---
description: OneAI Documentation
tags: Case Study, EN
---
[OneAI Documentation](/s/user-guide-en)
# AI Maker Case Study - Machine Learning with Tabular Data: Classification
[TOC]
## 0. Introduction
In supervised learning, when the predicted target value is non-continuous (ie discrete), it is called **Classification**; if the target value is continuous, it is called **Regression**.
| Classification | Regression |
| :------------------: | :--------------: |
| 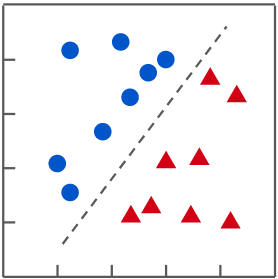 | 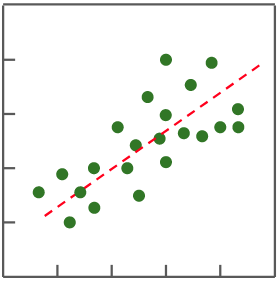 |
| In a classification problem, find a function that separates different categories of data | In a regression problem, find a function that fits the distribution of data |
In this example, we will use "tabular data" for classification and explanation, and gradually build the machine learning application with tabular data from scratch. The steps are as follows:
1. [**Prepare the Dataset**](#1-Prepare-Dataset-and-Upload)
At this stage, we will download the dataset from Kaggle and upload it to the designated location. Currently, Kaggle is the largest data science competition platform.
2. [**Train the Model**](#2-Training-Classification-Model)
At this stage, we will configure the relevant training job and use specified algorithms to train and fit the model, and store the trained model for inference service.
3. [**Create Inference Service**](#3-Create-Inference-Service)
At this stage, we will deploy the stored model and create a web service for the model to perform inference.
4. [**[Advanced Operations] Adjust the Parameters of Algorithm**](#4-Advanced-Operations-Adjust-the-Parameters-of-Algorithm)
At this stage, we will learn how to further adjust the algorithm parameters when the machine learning results are not as expected.
This tutorial provides a template named **`ml-sklearn-classification`**, you only need to upload the dataset you want to train and configure the environment variables required for training, then you are ready to train and validate.
## 1. Prepare Dataset and Upload
### 1.1 Data Format Description
Use **tabular data**, which is two-dimensional data consisting of Columns and Rows, with a **.csv** file extension, as shown in the table below.
sample_dataset.csv
| | Column 1 | Column 2 | Column 3 | ... | Column 9 |
| ----- | -------- | -------- | -------- | --- | -------- |
| **Row 1** | A1 | B1 | C1 | | I1 |
| **Row 2** | A2 | B2 | C2 | | I2 |
| **Row 3** | A2 | B3 | C3 | | I3 |
| **...** | | | | | |
| **Row 9** | A9 | B9 | C9 | | I9 |
The original table data needs to be split into **feature data (file name: train_x.csv)** and **target value data (file name: train_y.csv)** to be used as the input of the training model.
- **Feature data (file name: train_x.csv)**
It is the known data columns that will be used to predict the target value data.
- **Target value data (file name: train_y.csv, only one column of data)**
It is the real target value data, which is used for training and comparing with predicted values.
:::info
:bulb: **Tips: Tools for Splitting Data**
Generally, it can be processed quickly through spreadsheet software, such as **Microsoft Excel**, [**Google Sheets**](https://docs.google.com/spreadsheets/) and **LibreOffice Calc**. It can be done by deleting fields and then saving a new file.
:::
### 1.2 Prepare Data
This tutorial uses **[penguin data](https://www.kaggle.com/parulpandey/palmer-archipelago-antarctica-penguin-data)**, the public dataset provided by Kaggle as an example. In order to simplify the process, we use a simplified version of the dataset **penguins_size.csv** for description.
- **Column Description**
| Column Name | Description |
| ----------------- | ---- |
| species | Species, the values are<br> - Chinstrap (Antarctic penguin)<br> - Adélie (Adélie penguin)<br> - Gentoo (Gentoo penguin) |
| culmen_length_mm | The length of culmen (mm) |
| culmen_depth_mm | The depth of culmen (mm) |
| flipper_length_mm | The length of flipper (mm) |
| body_mass_g | Body weight (g) |
| island | The islands. The values are<br> - Dream<br> - Torgersen <br>- Biscoe<br> Palmer Archipelago in Antarctica |
| sex | Gender |
- **Data Content (Example)**
| 1 | species | island | culmen_<br>length_mm | culmen_<br>depth_mm | flipper_<br>length_mm | body_<br>mass_g | sex |
|-----|-----------|-----------|------------------|-----------------|-------------------|-------------|--------|
| 2 | Adelie | Torgersen | 39.1 | 18.7 | 181 | 3750 | MALE |
| ... | | | | | | | |
| 154 | Chinstrap | Dream | 46.5 | 17.9 | 192 | 3500 | FEMALE |
| ... | | | | | | | |
| 222 | Gentoo | Biscoe | 46.1 | 13.2 | 211 | 4500 | FEMALE |
| ... | | | | | | | |
Note: The index in the leftmost column is row number and is for reference, it’s not in the dataset.
In a classification task, as show in the example below, whether it is a sample dataset or a custom dataset, the dataset will contain two types of information:
1. **Feature (Feature Data)**:
Information such as culmen length, culmen depth, flipper length, body weight, island, gender.
2. **Classification Result (Target Value Data)**:
Such as the penguin species data, Chinstrap (Antarctic penguin), Adélie (Adelie penguin), Gentoo (Gentoo penguin).
Follow the steps below to re-split the dataset and convert the dataset into a format acceptable for model training:
1. **Training Dataset** And **Test Dataset**
Split penguins_size.csv proportionately by 80% and 20% (can be customized)
- Training dataset (train.csv): used to train the model.
- Test dataset (test.csv): Part of the data is reserved for evaluating the quality of the model.
2. **Features** And **Classification Results**
The Training Dataset and Test Dataset are further splitted into two parts: **Features** and **Classification Results**.
| | Features | Classification Results |
| ------------- | ----------- | ----------- |
| train.csv | train_x.csv| train_y.csv |
| test.csv | test_x.csv | test_y.csv |
Next, prepare to upload the four files: train_x.csv, train_y.csv, test_x.csv and test_y.csv.
### 1.3 Create a Bucket
Once the data is ready, you can go to **Storage Service** to upload the dataset.
1. **Go to Storage Service**
Select **Storage Service** from the OneAI service list to enter the Storage Service management page.
2. **Create a Bucket**
Then click **+CREATE** to add a bucket named **`penguin`** to store the dataset for training.
3. **View Bucket**
After the bucket is created, go back to the Storage Service Management page, click the **`penguin`** bucket justed created and get ready to upload the dataset.
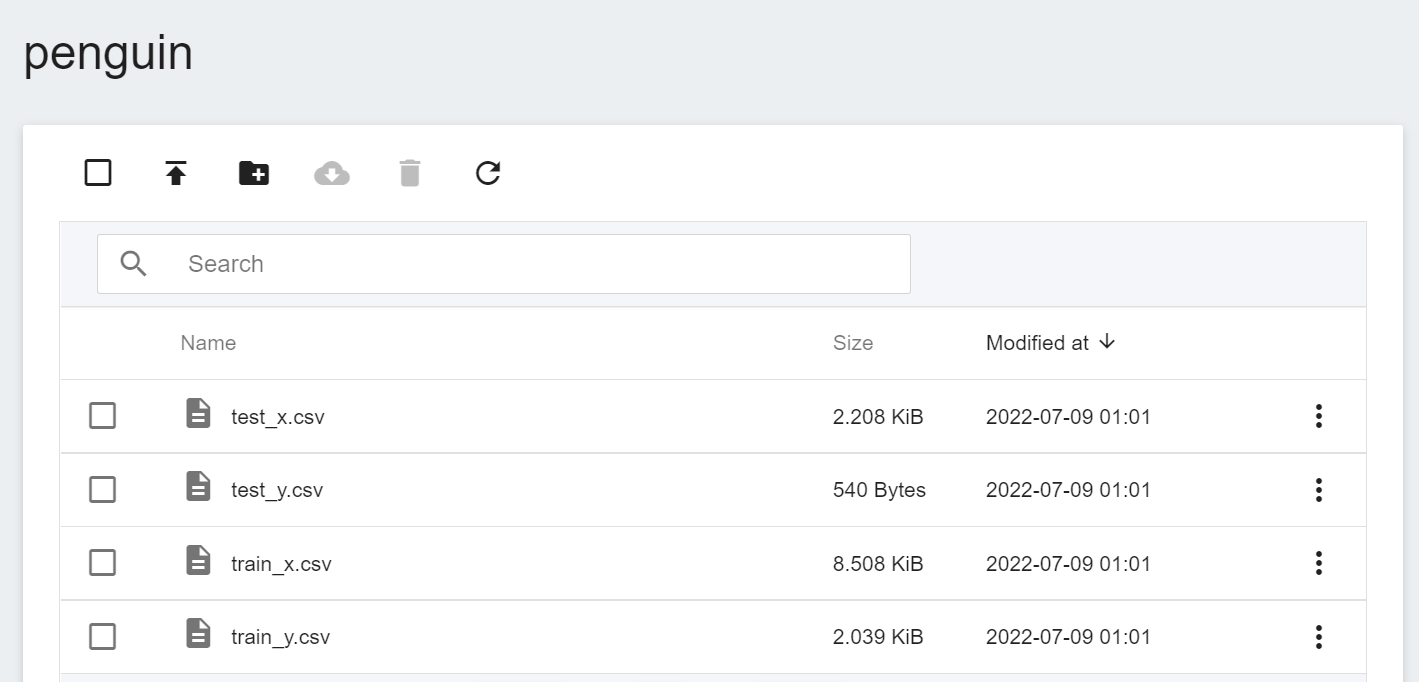
### 1.4 Upload Dataset
Next, upload the four penguin dataset files: train_x.csv, train_y.csv, test_x.csv and test_y.csv. The results after uploading are as follows:
## 2. Training Classification Model
After completing the [**Upload Dataset**](#1-Prepare-Dataset-and-Upload), you can use these data to train and fit our classification model.
### 2.1 Create Training Job
Select **AI Maker** from the OneAI service list, and then click **Training Job**. After entering the training job management page, switch to **Normal Training Job** tab, then click **+CREATE** to add a training job.
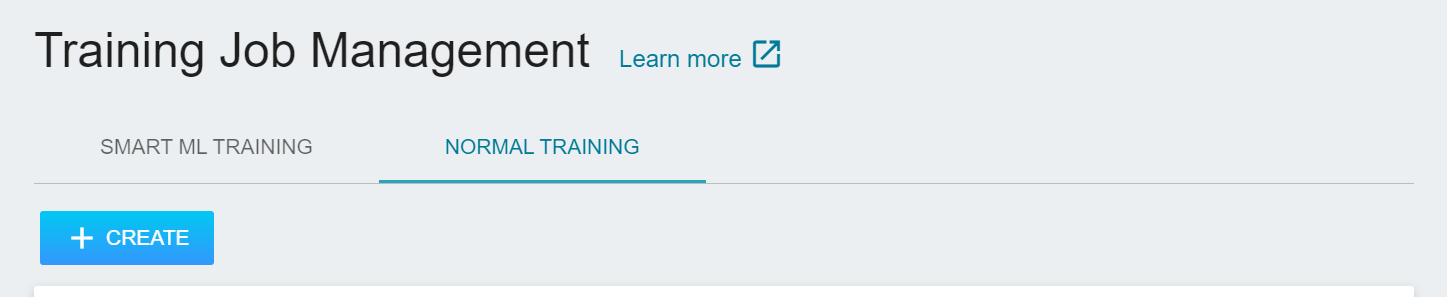
There are five steps in creating a training job. For detailed instructions, please refer to the [**AI Maker > Training Job**](/s/ai-maker-en#Training-Job).
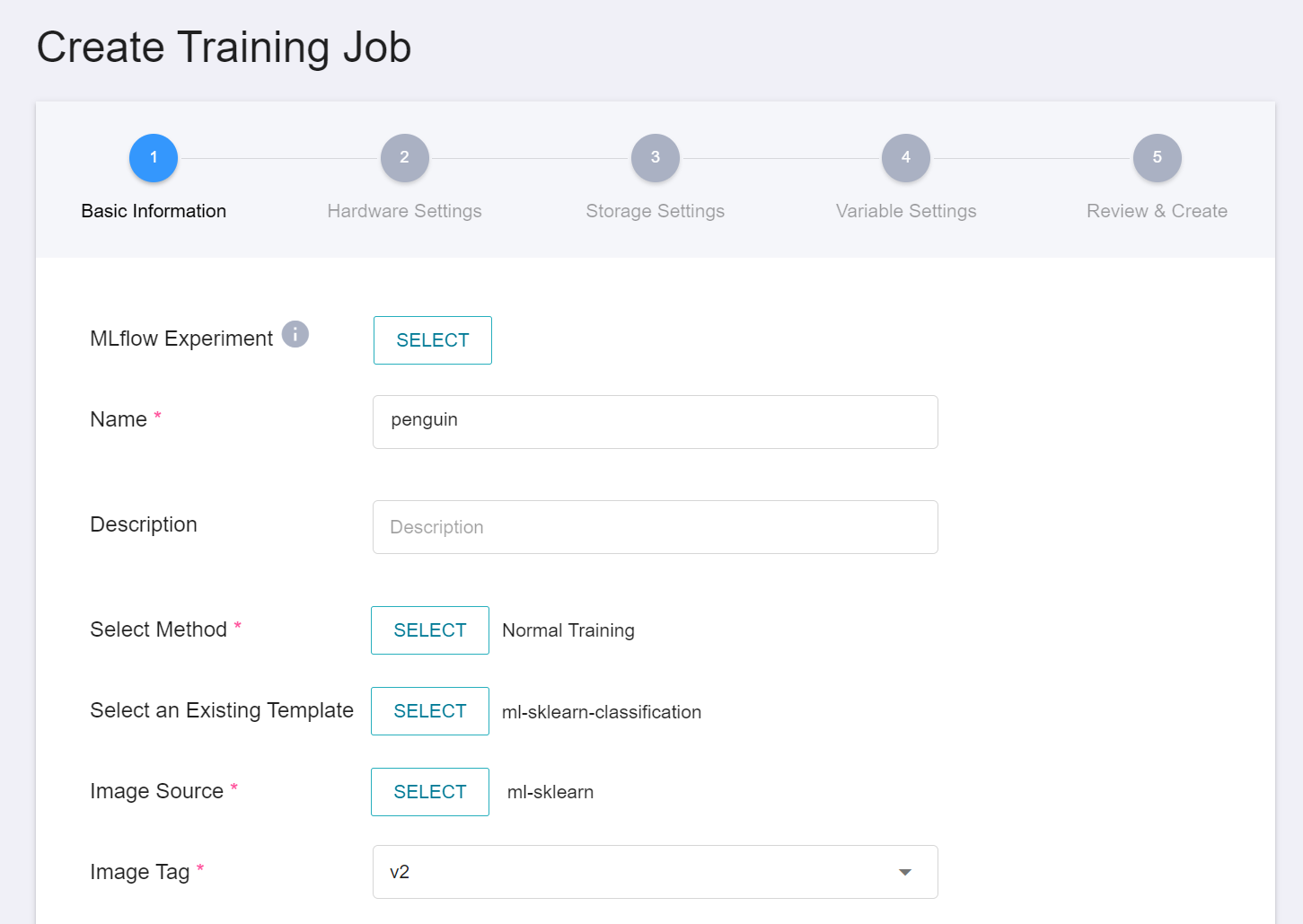
#### 2.1.1 Basic Information
The first step is to set the basic information, enter the name, description, selection method in sequence, and select the **`ml-sklearn-classification`** template. The template will automatically bring in the public image **`ml-sklearn:v2`** and various parameter settings for subsequent steps.
:::info
:bulb: **Tips: Template Feature**
AI Maker provides templates that define the default parameters and settings to be used for each stage of the task. You can use the template to quickly apply the parameters or settings to be used for each task to facilitate the workflow and training environment for machine learning.
:::
#### 2.1.2 Hardware Settings
The machine learning algorithm used in this example can use CPU or GPU computing resources. Please select the appropriate hardware resources from the list according to the current available quota and computing requirements.
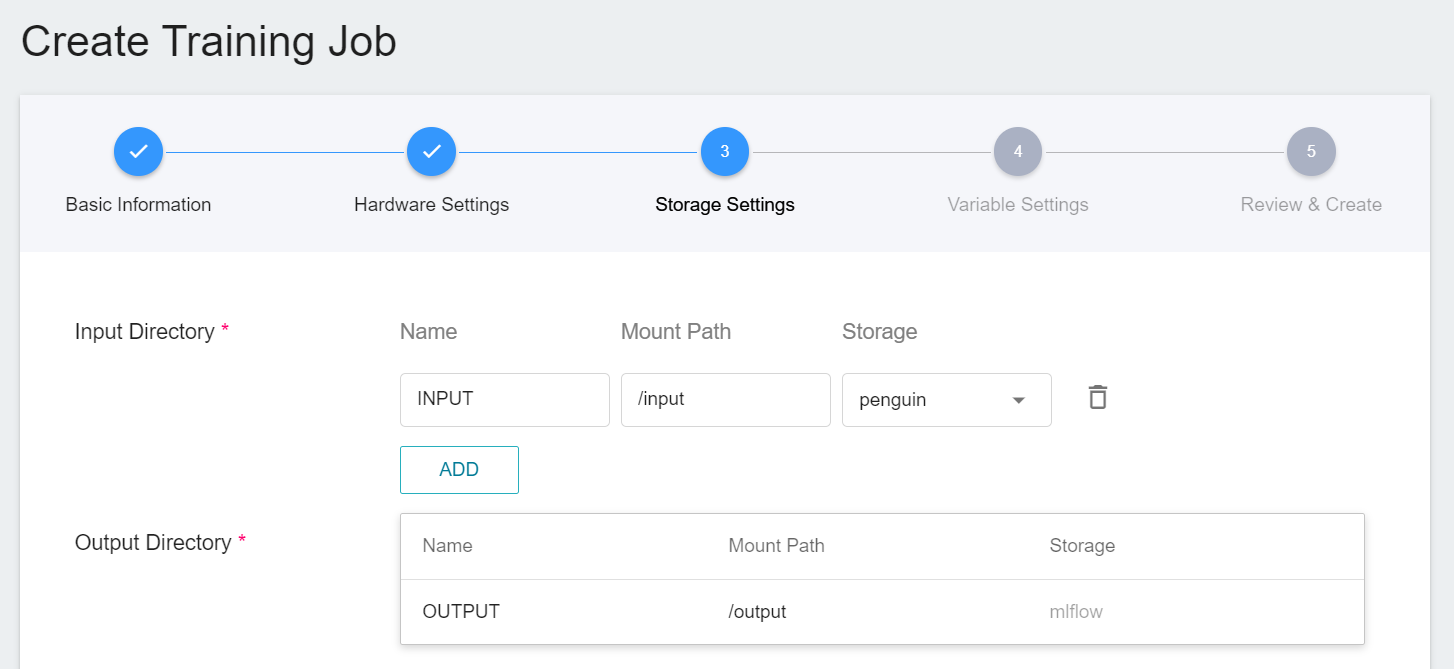
#### 2.1.3 Storage Settings
The bucket **`penguin`** onto which you previously uploaded dataset needs to be mounted in this step.
