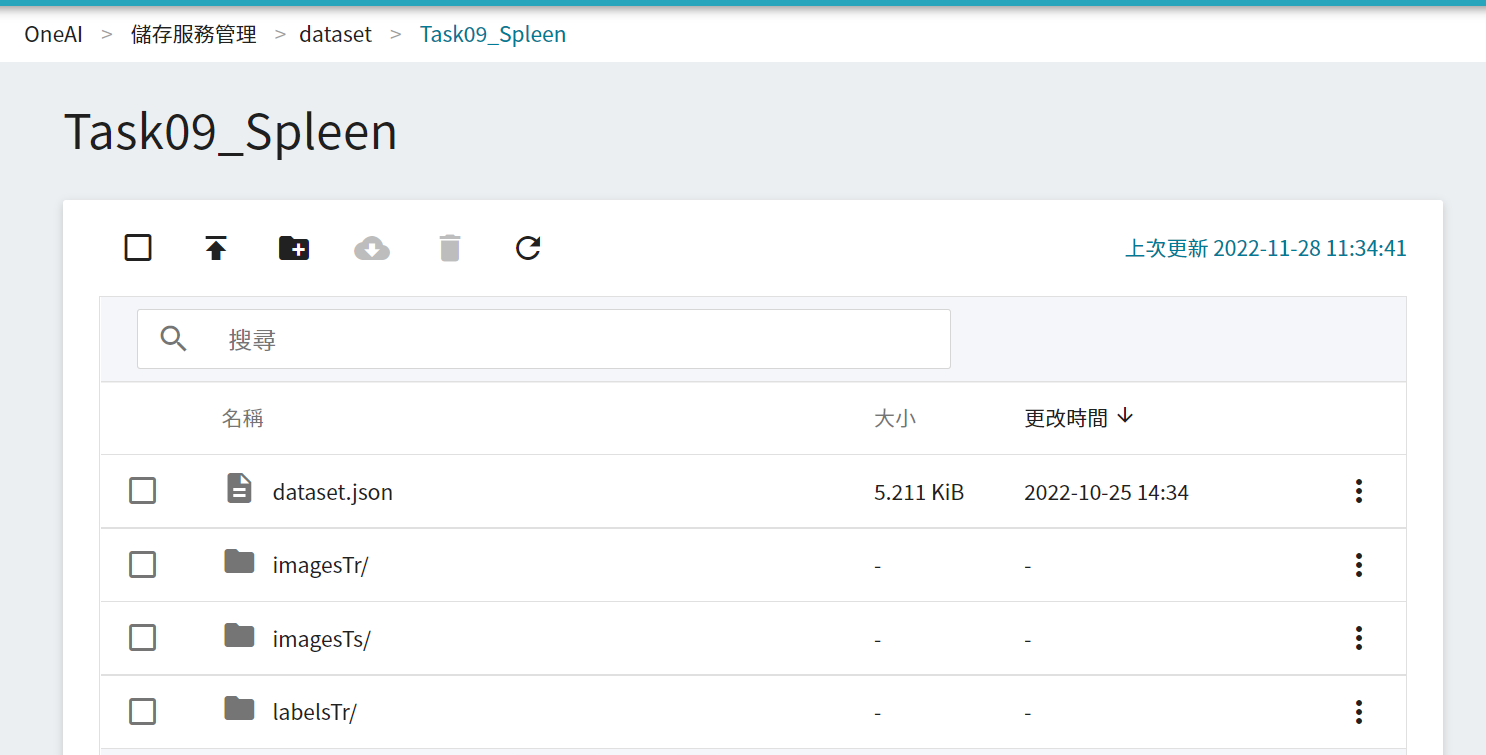
至此,我們完成了資料集的上傳。
## 2. 訓練分割技術模型
完成 [**MONAI Bundle**](#11-上傳-MONAI-Bundle) 與 [**資料集**](#12-上傳資料集) 的上傳後,我們就可以使用此資料集進行遷移學習的訓練。
### 2.1 建立訓練任務
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**訓練任務**」,進入訓練任務管理頁面後,點擊「**+建立**」,新增一個訓練任務。

#### 2.1.1 一般訓練任務
建立訓練任務可分成五個步驟:
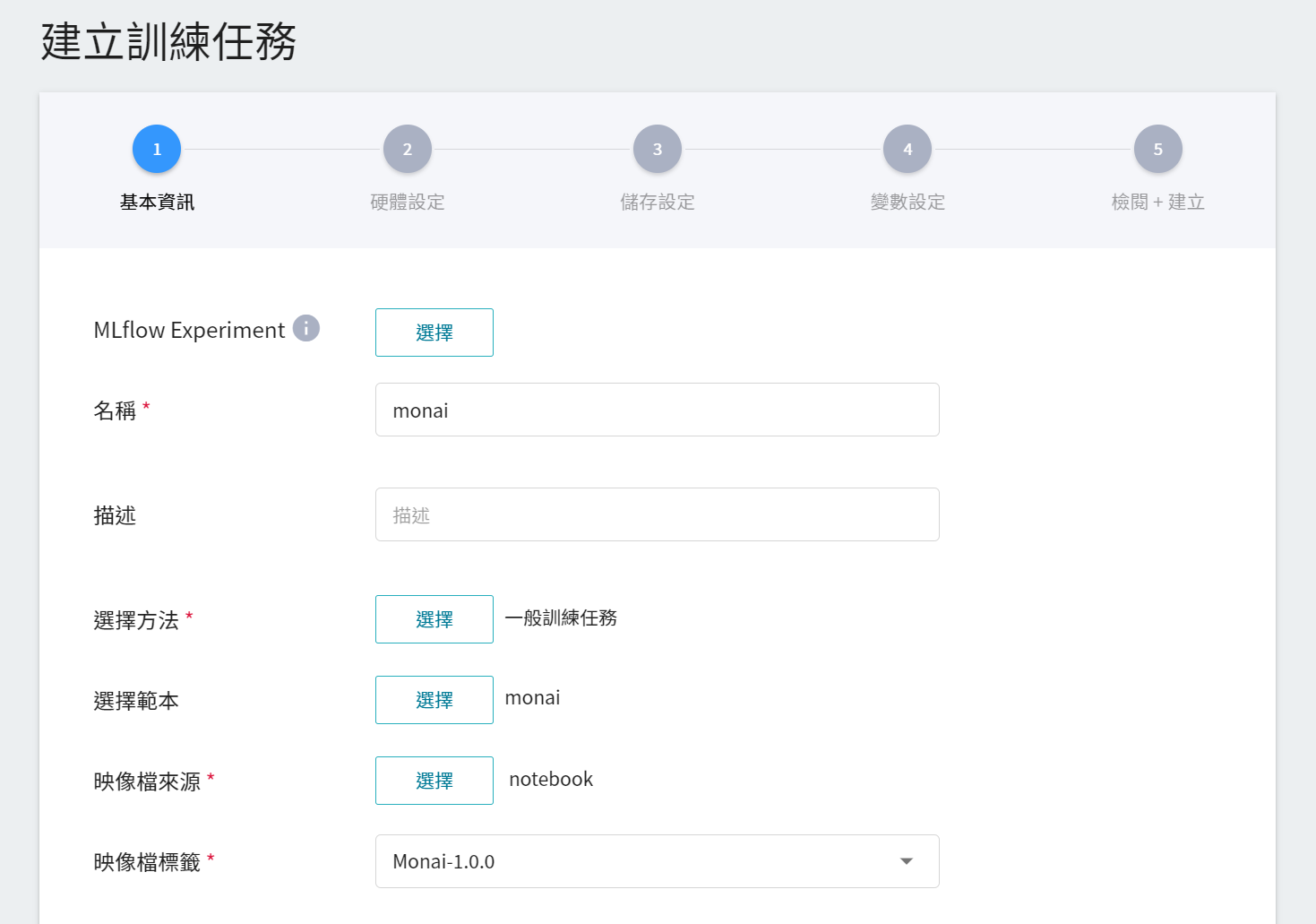
1. **基本資訊**
第一步是基本資訊的設定,請依序輸入 **名稱**、**描述**,並 **選擇方法**,在這一小節中,我們先選擇 **`一般訓練任務`** 來進行設定。除此之外,其餘的資訊可以透過 **選擇範本** 的功能,選取已經建立的範本,快速帶入各設定。
AI Maker 針對 MONAI 的訓練與使用,提供了一套 **`monai`** 的範本,定義了各階段任務所需使用的變數與設定,方便開發者迅速開發屬於自己的網路。在這階段,我們選用系統內建的 **`monai`** 的範本,來帶入各項設定。
2. **硬體設定**
參考目前的可用配額與訓練程式的需求,從列表中選出合適的硬體資源。
:::info
:bulb: **提示:** 建議選擇具有 **共享記憶體** 的硬體,以免因為資源不足而導致訓練失敗。
:::
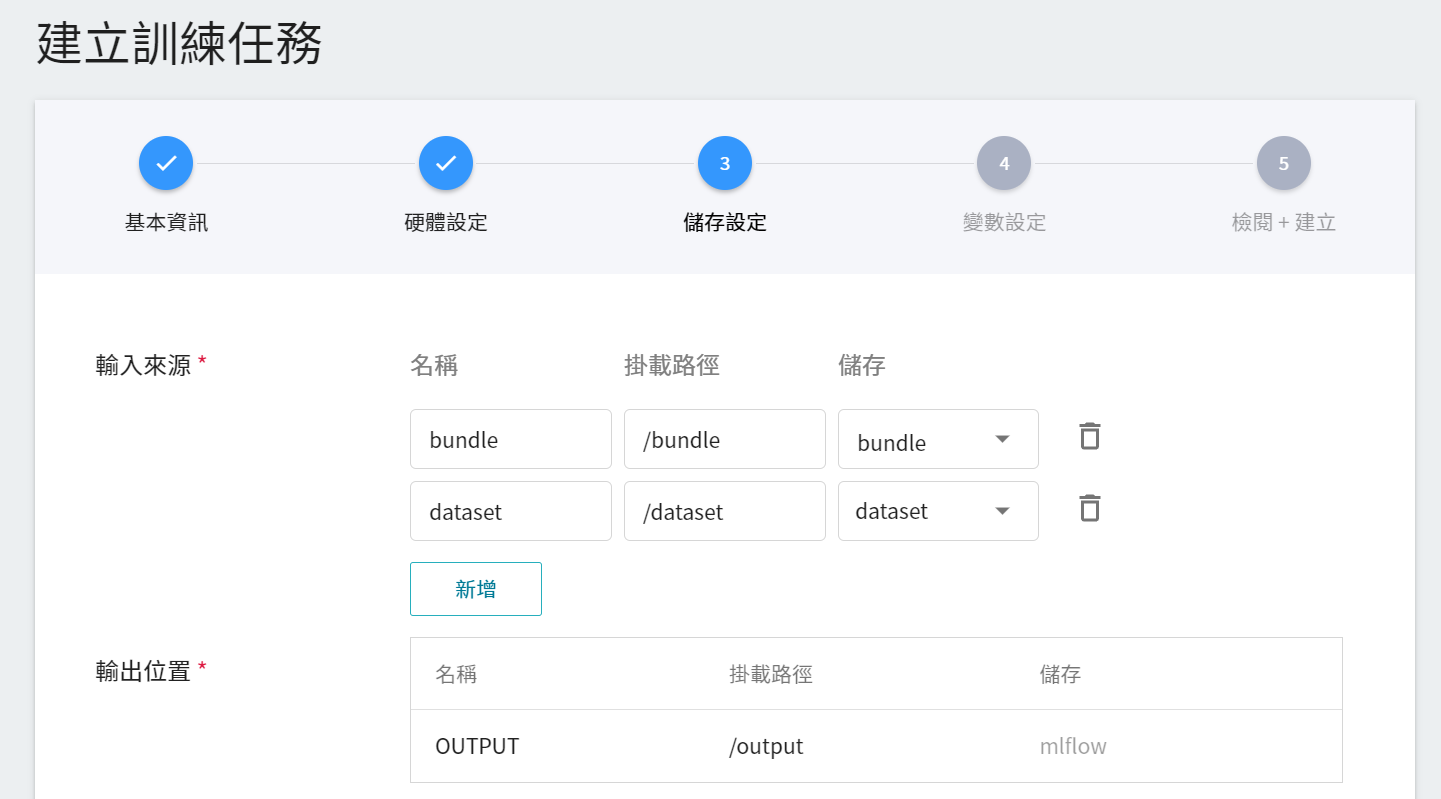
3. **儲存設定**
這個階段須掛載的儲存體有兩個:
1. **dataset**:是我們存放資料集的儲存體 **`dataset`**。
2. **bundle**:存放 MONAI Bundle 相關檔案的儲存體 **`bundle`**。
4. **變數設定**
變數設定步驟是設定環境變數及命令,不過因為在基本資訊填寫時,已經套用了 **`monai`** 範本,這些指令與參數會自動帶入。
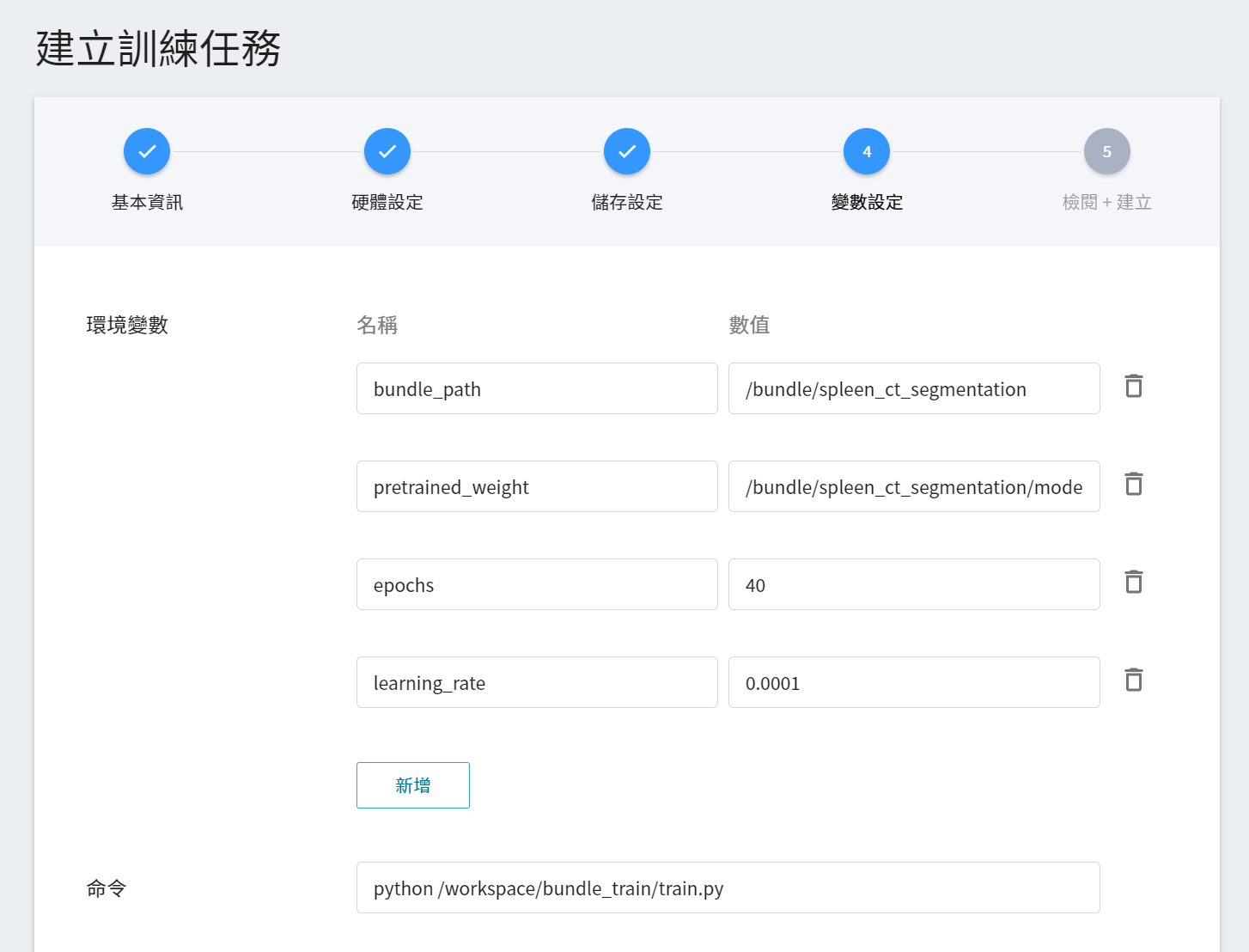
環境變數的設定值可依照您的開發需求進行調整,說明如下:
| 變數 | 預設值 | 說明 |
| ------------- | ---------- | ---- |
| bundle_path | 由 train.json 所定義 | 指定 MONAI Bundle 目錄的所在位置|
| pretrained_weight | 由 train.json 所定義 | 欲載入的預訓練模型位置,若是無此參數或檔案不存在,則會從頭開始訓練|
| epochs | 由 train.json 所定義 | 一個時期=所有訓練樣本的一個正向傳遞和一個反向傳遞。|
| learning_rate | 由 train.json 所定義 |**學習速度** 的參數,在模型學習初期時,可以設定大一點,加速訓練。在學習後期,需要設定小一點,避免發散。 |
另外,如果需要變更 MONAI Bundle 不在環境變數的神經網路參數、優化器... 等設定,就需要直接透過修改 **train.json** 來調整。
:::info
