---
description: OneAI Documentation
tags: Case Study, YOLO, CVAT, EN
---
[OneAI Documentation](/s/user-guide-en)
# AI Maker Case Study - YOLOv7 Image Recognition Application
[TOC]
## 0. Deploy YOLOv7 Image Recognition Application
In this example, we will build a YOLO image recognition application from scratch using the **`yolov7`** template provided by AI Maker for YOLOv7 image recognition application. The system provides **`yolov7`** template with pre-defined environment variables, image, programs and other settings for each stage of the task, from training to inference, so that you can quickly develop your own YOLO network.
The main steps are as follows:
1. [**Prepare the Dataset**](#1-Prepare-the-Dataset)
At this stage, we need to prepare the image dataset and annotation data for machine learning training and upload it to the specified location.
2. [**Data Annotation**](#2-Data-Annotation)
At this stage, we will annotate objects in the image, and these annotations will later be used to train the neural network.
3. [**Training YOLO Model**](#3-Training-YOLO-Model)
At this stage, we will configure the relevant training job to train and fit the neural network, and store the trained model.
4. [**Create Inference Service**](#4-Create-Inference-Service)
At this stage, we deploy the stored model and make inferences.
5. [**Perform Image Recognition**](#5-Perform-Image-Recognition)
At this stage, we will demonstrate how to send inference requests using the Python language in JupyterLab.
6. [**CVAT Assisted Annotation**](#6-CVAT-Assisted-Annotation)
At this stage, we will demonstrate how to use CVAT Assisted Annotation function to save time in manual annotation.
## 1. Prepare the Dataset
The YOLOv7 model must be trained on labeled data to learn the object categories in that data. The following will explain the preparation methods of the two materials.
### 1.1 Upload Your Own Dataset
First, prepare the training datasets, such as: cats, dogs, people, etc. Follow the steps below to upload the dataset to the Storage Service provided by the system, and store the dataset according to the specified directory structure for subsequent development.
1. **Create a Bucket**
Select **Storage Service** from the OneAI services to enter the Storage Service Management page, and then click **+CREATE** to add a bucket such as **yolo-dataset**. This bucket is used to store your dataset.
2. **View Bucket**
After the bucket is created, go back to the Storage Service Management page, and you will see that the bucket has been created.
3. **Upload Dataset**
Click the created bucket, and then click **UPLOAD** to start uploading the dataset. (See [**Storage Service**](/s/storage-en) Description).
### 1.2 Upload Your Own Dataset and Annotated Dataset
Please refer to the instructions in this chapter to prepare and upload the annotated dataset.
#### 1.2.1 Prepare Your Own Dataset
This example will use the [**COCO128 dataset**](https://www.kaggle.com/datasets/ultralytics/coco128) of the Kaggle website as an example. This dataset is the first 128 pictures in [**COCO train 2017**](https://cocodataset.org/#explore), including pictures and annotated data, please download this dataset to your local machine and unzip it.
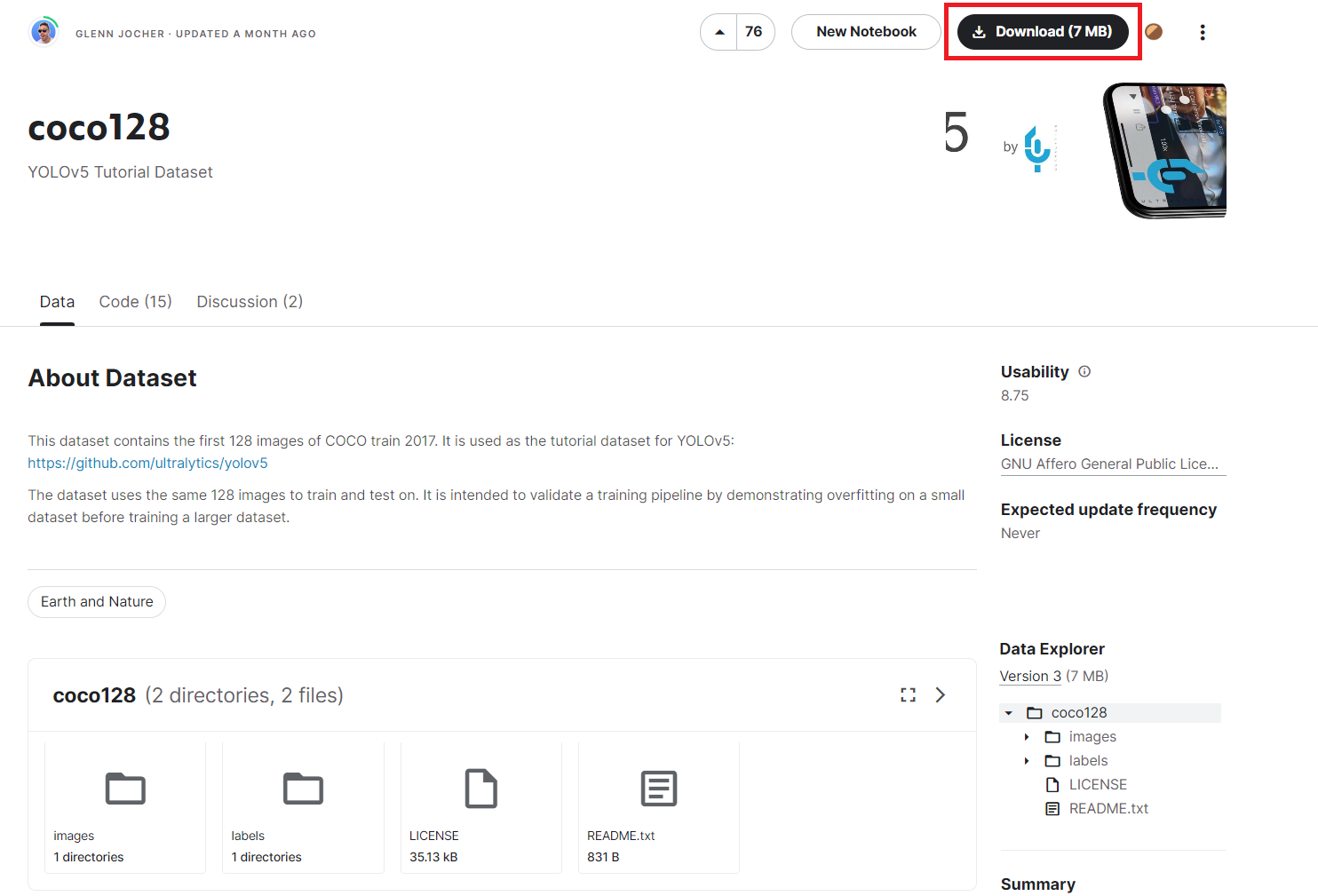
After decompression, you will see **images** and **labels** two folders in the **coco128** folder, where the **images** folder contains training pictures, and the **labels** folder stores text files of label data.
#### 1.2.2 Add **data.yaml** File
Define the class number and class names. There are 80 object classes in the [**COCO128 dataset**](https://www.kaggle.com/datasets/ultralytics/coco128). So we will add **data.yaml** in the **coco128** folder to define the relevant information required by the model training program.
- **`train: ./train.txt`**: Defines the file for training.
- **`val: ./val.txt`**: Defines the file for validation.
- **`test: ./test.txt`**: Defines the file for testing.
- **`nc`** and **`names`**: Defines the number of object class and corresponding names.
```yaml=
train: ./train.txt
val: ./val.txt
test: ./test.txt #optional
# number of classes
nc: 80
# class names
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ]
```
#### 1.2.3 Prepare Text Files for Labeling Data
[**COCO128 Dataset**](https://www.kaggle.com/datasets/ultralytics/coco128) used in this example has provided text files of labeled data. If you use your own dataset, please store the text file of the label data corresponding to each image file in the **labels** folder. The content of the text file must be in accordance with the YOYO format, which is described from left to right as follows:
```
3 0.716912 0.650000 0.069118 0.541176
```
| Content | Description |
| -------- | -------- |
| 3 | Represents the class ID of the annotated object. |
| 0.716912 | The ratio of the center coordinate X of the bounding box to the image width, which is the normalized center coordinate X of the bounding box. |
| 0.650000 | The ratio of the center coordinate Y of the bounding box to the image width, which is the normalized center coordinate Y of the bounding box. |
| 0.069118 | The ratio of the width of the bounding box to the width of the input image, which is the normalized width coordinate of the bounding box. |
| 0.541176 | The ratio of the height of the bounding box to the height of the input image, which is the normalized height coordinate of the bounding box. |
Then we will create three file lists of **train.txt**, **val.txt** and **test.txt** in the **coco128** folder according to the list of image files in the images folder, as train, validate and test purposes.
#### 1.2.4 Add **train.txt** File
For 80% of all images in the file name list (or other ratios, can be changed on demand), YOLO will read the contents of the file in order to retrieve the photos for training, and the contents of the file will be linked to the image location with relative paths.
:::spoiler **train.txt**
```=
./images/train2017/000000000133.jpg
./images/train2017/000000000136.jpg
./images/train2017/000000000138.jpg
./images/train2017/000000000142.jpg
./images/train2017/000000000143.jpg
./images/train2017/000000000144.jpg
./images/train2017/000000000149.jpg
./images/train2017/000000000151.jpg
./images/train2017/000000000154.jpg
./images/train2017/000000000164.jpg
./images/train2017/000000000165.jpg
./images/train2017/000000000192.jpg
./images/train2017/000000000194.jpg
./images/train2017/000000000196.jpg
./images/train2017/000000000201.jpg
./images/train2017/000000000208.jpg
./images/train2017/000000000241.jpg
./images/train2017/000000000247.jpg
./images/train2017/000000000250.jpg
./images/train2017/000000000257.jpg
./images/train2017/000000000260.jpg
./images/train2017/000000000263.jpg
./images/train2017/000000000283.jpg
./images/train2017/000000000294.jpg
./images/train2017/000000000307.jpg
./images/train2017/000000000308.jpg
./images/train2017/000000000309.jpg
./images/train2017/000000000312.jpg
./images/train2017/000000000315.jpg
./images/train2017/000000000321.jpg
./images/train2017/000000000322.jpg
./images/train2017/000000000326.jpg
./images/train2017/000000000328.jpg
./images/train2017/000000000332.jpg
./images/train2017/000000000338.jpg
./images/train2017/000000000349.jpg
./images/train2017/000000000357.jpg
./images/train2017/000000000359.jpg
./images/train2017/000000000360.jpg
./images/train2017/000000000368.jpg
./images/train2017/000000000370.jpg
./images/train2017/000000000382.jpg
./images/train2017/000000000384.jpg
./images/train2017/000000000387.jpg
./images/train2017/000000000389.jpg
./images/train2017/000000000394.jpg
./images/train2017/000000000395.jpg
./images/train2017/000000000397.jpg
./images/train2017/000000000400.jpg
./images/train2017/000000000404.jpg
./images/train2017/000000000415.jpg
./images/train2017/000000000419.jpg
./images/train2017/000000000428.jpg
./images/train2017/000000000431.jpg
./images/train2017/000000000436.jpg
./images/train2017/000000000438.jpg
./images/train2017/000000000443.jpg
./images/train2017/000000000446.jpg
./images/train2017/000000000450.jpg
./images/train2017/000000000459.jpg
./images/train2017/000000000471.jpg
./images/train2017/000000000472.jpg
./images/train2017/000000000474.jpg
./images/train2017/000000000486.jpg
./images/train2017/000000000488.jpg
./images/train2017/000000000490.jpg
./images/train2017/000000000491.jpg
./images/train2017/000000000502.jpg
./images/train2017/000000000508.jpg
./images/train2017/000000000510.jpg
./images/train2017/000000000514.jpg
./images/train2017/000000000520.jpg
./images/train2017/000000000529.jpg
./images/train2017/000000000531.jpg
./images/train2017/000000000532.jpg
./images/train2017/000000000536.jpg
./images/train2017/000000000540.jpg
./images/train2017/000000000542.jpg
./images/train2017/000000000544.jpg
./images/train2017/000000000560.jpg
./images/train2017/000000000562.jpg
./images/train2017/000000000564.jpg
./images/train2017/000000000569.jpg
./images/train2017/000000000572.jpg
./images/train2017/000000000575.jpg
./images/train2017/000000000581.jpg
./images/train2017/000000000584.jpg
./images/train2017/000000000589.jpg
./images/train2017/000000000590.jpg
./images/train2017/000000000595.jpg
./images/train2017/000000000597.jpg
./images/train2017/000000000599.jpg
./images/train2017/000000000605.jpg
./images/train2017/000000000612.jpg
./images/train2017/000000000620.jpg
./images/train2017/000000000623.jpg
./images/train2017/000000000625.jpg
./images/train2017/000000000626.jpg
./images/train2017/000000000629.jpg
./images/train2017/000000000634.jpg
./images/train2017/000000000636.jpg
./images/train2017/000000000641.jpg
./images/train2017/000000000643.jpg
./images/train2017/000000000650.jpg
```
:::
#### 1.2.5 Add **val.txt** File
For 20% of all images in the file name list (or other ratios, can be changed on demand), YOLO will read the contents of the file in order to retrieve the photos validation, and the contents of the file will be linked to the image location with relative paths.
:::spoiler **val.txt**
```=
./images/train2017/000000000074.jpg
./images/train2017/000000000077.jpg
./images/train2017/000000000078.jpg
./images/train2017/000000000081.jpg
./images/train2017/000000000086.jpg
./images/train2017/000000000089.jpg
./images/train2017/000000000092.jpg
./images/train2017/000000000094.jpg
./images/train2017/000000000109.jpg
./images/train2017/000000000110.jpg
./images/train2017/000000000113.jpg
./images/train2017/000000000127.jpg
```
:::
#### 1.2.6 Add **test.txt** File(Optional)
If you have a test dataset, you can add this file, and its content uses relative paths to concatenate images.