#### 2.1.4 Variable Settings
Next, set the environment variables and commands. When you choose to use the **`ml-sklearn-classification`** template while entering the basic information, the following variables and settings will be brought in automatically. The parameters are described below, and can be adjusted according to the requirements.
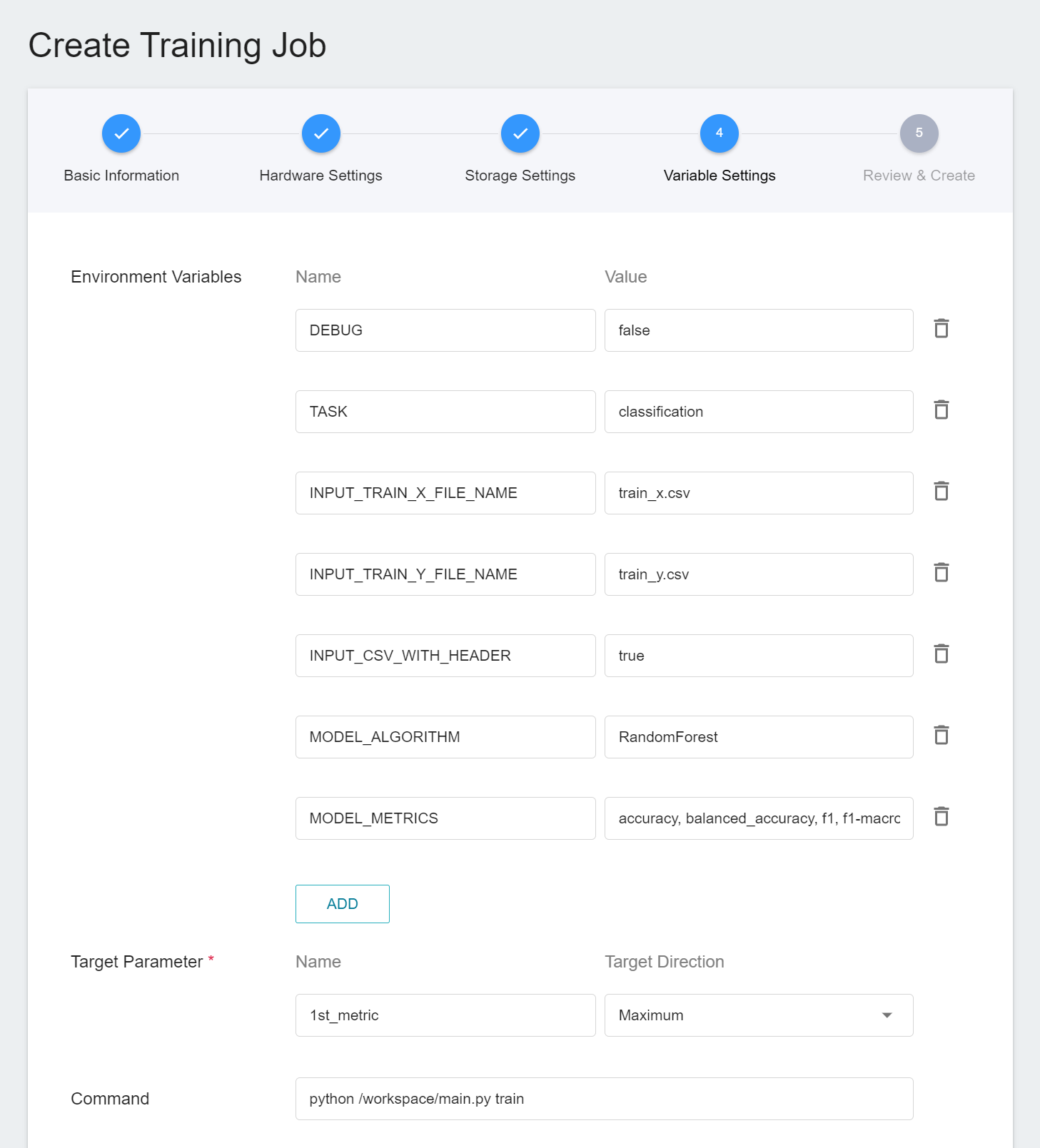
|Parameter |Default |Introduction|
|---|-----|---|
| [DEBUG](#DEBUG) | `false` | Whether to enable more logs to see the details of machine learning in action. To enable, set the value to `true`; otherwise, set the value to `false`. |
| [TASK](#TASK) <sup style="color:red"><b>*</b></sup> | `classification` | The type of tasks that machine learning is going to handle. Set the value to **`classification`** when the problem to be addressed by machine learning is a **classification problem**; set this value to **`regression`** for a **regression problem**.<br>|
| INPUT_TRAIN_X_FILE_NAME | `train_x.csv` | The file name of the feature data to be trained. |
| INPUT_TRAIN_Y_FILE_NAME | `train_y.csv` | The file name of the classification result to be trained. |
| <span style="white-space: nowrap"> [INPUT_CSV_WITH_HEADER](#INPUT_CSV_WITH_HEADER) <sup style="color:red"><b>*</b></sup></span> | `true` | If the dataset to be trained has a field name, set the value to `true`; if not, set the value to `false`. |
| [MODEL_ALGORITHM](#MODEL_ALGORITHM) <sup style="color:red"><b>*</b></sup> | `RandomForest` | Algorithm used in machine learning. |
| [MODEL_METRICS](#MODEL_METRICS) | `accuracy`, `balanced_accuracy`, `f1-macro`, `f1-micro` | Various metrics used to evaluate the classification model, please use `,` (comma) to separate each one, currently limited to log output. |
<sup style="color:red"><b>\*</b></sup> In general, the parameters that need to be noted when using machine learning are **TASK**, **INPUT_CSV_WITH_HEADER** and **MODEL_ALGORITHM**, more details of the parameters are as follows.
- #### DEBUG
Whether to enable more logs to view details of machine learning in action, including: input and output information for files, column and header information for data tables, information on how much memory is used in data tables, feature processing, and multiple evaluation metrics for models.
| Value | Description |
| -- | -------- |
| `true`<br>`1` | Enable more logs (recommended) |
| The rest of the values | Disable logs |
- #### TASK
The type of tasks that machine learning is going to handle.
| Value | Description |
| -- | -------- |
| `classification` | Machine learning will use the **classification** algorithm, see [**`MODEL_ALGORITHM`**](#MODEL_ALGORITHM) description |
| `regression` | Machine learning will use the **regression** algorithm, see [**`MODEL_ALGORITHM`**](#MODEL_ALGORITHM) description |
- #### INPUT_CSV_WITH_HEADER
Whether the dataset to train has field names.
| Value | Description |
| -- | -------- |
| `true`<br>`1` | Indicates that in the csv file, the first row are the field names |
| The rest of the values | Indicates that in the csv file, the first row are not the field names, and are just data |
- #### MODEL_ALGORITHM
Algorithm used in machine learning.
| Value | Support Classification | Support Regression | Additional Note<br>See detailed descriptions below the table |
| --------------------- |:--------:|:--------:| -------- |
| `Auto` | ✔ | ✔ | Automatic machine learning (Auto-ML) with **automatic algorithm selection** and **hyperparameter adjustment** |
| `AutoGluon` | ✔ | ✔ | An AutoML tool that supports CPU & GPU |
| `AutoSklearn` | ✔ | ✔ | An AutoML tool that does not support GPU, but can still be executed in a GPU environment |
| `AdaBoost` | ✔ | ✔ | Adaptive enhancement |
| `ExtraTree` | ✔ | ✔ | Extremely randomized tree |
| `DecisionTree` | ✔ | ✔ | Decision tree |
| <span style="white-space: nowrap">`GradientBoosting`</span> | ✔ | ✔ | Gradient boosting |
| `KNeighbors` | ✔ | ✔ | k nearest neighbors |
| `LightGBM` | ✔ | ✔ | Efficient gradient boosting decision tree |
| <span style="white-space: nowrap">`LinearRegression`</span> | ✘ | ✔ | Linear regression |
| <span style="white-space: nowrap">`LogisticRegression`</span> | ✔ | ✘ | Logistic regression |
| `RandomForest` | ✔ | ✔ | Random forest |
| `SGD` | ✔ | ✔ | Stochastic gradient descent |
| `SVM` | ✔ | ✔ | Support vector machine |
| `XGBoost` | ✔ | ✔ | Extreme gradient boosting |
:::spoiler **What happens when the value is set to `Auto`**
When the machine learning algorithm is set to `Auto`, the programs provided by the `ml-sklearn` image will choose depending on whether there is GPU in the current hardware resource:
- If there is GPU in the hardware resource, the AutoML tool [`AutoGluon`](https://auto.gluon.ai/stable/tutorials/tabular_prediction/index.html) will be used;
- Onversely, if there is no GPU in the hardware resource, that is, with only CPU, the AutoML tool [`AutoSklearn`](https://automl.github.io/auto-sklearn/master/index.html) will be used.
- In practice, users can also choose to use either [`AutoGluon`](https://auto.gluon.ai/stable/tutorials/tabular_prediction/index.html) or [`AutoSklearn`](https://automl.github.io/auto-sklearn/master/index.html).<br><br>
:::
:::spoiler **What happens when the value is set to `AutoGluon`**
- The programs provided by the `ml-sklearn` image directly use the `AutoGluon` set of AutoML tools.
- By default, `AutoGluon` integrates the underlying machine learning algorithms during training and produces a more powerful model.
| Algorithm name | Support GPU | Documentation |
| -------- | ------ | ---- |
| CatBoost | ✔ | [View](https://catboost.ai/) |
| ExtraTrees | | [View](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.ExtraTreesClassifier.html) |
| KNeightbors | | [View](https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html) |
| LightGBM | | [View](https://lightgbm.readthedocs.io/en/latest/) |
| NeuralNetFast | ✔ | [View](https://docs.fast.ai/tabular.models.html) |
| NeuralNetTorch | ✔ | - |
| RandomForest | | [View](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html) |
| XGBoost | ✔ | [View](https://xgboost.readthedocs.io/en/latest/) |
- `AutoGluon` enables GPU mode by default. In the GPU environment, if the algorithm supports GPU, it will use GPU acceleration; if it does not support GPU, it will use CPU for computing. If the user selects `AutoGluon` in an environment without GPU, the CPU mode will be used.
- For more detailed introduction, please refer to the official [**documentation**](https://auto.gluon.ai/stable/tutorials/tabular_prediction/index.html).<br>
:::
:::spoiler **What happens when the value is set to `AutoSklearn`**
- The programs provided by the `ml-sklearn` image directly use the `AutoSklearn` set of AutoML tools.
- `AutoSklearn` does not support GPU, but the tool can also be executed in GPU environment, only that it will not use GPU resources.
- For more detailed introduction, please refer to the official [**documentation**](https://automl.github.io/auto-sklearn/master/index.html).
:::
:::spoiler **Other machine learning algorithms**
<span id="footnote_experimental_algorithm_class_list"></span>If the machine learning algorithm used does not appear in the above list, the user can select it from the list below. Below is a list of all the **values** (in alphabetical order) that can be used by the classification model algorithm:
- `AdaBoostClassifier`
- `AutoSklearnClassifier`
- `AutoGluonClassifier`
- `BaggingClassifier`
- `BernoulliNB`
- `CategoricalNB`
- `ComplementNB`
- `DummyClassifier`
- `ExtraTreeClassifier`
- `ExtraTreesClassifier`
- `GaussianNB`
- `GaussianProcessClassifier`
- `GradientBoostingClassifier`
- `KNeighborsClassifier`
- `LGBMClassifier`
- `LinearSVCDecisionTreeClassifier`
- `LogisticRegression`
- `MLPClassifier`
- `MultinomialNB`
- `NuSVC`
- `PassiveAggressiveClassifier`
- `RadiusNeighborsClassifier`
- `RandomForestClassifier`
- `RidgeClassifier`
- `RidgeClassifierCV`
- `SGDClassifier`
- `SVC`
- `XGBClassifier`
:::
- #### MODEL_METRICS
Various metrics used to evaluate the classification model, please use `,` (comma) to separate each one, currently limited to log output. If this environment variable is not defined, the default evaluation metric will use `accuracy`.
Settings example:
- `f1`
- `accuracy`
- `accuracy, balanced_accuracy`
- `f1, f1_micro, f1_macro, f1_weighted`
<br>
| Value | Description |
| -- | -------- |
| `accuracy` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#accuracy-score) |
| `balanced_accuracy` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#balanced-accuracy-score) |
| `top_k_accuracy` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#top-k-accuracy-score) |
| `average_precision` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) |
| `neg_brier_score` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#brier-score-loss) |
| `f1` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) (Binary classification only) |
| `f1_micro` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) |
| `f1_macro` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) |
| `f1_weighted` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) |
| `f1_samples` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-f-measure-metrics) |
| `neg_log_loss` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#log-loss) |
| `precision` | [Usage description](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_score.html#sklearn.metrics.precision_score) |
| `recall` | [Usage description](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.recall_score.html#sklearn.metrics.recall_score) |
| `jaccard` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#jaccard-similarity-score) |
| `roc_auc` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#roc-metrics)<br>The classification result (target value data) must be numeric |
| `roc_auc_ovr` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#roc-metrics) |
| `roc_auc_ovo` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#roc-metrics) |
| `roc_auc_ovr_weighted` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#roc-metrics) |
| `roc_auc_ovo_weighted` | [Usage description](https://scikit-learn.org/stable/modules/model_evaluation.html#roc-metrics) |
|Target Parameter|Direction|Description|
|----------|-----|---|
| `1st_metric` | Maximum| **(Smart ML Training Job)** When using **`Bayesian`** or **`TPE`** algorithms, they will repeatedly adjust the appropriate parameters based on the results of the **target parameters** as a benchmark for the next training job. <br> After training, a value will be returned as the final result. Here, the name and target direction need to be set for this value. For example, if the returned value is the accuracy rate, you can name it accuracy and set its target direction to the maximum value; if the returned value is the error rate, you can name it error and set its direction to the minimum value.<br><br> The metrics provided according to the task type is **`f1`**, and its direction is **`Maximum`**. |
Finally, after confirming that the settings information is correct, click **CREATE**.
### 2.2 Start a Training Job
After completing the setting of the training job, go back to the training job management page, and you can see the job you just created. Click the job to view the detailed settings of the training job. If the job state is displayed as **`Ready`** at this time, you can click **START** to execute the training job.