:bulb: **提示:** 如 [**1.1 上傳 MONAI Bundle**](#11-上傳-MONAI-Bundle) 所提,在 **train.json** 需要修改的 **`dataset_dir`**,此參數在不同 MB 的名稱會有所變動(例如:[**brats_mri_segmentation**](https://github.com/Project-MONAI/model-zoo/releases/download/hosting_storage_v1/brats_mri_segmentation_v0.3.7.zip) 的 train.json 就使用 **`data_file_base_dir`**),故不適合定義在環境變數。
:::
5. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
#### 2.1.2 Smart ML 訓練任務
在 [**上一小結 2.1.1**](#211-一般訓練任務) 中介紹的是 **一般訓練任務** 的建立,這邊來介紹 **Smart ML 訓練任務** 的建立,您可以只選擇任一種訓練方法或比較兩種訓練方法的差異。兩者流程大致相同,但會多出額外參數需要設定,在此僅說明多出的變數:
1. **基本資訊**
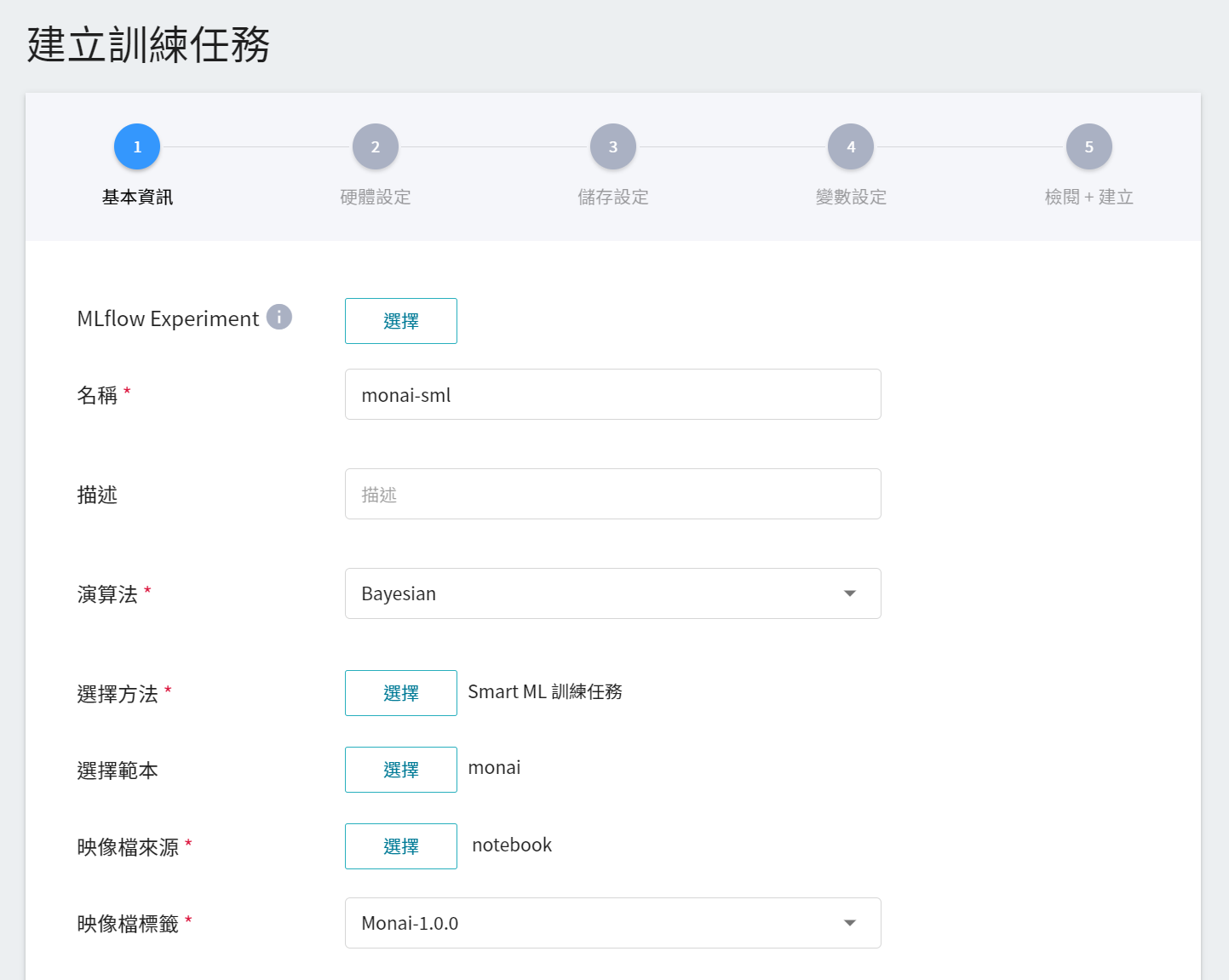
當設定方法為 Smart ML 訓練任務後,會進一步要求挑選 Smart ML 訓練任務所要使用的 **演算法**,可選擇的演算法如下:
- **Bayesian**:根據環境變數、超參數的設置範圍和訓練的次數,能有效地執行多項訓練任務,以找到更好的參數組合。
- **TPE**:Tree-structured Parzen Estimator,與 Bayesian 演算法類似,可優化高維度超參數的訓練任務。
- **Grid**:經驗豐富的機器學習使用者可以指定超參數的多個值,系統將根據超參數列表的組合執行多個訓練任務,並獲得計算結果。
- **Random**:在指定範圍內隨機選擇用於訓練任務的超參數。
2. **變數設定**
在變數設定的頁面中,會多出以下設定:
* **超參數**
這是告訴任務,有哪些參數需要進行嘗試。每個參數在設定時,須包含參數的名稱、類型及數值(或數值範圍),選擇類型後(整數、小數和陣列),請依提示輸入相對的數值格式。
範本提供了模型訓練常用的三種超參數:
- loss:調整損失函式
- optimizer:調整優化器的選擇
- learning_rate:optimizer 內的梯度變化值
* **目標參數(Bayesian 或 TPE 演算法)**
在使用 Bayesian 或 TPE 演算法時,會基於 **目標參數** 的結果來反覆調校出合適參數,作為下次訓練任務的基準。訓練結束會回傳一值做為最終結果,這邊為該值設定名稱及目標方向。例如:若回傳的數值為準確率,則可命名為 accuracy,並設定其目標方向為最大值;若回傳的值為錯誤率,則命名為 error ,其方向為最小值。
* **任務次數**
即訓練次數設定,讓訓練任務執行多次,以找到更好的參數組合。
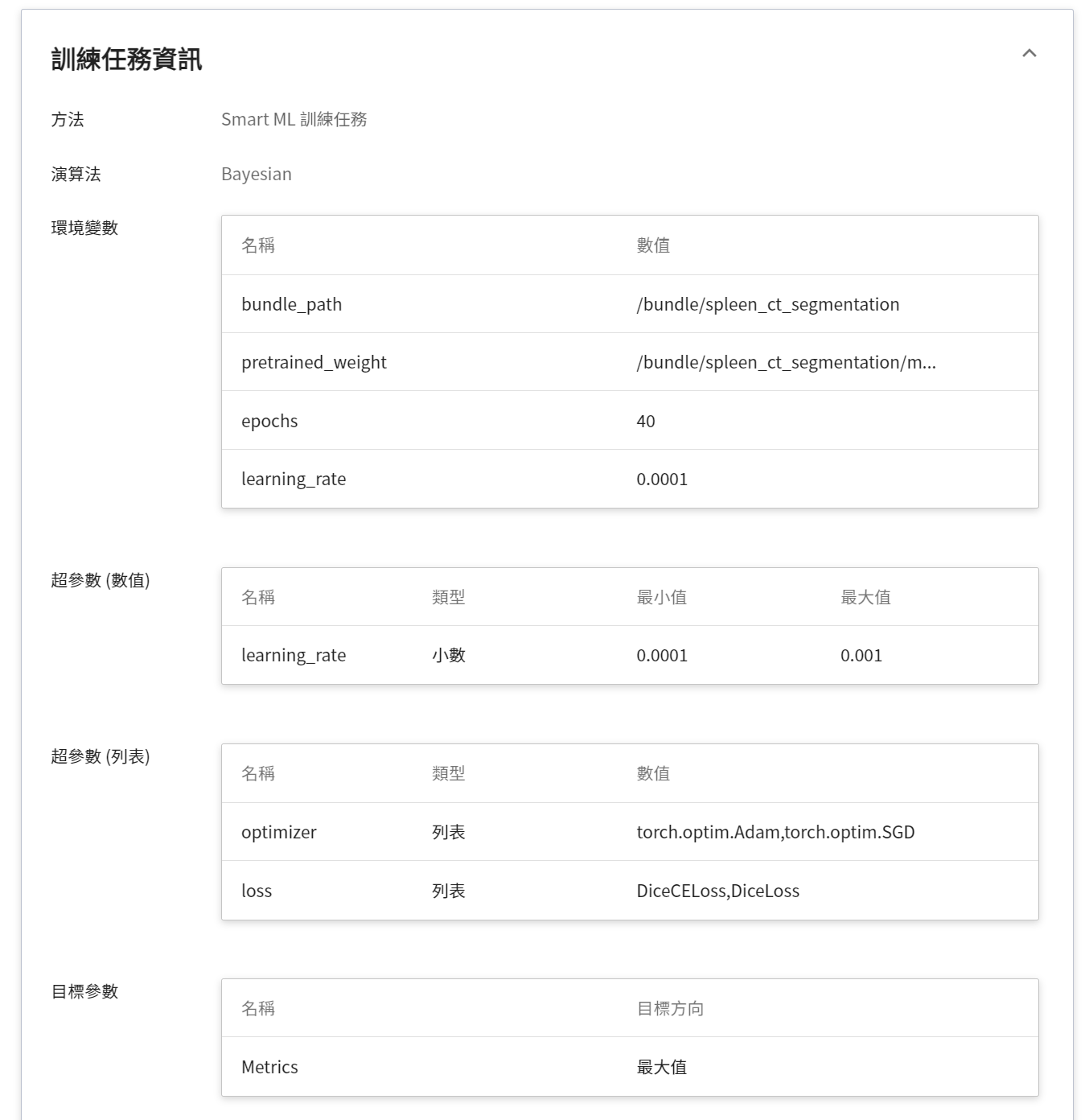
當然 **超參數** 中部份的訓練參數是可以移動至 **環境變數**;反之亦然。若您想固定該參數,則可將該參數從超參數區域中移除,新增至環境變數區域,並給定固定值;反之,若想將該參數加入嘗試,則將它從環境變數中移除,加入至下方的超參數區域。
:::info
:bulb: **提示:** 超參數的 optimizer 與 loss 實質上是透過列表的內容替代 train.json 的 optimizer#\_target_ 與 loss#\_target_,並未更換或刪除 optimizer 與 loss 其他參數,需要避免更換參數相差太多的元件以避免衝突。
ex. DiceCELoss 在 config 內指定了 squared_pred = true,若替換為 GeneralizedDiceLoss 則不支援此參數導致錯誤。可以選擇移除 squared_pred = true 或是替換成支援相同參數的 DiceLoss。