:::spoiler **test.txt**
```=
./images/train2017/000000000009.jpg
./images/train2017/000000000025.jpg
./images/train2017/000000000030.jpg
./images/train2017/000000000034.jpg
./images/train2017/000000000036.jpg
./images/train2017/000000000042.jpg
./images/train2017/000000000049.jpg
./images/train2017/000000000061.jpg
./images/train2017/000000000064.jpg
./images/train2017/000000000071.jpg
./images/train2017/000000000072.jpg
./images/train2017/000000000073.jpg
```
:::
#### 1.2.7 Create a Bucket
Select **Storage Service** from the OneAI services to enter the Storage Service Management page, and then click **+CREATE** to add a bucket such as **yolo-dataset**. This bucket is used to store our dataset.
#### 1.2.8 Upload Images and Annotated Data Files
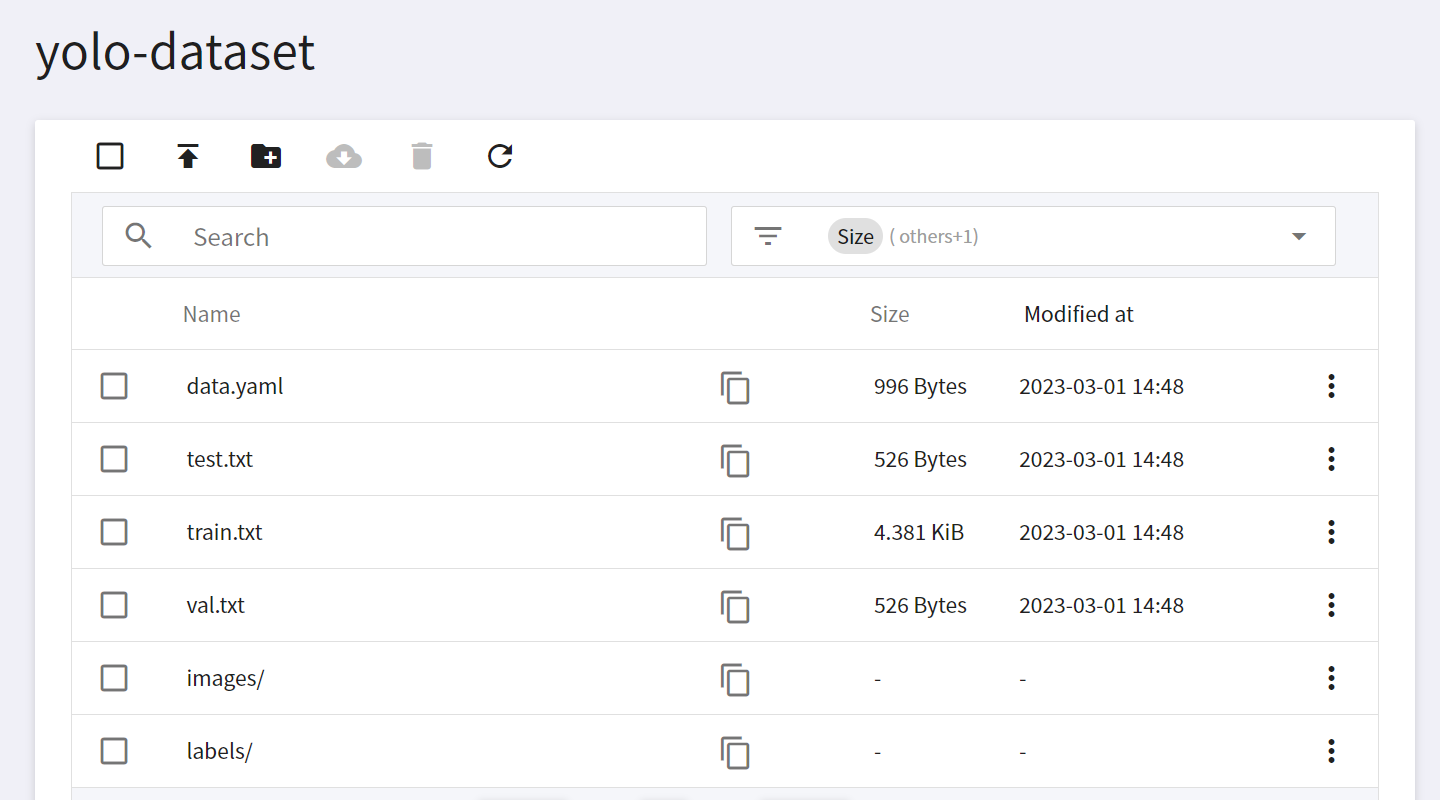
Finally, upload the prepared dataset and labeled files to the newly created bucket. The following figure shows the final file structure in the bucket.
## 2. Data Annotation
In order for the YOLO network to learn and recognize the images we provide, we must first annotate the images to be trained. In this section, we will annotate the data to be trained by the **CVAT Tool (CVAT Computer Vision Annotation Tool)** integrated with **AI Maker**.
After the model is trained or if you already have a trained model, you can use the **CVAT Tool (CVAT Computer Vision Annotation Tool)** to reduce the time and cost of manual annotation, See [**6. CVAT Assisted Annotation**](#6-CVAT-assisted-annotation) in this tutorial.
:::info
:bulb: **Tips**: If you already have your own dataset and annotation data, you can go directly to step [**3. Training YOLO Model**](#3-Training-YOLO-Model).
:::
### 2.1 Enable CVAT
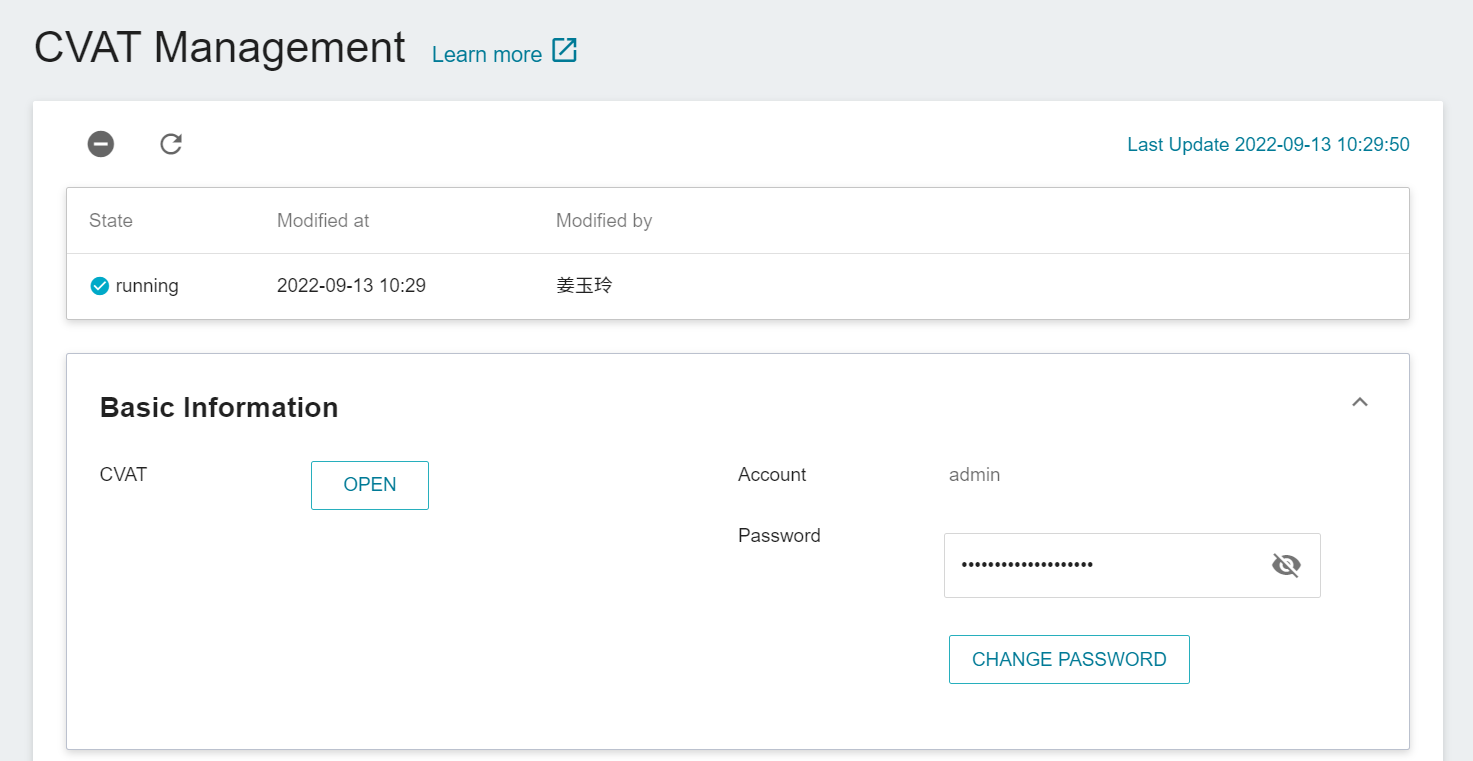
Click **Annotation Tools** on the left menu bar to enter the CVAT service home page. You need to click **Enable CVAT SERVICE** if you are using it for the first time. Only one CVAT service can be enabled for each project.
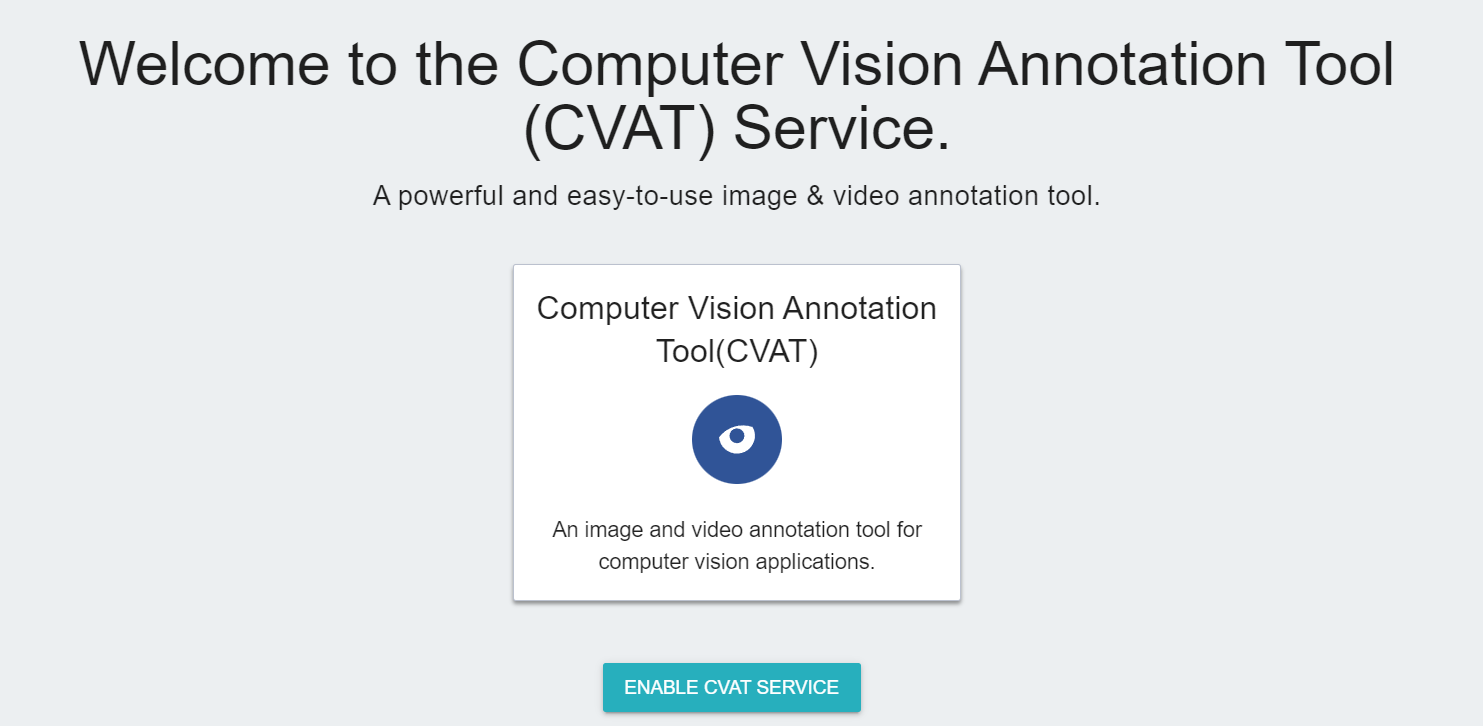
* After CVAT is successfully enabled, the CVAT service link and account password will appear, and the state will be **`running`**. Click **OPEN** in the basic information to open the login page of the CVAT service in the browser.
:::info
:bulb: **Tips:** When CVAT is enabled for the first time, it is recommended to change the default password. This password has no expiration date and can be used by members of the same project to log in to CVAT service. For security reasons, please change the password regularly.