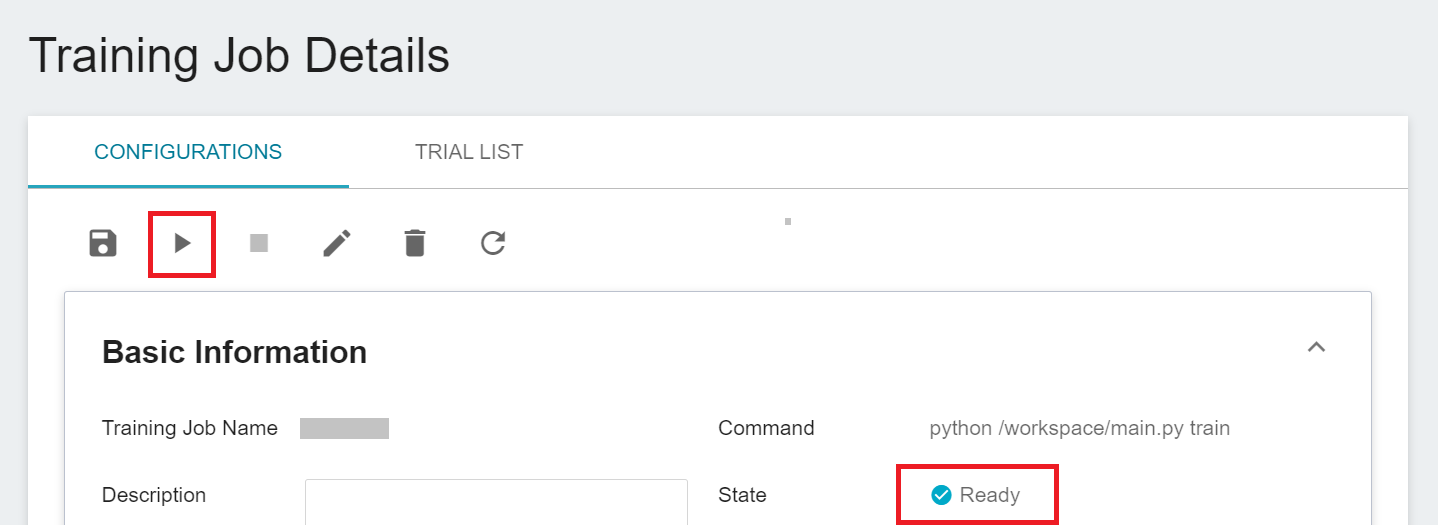
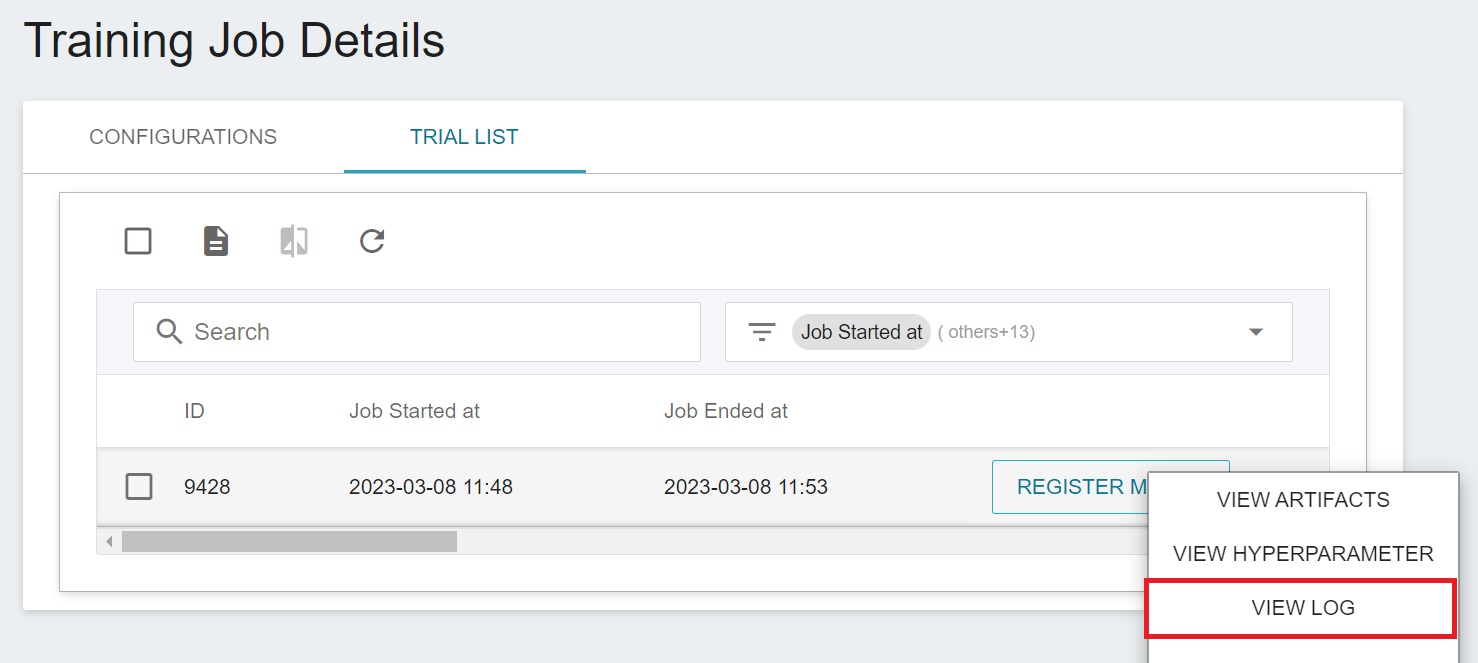
Once started, click the **TRIAL LIST** tab above to view the execution status and schedule of the job in the list. During training, you can click **VIEW LOG** or **VIEW DETAIL STATE** in the menu on the right of the job to know the details of the current job execution.
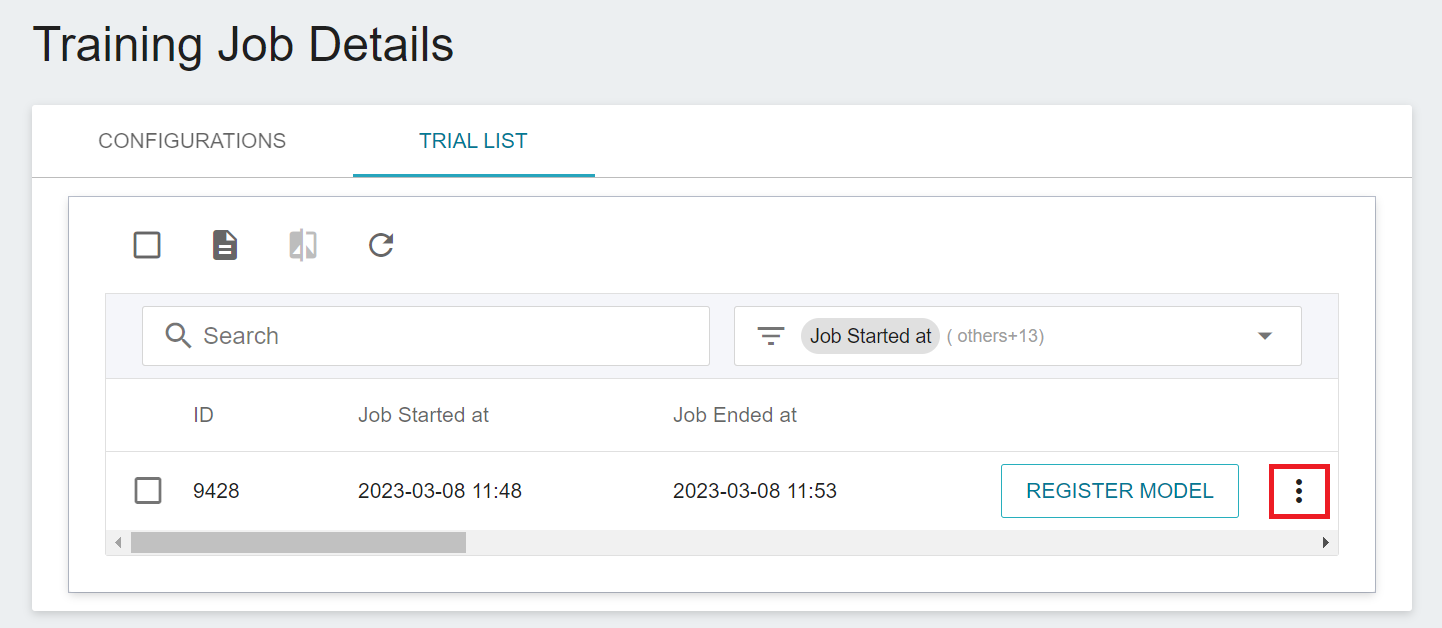
### 2.3 View Training Results
#### 2.3.1 Model Evaluation Score
When the training is complete, you can view the evaluation metrics generated by the model or [**custom model metrics**](#MODEL_METRICS).

You can also choose [**custom evaluation metrics**](#MODEL_METRICS) accuracy, balanced_accuracy (unselect all first, then check the desired metrics), and then observe the results, the larger the value, the better.
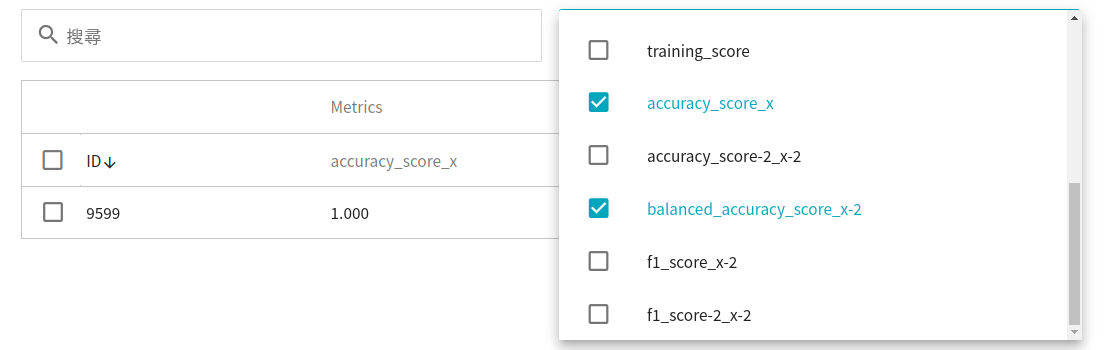
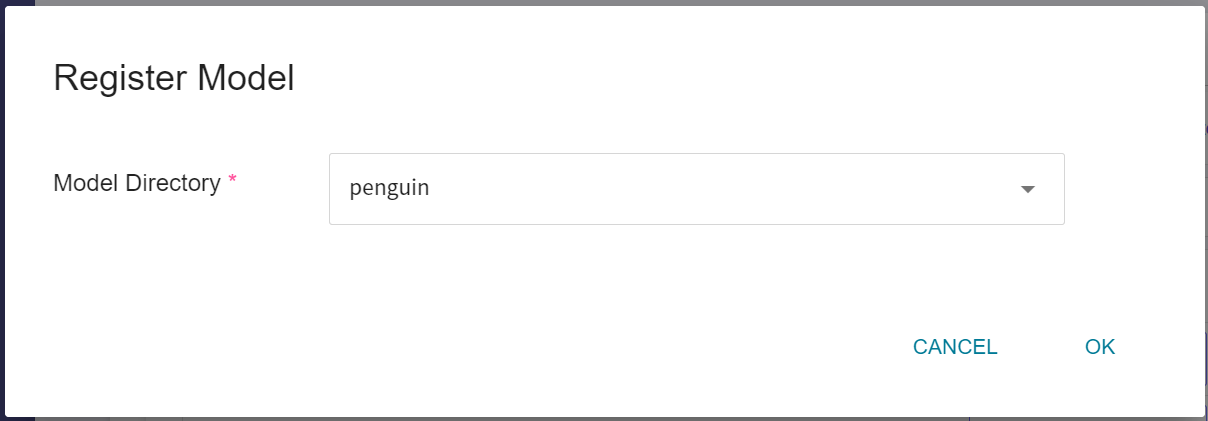
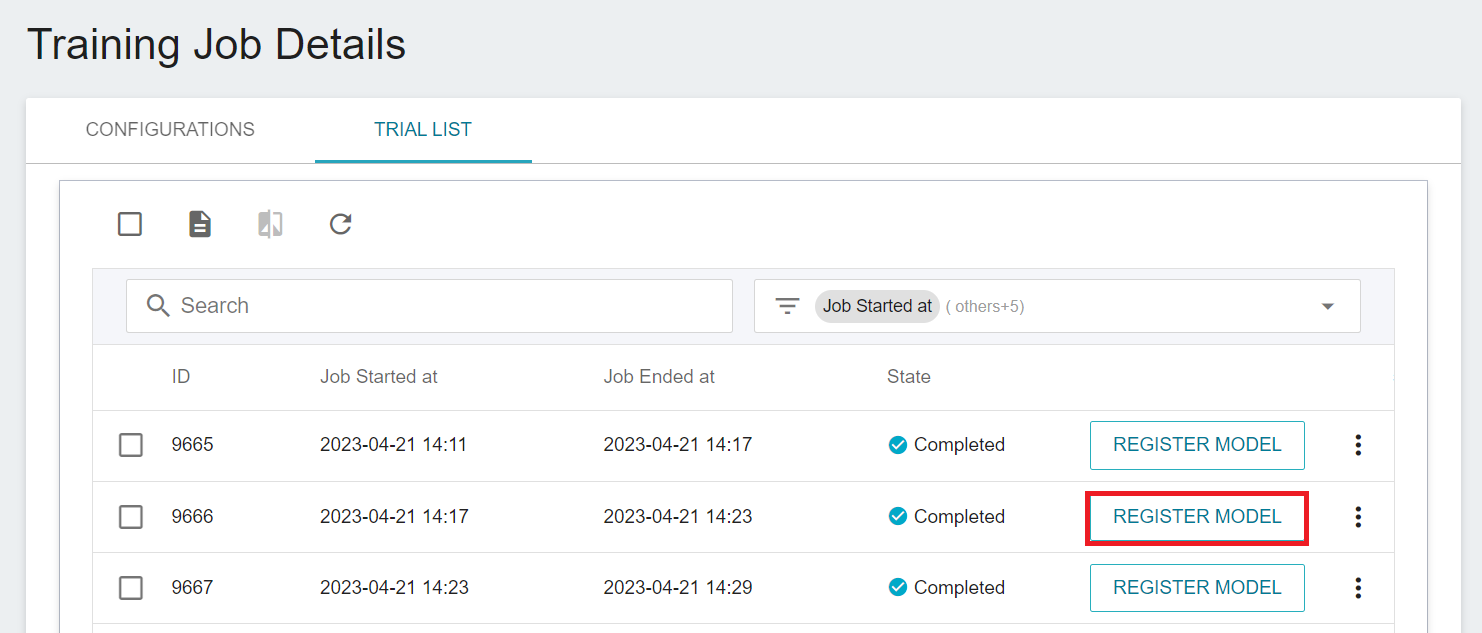
The current metrics is the result obtained through the machine learning algorithm **`RandomForest`**. If it meets expectations, you can click **REGISTER MODEL** to save it to **Model Management**; if not, readjust the values or value ranges of environmental variables and hyperparameters.
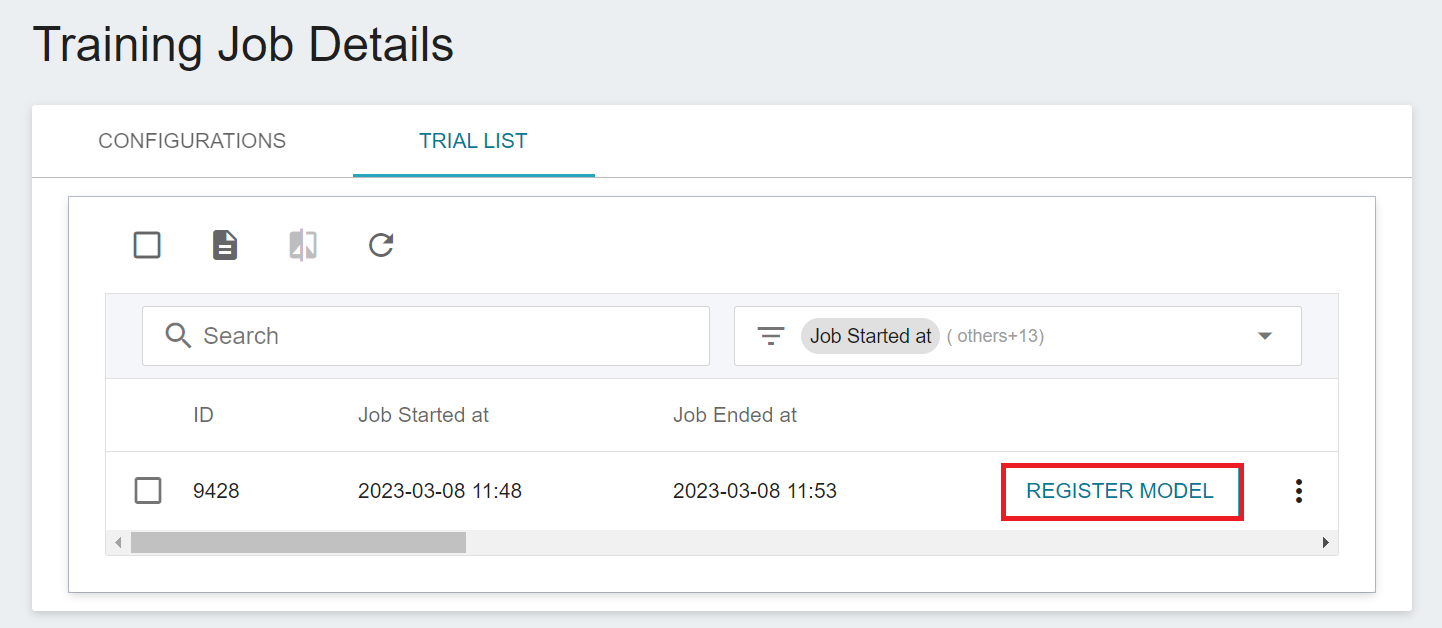
In the **Register Model** window, you can enter the name of the model directory to be created, for example: `penguin` or select an existing model directory.
You can use the following methods to evaluate the quality of a machine learning model:
1. Use the unseen test dataset (eg: test_x.csv and test_y.csv) to evaluate the model; if there is no test dataset, make atest dataset by subsampling from the training dataset (train_x.csv and train_y.csv).
2. The first metric in the list of metrics set by [**MODEL_METRICS**](#MODEL_METRICS) in the **Environmental Variables** is used as the evaluation metric, refer to the following table:
| | MODEL_METRICS Setting Example | Metric Used to Evaluate Result |
| ---- | ------------------- | ----------- |
| Example 1 | **f1** | f1|
| Example 2 | **accuracy** | accuracy |
| Example 3 | **accuracy**, balanced_accuracy | accuracy |
| Example 4 | **f1**, f1_micro, f1_macro, f1_weighted | f1 |
| Example 5 | No evaluation metric is specified, or the environment variable is not set | accuracy |
#### 2.3.2 Machine Learning Execution Logs
Click **View Log** in the menu to the right of the task.