:::
### 2.2 啟動訓練任務
完成訓練任務的設定後,回到訓練任務管理頁面,可以看到剛剛建立的任務。
點擊該任務,可檢視訓練任務的詳細設定。在命令列中,有 6 個圖示,若此時任務的狀態顯示為 **`Ready`** ,即可點擊 **啟動** 執行訓練任務。
啟動後,點擊上方的「**運行列表**」頁籤,可以在列表中查看該任務的執行狀況與排程。在訓練進行中,可以點擊任務右方清單中的 **查看日誌** 或 **查看詳細狀態**,來得知目前任務執行的詳細資訊。
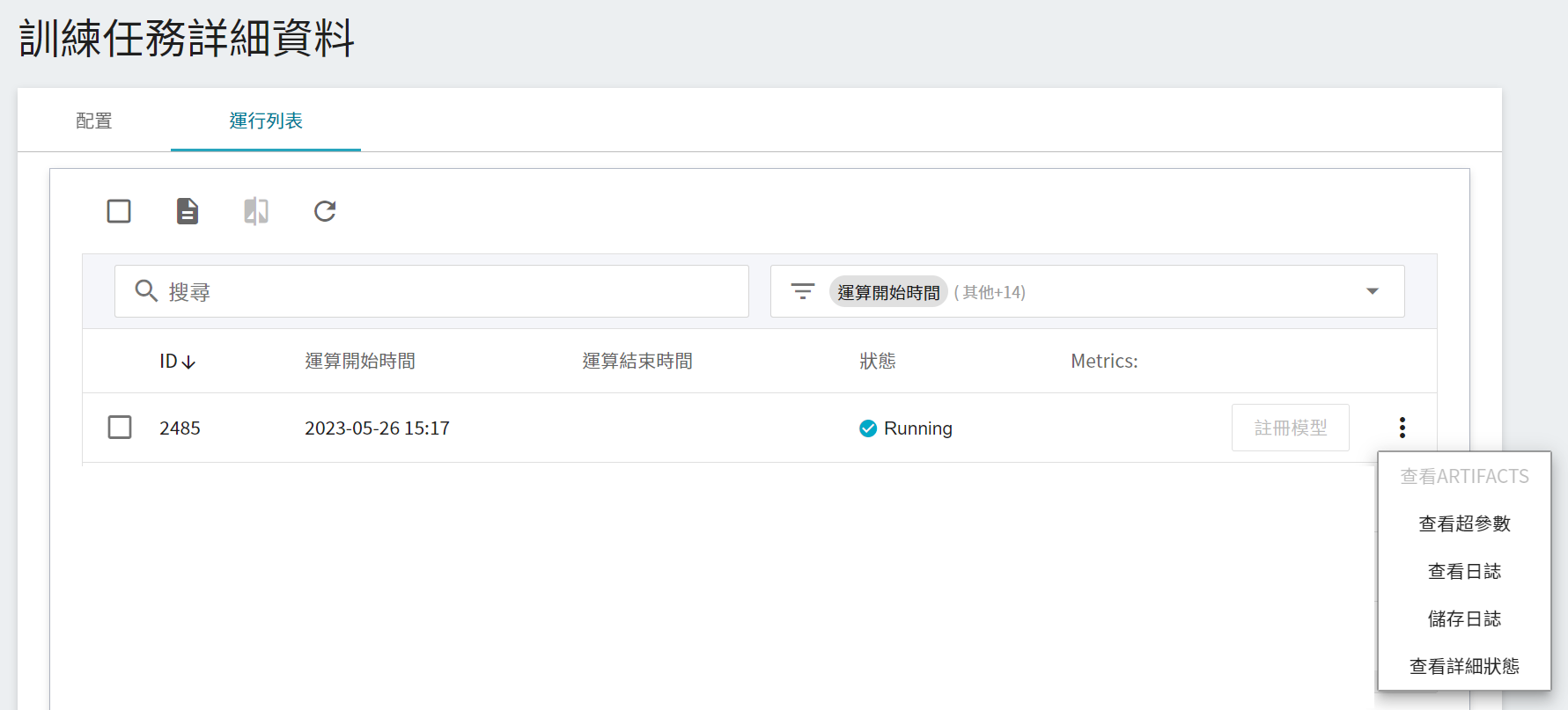
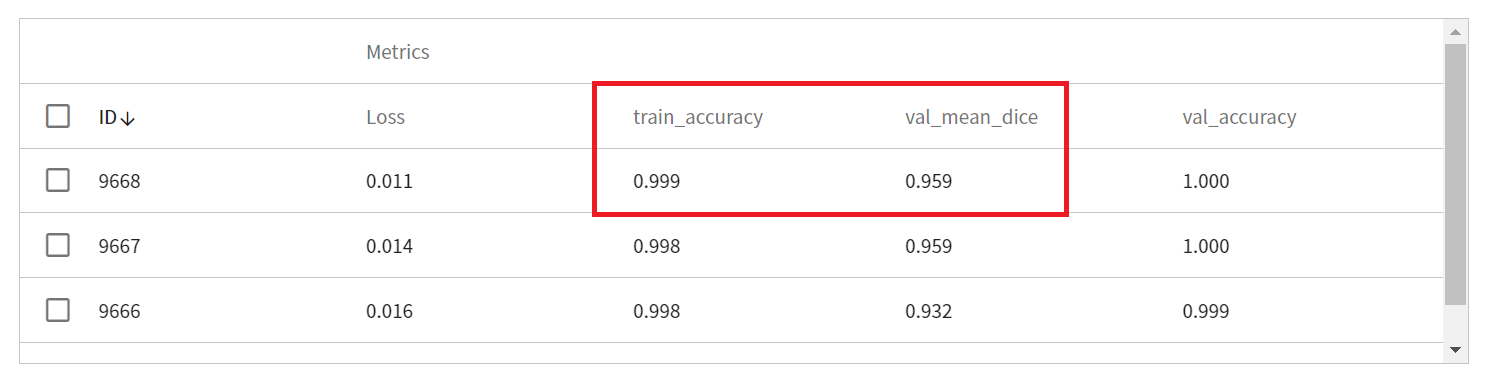
### 2.3 檢視訓練結果
當訓練完成後,可查看所有透過 MLflow 記錄的 Metrics 結果。Metrics 中分別紀錄了在訓練集的 Loss 與 Metrics(本範例為 train_accuracy)以及驗證集上的 Metrics(本範例為 val_mean_dice 與 val_accuracy)。在本範例中,優先選擇在驗證集表現較佳的結果,也就是 val_mean_dice 越高、val_accuracy 越高的結果。
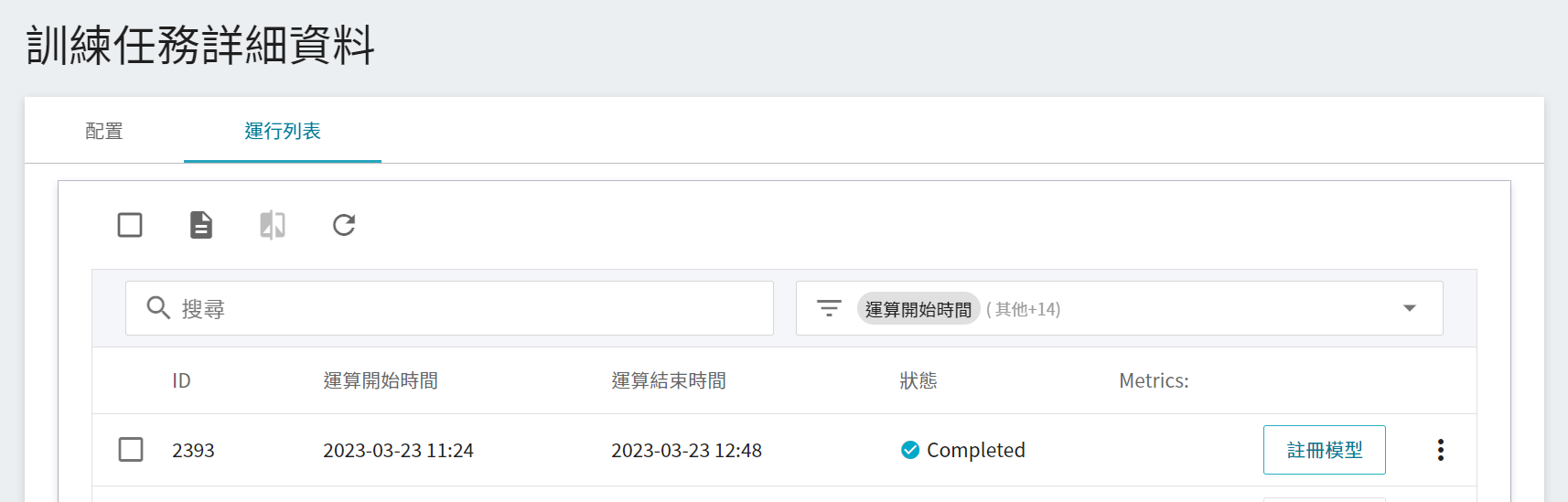
### 2.4 註冊模型
從一或多個結果中挑選出符合預期的運行列表,再點選右側「**註冊模型**」,將之儲存至模型庫中;若無符合預期結果,則重新調整環境變數與超參數的數值或數值範圍。
在註冊模型視窗中,點擊 **模型目錄** 右側選單可輸入欲建立的模型目錄名稱,例如:**`monai`** 或選擇既有的模型目錄。
註冊模型後,會進入模型版本管理頁面。在列表中可看到儲存模型的所有版本、描述、來源與結果等資訊。
## 3. 建立推論服務
當您完成分割技術模型的訓練後,我們可以部署 **推論功能** 以架設 MONAI Label Server。
### 3.1 建立推論
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**推論**」,進入推論管理頁面,並按下「**+建立**」,建立一個推論任務。
推論服務的建立步驟說明如下:
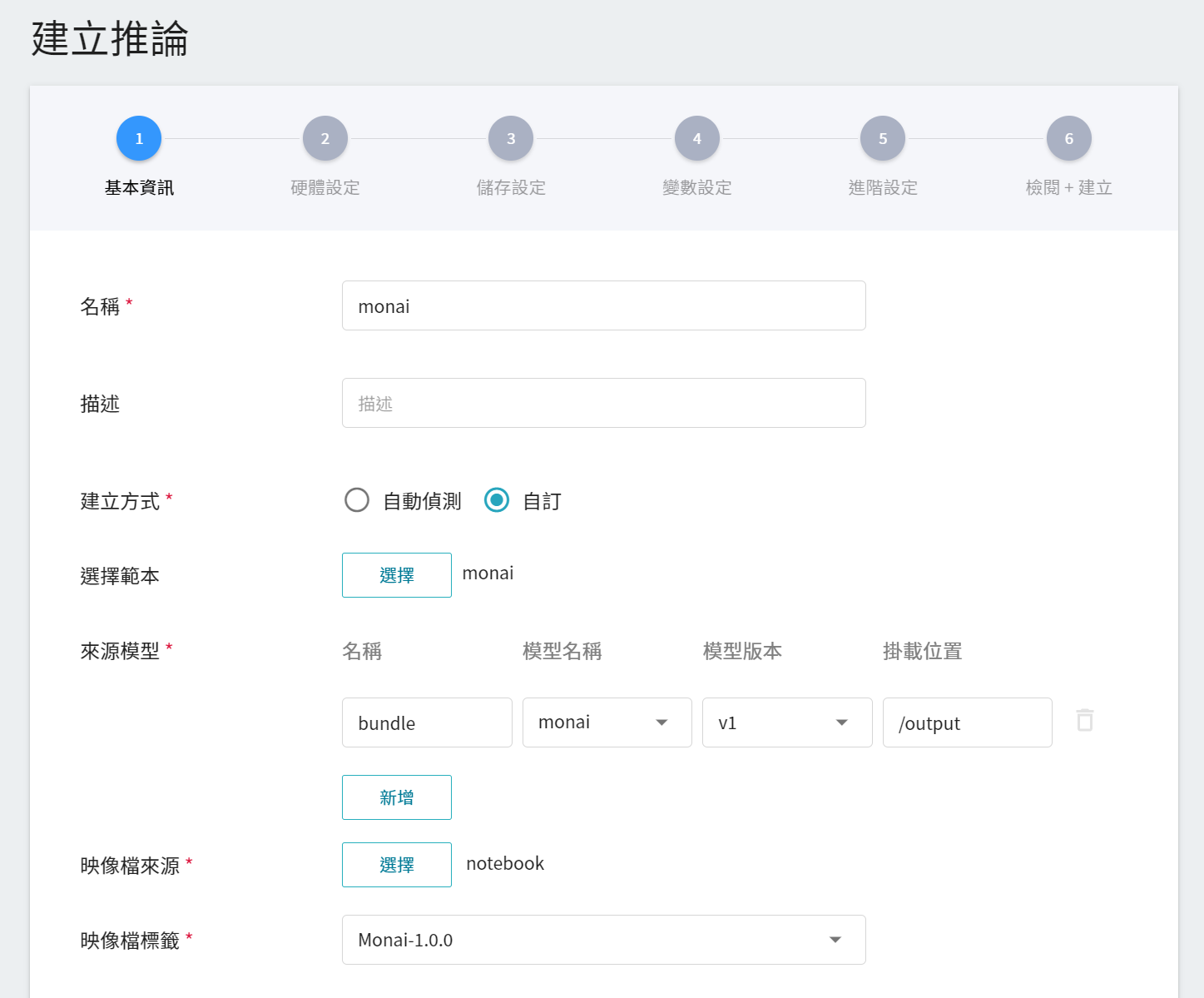
1. **基本資訊**
首先先將 **建立方式** 改成 **自訂**,與訓練任務的基本資訊的設定相似,我們也是使用 **`monai`** 的推論範本,方便開發者快速設定。但是,所要載入的模型名稱與版號仍須使用者手動設定:
- **模型名稱**
所要載入模型的名稱,即我們在 [**2.4 註冊模型**](#24-註冊模型) 中所儲存的模型。
- **版本**
所要載入模型的版號,亦是 [**2.4 註冊模型**](#24-註冊模型) 中所産生的版號。
- **掛載位置**
載入後模型所在位置,與程式進行中的讀取有關,這值會由 **`monai`** 推論範本設定。
2. **硬體設定**
參考目前的可用配額與訓練程式的需求,從列表中選出合適的硬體資源。
3. **儲存設定**
此步驟無須設定。
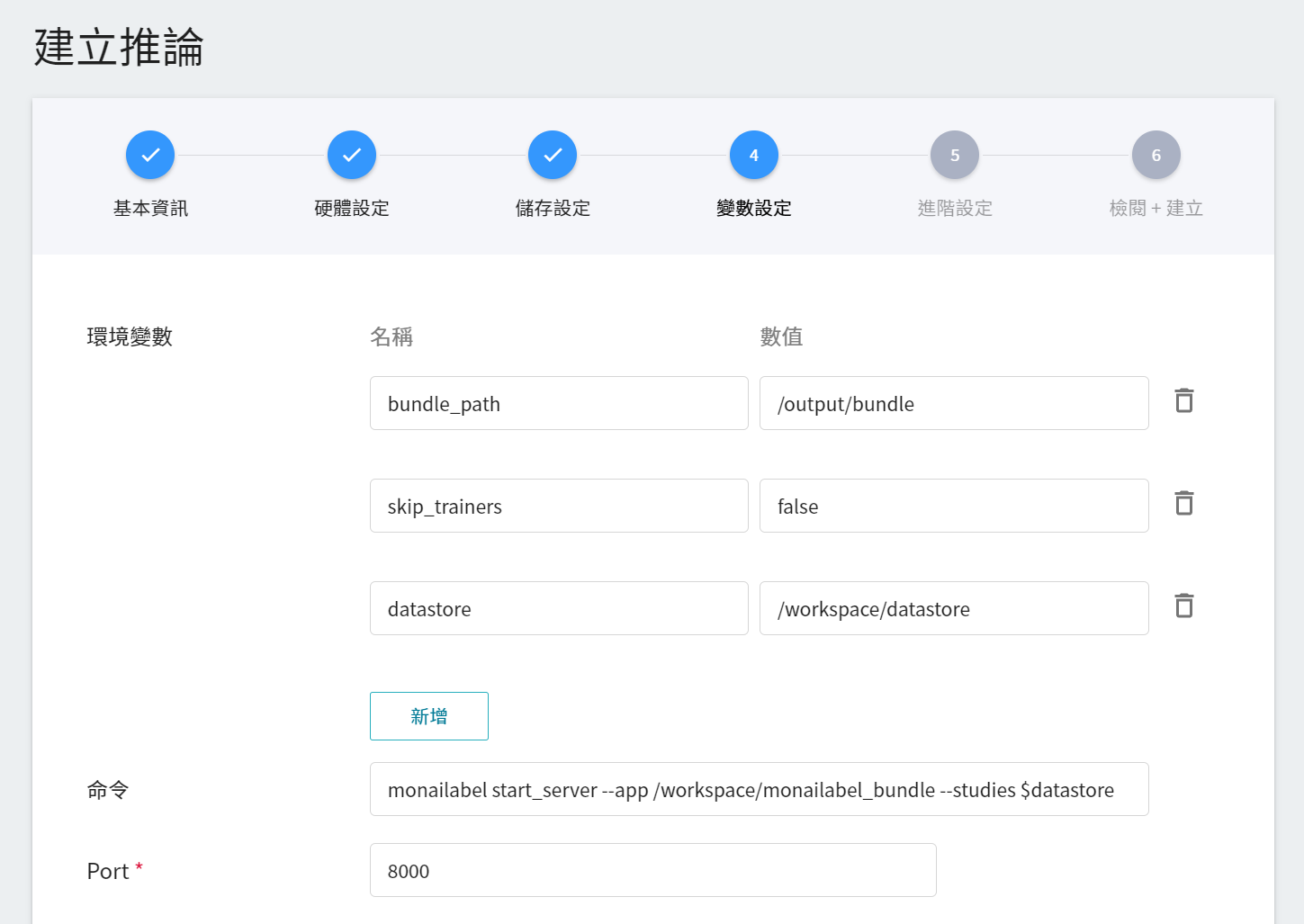
4. **變數設定**
在變數設定步驟,相關變數會由 **`monai`** 的範本自動帶入,可以根據需求修改。
| 變數 | 說明 |
| ---- | ---- |
| bundle_path | 指定 MONAI Label 讀取的 bundle 目錄,預設為訓練任務 model 儲存的位置,也可以指定外掛儲存空間的 bundle 目錄 |