:::
### 2.2 Use CVAT to Create Annotation Task
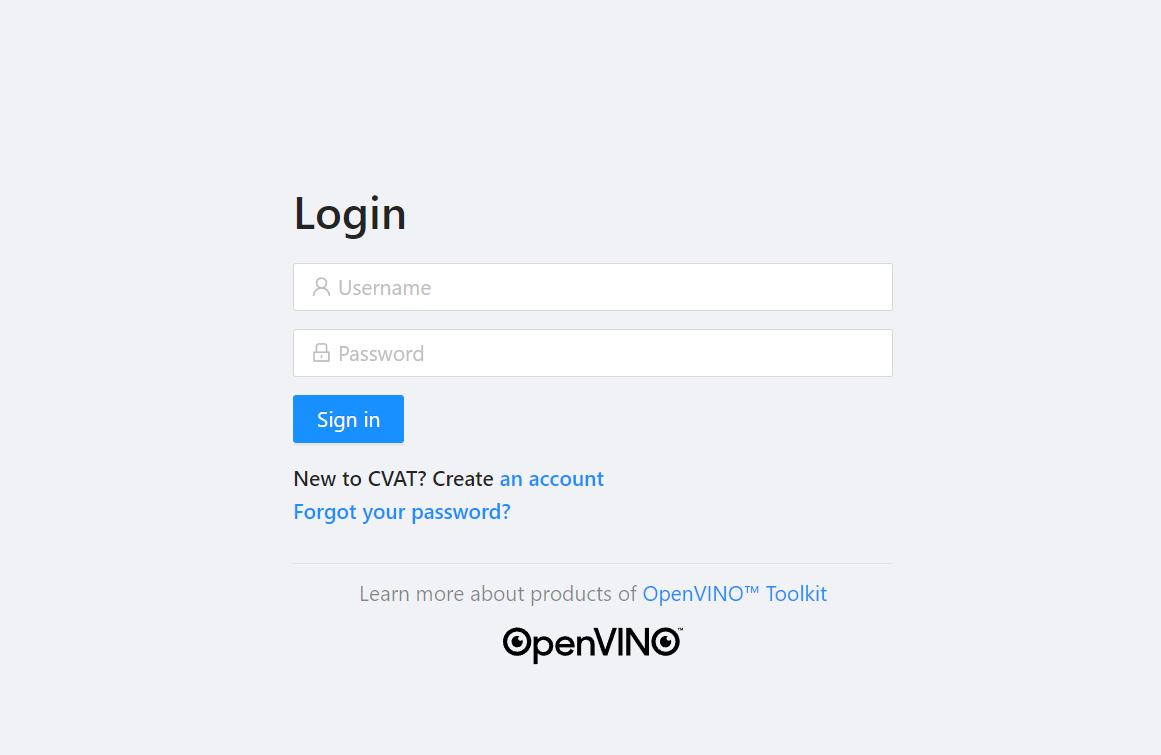
1. **Login CVAT**
After click **OPEN**,enter the account and password provided in the basic information to log in to the CVAT Service page.
:::warning
:warning: **Note:** Please use the Google Chrome browser to log in to CVAT. Using other browsers may cause unpredictable problems, such as being unable to log in or unable to annotate successfully.
:::
2. **Create CVAT Annotation Task**
After successfully logging in to the CVAT service, click **Tasks** above to enter the Tasks page. Next click **+** and then click **+ Create a new task** to create an annotation task.

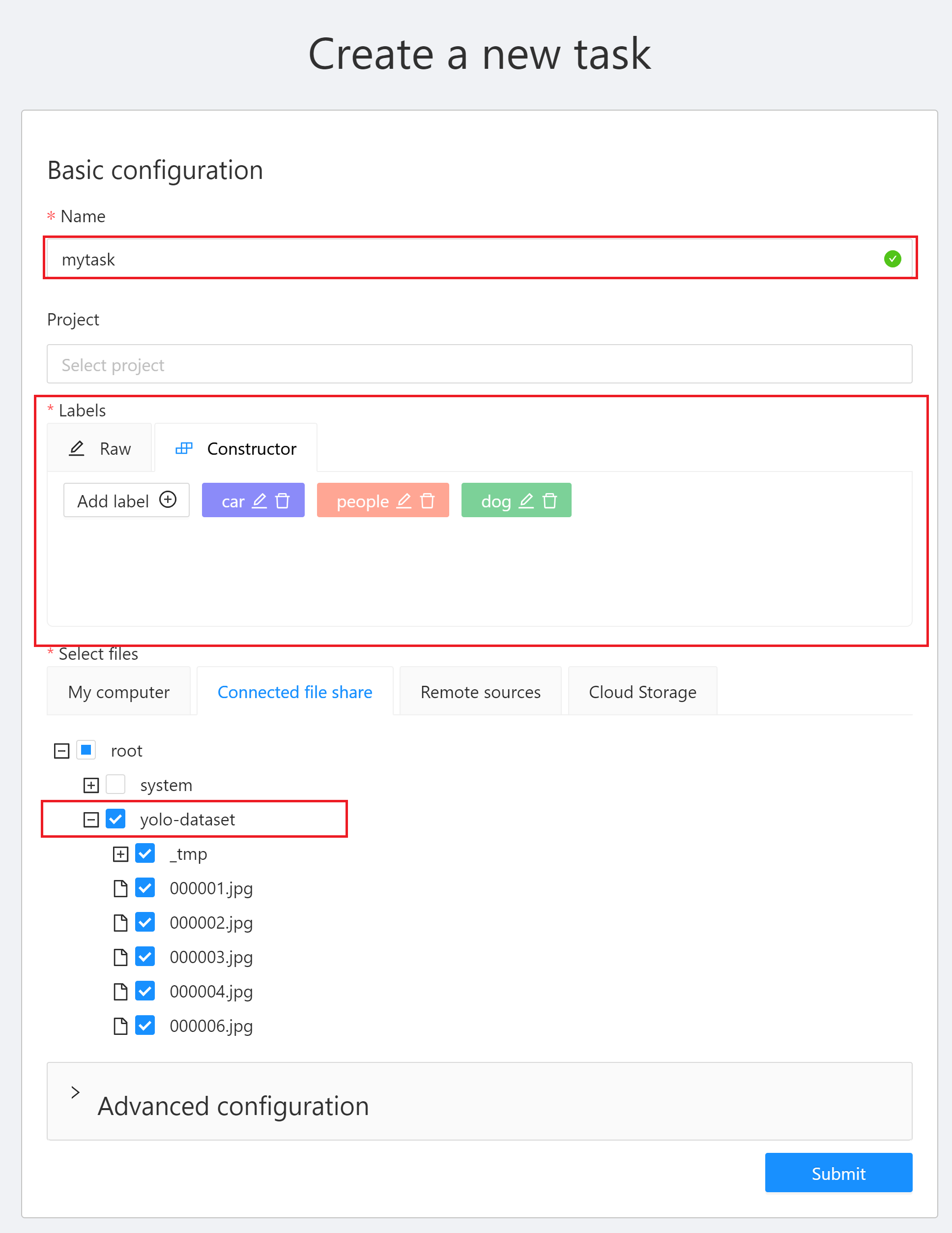
3. There are three places in the **Create a new task** window that need to be set:
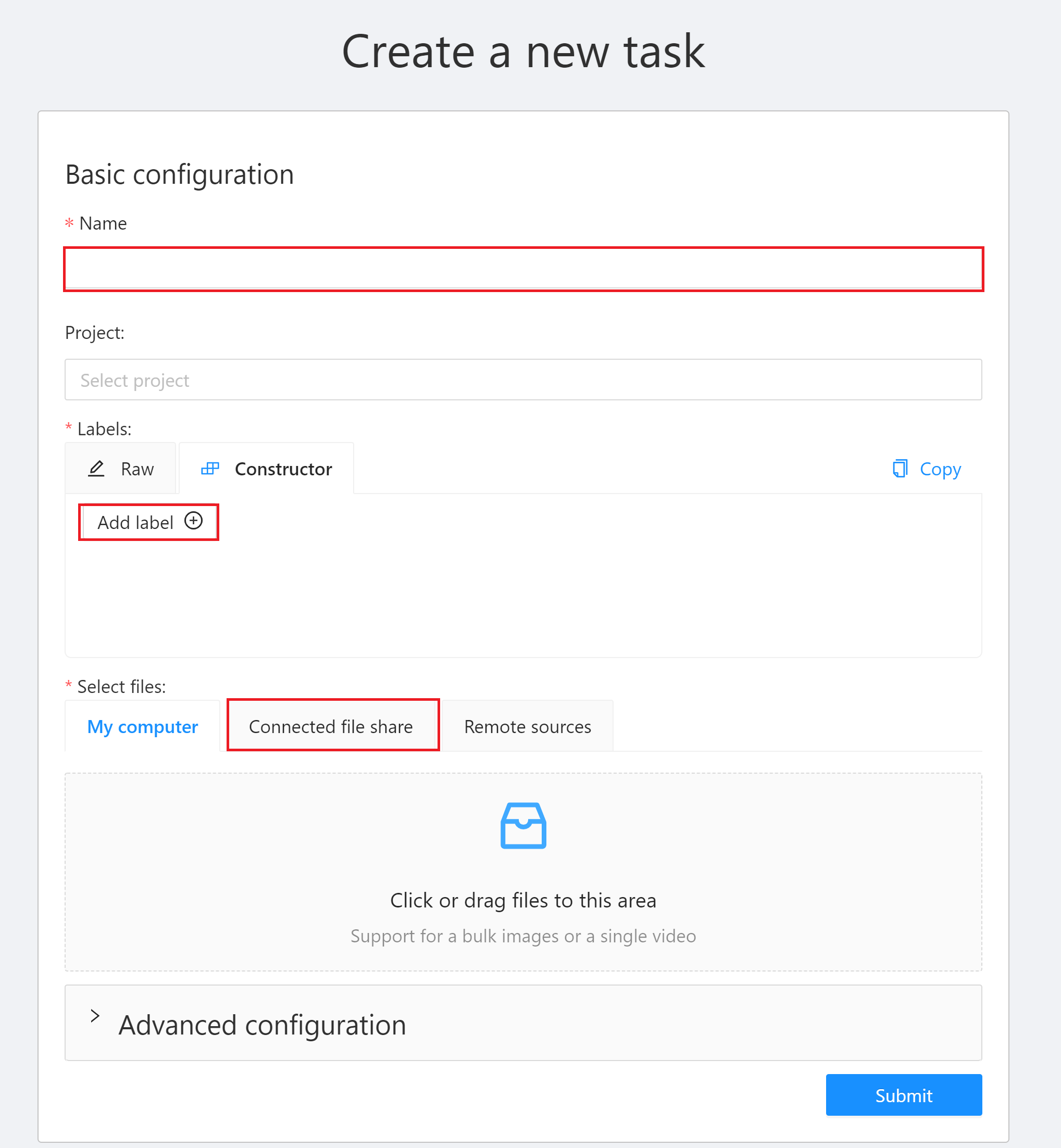
* **Name**: Enter a name for this Task, for example: `mytask`.
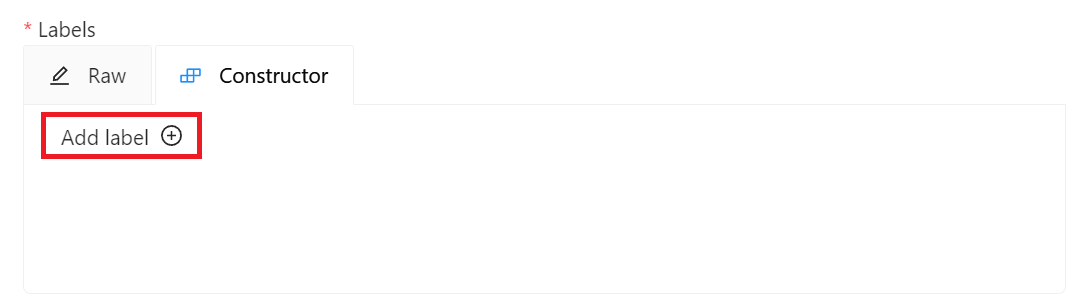
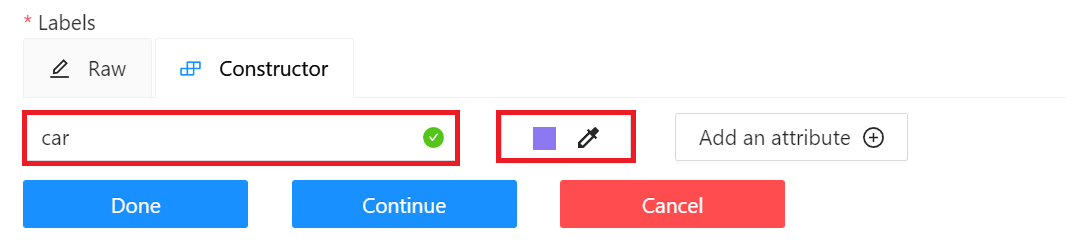
* **Labels**: Set the label of the object to be recognized. Click **Add label**, enter the label name, click the color block on the right to set the color of the label, then click **Continue** to continue adding other labels, or click **Done** to complete the label setting. In this example, we will create three labels: car, people and dog.
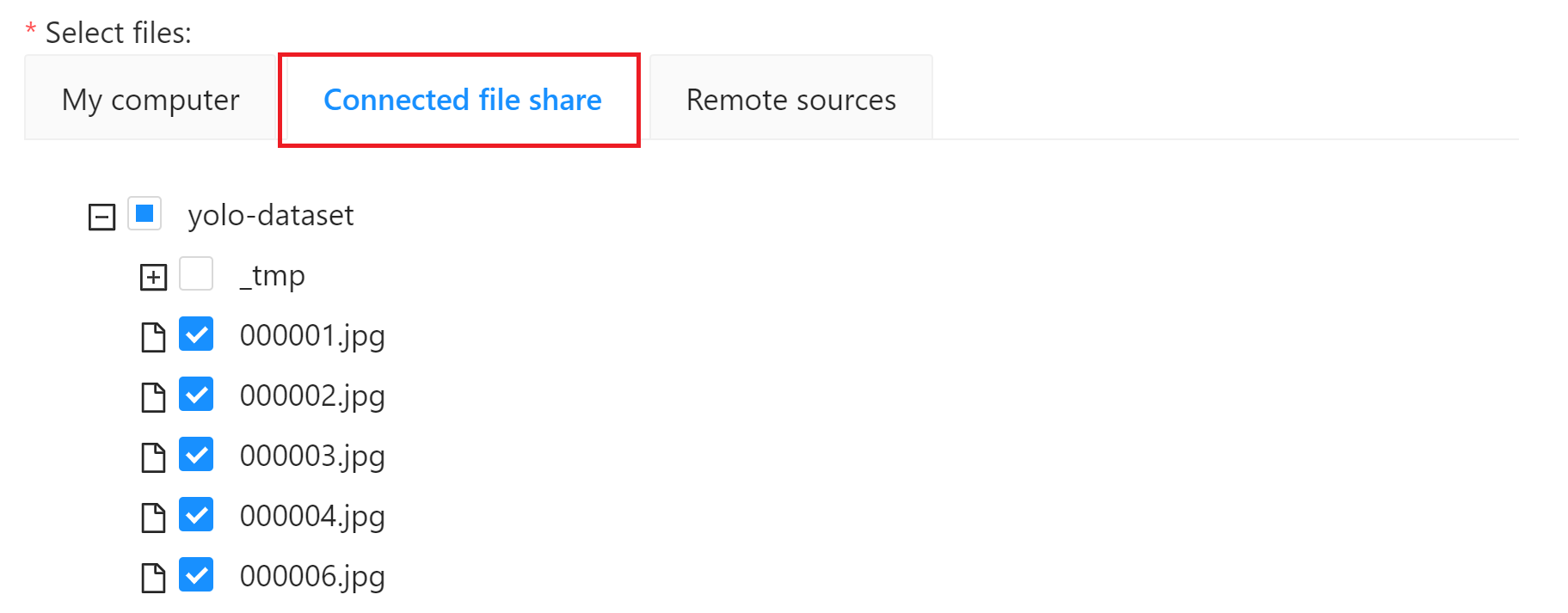
* **Select files**: Select the training dataset source. For this example, click **Connected file share** and select **`yolo-dataset`** bucket as the dataset source. For the dataset, please refer to [**1. Prepare the Dataset**](#1-prepare-the-dataset). After completing the setting, click **Submit** to create the task.