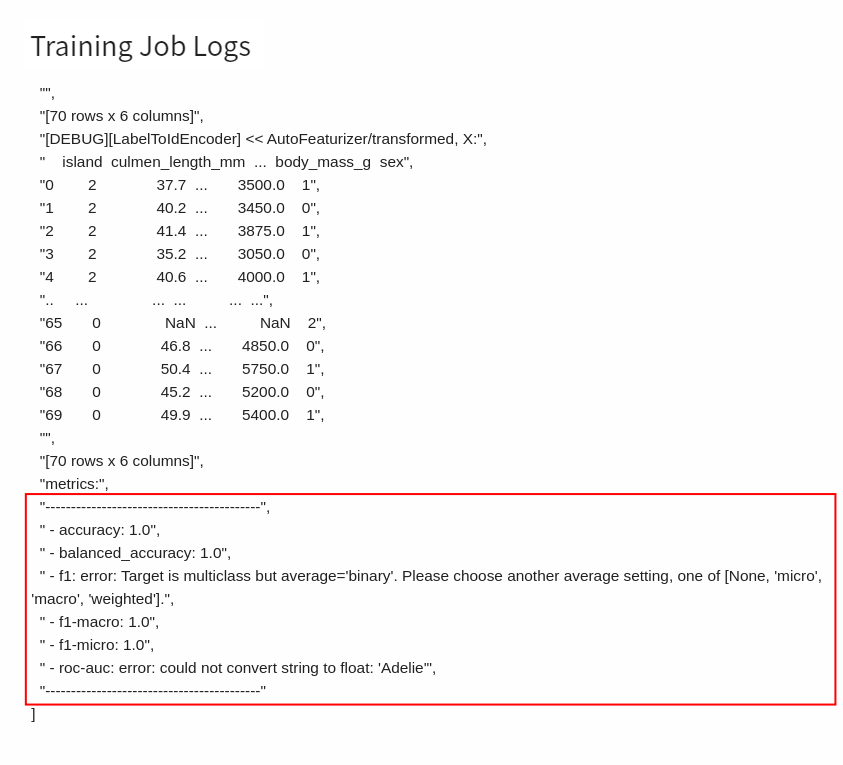
Scroll to the bottom of the log to get scores of all evaluation metrics set by [**MODEL_METRICS**](#MODEL_METRICS) in **Environment Variables**.
### 2.4 Try Different Algorithms and Retrain
If the results of the trained model are not as expected, try changing the algorithm and retrain.
1. Click the **CONFIGURATIONS** tab to return to the configuration page of the training job, and then click **EDIT** on the command bar to modify the settings.
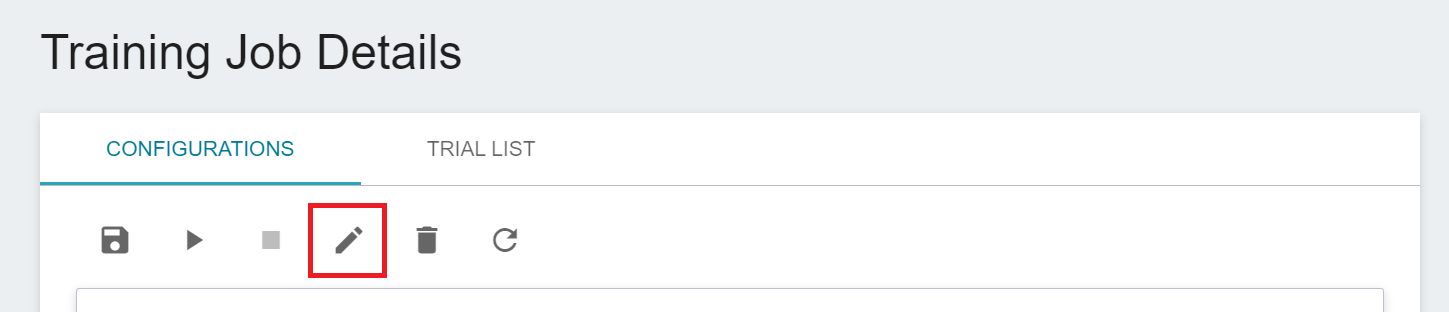
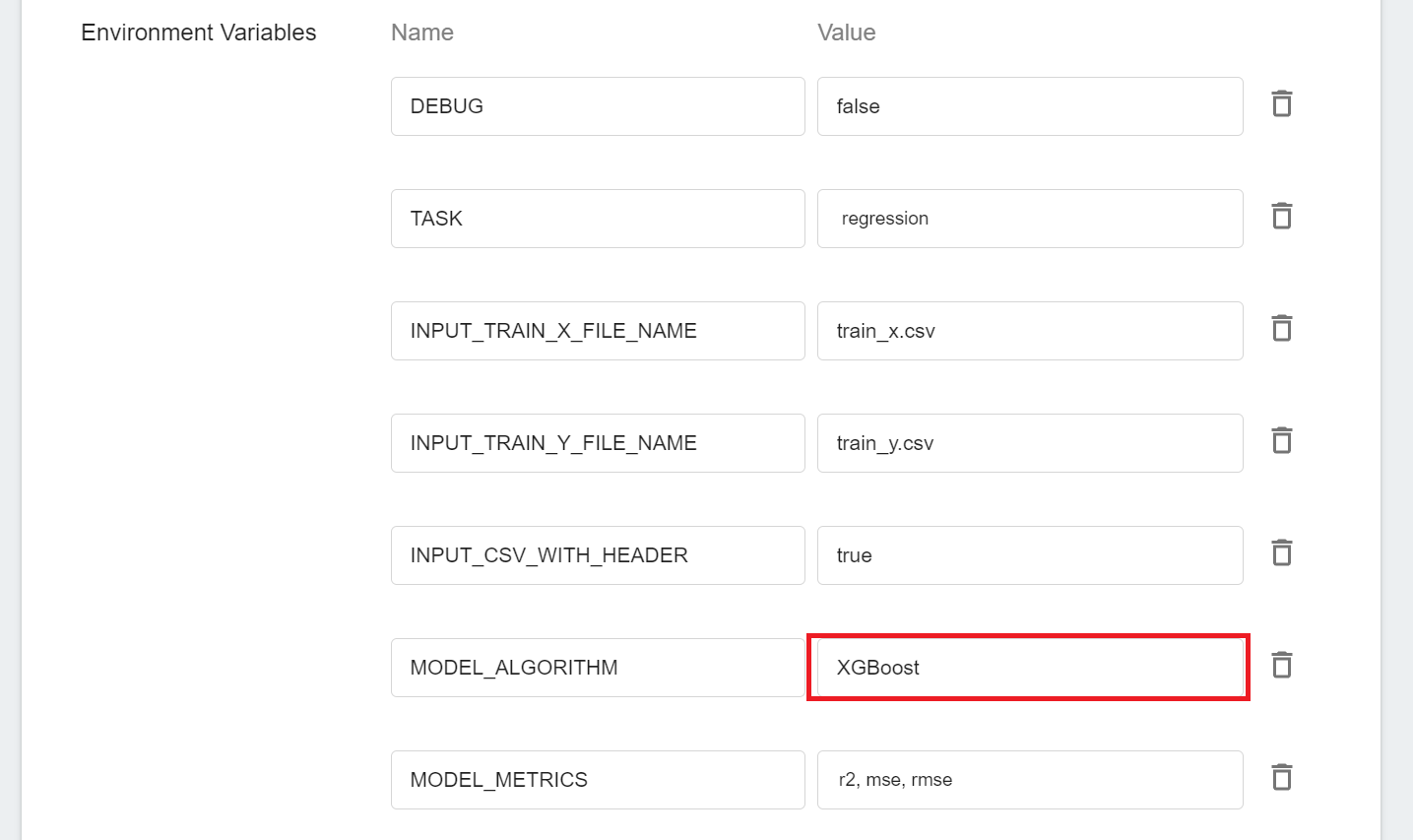
2. Change the [**`MODEL_ALGORITHM`**](#MODEL_ALGORITHM) in the **Environment Variables** to **`XGBoost`**, save it and restart the training job.
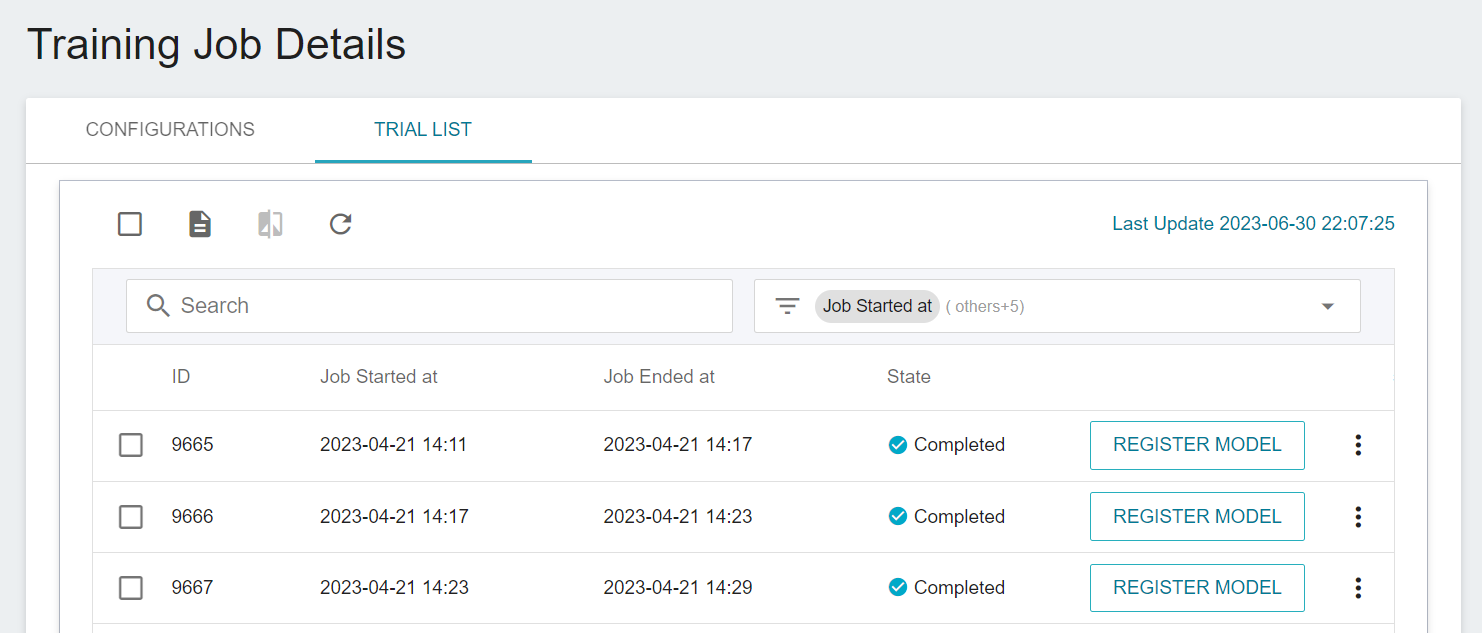
3. After trying different algorithms, go back to the **TRIAL LIST** page to see the execution results of multiple jobs.
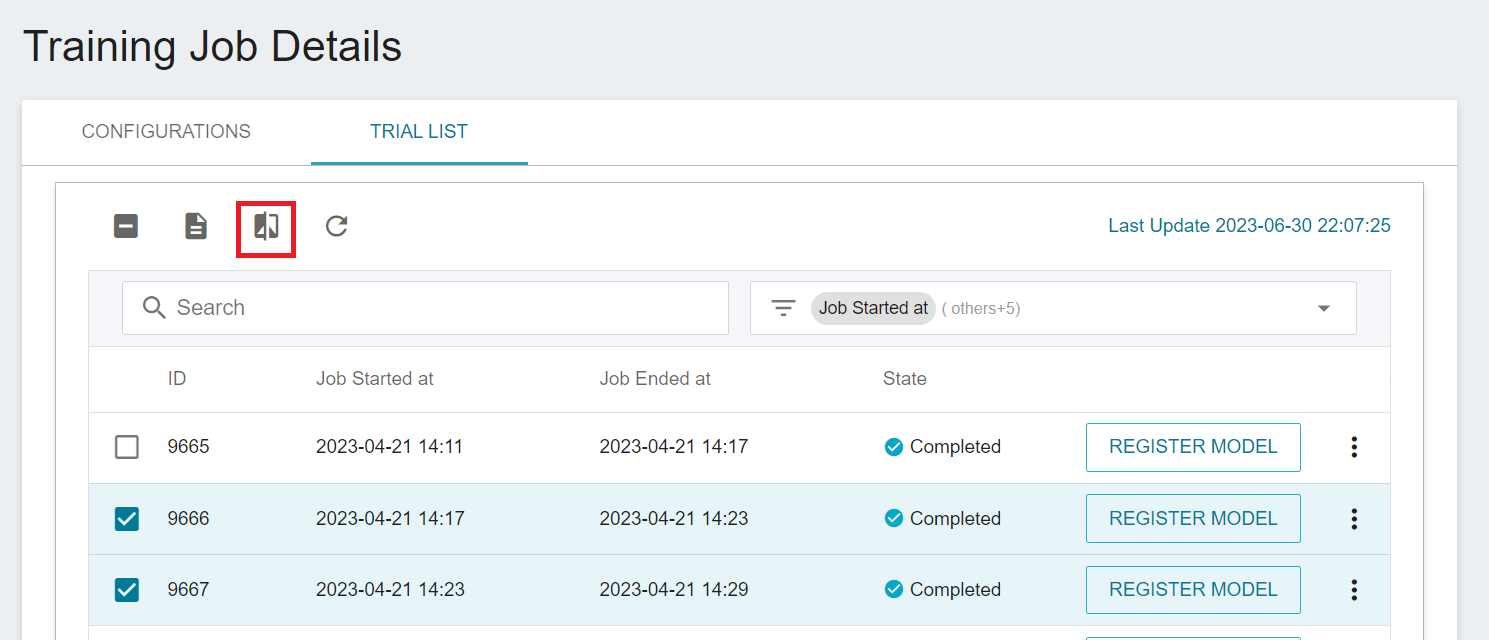
4. Select similar results for comparison (XGboost has better training results)
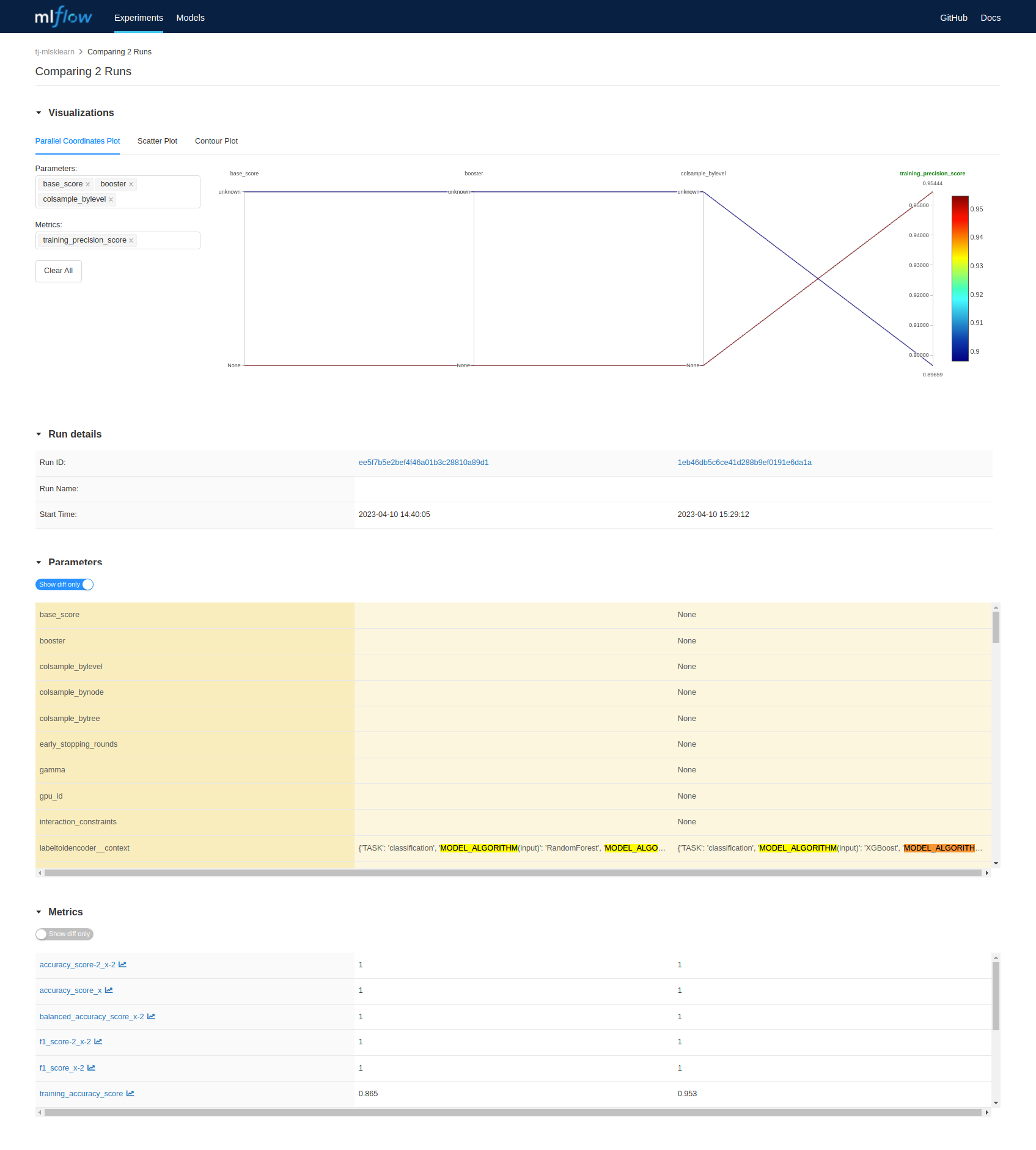
### 2.5 Register Model
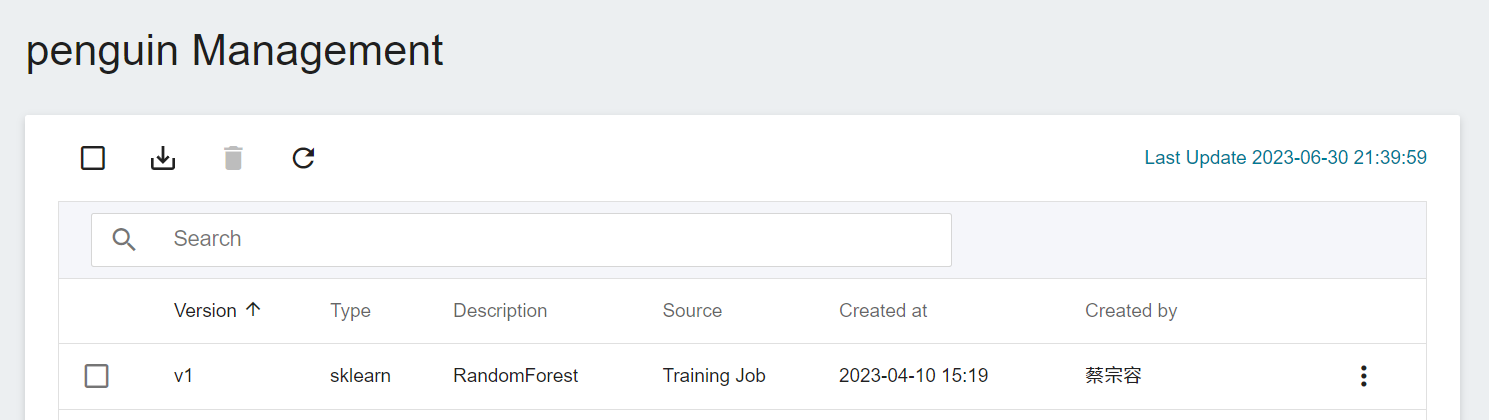
After trying out different algorithms, you can pick the ones that match your expectations and save the model in the **Model Repository**.