| skip_trainers | 若為 true,則會停用 MONAI Label 的訓練模型功能 |
| datastore | 指定從 MONAI Label Client 上傳標註資料的位置 |
**`Port`** 請設定為 8000。
5. **進階設定**
此步驟無須設定。
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
:::info
:bulb:提示:這裡使用的 MONAI Label 取自 [**MONAI Label Sample Apps**](https://github.com/Project-MONAI/MONAILabel/tree/main/sample-apps/monaibundle) 並進行客製,想進一步了解參數設定可以參考官網文件。
:::
### 3.2 查詢推論資訊
建立完成推論任務後,返回推論管理頁面,點擊剛剛建立的任務,檢視該服務的詳細設定。當服務的狀態顯示為 **`Ready`** 時,即可以開始使用 MONAI Label Client 進行推論。不過在這些詳細資料中,有些資訊需請您留意,之後在使用 MONAI Label Client 時會用到這些資訊:
* **網路**
由於目前推論服務為了安全性的考量沒有開放對外的服務埠,但我們可以透過「**容器服務**」來跟我們的已經建立好的推論服務溝通,溝通的方式就是透過推論服務提供的「**網址**」,在下一章節會說明如何使用。
:::info
:bulb: **提示:** 文件中的網址僅供參考,您所取得的網址可能會與文件中的不同。
:::

<br>
## 4. MONAI Label Client - 3D Slicer
當您完成推論服務的啟動時,也就完成 MONAI Label Server 的啟動,如此一來就可以在本地端的 MONAI Label Client 進行相關工作。
這邊使用 [**3D Slicer**](https://www.slicer.org/) 作為操作範例,示範如何與推論服務進行串接。若您有 3D Slicer 的下載與安裝的疑問,請參考 [**3D Slicer 官網**](https://download.slicer.org/)。
### 4.1 **建立容器服務**
推論服務為了安全性的考量所以沒有開放對外的服務埠,所以我們需要透過容器服務跟建立好的推論服務溝通。
從 OneAI 服務列表點選 **容器服務** 進入容器服務管理頁面後,依下列步驟建立容器服務。
1. **基本資訊**
* 名稱:monai-proxy
* 描述:非必要,可自行輸入
* 映像檔來源:generic-nginx
* 映像檔標籤:v1
2. **硬體設定**
選擇硬體設定,在資源的選擇時,考慮到資源的使用狀況,可以不用配置 GPU。
3. **儲存設定**
此步驟無須設定。
4. **網路設定**
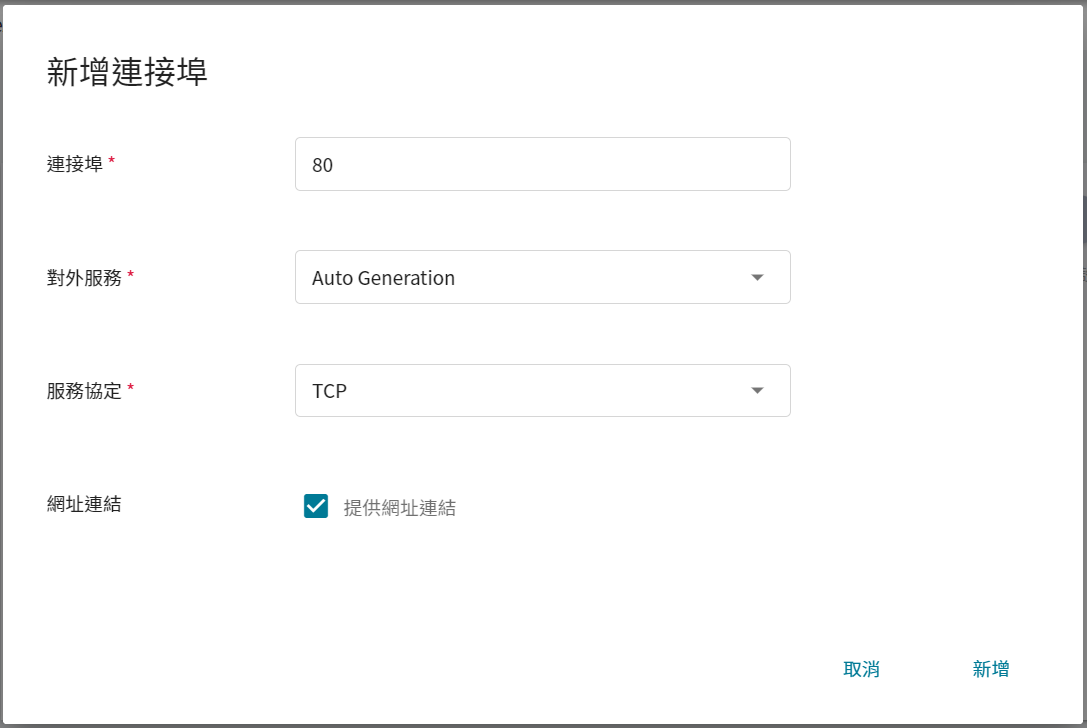
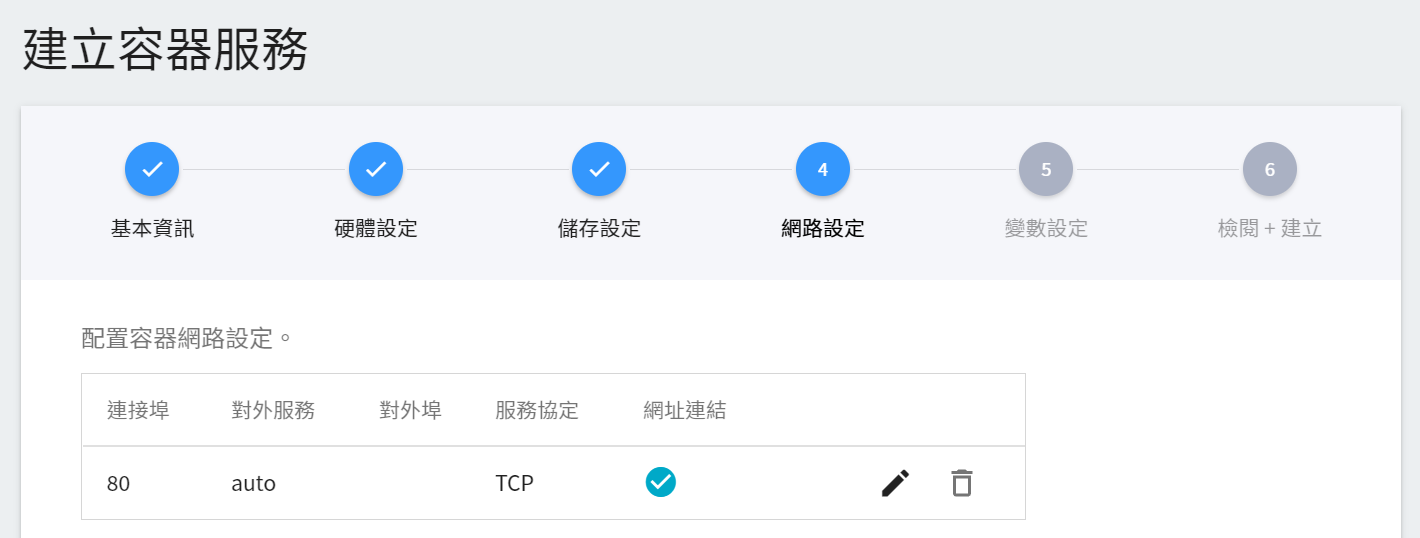
**連接埠** 請設定為 **80**,讓它自動產生對外的服務埠,並且勾選「**提供網址連結**」。
5. **變數設定**
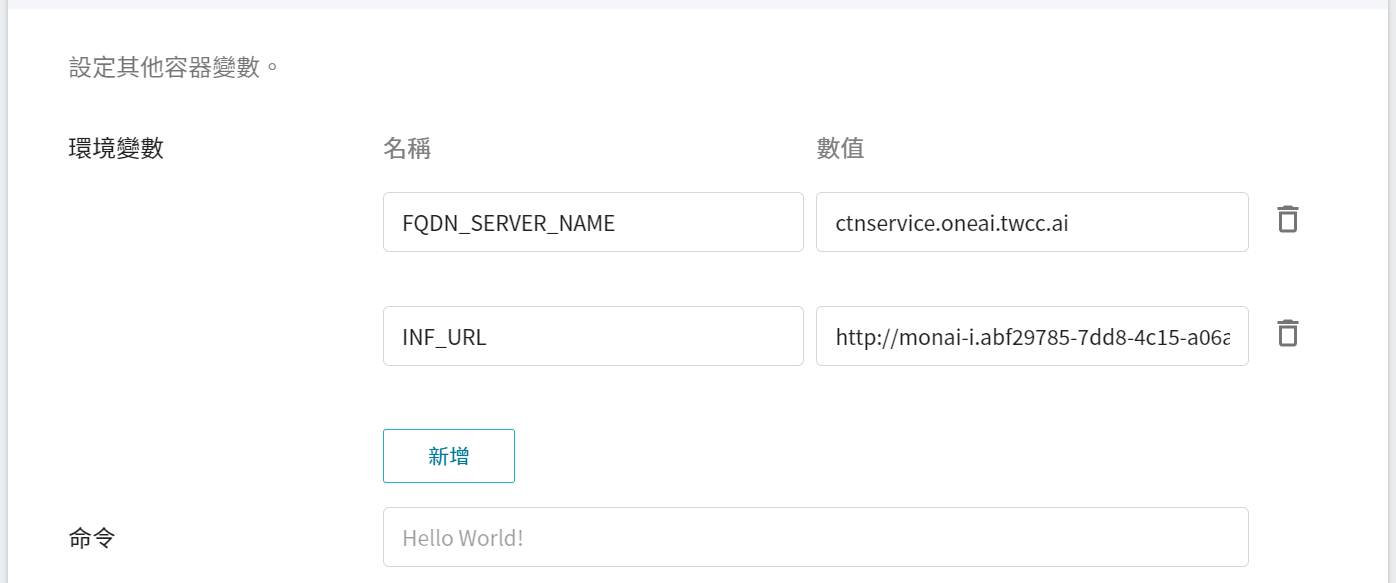
* **環境變數**:設定兩個環境變數。
* **FQDN_SERVER_NAME**: **`ctnservice.oneai.twcc.ai`**。
* **INF_URL**:輸入推論服務中所取得的網址。
* **命令**:此範例無需設定。