:::warning
:warning: **Note: CVAT file size limit**
In the CVAT service, it is recommended that you use the bucket of the storage service as data source. If the data is uploaded locally, the CVAT service limits the file size of each task to 1 GB.
:::
### 2.3 Use CVAT for Data Annotation
After creating CVAT annotation task, you can then proceed to data annotation.
1. **View the Created Task**
After the annotation task is created, it will appear at the top of the **Tasks** list. Click **OPEN** to enter the task details page.

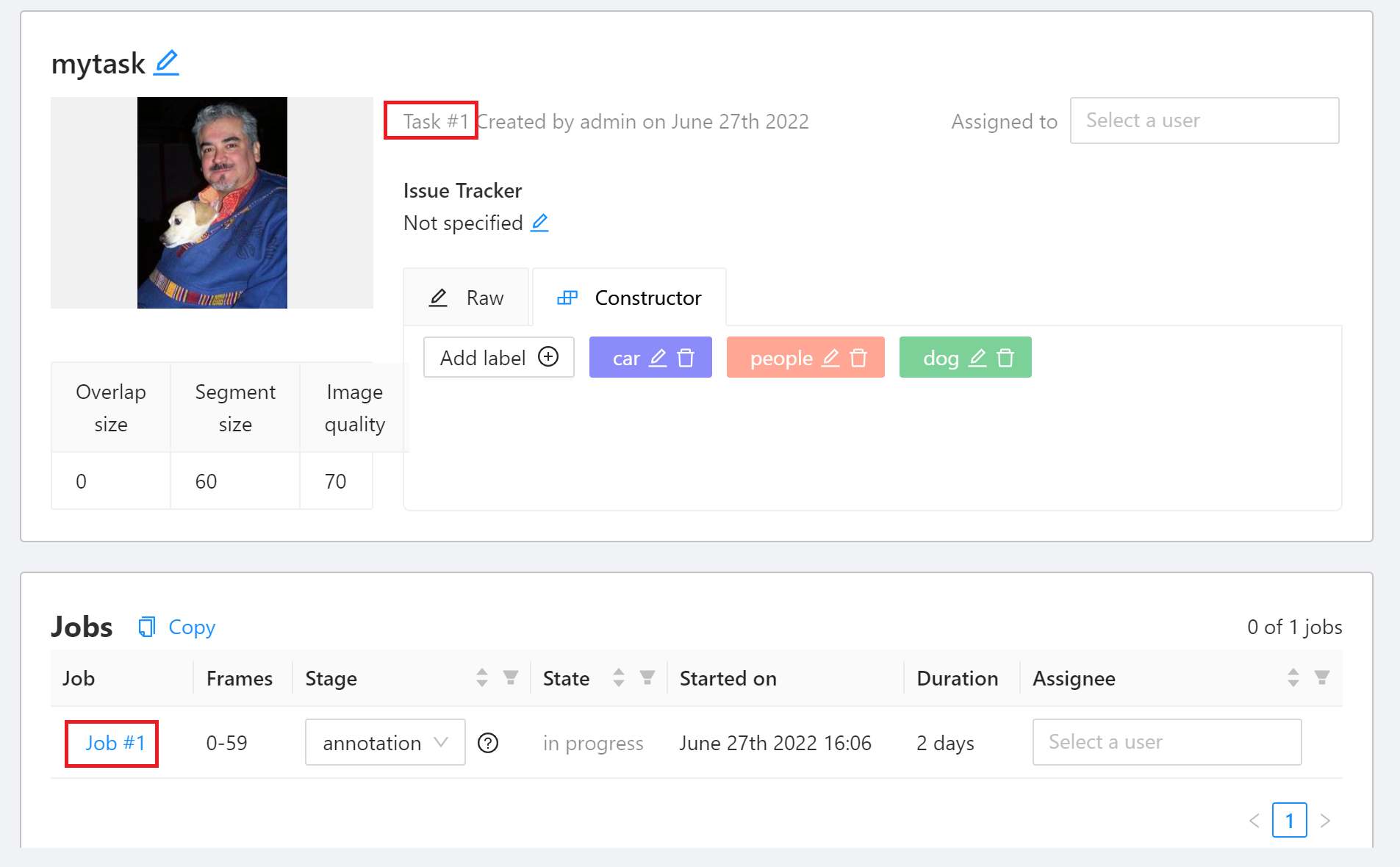
2. **Start Annotating**
On the task details page, the created object label will be displayed. After the label is confirmed, click **Job #id** to start annotating. Here, **`Task #1`** means that this Taskid is 1, and subsequent training tasks will need this information.
3. **Annotation**
You will see a picture you want to annotate after entering the annotation page. If there is a target object in the picture, you can annotate it according to the following steps.
1. Select the rectangle annotation tool **Draw new rectangle** on the left toolbar.
2. Select the label corresponding to the object.
3. Frame the target object.
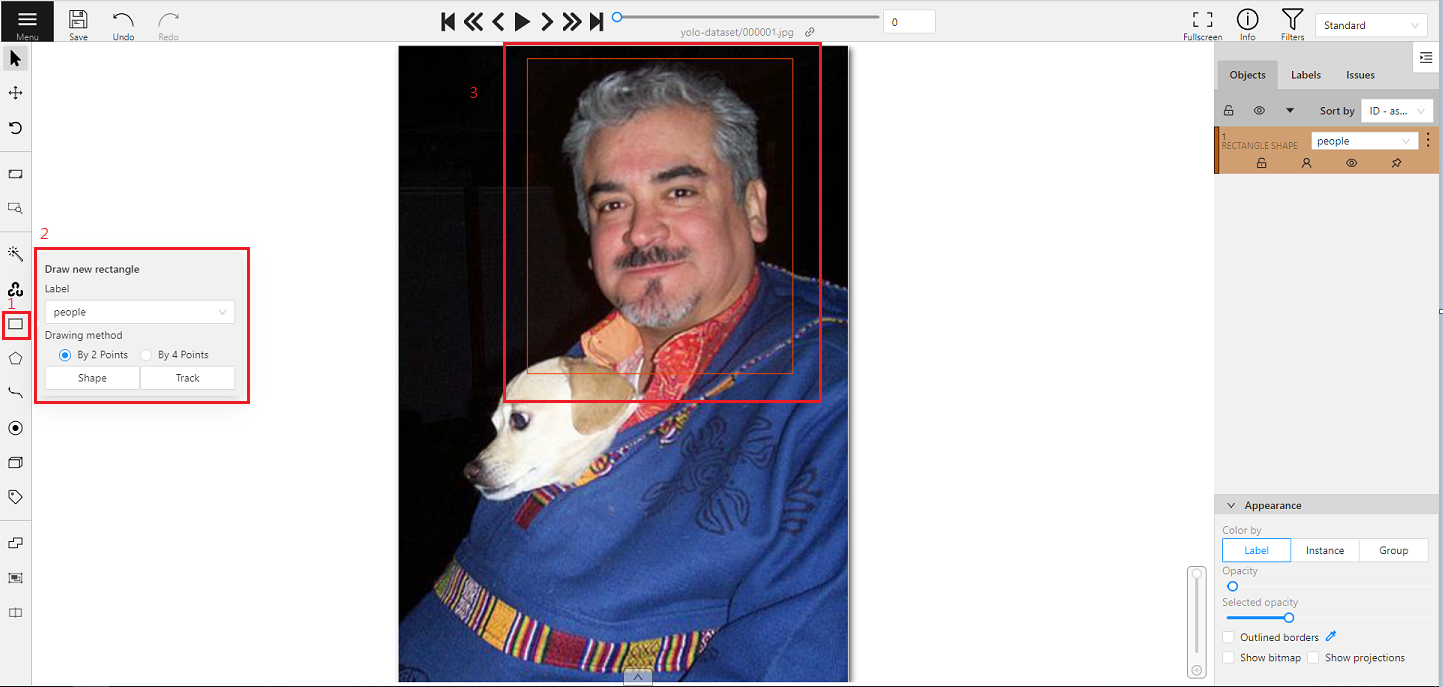
If there are multiple target objects in the picture, please repeat the annotating action until all target objects are annotated.
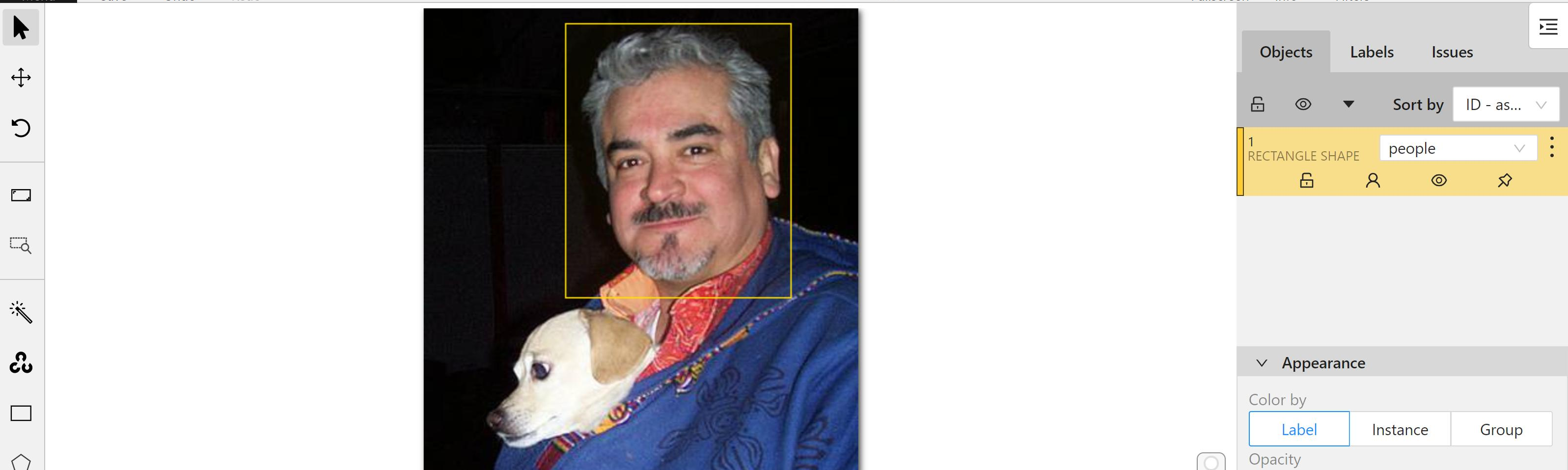
4. **Save Annotation Results**
After annotating several pictures, you can click **SAVE** in the upper left corner to save the annotation results, and continue with the subsequent tutorial.
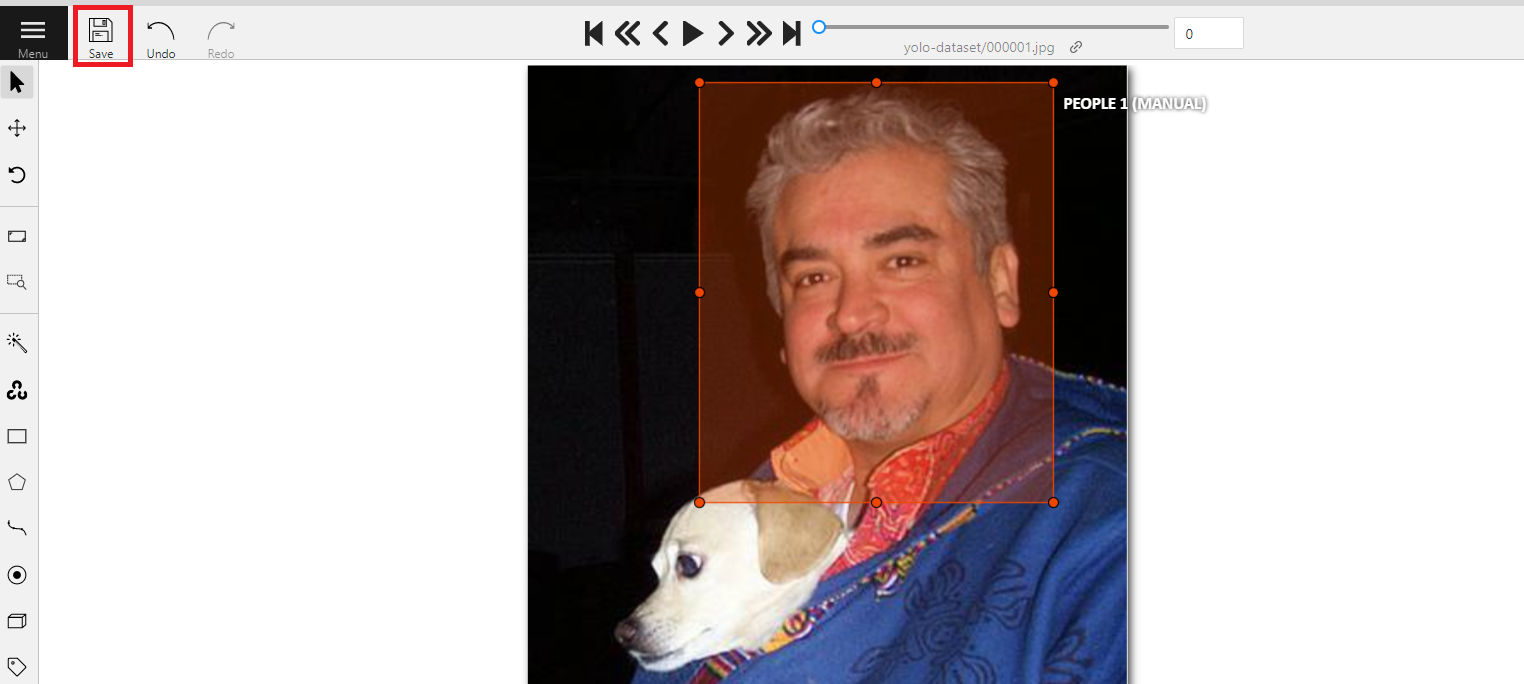
:::warning
:warning: **Note:** Make it a habit to save at any time during the annotation process, so as not to lose your work due to unavoidable incidents.