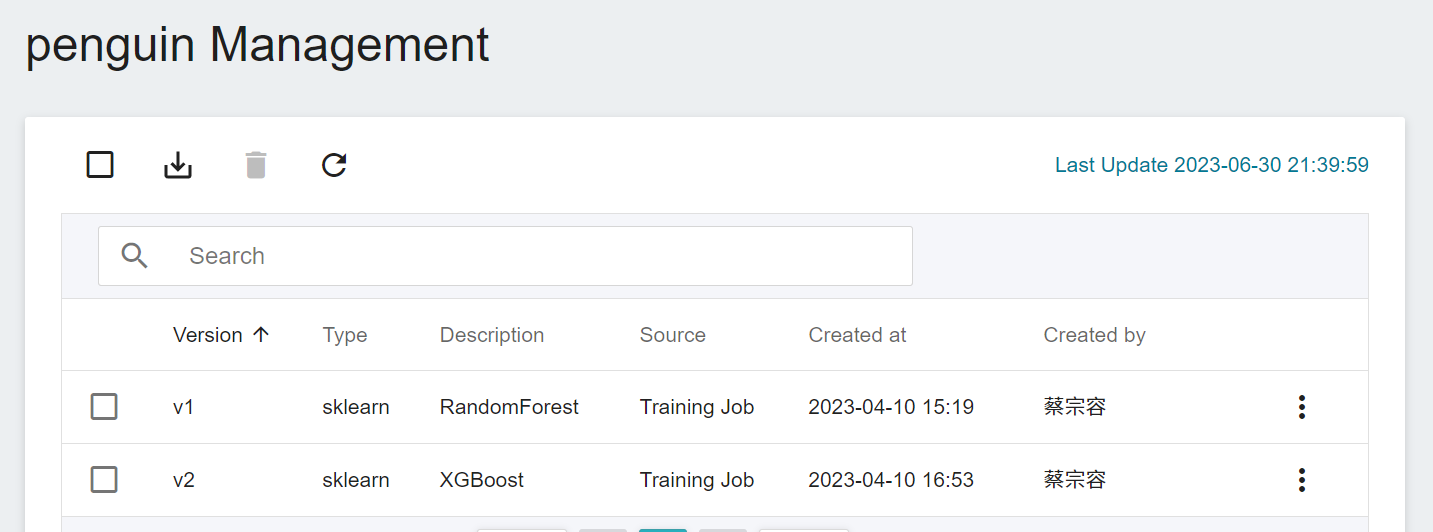
In this example, one or more models can be stored.
## 3. Create Inference Service
Once you have trained a classification model and stored a suitable model, you can then deploy the model as a web service using the **Inference Feature** for an application or service to perform inference.
### 3.1 Create Inference Service
Select **AI Maker** from the OneAI service list, then click **Inference** to enter the inference management page, and click **+CREATE** to create an inference service. The steps for creating the inference service are described below:
#### 3.1.1 **Basic Information**
Similar to the setting of the basic information of the training job, firstly change the **Create Method** to **Customize**, and apply the public template **`ml-sklearn-classification`** to load the default settings. The template will automatically bring in the basic settings of the **Source Model**. However, the model name and version number to be loaded still need to be set manually, as shown below.
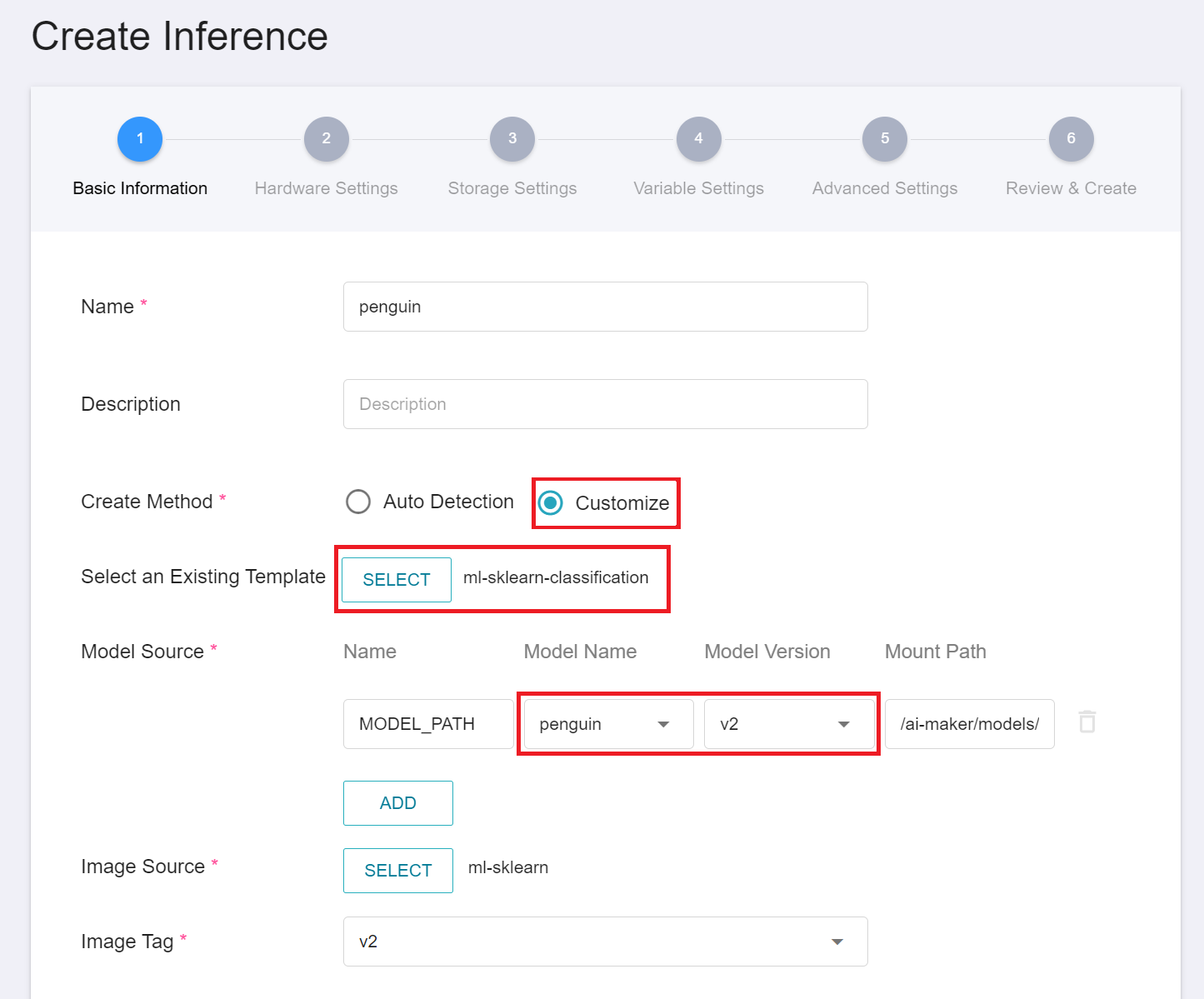
:::info
:bulb: **Tips: Source Model Information**
Refer to the model saved in step [**2.5 Save Model**](#25-Save-Model).
| ID | [`MODEL_ALGORITHM`](#MODEL_ALGORITHM) | Model's accuracy evaluation score | Model Name |
| ---- | --------------------- | ----------- | ------- |
| 286 | `XGBoost` | 1.0 | `penguin:xgb-100` |
| 285 | `RandomForest` | 1.0 | ==`penguin:rf-100`== |
:::
#### 3.1.2 **Hardware Settings**
Select the appropriate hardware resource from the list with reference to the current available quota and requirements.
#### 3.1.3 **Storage Settings**
No configuration is required for this step.
#### 3.1.4 **Variable Settings**
On the Variable Settings page, These commands and parameters are automatically brought in when the template is applied.
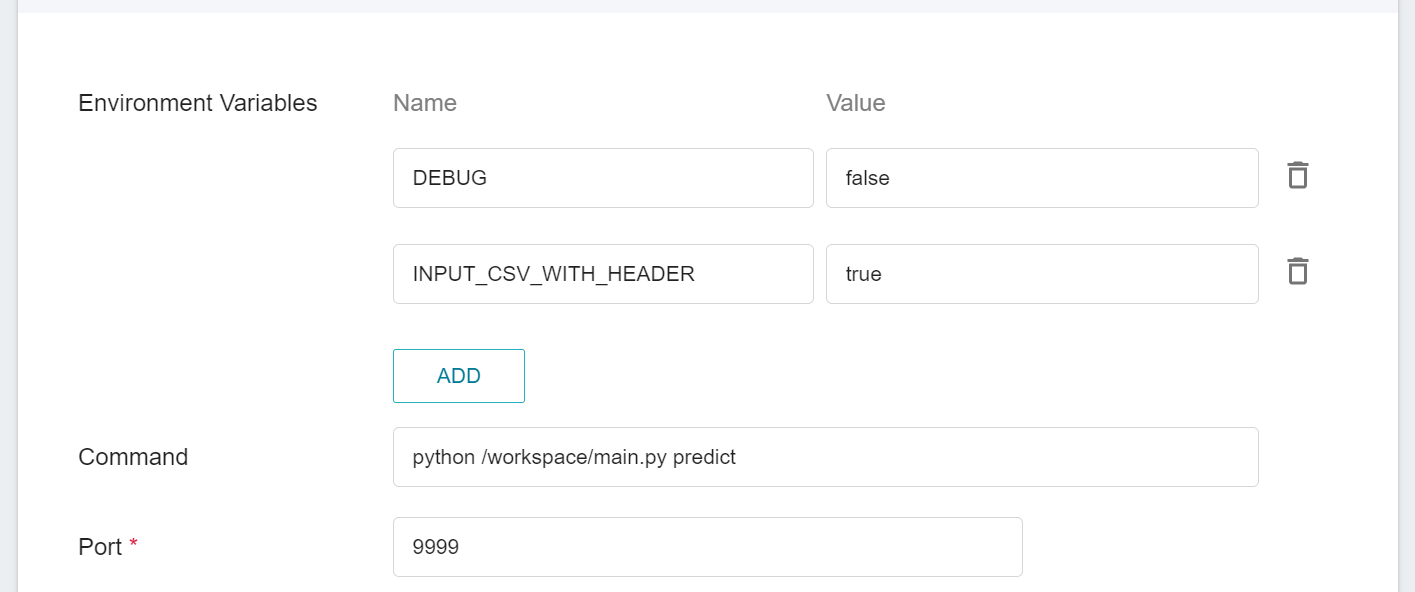
The parameters set in **Environment Variables** for this inference template are described as follows:
|Parameter |Default |Introduction|
|---|-----|---|
| [DEBUG](#DEBUG) | `false` | Whether to enable more logs to see the details of inference service. To enable, set the value to `true`; otherwise, set the value to `false`. |
| <span style="white-space: nowrap">[INPUT_CSV_WITH_HEADER](#INPUT_CSV_WITH_HEADER) <sup style="color:red"><b>*</b></sup></span> | `true` | If the dataset to be inferred has a field name, set the value to `true`; if not, set the value to `false`. |
<sup style="color:red"><b>\*</b></sup> In general, the parameters that need to be noted when using inference are **INPUT_CSV_WITH_HEADER**, more details of the parameters are as follows:
- #### `DEBUG`
Whether to enable more logs to see the details of inference service.
| Value | Description |
| -- | -------- |
| `true`<br>`1` | Enable more logs (recommended) |
| The rest of the values | Disable logs |
- #### `INPUT_CSV_WITH_HEADER`
Whether the dataset to be inferred has field names. This parameter is used to set the default option of the inference service. Subsequent inference tests do not need to carry this parameter, which simplifies the commands or code required for inference test.
| Value | Description |
| -- | -------- |
| `true`<br>`1` | Indicates that in the csv file, the first row are the field names |
| The rest of the values | Indicates that in the csv file, the first row are not the field names, and are just data |
#### 3.1.5 Advanced Settings: Inference Monitoring
Inference monitoring allows you to observe the number of calls to the inference service API and the statistics of inference results over a period of time. This template sets up two monitoring metrics, target and statistics, to provide statistical information on the type and number of inference results.
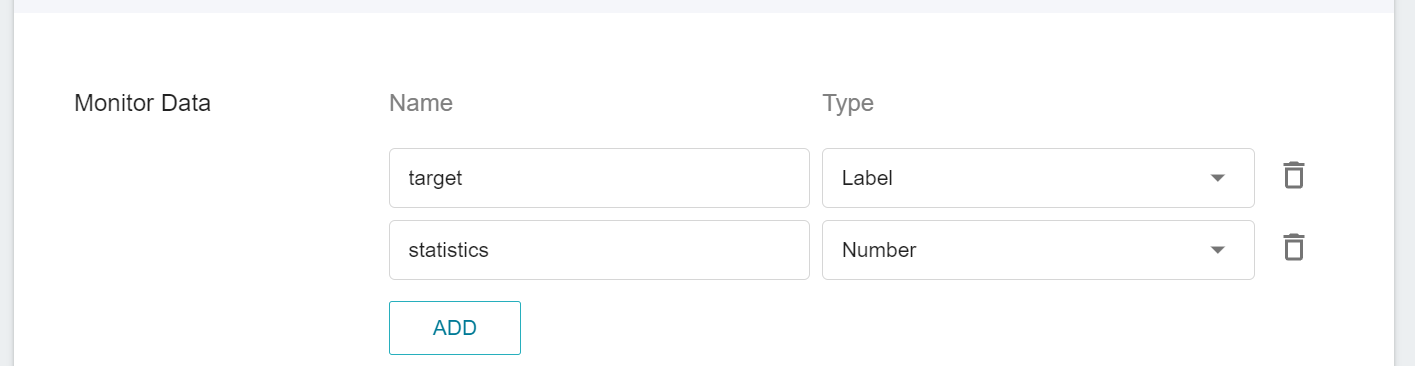
| Name | Type | Type & Description |
|-----|-----|------------|
| target | Tag | **Counting type**<br>The total number of times each target value is accumulated in the specified time interval.<br> In other words, the distribution of the categories over a period of time.<br>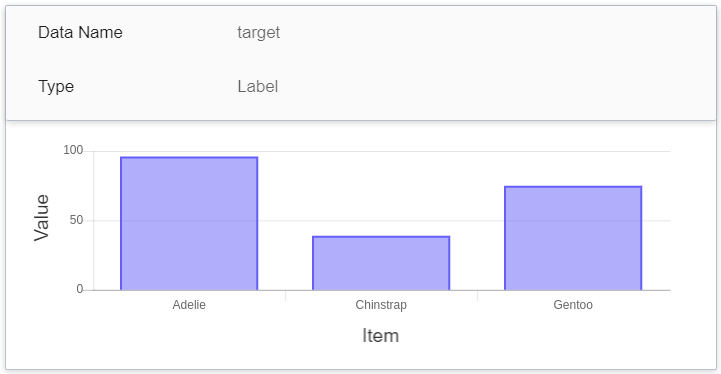
|
| statistics | Number | **Metric**<br>The total number of occurrences of each target value in one call to the Inference API at a point in time.<br> In other words, you can see the changes in total number of times each category calls the API.<br>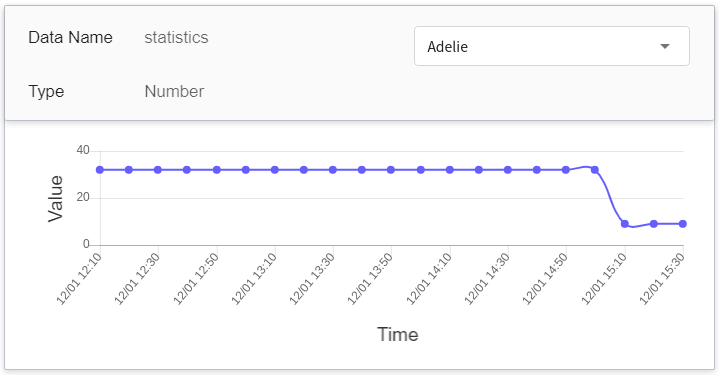<br> (Future trend, if there is no API call, it will continue with the last value) |
#### 3.1.6. **Review & Create**
Finally, confirm the entered information and click **CREATE**.
### 3.2 Viewing the Status and Endpoint of Inference Service
After completing the settings of the inference service, go back to the inference management page, click the inference service you just created to view the basic information. When the service state shows as **`Ready`**, you can start connecting to the inference service for inference.