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
7. **查看對外服務**
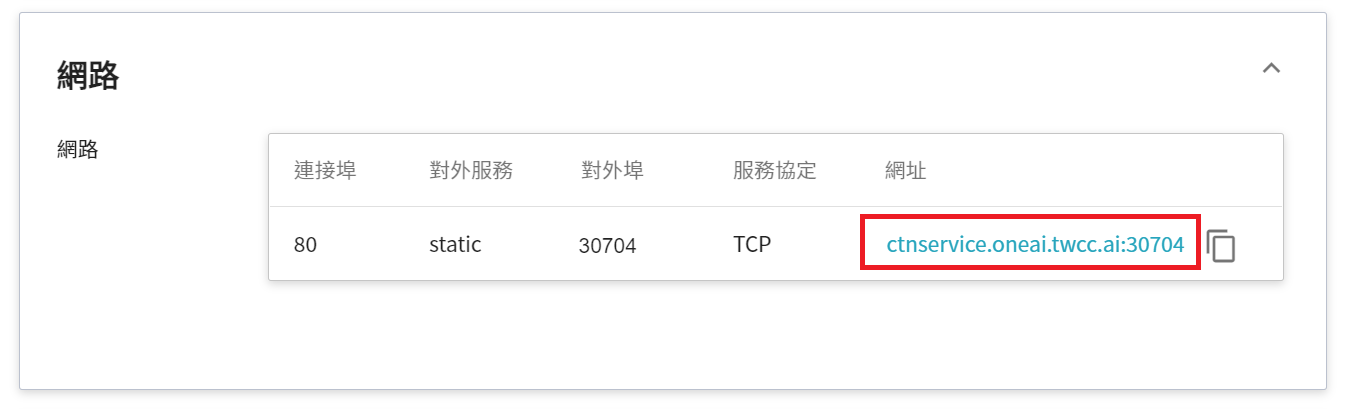
完成容器服務的建立後,回到容器服務管理列表頁面,點擊該服務可以取得詳細資訊。請注意下圖紅框中的網址,此為 **MONAI Label Server** 對外服務的網址,點擊此網址連結可在瀏覽器分頁中確認 MONAI Label Server 服務是否正常啟動;點擊右側的 **複製** 圖示可複製此網址連結,接下來會介紹如何 **使用 3D Slicer**。
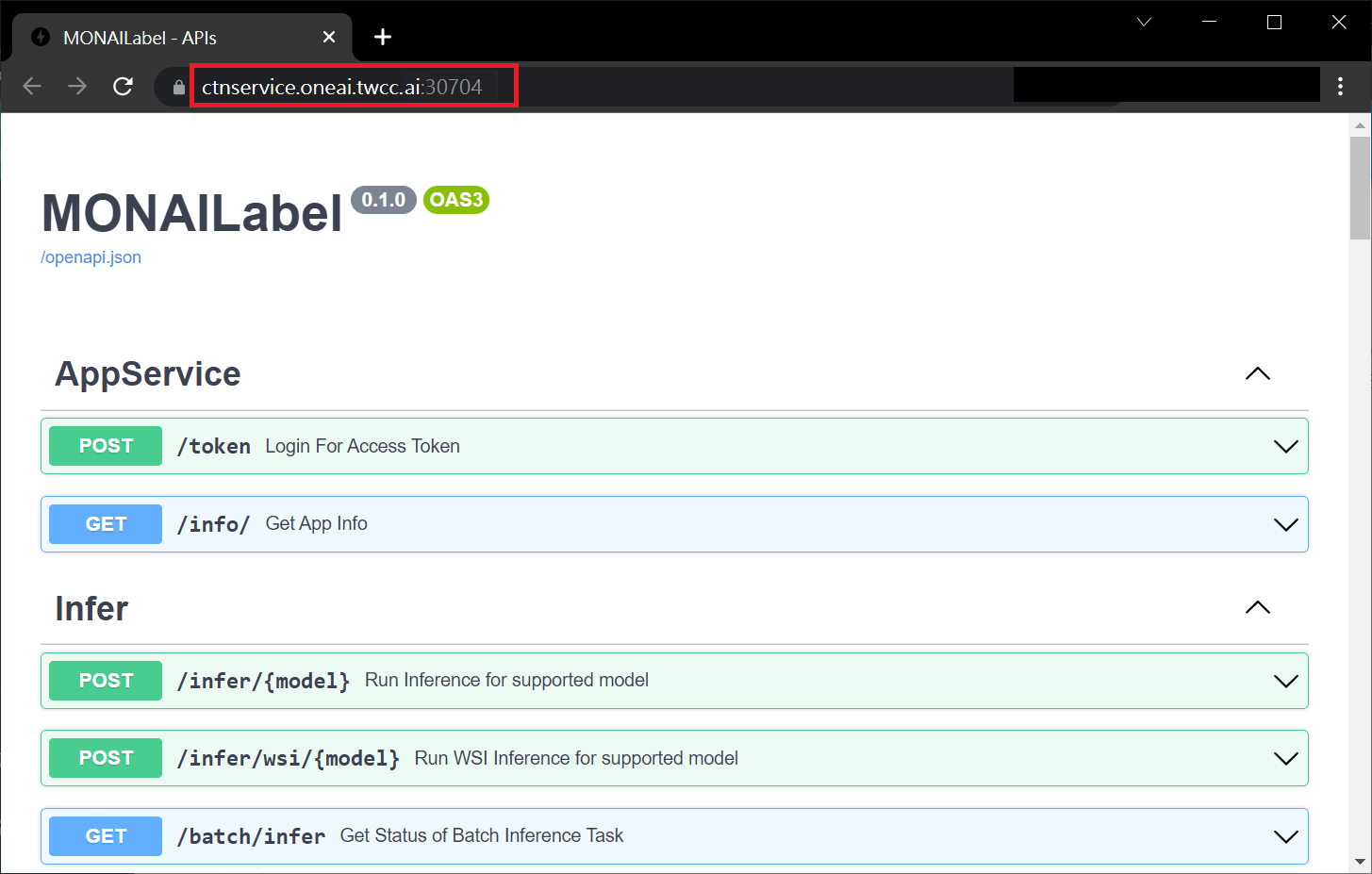
### 4.2 **使用 3D Slicer**
:::info
:bulb:**提示:** 以下 3D Slicer 設定畫面以 5.0.3 版本為例,若使用其他版本,請參照 [**3D Slicer 官網說明**](https://www.slicer.org/)。
:::
1. **安裝 MONAI Label Plug-in**
在開始前需要先安裝 MONAI Label Plug-in,才能進行後面步驟的操作。開啟 3D Slicer 後請先點選 **`View` > `Extension Manager`**。
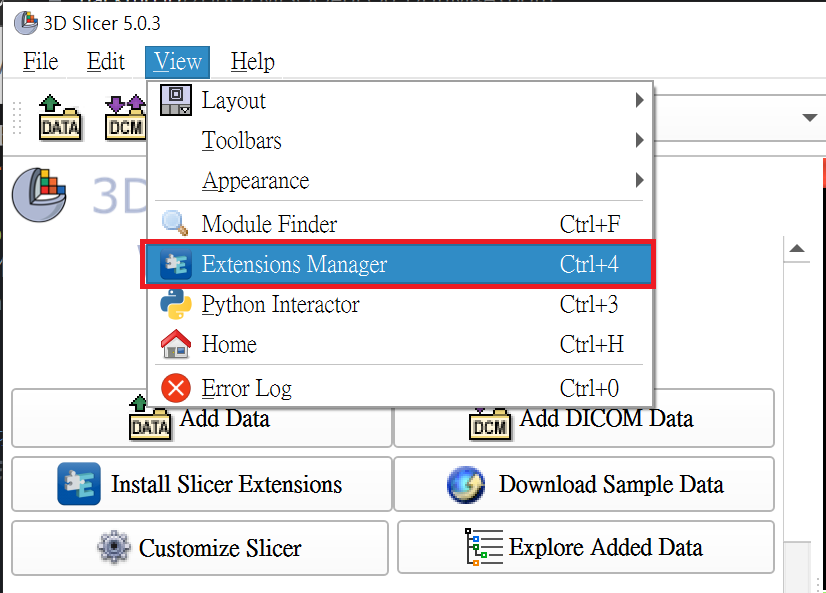
點擊 **`Install Extensions`** 並點選左側 **Active Learning** 分類,出現 **MONAI Label**,請點選 **INSTALL**,並重新開啟 3D Slicer。

2. **載入欲切割的資料**
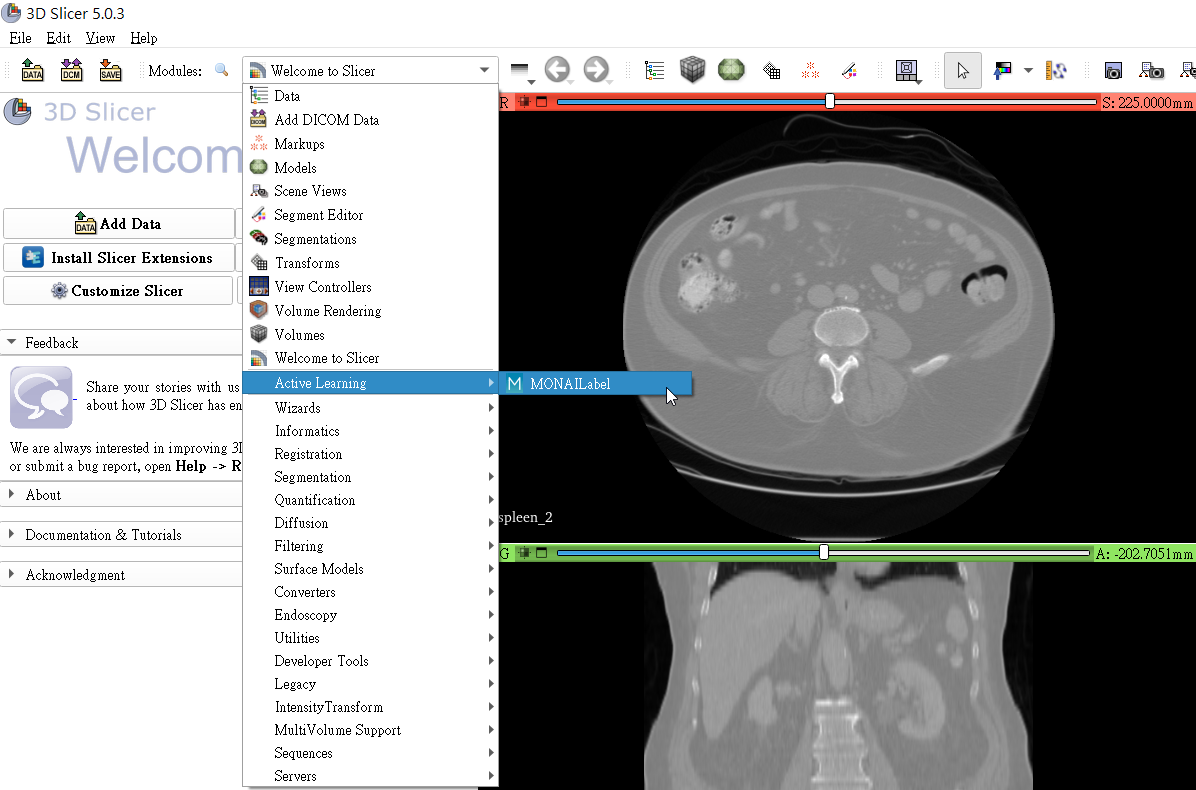
接下來點選 **`Add Data`**,載入我們要切割的脾臟資料。
並調出 **`Active Learning -> MONAILabel`**。
3. **連接推論服務**
在 **MONAI Label server** 欄位中需填入上一小節中複製的 **MONAI Label server** 網址,例如:**`https://ctnservice.oneai.twcc.ai:30704`**。若 MONAI Label server 服務設定正確,在 **Auto Segmentation** 的 **Model** 會顯示預設的 **AIMaker_Inference** 名稱,點擊右側的「**Run**」按鈕即可開始進行推論。
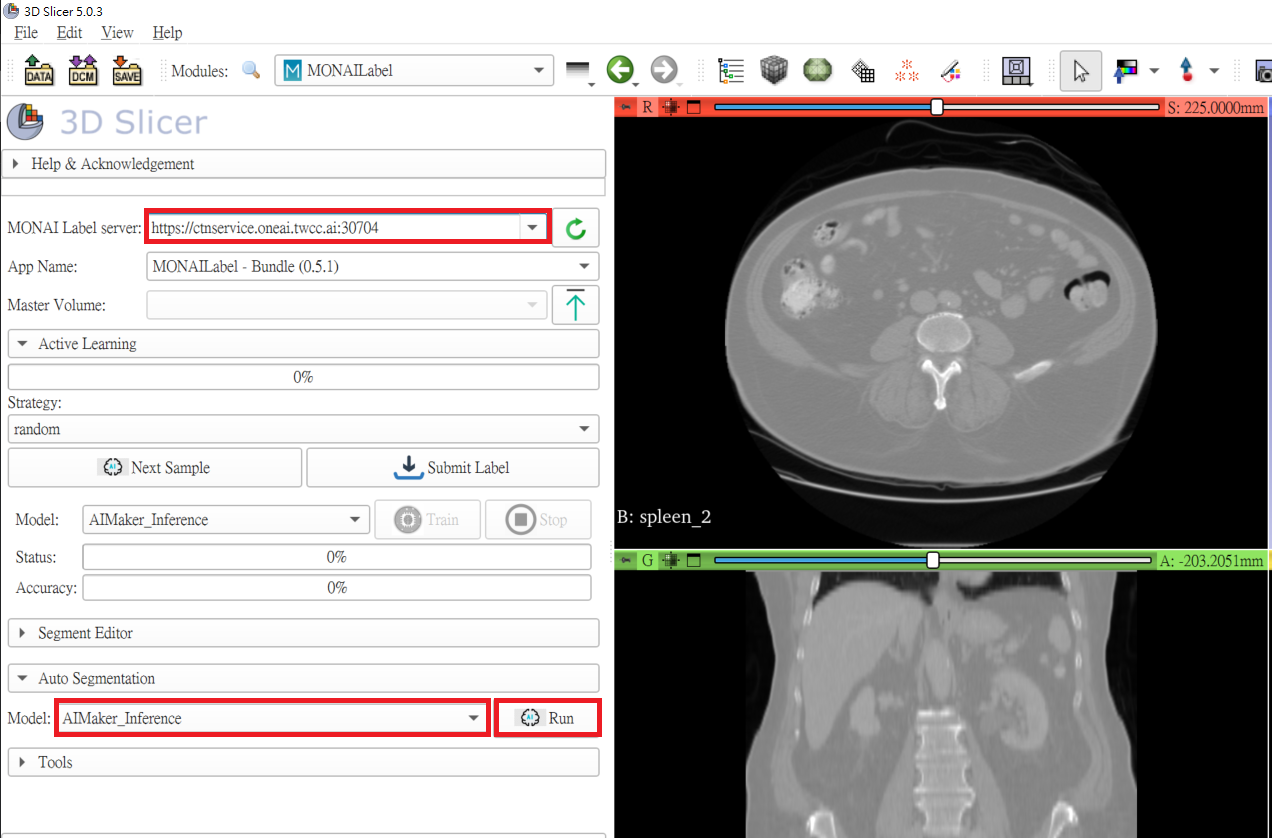
:::info
:bulb: **提示:** 文件中的網址僅供參考,您所取得的網址可能會與文件中的不同。
:::
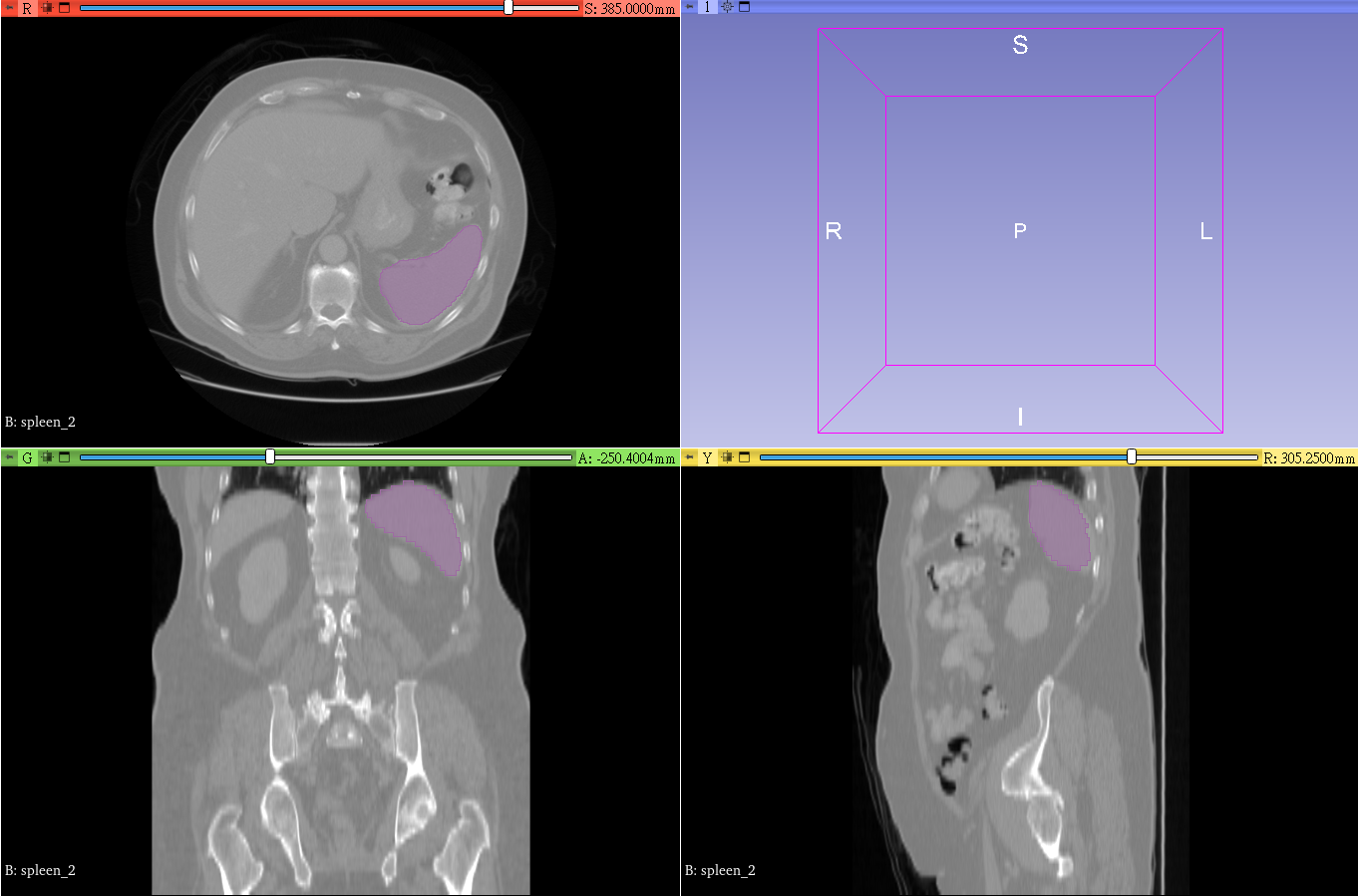
4. **標註輔助**
此時您會看到,CT 影像中多了紫色標註的區域,這些紫色區域即是您選擇的模型推論出來的脾臟位置結果。
# [補充] 推論應用範例 - MONAI Label Sample Apps
除了前述 **準備 MONAI Bundle 與資料集 > 訓練任務 > 儲存模型 > 推論服務** 的流程,也可以選擇直接上傳內含模型檔的 MONAI Bundle 到 OneAI 的儲存服務,並應用在推論服務與對應領域的 MONAI Label Client。
在此範例中,我們將介紹如何使用 Model Zoo 提供的 MONAI Bundle 建立模型與推論服務。若對 MONAI Bundle 與 MONAI Label 還不熟悉的,可以參考本範例教學一開始的 [**基礎概念**](#基礎概念)。