:::
### 2.4 Download Annotation Data
After the annotation is completed, the annotated data can be exported to the storage service, and then used in training model in AI Maker.
Go back to the **Tasks** page, click **Actions** on the right side of the task you want to download, and then click **Export task dataset**.
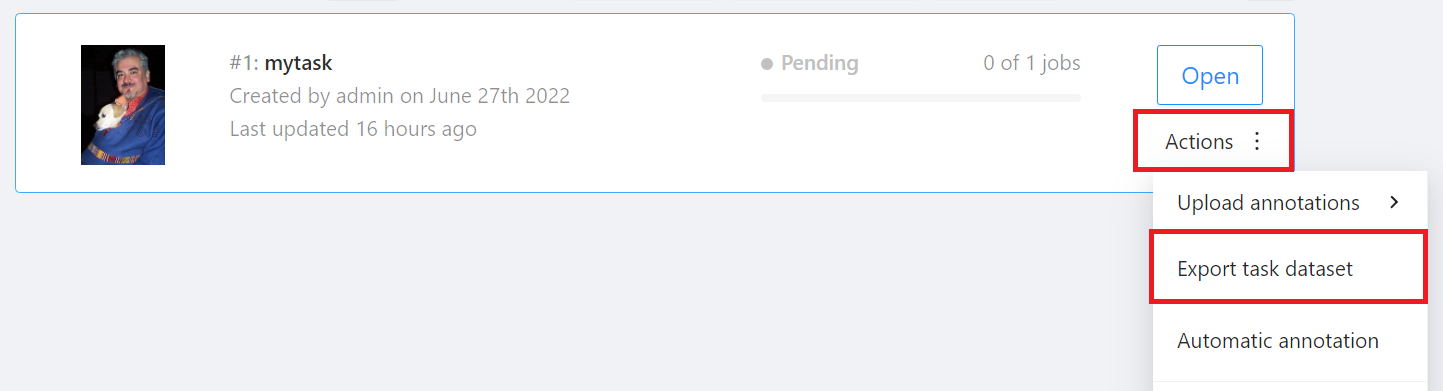
When the **Export task as a dataset** window appears, select the format of the annotation data to be exported and the bucket. This example will export the annotation data in **YOLO 1.1** format to the **`yolo-dataset`** bucket.
At this point, when you return to the bucket **`yolo-dataset`**, there will be an **Export** folder, and the downloaded annotation data will be stored according to the path of the Task id and data format. In this example, the Task id is 1 and the format is **YOLO 1.1**, so the downloaded annotation data will be placed in the **/Export/1/YOLO 1.1/** folder.
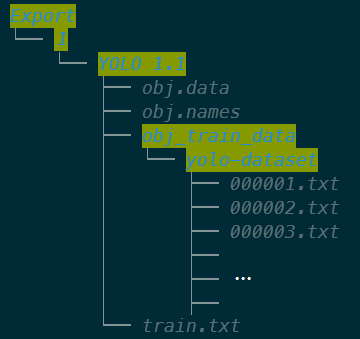
## 3. Training YOLO Model
After completing data [**Preparation**](#1-Prepare-the-Dataset) and [**Data Annotation**](#2-Annotation-Data), you can use these data to train and fit our YOLO network.
### 3.1 Create Training Job
Select **AI Maker** from the OneAI services, and then click **Training Job**. After entering the training job management page, switch to **Normal Training Job**, the click **+CREATE** to add a training job.
- **Normal Training Job**
Perform a one-time training job on your given training parameters.
- **Smart ML Training Job**
Hyperparameters can be automatically adjusted, and computing resources can be efficiently used for multiple model training to save you time and cost in analyzing and adjusting model training parameters.
#### 3.1.1 Normal Training Job
There are five steps in creating a training job:
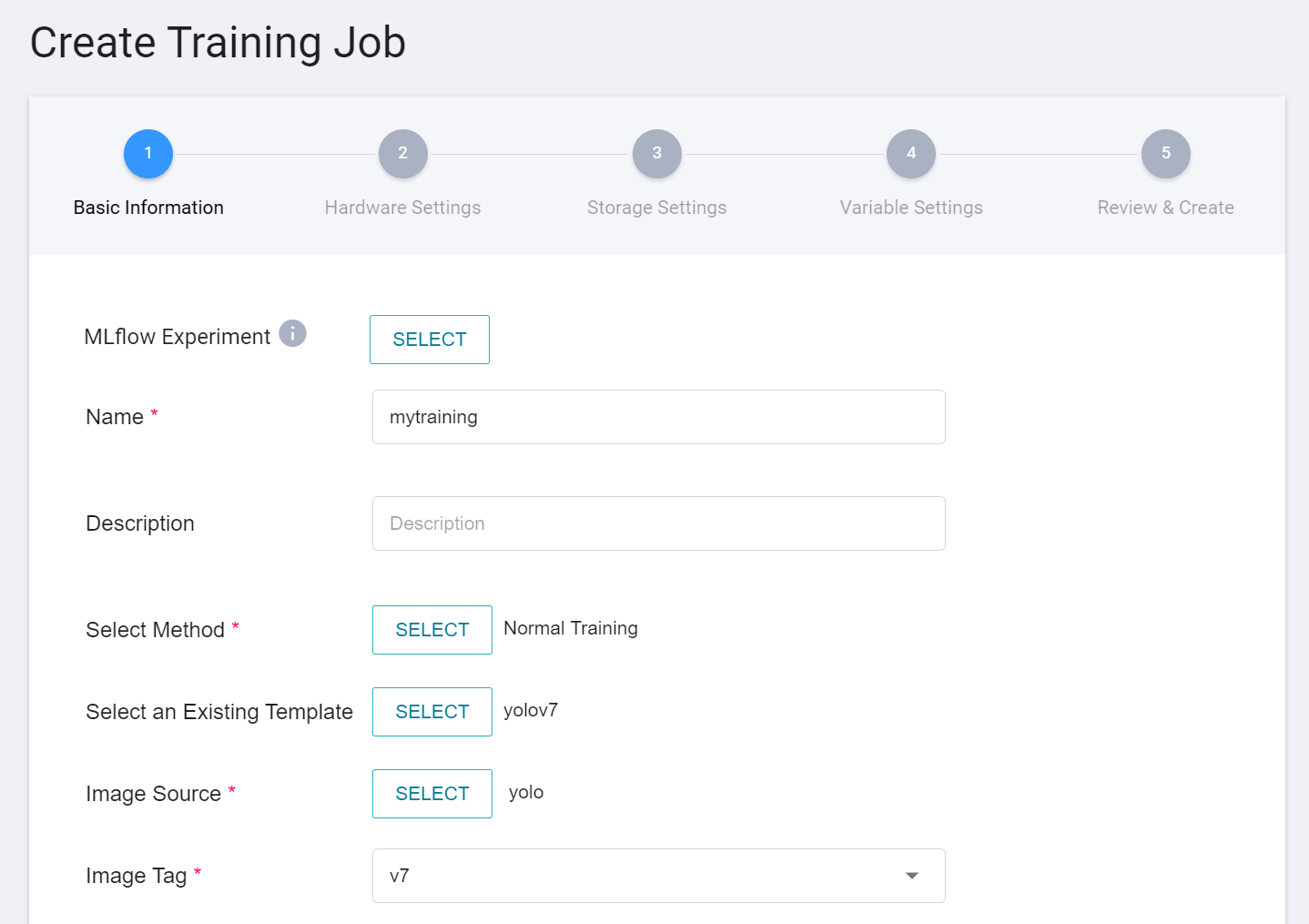
1. **Basic Information**
Let's start with the basic information setting. We first select **Normal Training Jobs** and use the built-in **`yolov7`** template to bring in the environment variables and settings. The setting screen is as follows:
2. **Hardware Settings**
Select the appropriate hardware resource from the list with reference to the current available quota and training program requirements.
:::info
:bulb:**Tips:** It is recommended to choose a hardware with **shared memory** to avoid training failure due to insufficient resources.
:::
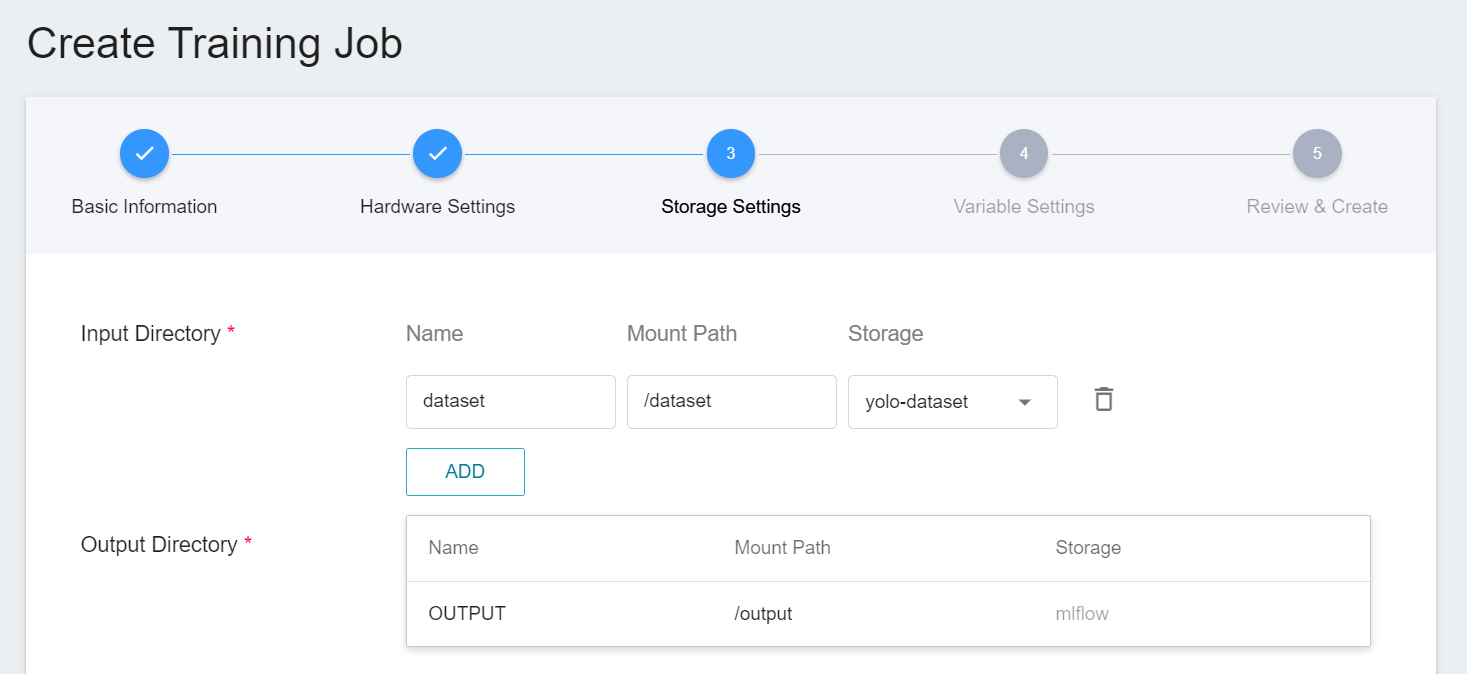
3. **Storage Settings**
There is a default storage setting in this stage, name: **`dataset`**, mount path: **`/dataset`**. Please select the storage bucket where you store the training data, for example, **`yolo-dataset`**.
:::info
:bulb: **Tips: About Pre-trained Weights**
* To speed up the training convergence, the system has built-in pre-trained weight files trained by **COCO datasets**. Its pre-trained weight file is related to which **MODEL_TYPE** you use. For the corresponding relationship, please refer to [**3.1.3 Advanced Environment Variables**](#313-Advanced-EnvironmentV-Variables).
* If you want to use your own pre-trained model, you can add a set of storage settings in **Input Source**, name: **`weights`**, mount path: **`/weights`**, and select your Store the storage body of the pre-trained model, for example: **`yolov7-weights`**.