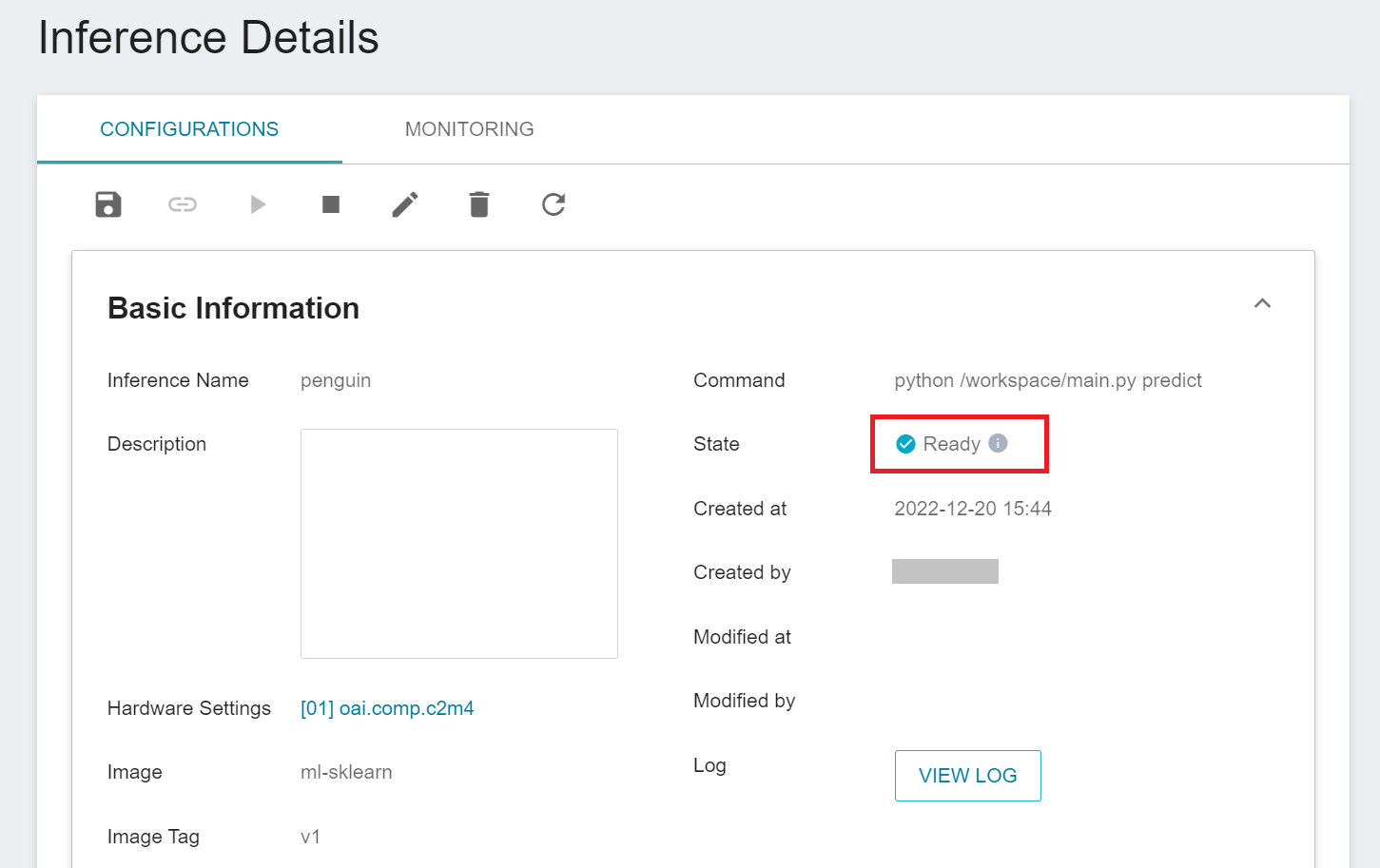
You can also click **VIEW LOG**. If you see the following message in the log, the inference service is already running.
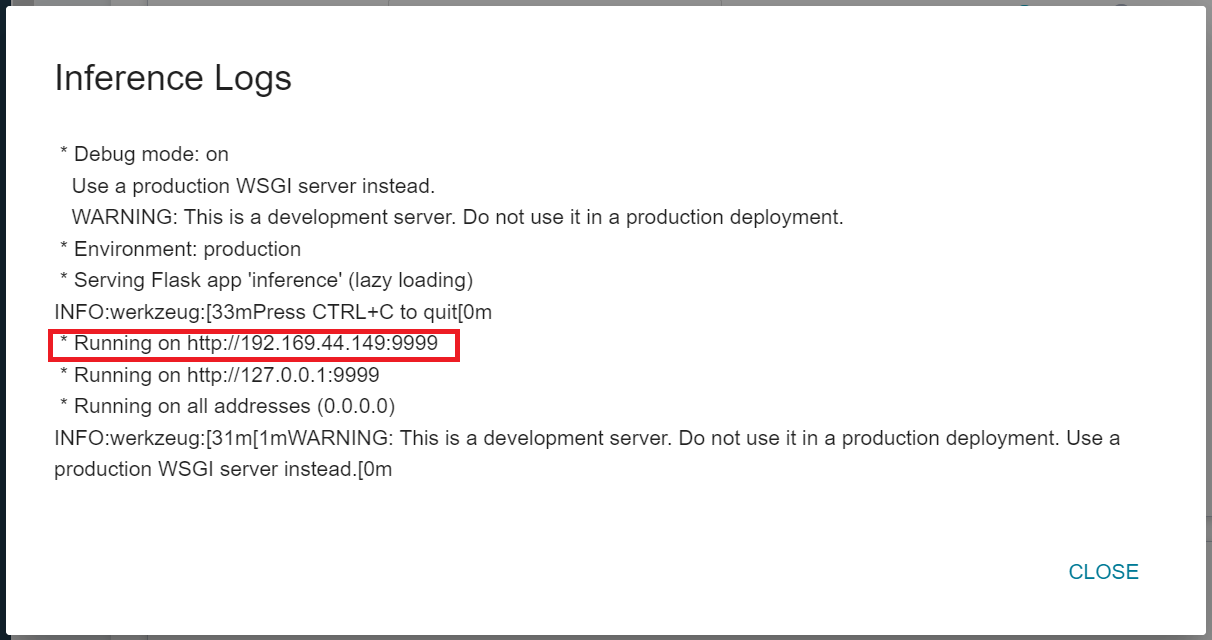
Note that the URL http://{ip}:{port} displayed in the log is only the internal URL of the inference service and is not accessible from outside. Since the current inference service does not have a public service port for security reasons, we can communicate with the inference service we created through the **Notebook Service**. The way to communicate is through the **Network** Block displayed at the bottom of the **Inference Details** page.
:::warning
:warning: **Please note:** The URLs in the document are for reference only, and the URLs you got may be different.
:::
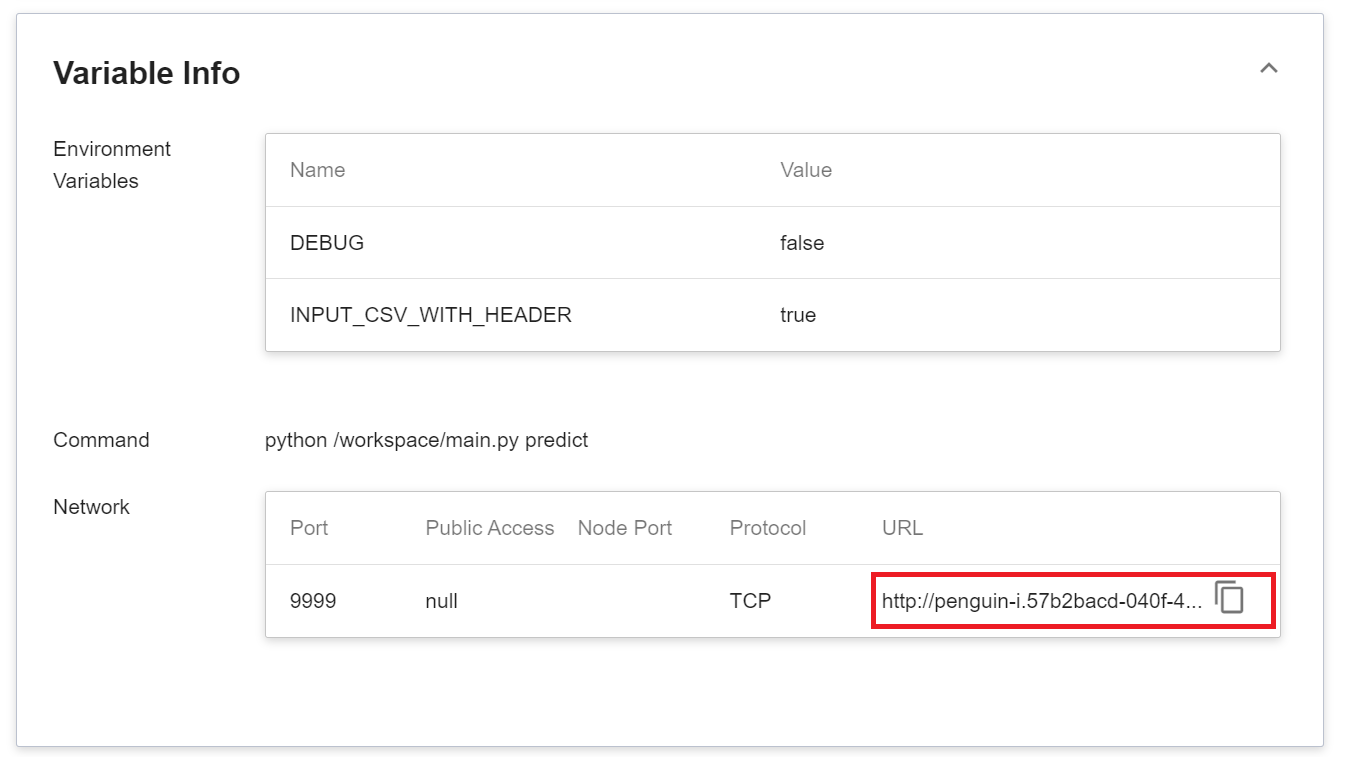
:::info
:bulb: **Tips: Inference Service URL**
- For security reasons, the **URL** provided by the inference service can only be used in the system's internal network, and cannot be accessed through the external Internet.
- To provide this Inference Service externally, please refer to [**AI Maker > Provide External Service**](/s/ai-maker-en#Making-Inference) for instructions.
:::
To view inference monitoring, you can click the **Monitoring** tab to see relevant information on the monitoring page. After a period of time, the monitoring page can display the statistics of calls to the inference service API in the past period.
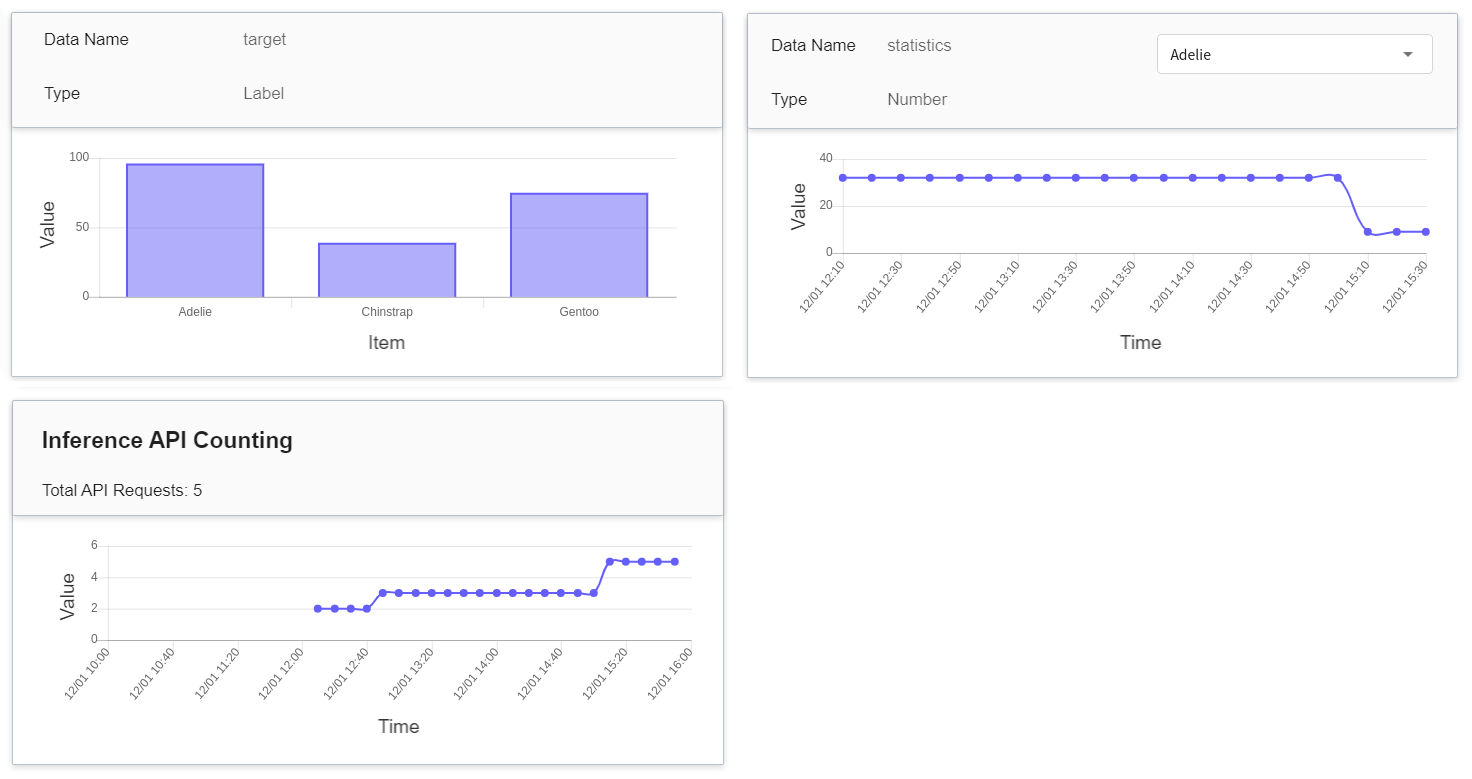
Click the Period menu to filter the statistics of the Inference API Call for a specific period, for example: 1 hour, 3 hours, 6 hours, 12 hours, 1 day, 7 days, 14 days, 1 month, 3 months, 6 months, 1 year, or custom.

:::info
:bulb: **About the start and end time of the observation period**
For example, if the current time is 15:10, then.
- **1 Hour** refers to 15:00 ~ 16:00 (not the past hour 14:10 ~ 15:10)
- **3 Hours** refers to 13:00 ~ 16:00
- **6 Hours** refers to 10:00 AM ~ 16:00
- And so on.
:::
### 3.3 Establish Client
After starting the inference service, you can create a client through [**Notebook Service**](/s/notebook-en) for inference.
1. When creating a notebook service, the development framework chooses a name ending with `-py`, such as `PyTorch-22.08-py3`, `TensorFlow-22.08-tf2-py3`, etc. The development framework provides a python environment, which can be accessed through python to carry out inferences.