## Radiology: 3D Slicer + DeepEdit 互動式標註
### 1. 建立模型
1. **下載預訓練模型**
請下載 MONAI 提供的 [**Spleen deepedit annotation**](https://github.com/Project-MONAI/model-zoo/releases/download/hosting_storage_v1/spleen_deepedit_annotation_v0.3.0.zip),此為從 CT 圖像中對脾臟器官進行 3D 分割的預訓練模型,下載後解壓縮至本機上的**spleen_deepedit_annotation_v0.3.0**資料夾待用。
:::info
:bulb: **提示:** 更多關於 **Spleen deepedit annotation** 的資訊請參考 [**MONAI > model zoo > models > Spleen deepedit annotation**](https://github.com/Project-MONAI/model-zoo/tree/dev/models/spleen_deepedit_annotation) 網站。
:::
:::warning
:warning: **注意:** 在目前的運作環境 **MONAI 1.0 + MONAI Label 0.5.1** 以 ITK 讀入資料有 [相容性問題](https://github.com/Project-MONAI/MONAILabel/issues/1064),MONAI 官方下一個版本已修正。
使用此版本需要手動先將 configs/inference.json 內的 "reader": "ITKReader" 設定移除,程式會自動使用 NibabelReader 來讀取本範例使用的 NIfTI 檔案,此變動不影響推論效能與結果。

:::
2. **建立儲存體**
從 OneAI 服務列表選擇「**儲存服務**」,進入儲存服務管理頁面,接著點擊「**+建立**」,新增一個名為 `monai-bundle` 的儲存體,以用來存放我們的 MONAI Bundle。
3. **檢視儲存體**
完成儲存體的建立後,回到儲存服務管理頁面,此時會看到剛剛新增的儲存體。
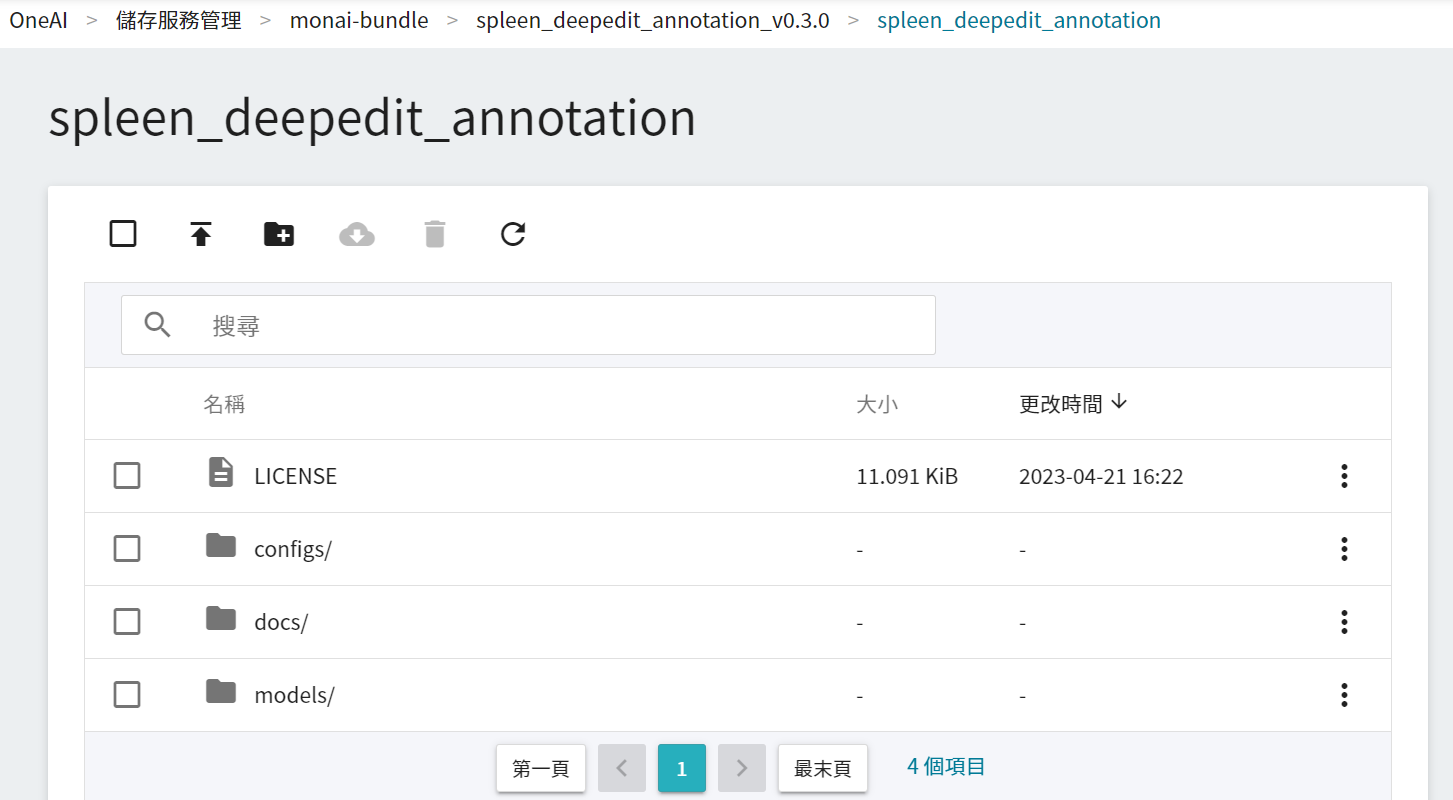
4. **上傳 MONAI Bundle**
點擊建立好的儲存體,然後點選「**上傳**」就可以開始上傳檔案,將之前解壓縮的資料夾 **spleen_deepedit_annotation_v0.3.0** 上傳,完成後的目錄結構應該如附圖所示。(請參考 [**儲存服務說明**](/s/storage))。
5. **新增模型目錄**
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**模型**」,在模型管理頁面點選新增目錄,建立模型目錄 `monai-bundle` 。
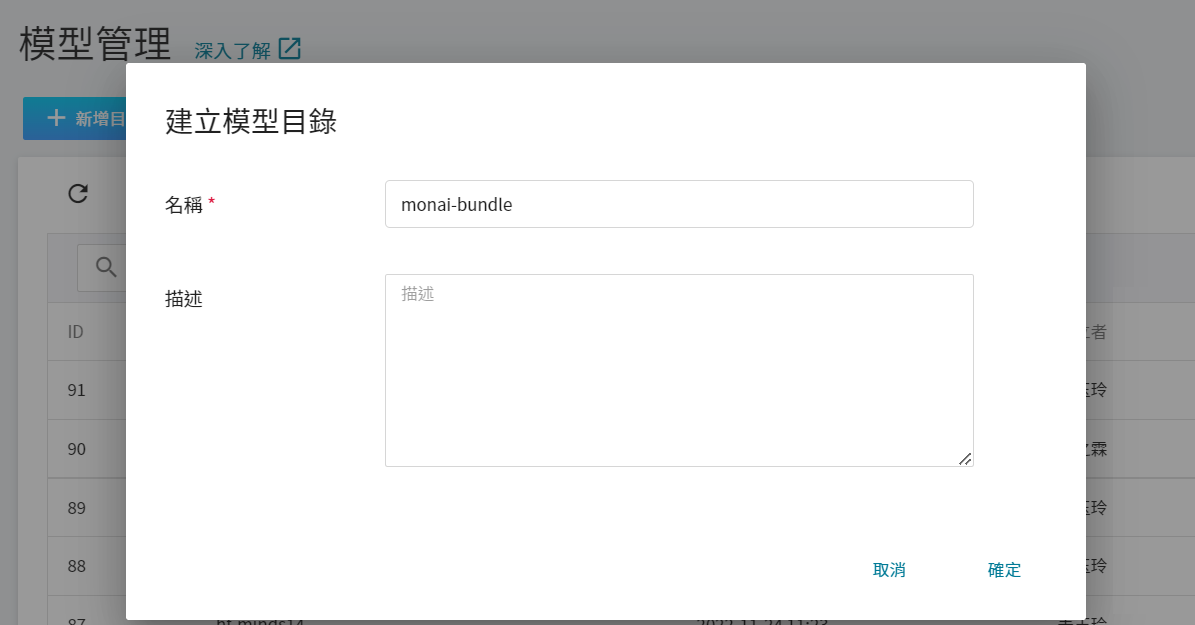
6. **匯入模型**
點擊進入建立好的模型目錄,接著點擊上方的 **匯入** 圖示,匯入剛下載的模型。

完成「**匯入模型**」的設定後點擊「**確定**」。
* 模型名稱:此欄位會自動帶入。
* 儲存:選擇模型存放的儲存體,例如:monai-bundle。
* 儲存子路徑:選擇模型存放的儲存體中的子路徑,非必填,本範例為spleen_deepedit_annotation_v0.3.0。
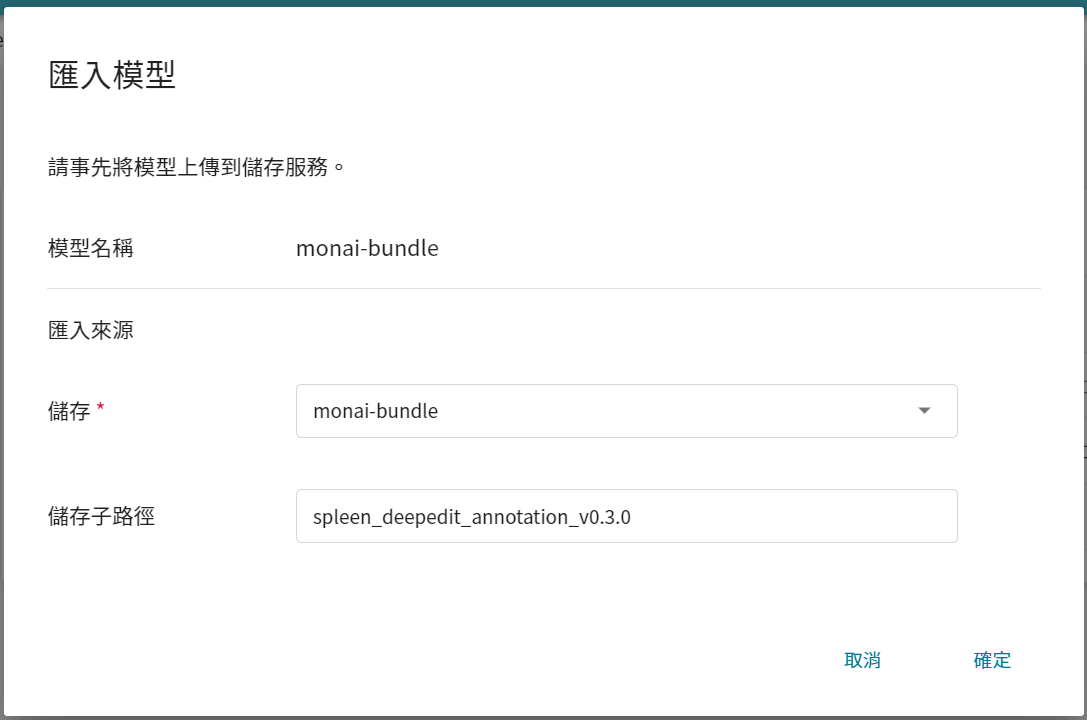