:::
4. **Variable Settings**
When filling in the basic information, When choosing to apply the yolov7 template in the Basic Information step, the basic variables and commands will be automatically brought in. The variable setting values can be adjusted or added according to the development needs. The parameters provided by the template yolov7 are described below.
| Variables | Preset | Description |
| ----- | -------| ---- |
| WIDTH|640|Set the width of the picture to enter the network.|
| HEIGHT|640|Set the height of the picture to enter the network.|
| BATCHSIZE|16|Batch size, the size value of each batch, and the model is updated once per batch.|
| EPOCHS | 300 | Set the epoch for the training job.|
| MODEL_TYPE|yolov7 | Set the training model, can input **yolov7, yolov7-tiny, yolov7-x, yolov7-w6, yolov7-e6, yolov7-d6 yolov7-e6e** etc., please refer to [**3.1.3 Advanced Environment Variables**](#313-Advanced-EnvironmentV-Variables) for more information.|
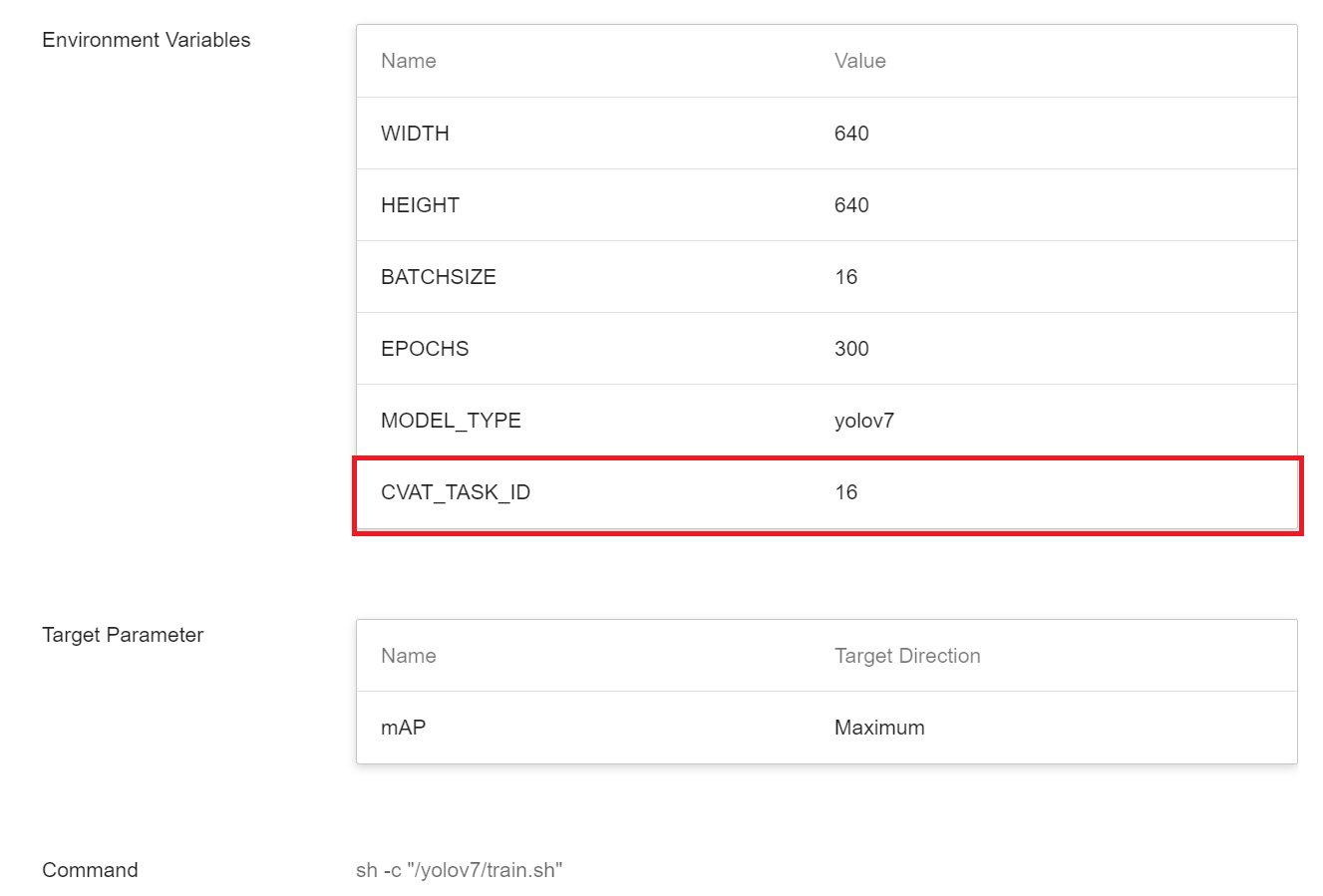
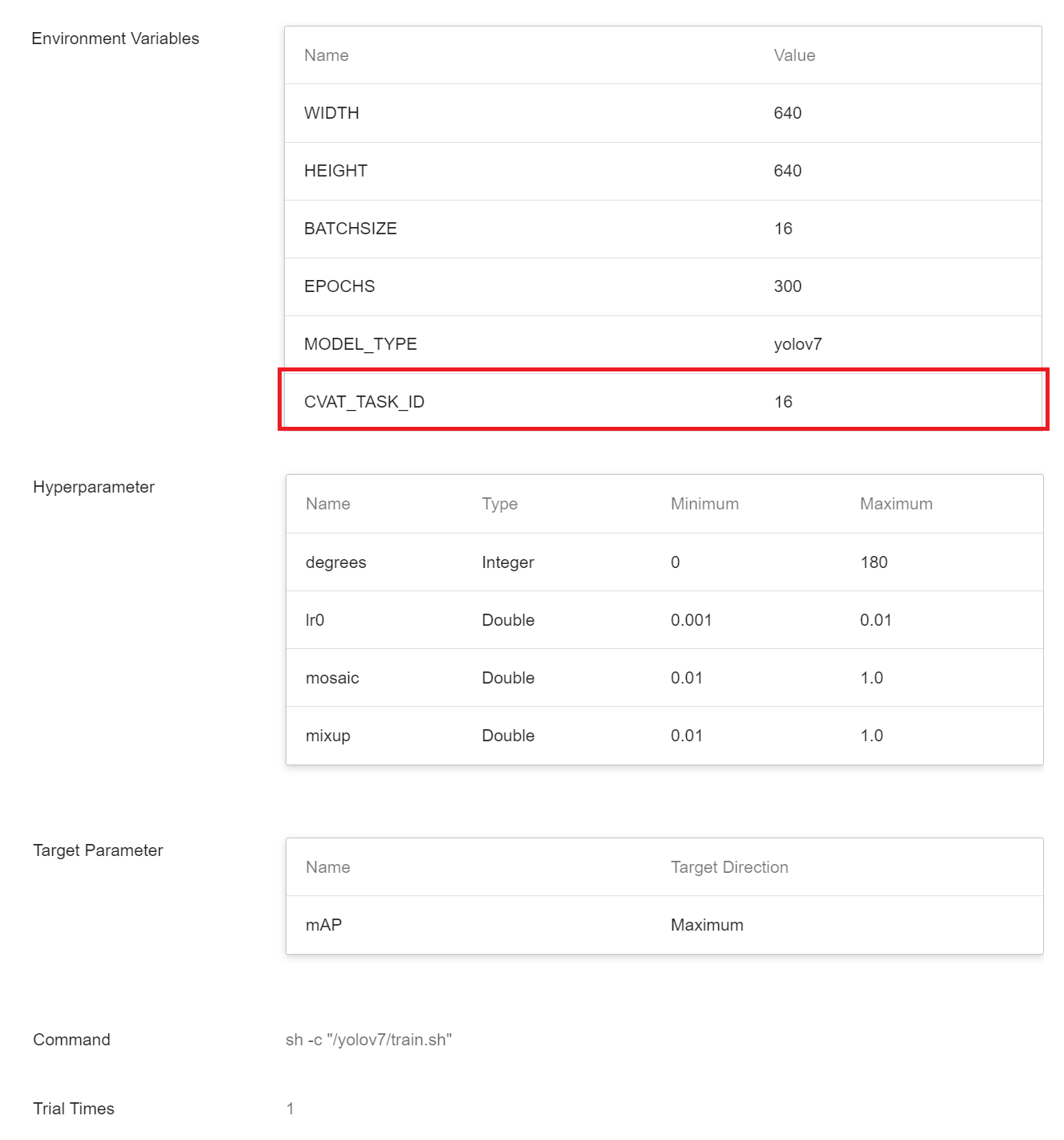
| CVAT_TASK_ID |==cvat_task_id==|Please modify this parameter value to the **Task ID** of the data to be annotated with **CVAT**. The Task ID can be queried on the Tasks page of CVAT. If you use your own dataset and annotation data, please set to **none**.|
The following are examples of variable settings for **Data Labeled with CVAT Tool** and **Use Your Own Dataset and Labeled Data**. For advanced environment variables that are not brought out by default in the template, you can refer to [**3.1.3 Advanced Environment Variables**](#313-Advanced-EnvironmentV-Variables) and add them as needed.
| Normal Training <br> Variable Settings Example <br> Data Labeled with CVAT Tool | Normal Training <br> Variable Settings Example<br>Use Your Own Dataset and Labeled Data|
| :--------: | :--------: |
| ||
:::info
:bulb: **Tips:**
* If the dataset is from CVAT annotation, remember to set the corresponding CVAT TASK ID.
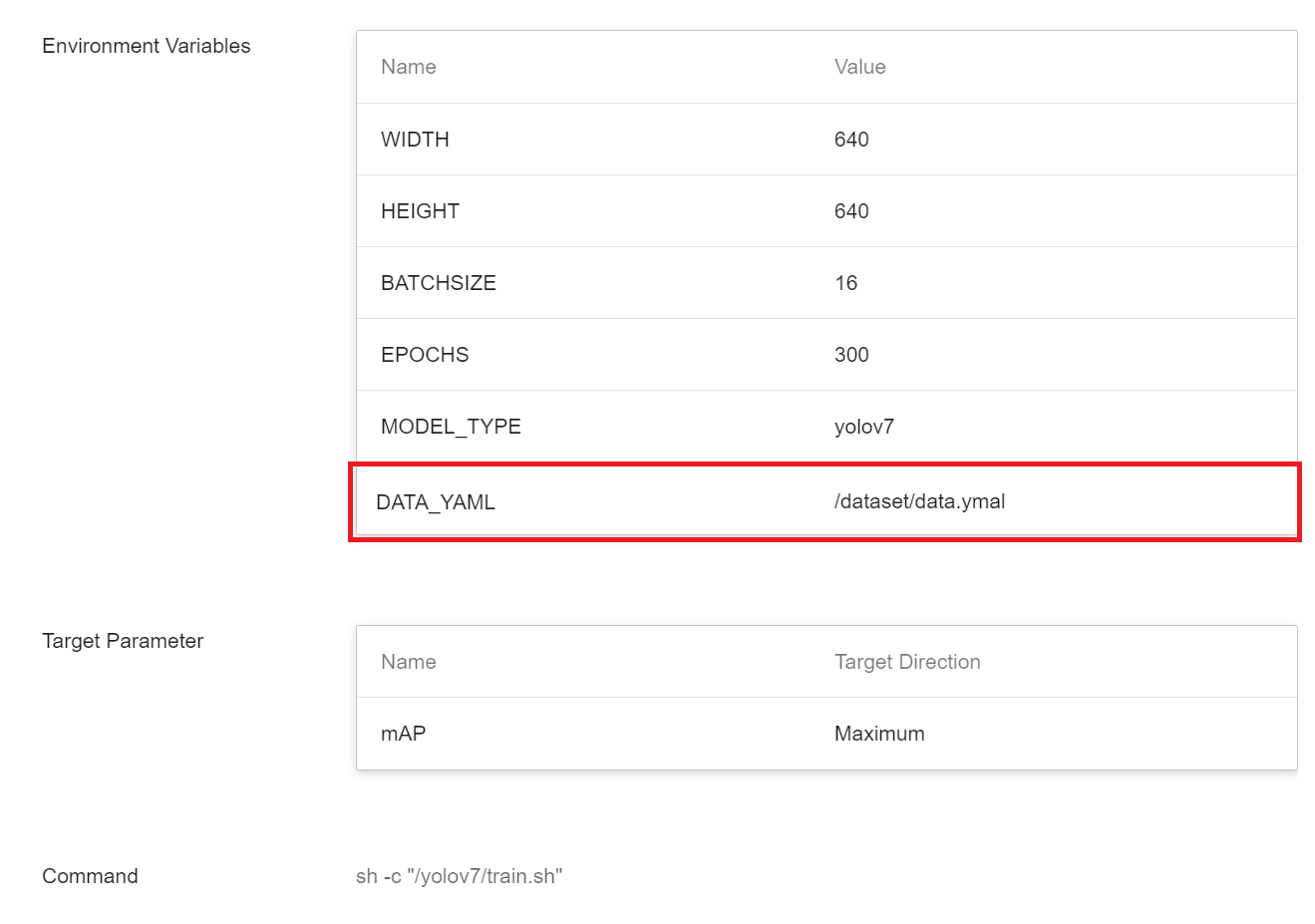
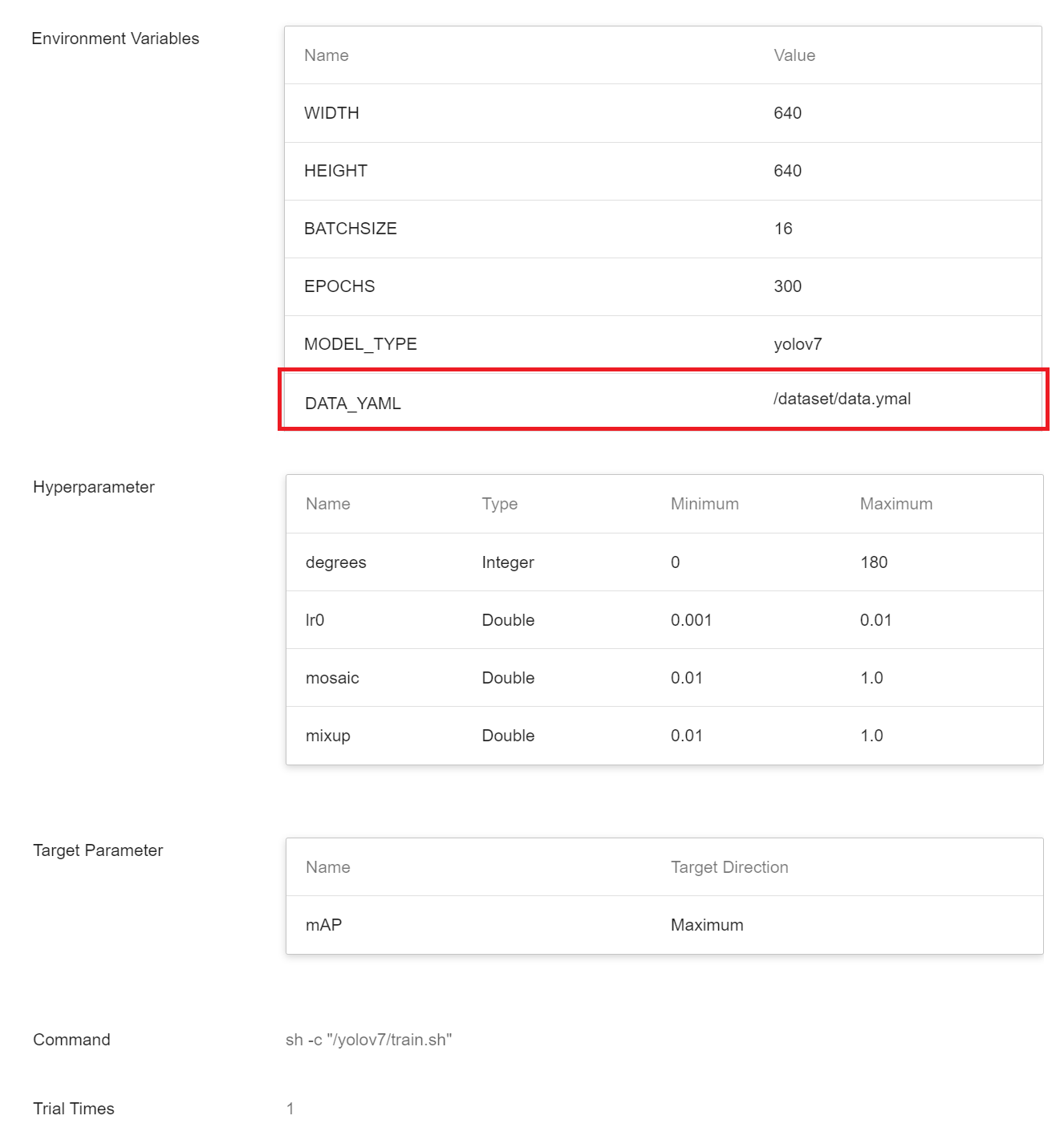
* If the dataset comes from your own dataset, remember to specify the corresponding value of the **`DATA_YAML`** and the value of **`train`**, **`val`** and **`test`** in the YAML file. (Optional)
:::
5. **Review & Create**
Finally, confirm the entered information and click **CREATE**.