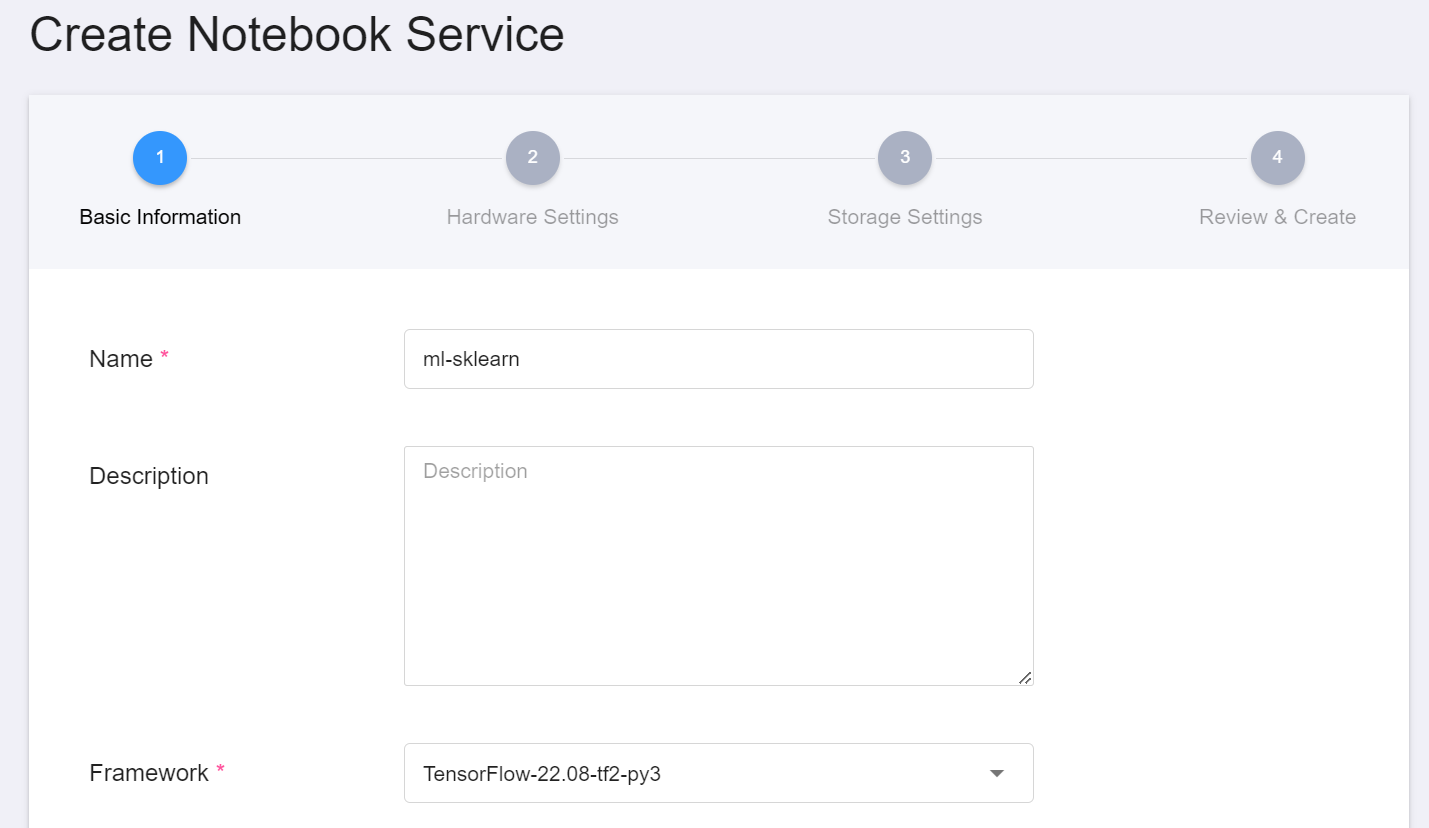
2. In addition, the dataset to perform inference also needs to be hooked into the notebook service.
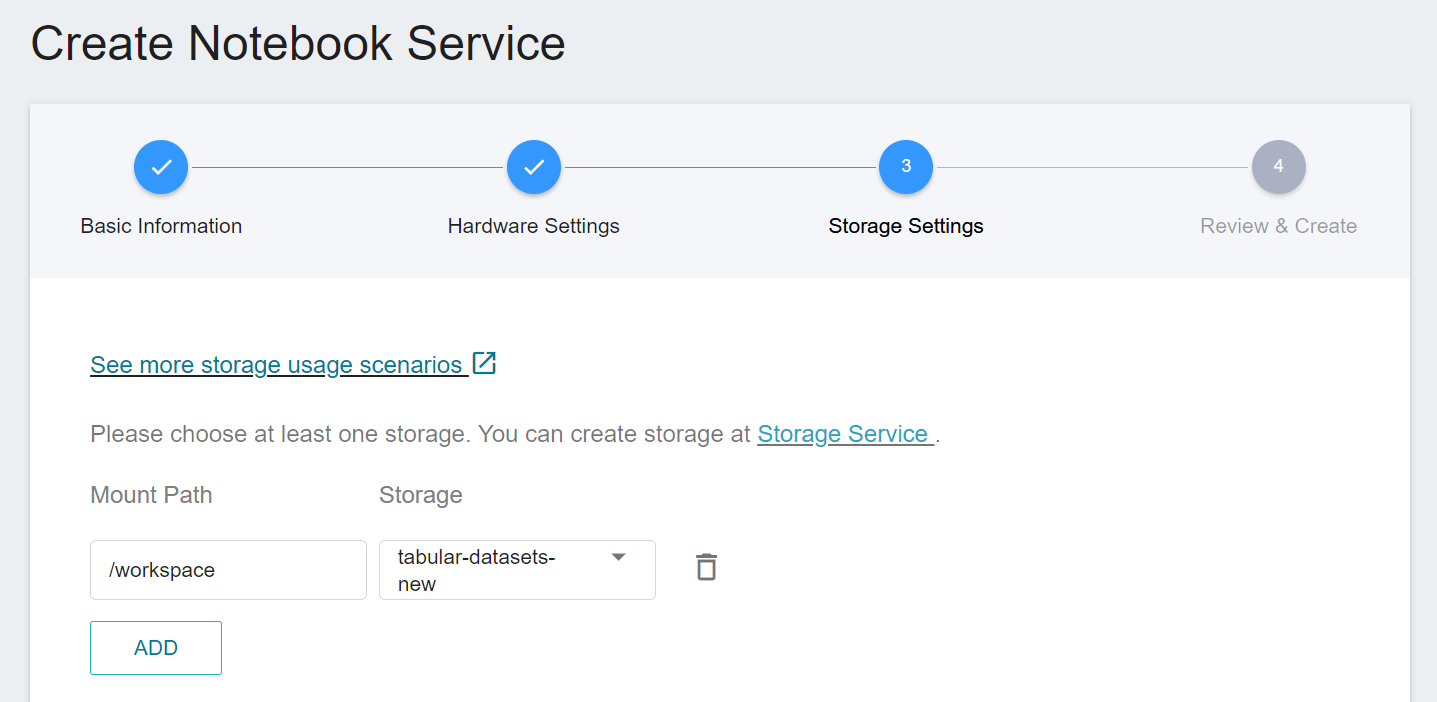
3. When the status of the notebook service is Ready, click to launch Jupyterlab.
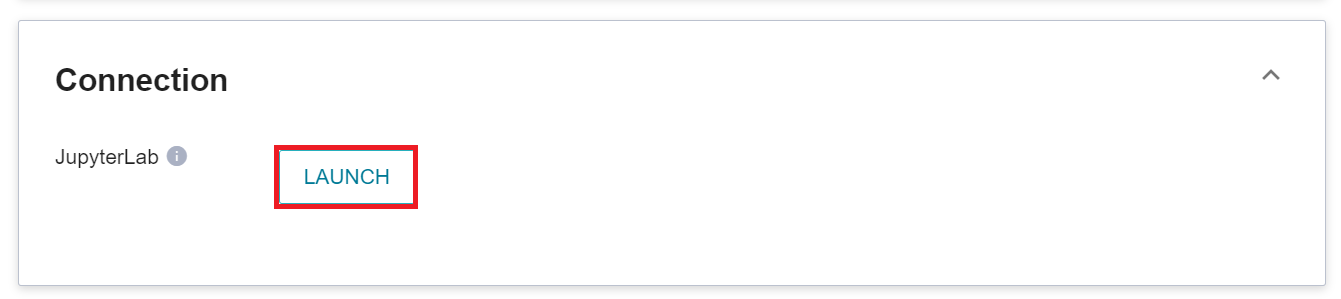
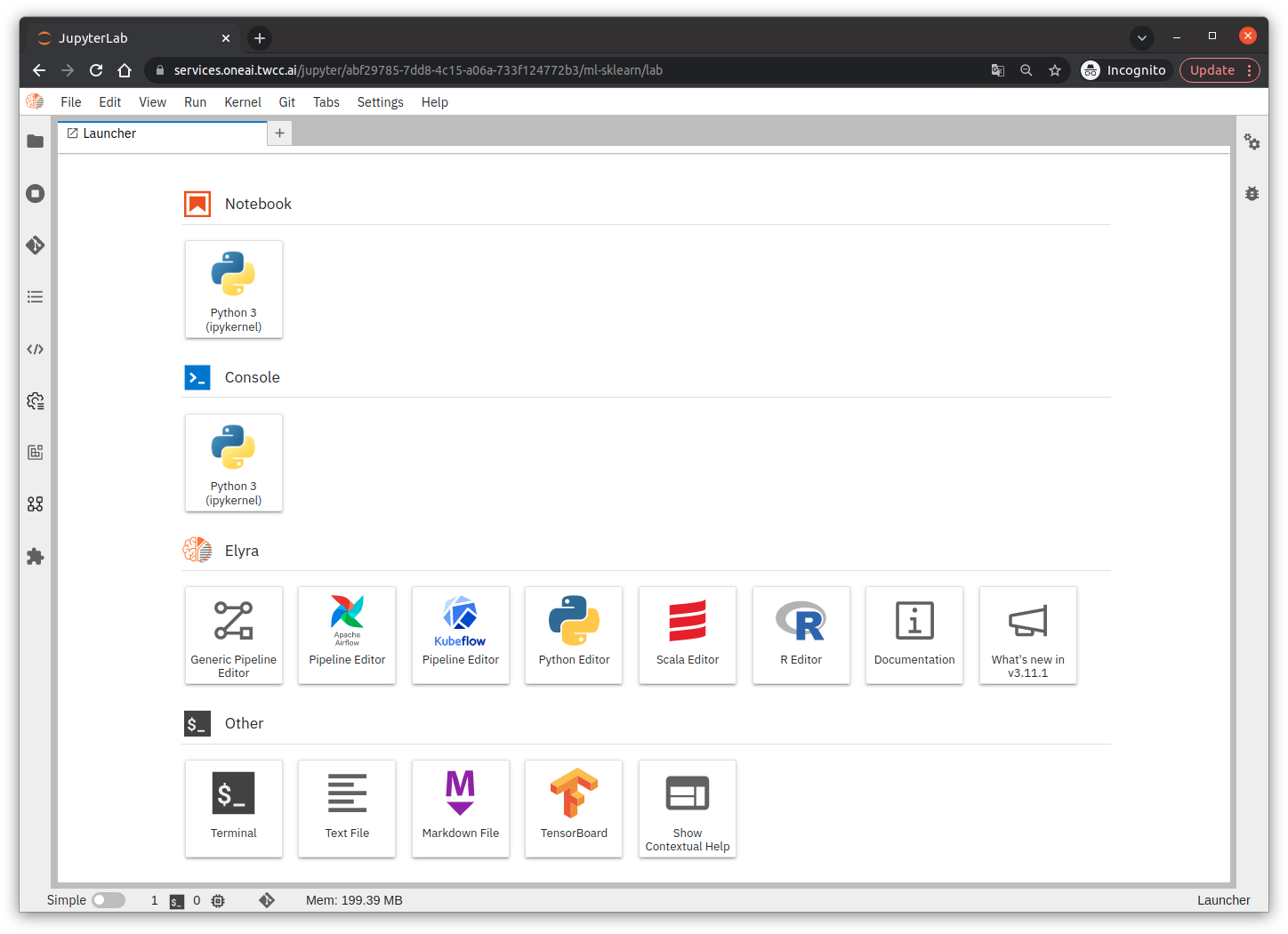
### 3.4 Test Inference Service with Curl Command
After logging in to JupyterLab, click the **Terminal** icon at the bottom of the **Launcher** page to open the **Terminal**.
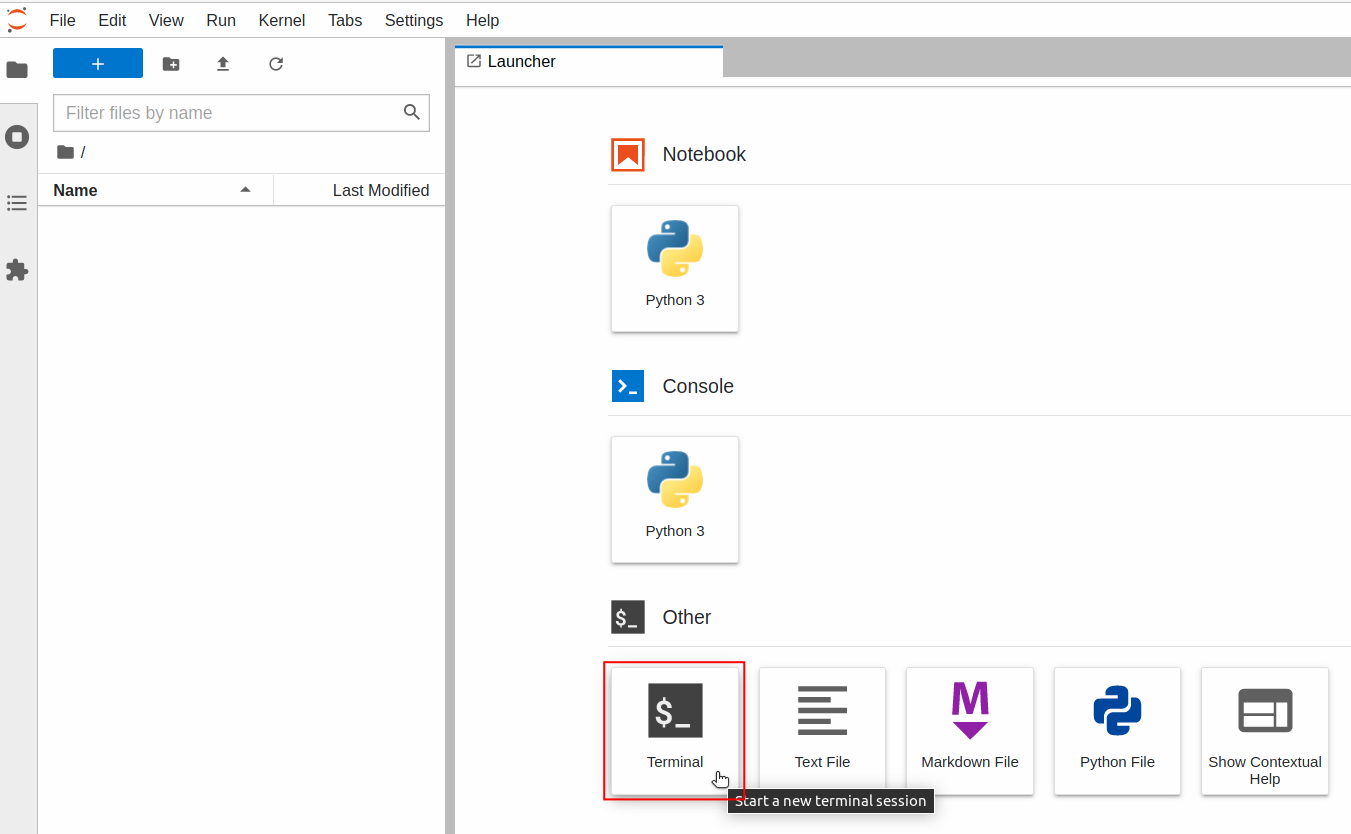
Enter the **`curl`** command in the **Terminal** to confirm that the inference service starts normally.
```bash=
# "penguin-i.abf29785-7dd8-4c15-a06a-733f124772b3:9999" is the URL for inference service
$> curl http://penguin-i.abf29785-7dd8-4c15-a06a-733f124772b3:9999/hello
Hello, this is ml-sklearn!
# or
$> curl -X GET http://penguin-i.abf29785-7dd8-4c15-a06a-733f124772b3:9999/hello
Hello, this is ml-sklearn!
```
If the service starts successfully, you can call the `predict` API to make inferences.
```bash=
$> curl -X POST \
penguin-i.abf29785-7dd8-4c15-a06a-733f124772b3:9999/predict \
-F file=@/workspace/penguin/test_x.csv \
-F INPUT_CSV_WITH_HEADER=true
```
Here:
- **`-X POST`**
Indicates that the HTTP request method is POST.
- **`-F file=@<the location of the dataset on the local side>`**
Indicates that the local dataset file is to be uploaded to the inference service for inference;
You can use either `train_x.csv` or `test_x.csv` as the dataset file for the test.
- **`-F INPUT_CSV_WITH_HEADER=true`**
Indicates that in the uploaded dataset, the first row has field names.
(Please refer to the description of [**INPUT_CSV_WITH_HEADER**](#INPUT_CSV_WITH_HEADER) variable setting)
When the inference service receives the dataset, it will perform predict, and finally return the inference results of the dataset.
```json
{
"y_pred": [
"Adelie",
"Adelie",
...
"Chinstrap",
"Chinstrap",
...
"Gentoo",
"Gentoo",
...
]
}
```
### 3.5 Using Python's `requests` Module to Test Inference Service
In addition to using the Terminal command to test, you can also test the inference service through the Python environment and by executing the Python code below.
Click the **Notebook > Python 3** icon at the top of the JupyterLab Launcher page to open **Notebook**.
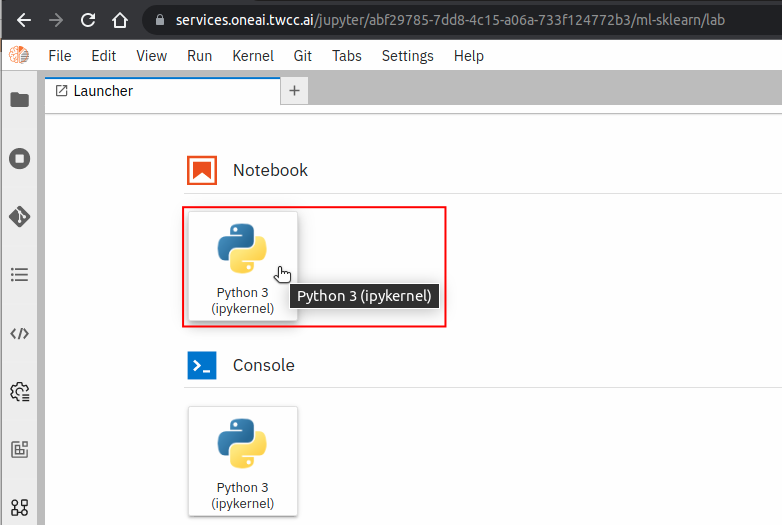
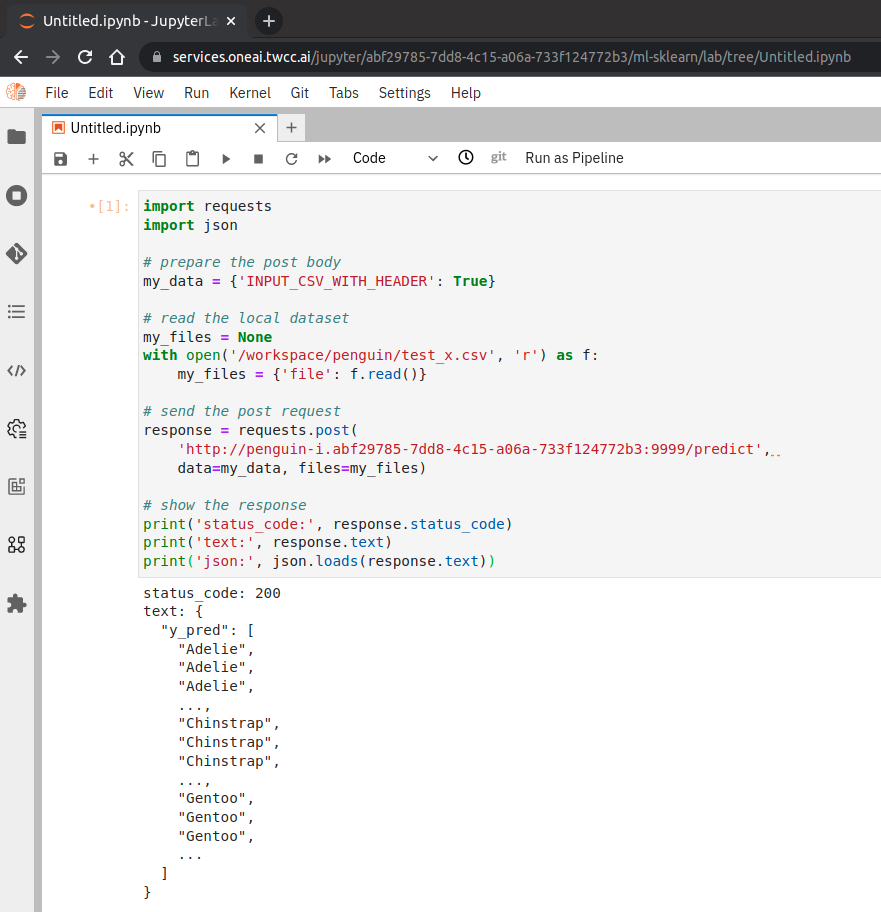
Use the **`requests`** module to test online:
```python=
import requests
import json
# prepare the post body
my_data = {'INPUT_CSV_WITH_HEADER': True}
# read the local dataset
my_files = None
with open('/workspace/penguin/test_x.csv', 'r') as f:
my_files = {'file': f.read()}
# send the post request
response = requests.post(
'http://penguin-i.abf29785-7dd8-4c15-a06a-733f124772b3:9999/predict',
data=my_data, files=my_files)
# show the response
print('status_code:', response.status_code)
print('text:', response.text)
print('json:', json.loads(response.text))
```
Execution result:
```
status_code: 200
text: {
"y_pred": [
"Adelie",
"Adelie",
...