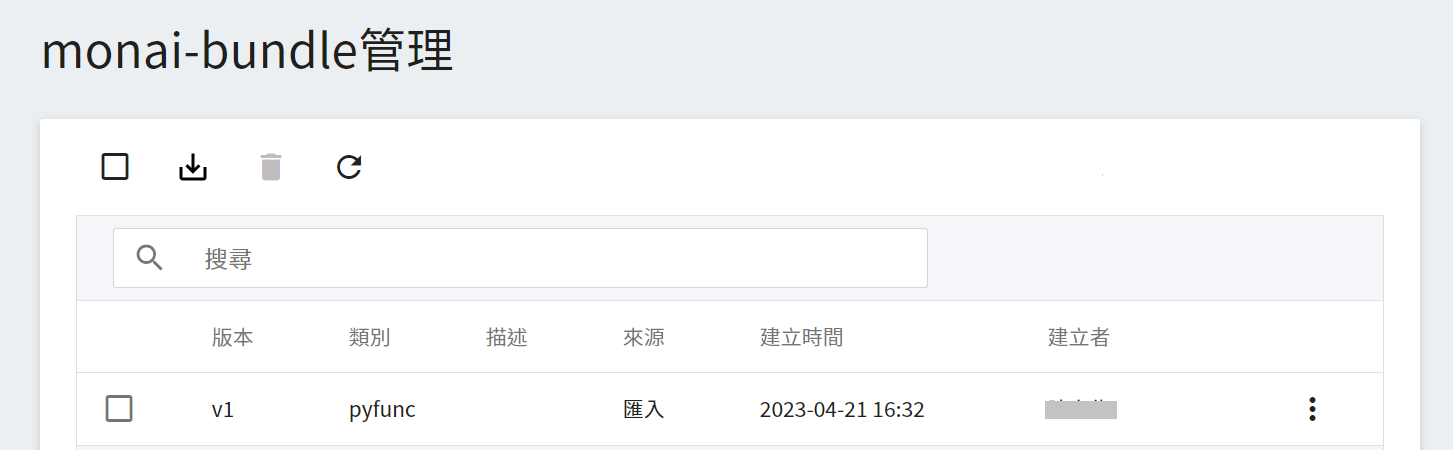
匯入模型可能需要一些時間,可點擊上方的 **重新整理** 圖示,匯入成功後將出現在模型版本列表中,來源顯示為 `滙入` 。
### 2. 建立推論服務
從 OneAI 服務列表選擇「**AI Maker**」,再點擊「**推論**」,進入推論管理頁面,並按下「**+建立**」,建立一個推論任務。
推論服務的建立步驟說明如下:
1. **基本資訊**
與訓練任務的基本資訊的設定相似,我們也是使用 **`monai`** 的推論範本,方便開發者快速設定。但是,所要載入的模型名稱與版號仍須使用者手動設定:
- **模型名稱**
所要載入的模型名稱,即我們在 [**1.1 建立模型**](#11-建立模型) 中所匯入的模型。
- **版本**
所要載入模型的版號,亦是 [**1.1 建立模型**](#11-建立模型) 中所設定的版號。
- **掛載位置**
載入後模型所在位置,與程式進行中的讀取有關,這值會由 **`monai`** 推論範本設定。
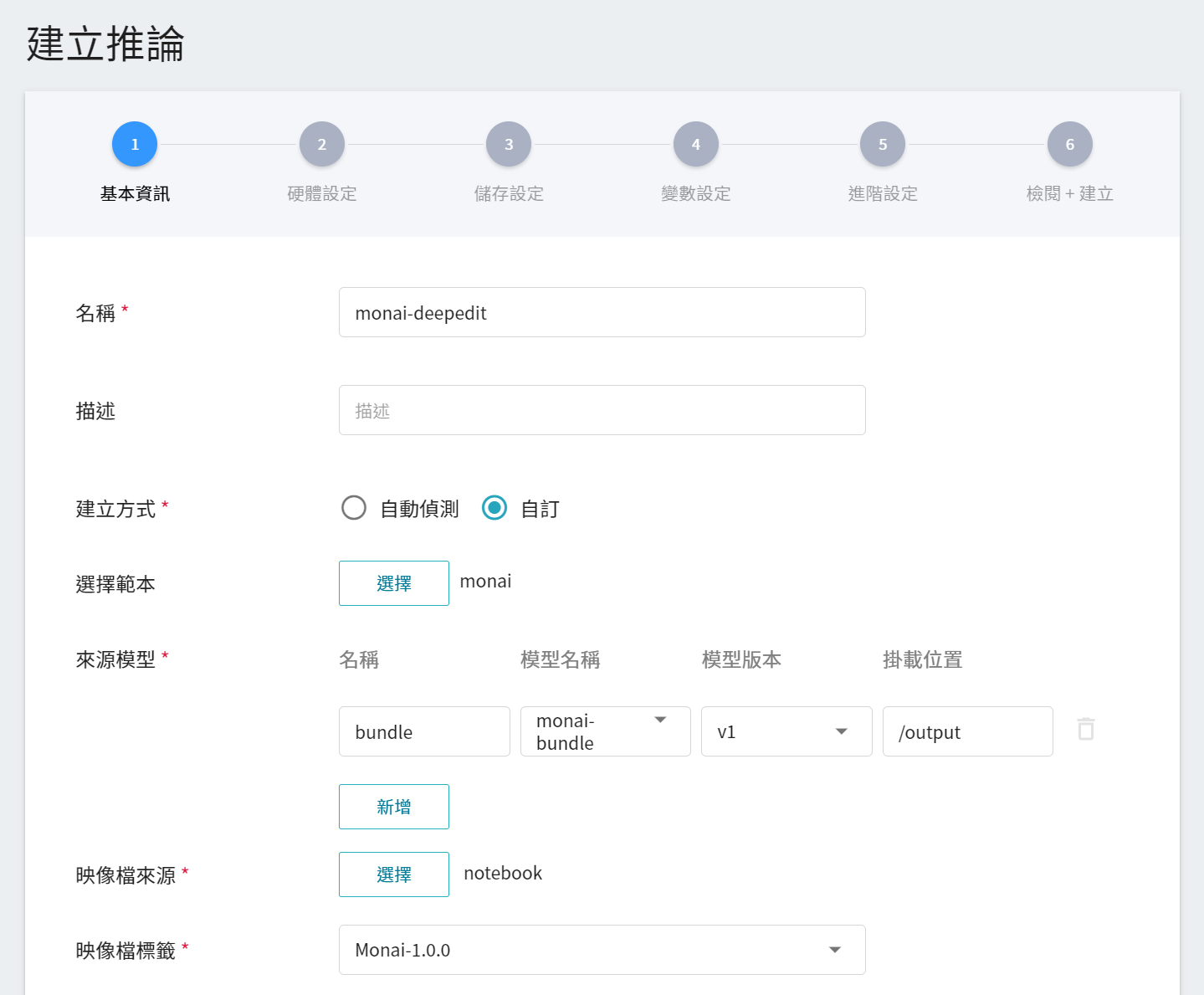
2. **硬體設定**
參考目前的可用配額與訓練程式的需求,從列表中選出合適的硬體資源。
3. **儲存設定**
此步驟無須設定。
4. **變數設定**
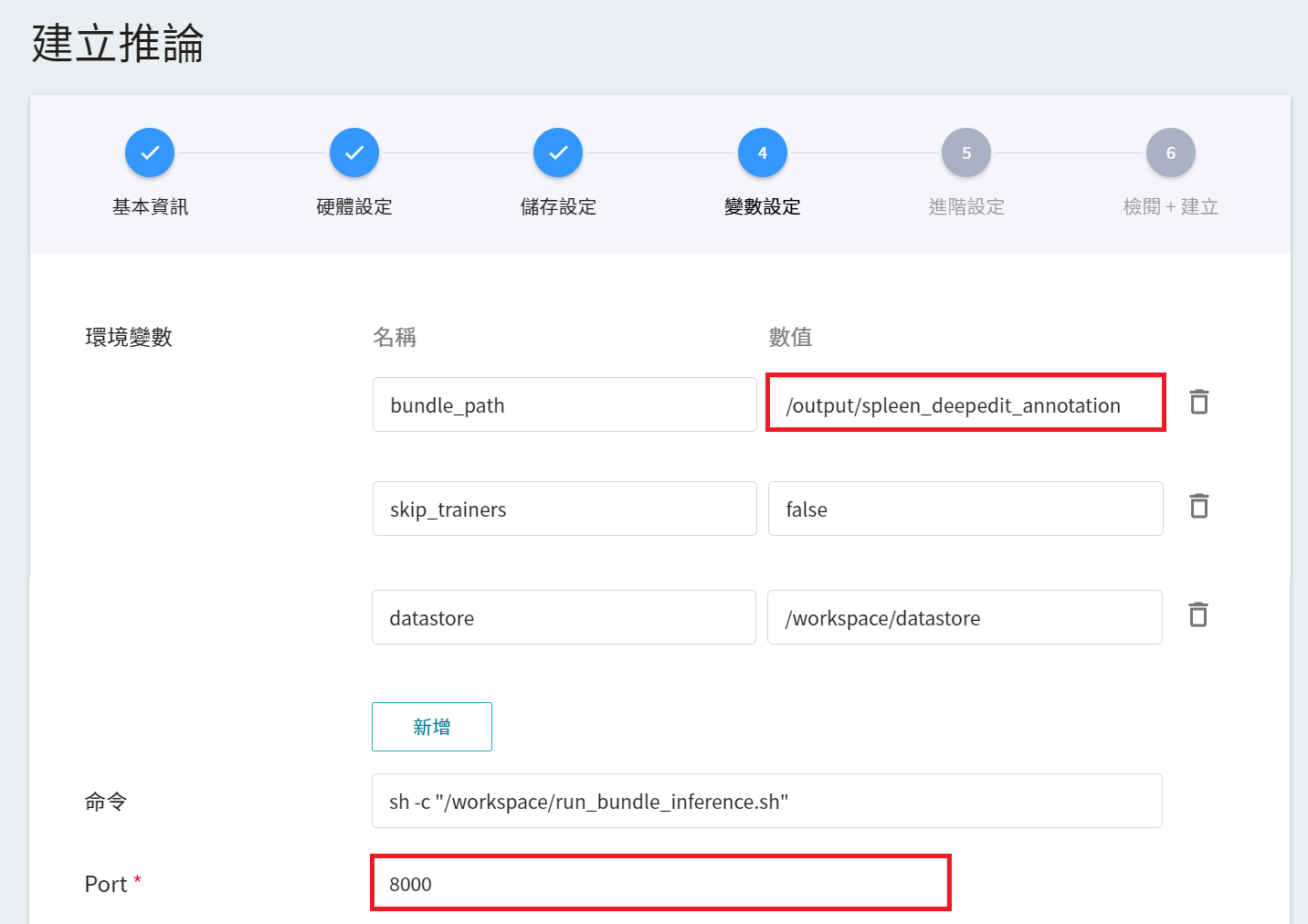
在變數設定步驟,相關變數會由 **`monai`** 的範本自動帶入,可以根據需求修改,由於此範例使用的 MONAI Bundle 壓縮檔內部目錄名稱為 **spleen_deepedit_annotation**,這裡需手動將 **`bundle_path`** 改成 **`/output/spleen_deepedit_annotation`**。
| 變數 | 說明 |
| ---- | ---- |
| bundle_path| 指定 MONAI Label 讀取的 bundle 目錄,預設為訓練任務 model 儲存的位置,也可以指定外掛儲存空間的 bundle 目錄 |
| skip_trainers | 若為 true,則會停用 MONAI Label 的訓練模型功能 |
| datastore | 指定從 MONAI Label Client 上傳標註資料的位置 |
**`Port`** 請設定為 8000。
5. **進階設定**
此步驟無須設定。
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
:::info
:bulb:提示:這裡使用的 MONAI Label 取自 [**MONAI Label Sample Apps**](https://github.com/Project-MONAI/MONAILabel/tree/main/sample-apps/monaibundle) 並進行客製,對參數設定想進一步了解可以參考官網文件。
:::
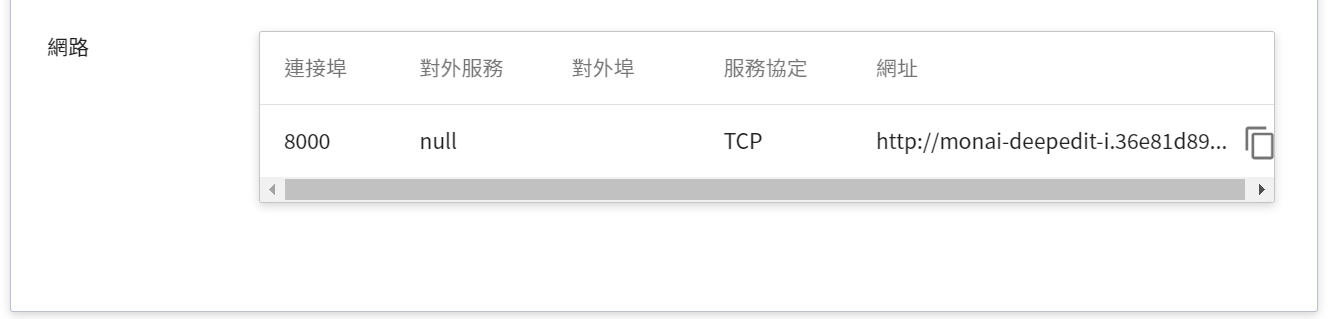
推論任務建立完成後,返回推論管理頁面,點擊剛剛建立的任務,檢視該服務的詳細設定。當服務的狀態顯示為 **`Ready`** 時,即可以開始使用 MONAI Label Client 進行推論。不過在這些詳細資料中,有些資訊需請您留意,之後在使用 MONAI Label Client 時會用到這些資訊:
* **網路**
由於目前推論服務為了安全性的考量沒有開放對外的服務埠,但我們可以透過「**容器服務**」來跟我們的已經建立好的推論服務溝通,溝通的方式就是透過推論服務提供的「**網址**」,在下一章節會說明如何使用。
:::info