#### 3.1.2 Smart ML Training Jobs
In the [**previous section 3.1.1**](#311-Normal-Training-Jobs), we introduced the creation of **Normal Training Jobs**, and here we introduce the creation of **Smart ML Training Jobs**. You can choose just one training method or compare the differences between the two. Both processes are roughly the same, but there are additional parameters to be set, and only the additional variables are described here.
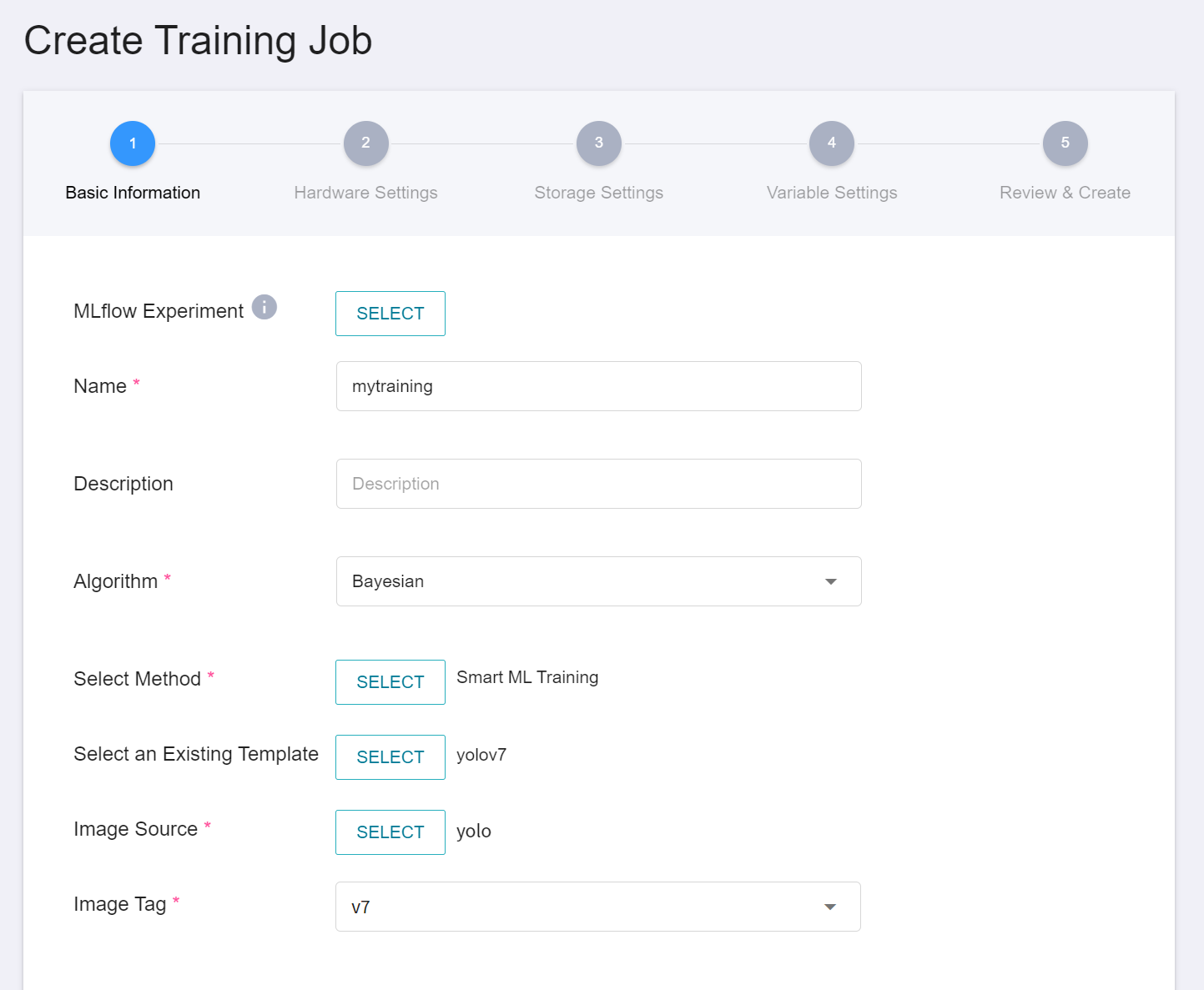
1. **Basic Information**
When Smart ML training job is the setting method, you will be further required to select the **Algorithm** to be used for the Smart ML training job, and the algorithms that can be selected are as follows.
- **Bayesian**: Efficiently perform multiple training jobs to find better parameter combinations, depending on environmental variables, the range of hyperparameter settings, and the number of training sessions.
- **TPE**: Tree-structured Parzen Estimator, similar to the Bayesian algorithm, can optimize the training jobs of high-dimensional hyperparameters.
- **Grid**: Experienced machine learning users can specify multiple values of hyperparameters, and the system will perform multiple training jobs based on the combination of the hyperparameter lists and obtain the calculated results.
- **Random**: Randomly select hyperparameters for the training job within the specified range.
2. **Variable Settings**
The variable settings for **Smart ML Training Job** will be slightly different.
| Field name | Description |
| --- | --- |
| Environment variable | Enter the name and value of the environment variables. The environment variables here include not only the settings related to the training execution, but also the parameters required for the training network. |
| Hyperparameter<sup style="color:red"><b>\*</b></sup> | **(Smart ML Training Job)** This tells the job what parameters to try. Each parameter must have a name, type, and value (or range of values) when it is set. After selecting the type (integer, float, and array), enter the corresponding value format when prompted. |
| Target Parameter<sup style="color:red"><b>\*</b></sup> | **(Smart ML Training Job)** When using **`Bayesian`** or **`TPE`** algorithms, they will repeatedly adjust the appropriate parameters based on the results of the **target parameters** as a benchmark for the next training job. <br> After training, a value will be returned as the final result. Here, the name and target direction need to be set for this value. For example, if the returned value is the accuracy rate, you can name it accuracy and set its target direction to the maximum value; if the returned value is the error rate, you can name it error and set its direction to the minimum value.<br><br> The metrics provided according to the task type is **`accuracy`**, and its direction is **`Maximum`**. |
| Command | Enter the command or program name to be executed. The command provided in this image is: `sh -c "/yolov7/train.sh"`. |
| Trial Times<sup style="color:red"><b>\*</b></sup> | **(Smart ML Training Job)** That is, the number of training sessions, the training job is executed multiple times to find a better parameter combination. |
Here, **environment variables** and **hyperparameters** can switch from one to another. If you want a parameter to be a fixed value, you can remove it from the hyperparameter setting and add it to the environment variable with a fixed value; conversely, if you want to add the parameter to the trial, remove it from the environment variable and add it to the hyperparameter settings below.
The preset hyperparameters in the template are described as follows:
| Name | Value range | Description |
| ---- | ---- | ---- |
| lr0 | 0.001 ~ 0.01 | The **Learning Rate** parameter can be set larger at the beginning of model learning to speed up the training. In the later stage of learning, it needs to be set smaller to avoid divergence. |
|degrees |0 ~180 | The **Angle** of the picture to be adjusted, setting it to 5 means the picture will be rotated by -5 ~ 5 degrees to get more samples.|
|mosaic|0.01~1.0| Sets to generate a new unique image (original image plus 3 random images) each time images are loaded for training.|
| mixup|0.01~1.0|It is to mix the original image and the randomly selected image in a certain proportion to generate a new image.
Of course, you can also customize your own hyperparameters, refer to the parameters in [**hyp.scratch.custom.yaml**](https://github.com/WongKinYiu/yolov7/blob/main/data/hyp.scratch.custom.yaml) and fill in the parameters you want to add and the corresponding ranges.
The following are examples of variable settings for **Data Labeled with CVAT Tool** and **Use Your Own Dataset and Labeled Data**. For advanced environment variables that are not brought out by default in the template, you can refer to [**3.1.3 Advanced environment variables**](#313-Advanced-Environment-Variables) and add them as needed.
| SMART ML Training Variable Settings Example <br> Data Labeled with CVAT Tool | SMART ML Training Variable Settings Example <br>Use Your Own Dataset and Labeled Data|
| :--------: | :--------: |
| ||
#### 3.1.3 Advanced Environment Variables
The advanced environment variables are described as follows, and can be added according to requirements.
| Variables | Preset | Description |
| -------- | -------- | -------- |
| WEIGHT| default |Use weight; the available content is: **none**, **default** or **weight file path**; the following table will explain more.|
| DATA_YAML|default|data yaml file;If you use your own dataset, please set this environment variable.|
| HYP_YAML|default|hyperparameter yaml file ; the following table will explain more.|
| CFG_YAML|default|cfg yaml file; the following table will explain more.|
| CVAT_VAL_TASK_ID|none|(Optional) Which CVAT task id to use as the validation dataset.|
| CVAT_TEST_TASK_ID|none|(Optional) Which CVAT task id to use as the test dataset.|
| TRAIN_VALIDATION_RATE|8:2|Randomly divide the training set and validation set from the training set data at a ratio of 8:2. If you do not define a validation set, the system will divide the data set according to this ratio.|
| EXTRA_PARAMETER|none|Advanced parameters for yolov7 [**train.py**](https://github.com/WongKinYiu/yolov7/blob/main/train.py#L528)|
| EXTRA_TEST_PARAMETER|none|Advanced parameters for yolov7 [**test.py**](https://github.com/WongKinYiu/yolov7/blob/main/test.py#L291)|
The following describes the relationship between the environment variables MODEL_TYPE, WEIGHT, HYP_YAML, and CFG_YAML. For more information about **MODEL_TYPE**, please refer to [**YOLOv7 Official Documentation**](https://github.com/WongKinYiu/yolov7).