]
}
json: {'y_pred': ['Adelie', 'Adelie', ...]}
```
:::spoiler Complete code Including: installing related packages, sending requests, accepting responses, and calculating accuracy indicators based on responses)
```python=
import os
# install related packages (if needed):
os.system('pip install requests')
import requests
import json
# prepare the post body
my_data = {'INPUT_CSV_WITH_HEADER': True}
# read the local dataset
my_files = None
with open('/workspace/penguin/test_x.csv', 'r') as f:
my_files = {'file': f.read()}
# send the post request
response = requests.post(
'http://penguin-i.abf29785-7dd8-4c15-a06a-733f124772b3:9999/predict',
data=my_data, files=my_files)
# show the response
print('status_code:', response.status_code)
print('text:', response.text)
print('json:', json.loads(response.text))
# ---
# calculate the evaluation metric: accuracy
# install related packages (if needed):
os.system('pip install pandas')
os.system('pip install scikit-learn')
import pandas
from sklearn.metrics import accuracy_score
df_y_true = pandas.read_csv(
'/workspace/penguin/test_y.csv',
header=0)
y_true = df_y_true.values
y_pred = json.loads(response.text)['y_pred']
accuracy = accuracy_score(y_true, y_pred)
print('accuracy: %.2f%%' % (accuracy * 100))
```
:::
## 4. [Advanced Operations] Adjust the Parameters of Algorithm
:::info
:bulb:**Tips:** This section is for advanced operations. If the machine learning result does not meet the expectation and you want to further set or adjust the algorithm parameters, you can refer to the description here.
:::
Section [**2.1.4 Variable Settings**](#214-Variable-Settings) has mentioned the [**Algorithm (MODEL_ALGORITHM)**](#MODEL_ALGORITHM) to be used for machine learning. When the default parameters of the algorithm or the training results do not meet the actual requirements, for example:
1. If you want to spend more time finding the optimal algorithm and hyperparameters, you need to increase the calculation time.
2. The number of iterations is not enough, and the model cannot be fit and finalized, and the number of iterations needs to be increased.
3. There are different calculation methods in a single algorithm, and you want to choose different calculation methods to fit the data.
4. To use a polynomial-based algorithm which can increase the complexity of the model by changing the power (exponential part).
5. Change the penalty level (penalty points)...etc.
Based on needs, parameters can be adjusted to meet actual requirements. The parameter adjustment is also known as hyerparameter adjustment (tuning).
### 4.1 Parameter Adjustment Method
On the [**Variable Settings**](#214-Variable-Settings) page, add one or more sets of key values to change the default parameters of the model algorithm.
### 4.2 Parameter Syntax Rule
The rule for setting the algorithm parameters is: the entered [**MODEL_ALGORITHM**](#MODEL_ALGORITHM) value, plus the **parameter name** and **parameter value**.
Template:
```
{MODEL_ALGORITHM}_param_{parameter name}: {parameter value}
```
:::info
:pencil: **Example 1**
- Algorithm name: `AutoSklearn`
- Parameter 1
- Name: `time_left_for_this_task`
- Value: `60*5` (total execution time, limited to 5 minutes)
- Parameter 2
- Name: `per_run_time_limit`
- Value: `30` (single test time, limited to 30 Sec)<br><br>
After applying the above template, it becomes:
```
AutoSklearn_param_time_left_for_this_task: 60*5
AutoSklearn_param_per_run_time_limit: 30
```
And set it as an environment variable:

:::
:::info
:pencil: **Example 2**
- Algorithm category: `AutoSklearnClassifier`
- Parameter 1
- Name: `time_left_for_this_task`
- Value: `60*5` (total execution time, limited to 5 minutes)
- Parameter 2
- Name: `per_run_time_limit`
- Value: `30` (single test time, limited to 30 Sec)<br><br>
After applying the above template, it becomes:
```
AutoSklearnClassifier_param_time_left_for_this_task: 60*5
AutoSklearnClassifier_param_per_run_time_limit: 30
```
And set it as an environment variable:

:::
The **name** of each algorithm, and its corresponding **class** and **parameter description** are listed below:
| Algorithm name | Algorithm category | Parameter description<br>(parameter name & parameter value) |
| --------------------- | -------- | -------- |
| `Auto` | [^Note 1^](#footnote_auto_algorithm_class) | - |
| `AutoSklearn` | AutoSklearnClassifier | [View parameter](https://automl.github.io/auto-sklearn/master/api.html) |
| `AutoGluon` | AutoGluonClassifier | View parameter: [init](https://auto.gluon.ai/0.1.0/api/autogluon.task.html#autogluon.tabular.TabularPredictor), [fit](https://auto.gluon.ai/0.1.0/api/autogluon.task.html#autogluon.tabular.TabularPredictor.fit) [^Note 2^](#footnote_autogluon_parameters) |
| `AdaBoost` | AdaBoostClassifier | [View parameter](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html) |
| `ExtraTree` | ExtraTreeClassifier | [View parameter](https://scikit-learn.org/stable/modules/generated/sklearn.tree.ExtraTreeClassifier.html) |
| `DecisionTree` | DecisionTreeClassifier | [View parameter](https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html) |
| <span style="white-space: nowrap">`GradientBoosting`</span> | GradientBoostingClassifier | [View parameter](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html) |
| `KNeighbors` | KNeighborsClassifier | [View parameter](https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html) |
| `LightGBM` | LGBMClassifier | [View parameter](https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.LGBMClassifier.html) |
| <span style="white-space: nowrap">`LogisticRegression`</span> | LogisticRegression | [View parameter](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) |
| `RandomForest` | RandomForestClassifier | [View parameter](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html) |
| `SGD` | SGDClassifier | [View parameter](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassifier.html) |
| `SVM` | SVC | [View parameter](https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html) |
| `XGBoost` | XGBClassifier | [View parameter](https://xgboost.readthedocs.io/en/latest/python/python_api.html#xgboost.XGBClassifier) |
- <span id="footnote_auto_algorithm_class"></span>**Note 1**: Not recommended, users need to know whether `Auto` is dynamically bound to `AutoSklearnClassifier` or `AutoGluonClassifier` during execution?
- Without GPU environment, `Auto` is bound to `AutoSklearnClassifier`
- With GPU environment, `Auto` is bound to `AutoGluonClassifier`
- <span id="footnote_autogluon_parameters"></span>**Note 2**: AutoGluon currently uses preset parameters.
- There are two sources of parameters for adjustment:
- One source is [init parameter](https://auto.gluon.ai/0.1.0/api/autogluon.task.html#autogluon.tabular.TabularPredictor);
- Another source is [fit parameter](https://auto.gluon.ai/0.1.0/api/autogluon.task.html#autogluon.tabular.TabularPredictor.fit).
- To limit the total execution time, you can do the following:
- Use the algorithm name
```
AutoGluon_param_time_limit: 60*5
```
- Explicitly specify the algorithm category
```
AutoGluonClassifier_param_time_limit: 60*5
```
- <span id="footnote_experimental_algorithm_name"></span>**Q & A**:
- **How to set parameters for machine learning algorithms that are not in the above table?**
To use a machine learning algorithm that is not in the above table, the user needs to explicitly specify the [**algorithm category**](#footnote_experimental_algorithm_class_list) provided by the `ml-sklearn` image. Using the algorithm category as a keyword, find the corresponding algorithm category in the official [**scikit-learn documentation**](https://scikit-learn.org/stable/modules/classes.html), and then click to find the parameters that can be used by the algorithm category.<br>
For example, if you want to use `MLPClassifier`, you can find it by searching for keywords on this page, as follows:

Then click again, you can see the relevant parameter usage.

### 4.3 Practical Examples
The first example will be used to describe the actual operation process; the subsequent examples will be briefly explained.
#### 4.3.1 If You Want to Spend More Time Finding the Optimal Algorithm And Hyperparameters, You Need to Increase the Calculation Time.
This section is a supplementary note for when [**MODEL_ALGORITHM**](#MODEL_ALGORITHM) is set to the `Auto` option. In the [**parameter description**](https://automl.github.io/auto-sklearn/master/api.html) of **AutoClassifier**, it is mentioned:
- **`time_left_for_this_task` (total time for the task)**
> The preset time is 3600 seconds (1 hour) in seconds.
>
> The total time limit for searching for the best model. By increasing this value, AutoClassifier is more likely to find a better model.
- **`per_run_time_limit` (time limit for a single execution)**
> The preset time is 360 seconds (6 minutes) in seconds.
>
> Time limit for a single test with a selected model and a set of parameters.
>
> Some algorithms (such as MLP) may take longer to fit the model in a single test, and once the execution time exceeds the default 6 minutes, the algorithm is marked as a failure and is not included in the list of reference models.
When should this parameter be adjusted?
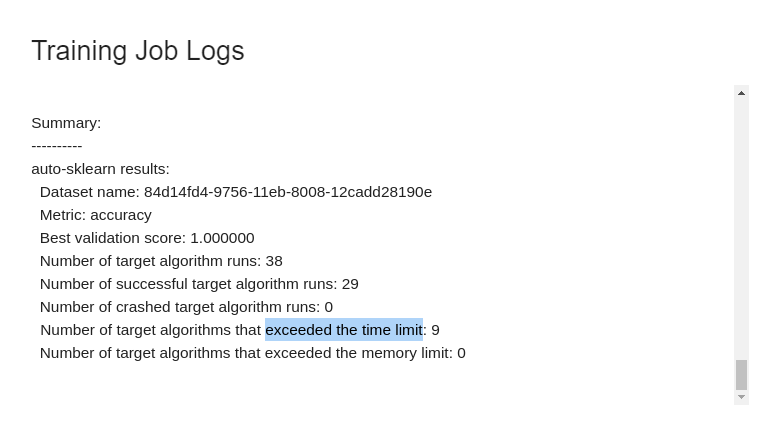
> See [**2.3.2 Machine Learning Execution Logs**](#232-Machine-Learning-Execution-Logs) section to learn how to view logs. When the proportion of time-out algorithms is too high, we can consider relaxing the time limit for a single execution without considering time and other costs.
> 
To increase the calculation time, you can do the following:
| Parameter | Settings Value | Description |
| --- | ----- | --- |
| `AutoClassifier_param_time_left_for_this_task` | `60*60*24` | in seconds.<br> The total time is set to 24 hours, or `86400`. |
| `AutoClassifier_param_per_run_time_limit` | `60*30` | in seconds.<br> The single test time is set to 30 minutes, or `1800`. |
In the **Environment Variables** table of the [**Variable Settings**](#214-variable-settings) stage, actually enter two key values:
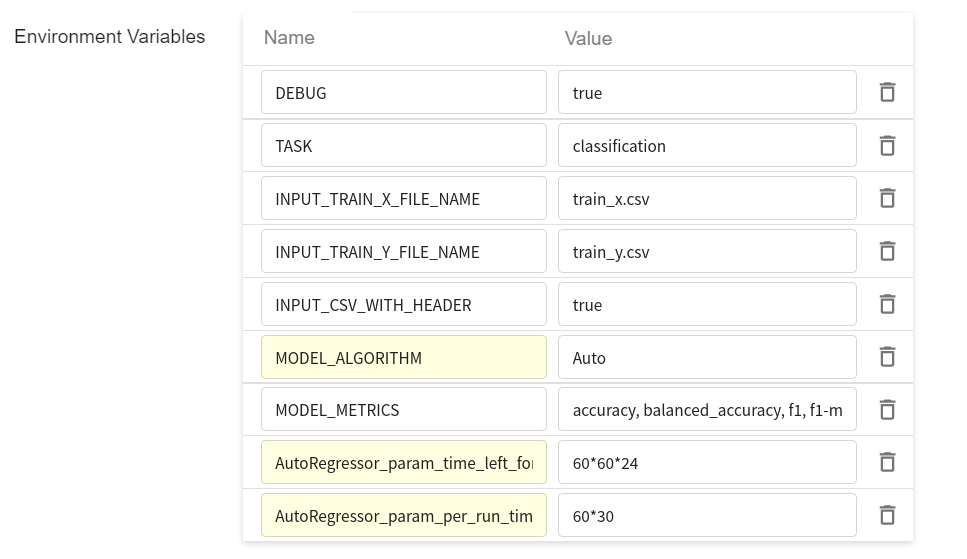
Training jobs that are started subsequently will use this setting.
:::info
:bulb: **Tips: More Settings and Configurations**
In the section 2.1.2 [**Hardware Settings**](#212-Hardware-Settings), there are references to hardware resources for your own needs. To make use of the allocated hardware resources, you can do the following:
| Parameter | Settings Value | Description |
| --- | ----- | --- |
| `AutoClassifier_param_n_jobs` | `-1` | Use all CPUs. The original default is a single core. |
| `AutoClassifier_param_memory_limit`|`1024*40` |Increase the memory limit to 40GB to handle millions of table data.|
:::
:::warning
:warning: **Note:**
The setting of algorithm parameters must be used together with the **`MODEL_ALGORITHM`** parameter; otherwise, the setting of algorithm parameters will be ignored.
:::
#### 4.3.2 The Number of Iterations Is Not Enough, the Model Cannot Be Fit And Finalized, And the Number of Iterations Needs to Be Increased.
| Parameter | Settings Value | Description |
| --- | ----- | --- |
| `LogisticRegression_param_max_iter` | `500` | The default value of LogisticRegression is 100. |
| `SGDClassifier_param_max_iter` | `5000` | The default value of SGDClassifier is 1000. |
#### 4.3.3 There Are Different Calculation Methods in A Single Algorithm, And You Want to Choose Different Calculation Methods to Fit the Data
| LogisticRegression parameter | Settings Value | Description |
| ---------------------- | ----- | --- |
| `LogisticRegression_param_solver` | `liblinear` | Set the LogisticRegression solution method to `liblinear` |
| `LogisticRegression_param_solver` | `sag` | Set the LogisticRegression solution method to `sag` |
| `LogisticRegression_param_solver` | `saga` | Set the LogisticRegression solution method to `saga` |
| SVC parameter | Settings Value | Description |
| ------- | ----- | --- |
| `SVC_param_kernel` | `linear` | Set the kernelof SVC (SVM) to `linear` |
| `SVC_param_kernel` | `poly` | Set the kernel of SVC (SVM) to `poly` |
| `SVC_param_kernel` | `sigmoid` | Set the kernel of SVC (SVM) to `sigmoid` |
<br>
#### 4.3.4 To Use A Polynomial-based Algorithm Which Can Increase the Complexity of the Model by Changing the Power (Exponential Part).
For SVC settings, the following 3 settings are grouped together and need to be used together:
| SVC parameter | Settings Value | Description |
| ------- | ----- | --- |
| `MODEL_ALGORITHM` | `SVM` | Using SVM algorithm |
| `SVC_param_kernel` | `poly` | Set the kernel of SVC (SVM) to `poly` |
| `SVC_param_degree` | `5` | Change the power of [polynomial](https://zh.wikipedia.org/wiki/%E5%A4%9A%E9%A0%85%E5%BC%8F) from default of 3 to 5 |
#### 4.3.5 Change the Penalty Level (Penalty Points)
Penalty is also known as regularization term, the generally available selections are L1, L2, and ElasticNet.
| Parameter | Settings Value | Description |
| --- | ----- | --- |
| `SGDClassifier_param_penalty` | `elasticnet` | |
| `SVC_param_C` | `2` | Set the penalty coefficient from the default of `1` to `2`; the higher the value of `C`, the less tolerance for errors, but it may overfit. |
For LogisticRegression settings, the following 4 settings are grouped together and need to be used together:
| LogisticRegression parameter | Settings Value | Description |
| ---------------------- | ----- | --- |
| `MODEL_ALGORITHM` | `LogisticRegression` | Using LogisticRegression algorithm |
| `LogisticRegression_param_solver` | `saga` | Set the solution method to `saga` |
| `LogisticRegression_param_penalty` | `elasticnet` | Need to use with `saga` |
| `LogisticRegression_param_l1_ratio` | `0.5` | Need to use with `elasticnet` |
If not used together, the training job will fail() and the log will have the following error message:
```
ValueError: Solver lbfgs supports only 'l2' or 'none' penalties,
got elasticnet penalty.
```
```
ValueError: l1_ratio must be between 0 and 1;
got (l1_ratio=None)
```