:bulb: **提示:** 文件中的網址僅供參考,您所取得的網址可能會與文件中的不同。
:::
### 3. 建立容器服務
從 OneAI 服務列表點選 **容器服務** 進入容器服務管理頁面後,依下列步驟建立容器服務。
1. **基本資訊**
* 名稱:monai-deepedit
* 描述:非必要,可自行輸入
* 映像檔來源:generic-nginx
* 映像檔標籤:v1
2. **硬體設定**
選擇硬體設定,在資源的選擇時,考慮到資源的使用狀況,可以不用配置 GPU。
3. **儲存設定**
此步驟無須設定。
4. **網路設定**
「**容器連接埠**」請設定為 **80**,讓它自動產生對外的服務埠,並且勾選「**提供網址連結**」。


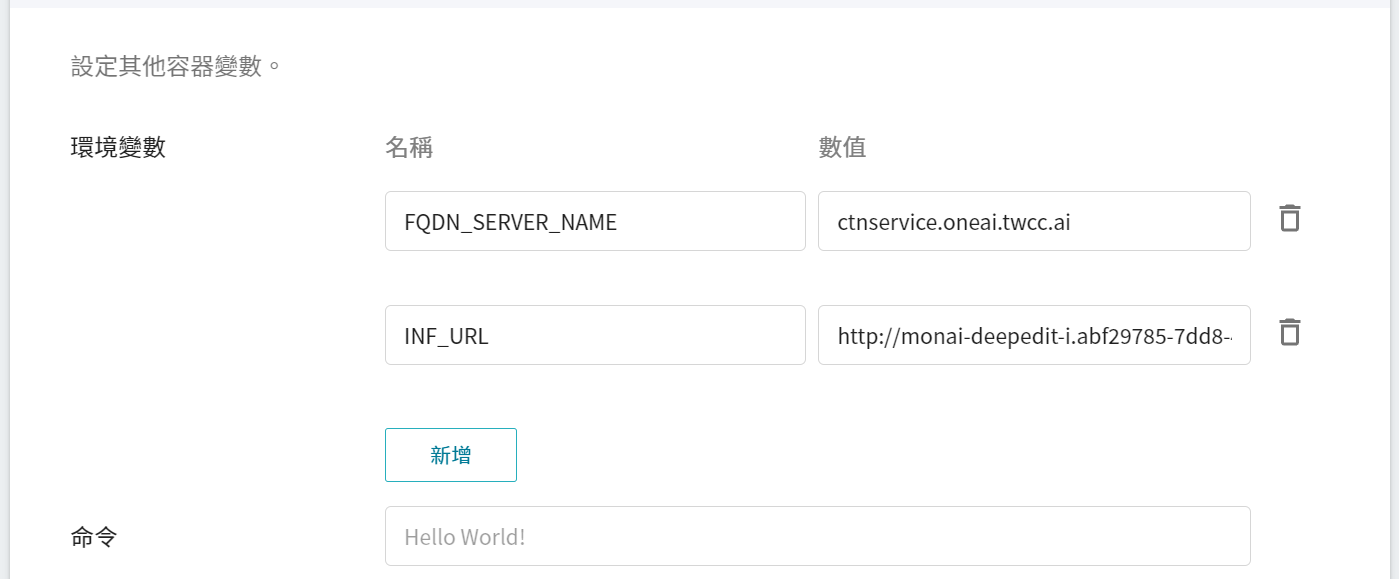
5. **變數設定**
* **環境變數**:設定兩個環境變數。
* **FQDN_SERVER_NAME**: **`ctnservice.oneai.twcc.ai`**。
* **INF_URL**:輸入推論服務中所取得的網址。
* **命令**:此範例無需設定。
6. **檢閱 + 建立**
最後,確認填寫的資訊,就可按下建立。
7. **查看對外服務**
完成容器服務的建立後,回到容器服務管理列表頁面,點擊該服務可以取得詳細資訊。請注意下圖紅框中的網址,此為 **MONAI Label Server** 對外服務的網址,點擊此網址連結可在瀏覽器分頁中確認 MONAI Label Server 服務是否正常啟動;點擊右側的 **複製** 圖示可複製此網址連結,接下來會介紹如何 **使用 3D Slicer**。


### 4. 使用 3D Slicer
:::info
:bulb:**提示:** 以下 3D Slicer 設定畫面以 5.0.3 版本為例,若使用其他版本,請參照 [**3D Slicer 官網說明**](https://www.slicer.org/)。
:::
1. **安裝 MONAI Label Plug-in**
在開始前需要先安裝 MONAI Label Plug-in,才能進行後面步驟的操作。開啟 3D Slicer 後請先點選 **`View` > `Extension Manager`**。

點擊 **`Install Extensions`** 並點選左側 Active Learning 分類,出現 MONAILabel,請點選安裝,並重新開啟 3D Slicer。

2. **載入欲切割的資料**
接下來點選 **`Add Data`**,載入我們要切割的脾臟資料。

並調出 **`Active Learning -> MONAILabel`**。

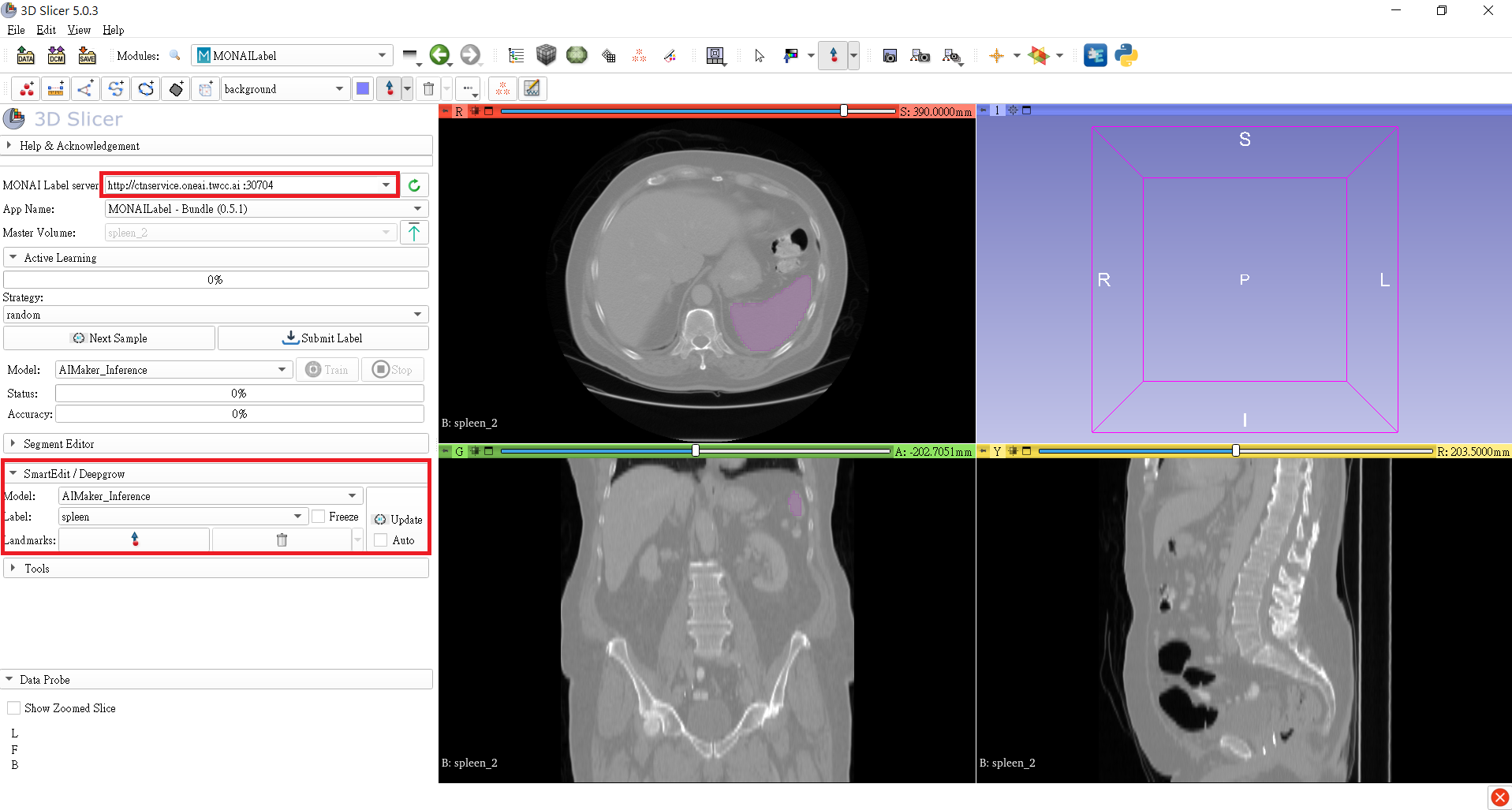
3. **連接推論服務**
在 **MONAI Label server** 欄位中需填入上一小節中複製的 **MONAI Label server** 網址,例如:**`http://ctnservice.oneai.twcc.ai:30704`**。若 MONAI Label server 服務設定正確,在 **SmartEdit / Deepgrow** 的 **Model** 會顯示預設的 **AIMaker_Inference** 名稱,點擊右側的「**Update**」按鈕即可開始進行推論,也可以選擇放置輔助點再進行推論。
:::info
:bulb: **提示:** 文件中的網址僅供參考,您所取得的網址可能會與文件中的不同。
:::
4. **標註輔助**
此時您會看到,CT 影像中多了紫色標註的區域,這些紫色區域即是您選擇的模型推論出來的脾臟位置結果。