| MODEL_TYPE | WEIGHT | HYP_YAML |CFG_YAML|
| :---- |:-------- | ---- | -------|
| yolov7 |none:<br>Do not use pretrained weights, train from scratch. <br>default:<br>Use the built-in [yolov7_training.pt](https://github.com/WongKinYiu/yolov7/releases/tag/v0.1) pre-trained weights. <br>path file: Use a custom weight file. |default:<br>Use the built-in [hyp.scratch.p5.yaml](https://github.com/WongKinYiu/yolov7/blob/main/data/hyp.scratch.p5.yaml) hyperparameter file. <br>path file:<br>Use a custom<br>hyperparameter file. |default:<br>Use the built-in [coco.yaml](https://github.com/WongKinYiu/yolov7/blob/main/data/coco.yaml)<br>path file:<br>Use custom data yaml.|
| yolov7-tiny |none:<br>Do not use pretrained weights, train from scratch.<br><br>default:<br>Use the built-in [yolov7_tiny.pt](https://github.com/WongKinYiu/yolov7/releases/tag/v0.1) pre-trained weights.<br>path file: Use a custom weight file.|<br>default:<br>Use the built-in [hyp.scratch.tiny.yaml](https://github.com/WongKinYiu/yolov7/blob/main/data/hyp.scratch.tiny.yaml) hyperparameter file. <br>path file:<br>Use custom<br>hyperparameter file. |deafult:<br>Use custom [yolov7-tiny.yaml](https://github.com/WongKinYiu/yolov7/blob/main/cfg/training/yolov7-tiny.yaml)<br>path file:<br>Use custom cfg yaml。
| yolov7-x|none:<br>Do not use pretrained weights, train from scratch.<br><br>default:<br>Use the built-in [yolov7x_training.pt](https://github.com/WongKinYiu/yolov7/releases/tag/v0.1) pre-trained weights.<br>path file: Use a custom weight file.|<br>default:<br>Use the built-in [hyp.scratch.p5.yaml](https://github.com/WongKinYiu/yolov7/blob/main/data/hyp.scratch.p5.yaml) hyperparameter file.<br>path file:<br>Use custom<br>hyperparameter file.|deafult:<br>Use custom [yolov7-x.yaml](https://github.com/WongKinYiu/yolov7/blob/main/cfg/training/yolov7-x.yaml)<br>path file: Use custom cfg yaml。
| yolov7-w6|none:<br>Do not use pretrained weights, train from scratch.<br><br>default:<br>Use the built-in [yolov7x_training.pt](https://github.com/WongKinYiu/yolov7/releases/tag/v0.1) pre-trained weights.<br>path file: Use a custom weight file.|<br>default:<br>Use the built-in [hyp.scratch.p6.yaml](https://https://github.com/WongKinYiu/yolov7/blob/main/data/hyp.scratch.p6.yaml) hyperparameter file.<br>path file:<br>Use custom<br>hyperparameter file.|deafult:<br>Use custom [yolov7-w6.yaml](https://github.com/WongKinYiu/yolov7/blob/main/cfg/training/yolov7-w6.yaml)<br>path file:<br>Use custom cfg yaml。
| yolov7-e6|none:<br>Do not use pretrained weights, train from scratch.<br><br>default:<br>Use the built-in [yolov7-e6_training.pt](https://github.com/WongKinYiu/yolov7/releases/tag/v0.1) pre-trained weights.<br>path file:<br>Use a custom weight file.|<br>default:<br>Use the built-in [hyp.scratch.p6.yaml](https://https://github.com/WongKinYiu/yolov7/blob/main/data/hyp.scratch.p6.yaml) hyperparameter file.<br>path file:<br>Use custom<br>hyperparameter file.|deafult:<br>Use custom [yolov7-e6.yaml](https://github.com/WongKinYiu/yolov7/blob/main/cfg/training/yolov7-e6.yaml)<br>path file:<br>Use custom cfg yaml。
| yolov7-d6|none:<br>Do not use pretrained weights, train from scratch.<br><br>default:<br>Use the built-in [yolov7-d6_training.pt](https://github.com/WongKinYiu/yolov7/releases/tag/v0.1) pre-trained weights.<br>path file:<br>Use a custom weight file.|<br>default:<br>Use the built-in [hyp.scratch.p6.yaml](https://https://github.com/WongKinYiu/yolov7/blob/main/data/hyp.scratch.p6.yaml) hyperparameter file.<br>path file:<br>Use custom<br>hyperparameter file.|deafult:<br>Use custom [yolov7-d6.yaml](https://github.com/WongKinYiu/yolov7/blob/main/cfg/training/yolov7-d6.yaml)<br>path file:<br>Use custom cfg yaml。
| yolov7-e6e|none:<br>Do not use pretrained weights, train from scratch.<br><br>default:<br>Use the built-in [yolov7-e6e_training.pt](https://github.com/WongKinYiu/yolov7/releases/tag/v0.1) pre-trained weights.<br>path file:<br>Use a custom weight file.。|<br>default:<br>Use the built-in [hyp.scratch.p6.yaml](https://https://github.com/WongKinYiu/yolov7/blob/main/data/hyp.scratch.p6.yaml) hyperparameter file.<br>path file:<br>Use custom<br>hyperparameter file.|deafult:<br>Use custom[yolov7-e6e.yaml](https://github.com/WongKinYiu/yolov7/blob/main/cfg/training/yolov7-e6e.yaml)<br>path file:<br>Use custom cfg yaml。|
#### 3.1.4 Environment Variable Setting Example
This section will illustrate the setting of environment variables in two scenarios: **Use the Data Labeled with CVAT Tool** or **Use Your Own Dataset and Labeled Data**.
1. **Use the Data Labeled with CVAT Tool**
Example of environment variable setting: When training the yolov7-x model, use the built-in yolov7x_training.pt for Transfer Learning (see the above table); use the TASK ID corresponding to CVAT: 1 and 2 as the training set; TASK ID: 3 as the verification set; TASK ID: 4 and 5 are the test sets.
| Name | Value |
|------|-------|
| MODEL_TYPE|yolov7-x|
| CVAT_TASK_ID|1, 2|
| CVAT_VAL_TASK_ID|3|
| CVAT_TEST_TASK_ID|4, 5|
2. **Use Your Own Dataset and Labeled Data**
Example of environment variable setting: When training the yolov7-x model, use the built-in yolov7x_training.pt for Transfer Learning (see the above table); and specify the path of the training set, verification set, test set and category file (DATA_YAML).
| Name | Value |
|------|-------|
| MODEL_TYPE|yolov7-x|
| CVAT_TASK_ID|none|
| DATA_YAML|/dataset/data.yaml|
For the content of data.yaml, please refer to [**1.2.2 Add data.yaml File** ](#122-Add-datayaml-File) for setting instructions.
:::info
:bulb: **Tips**
1. Please remember to remove or set CVAT_TASK_ID to none.
2. Please confirm that there is a corresponding file in the selected bucket.
:::
3. **Use Your Own Dataset and Pre-trained Model**
* Storage Setting example
- In the **`dataset`** setting of the input source, select the bucket where you store your own dataset and labeled data, for example:**`yolo-dataset`**.
- Please add a new set of storage settings, name: **`weights`**, mount path: **`/weights`**, and select the storage body where you store the pre-trained model, for example: **`yolov7-weights`**.

* Example of environment variable setting: When training the yolov7-x model, use the pre-trained model weight file you specified:
| Name | Value |
|------|------|
| MODEL_TYPE|yolov7-x|
| WEIGHT|/weights/my.pt|
### 3.2 Start a Training Job
After completing the setting of the Training Job, go back to the **Training Job Management** page, and you can see the job you just created. Click the job to view the detailed settings of the training job. If the job state is displayed as **`Ready`**, you can click **START** to execute the training job.
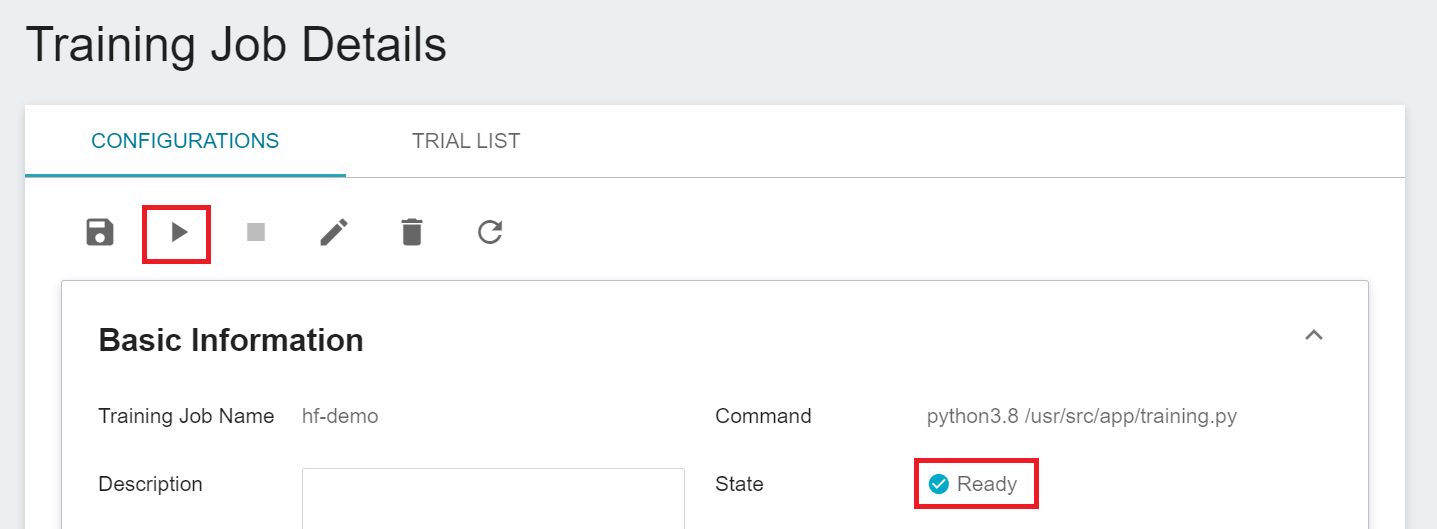
Once started, click the **TRIAL LIST** tab above to view the execution status and schedule of the job in the list. During training, you can click **VIEW LOG** or **VIEW DETAIL STATE** in the list on the right of the job to know the details of the current job execution.
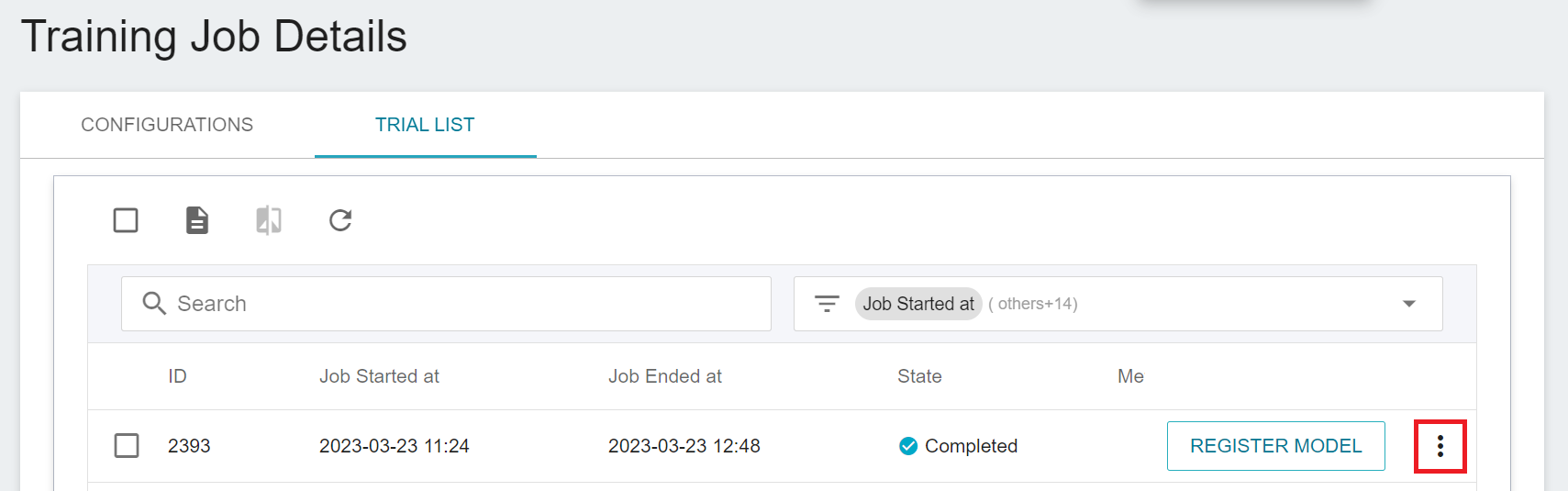
### 3.3 View Training Results
Please refer to the [**AI Maker > View Training Results**](/s/ai-maker-en#View-Training-Results) documentation for step by step instructions. For the Metrics of the training job, it is mAP_0.5 in this example, the larger the value, the better.

### 3.4 Model Registration
Select the result that meets expectation from one or more trial results, and then click **REGISTER MODEL** on the right to save them to Model Management; if no results meet expectation, then re-adjust the value or value range of environment variables and hyperparameters.
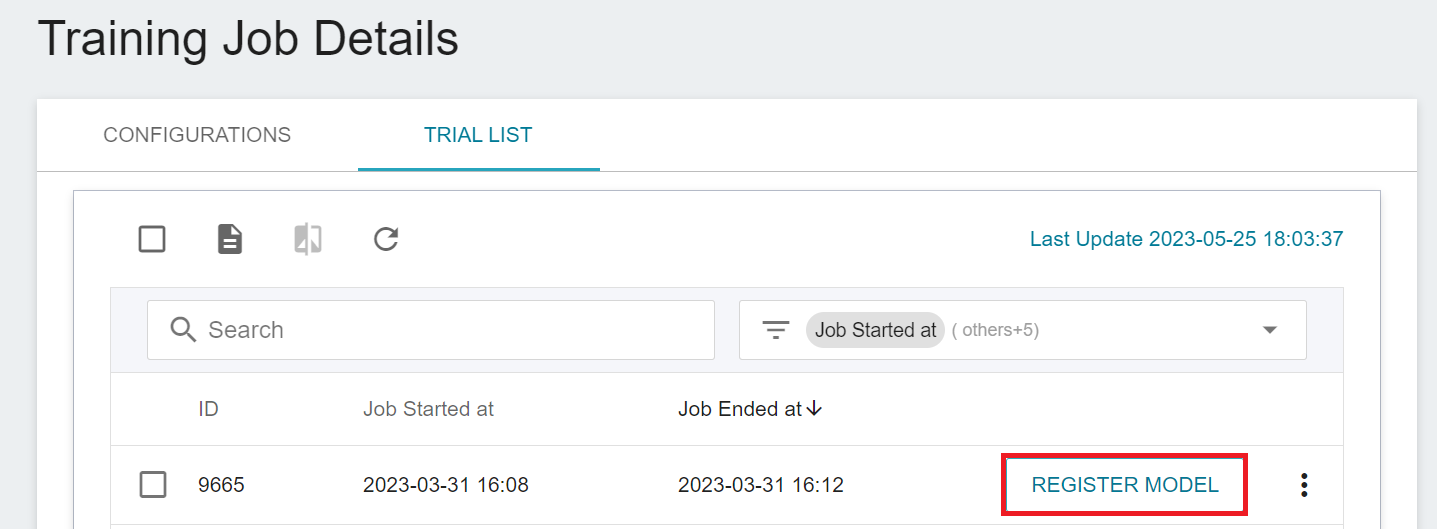
In the **Register Model** window, select **Model Source** and **Model Directory**, click the **Model Directory** menu to enter the name of the model directory to be created, for example: `mymodel` or choose an existing model directory.
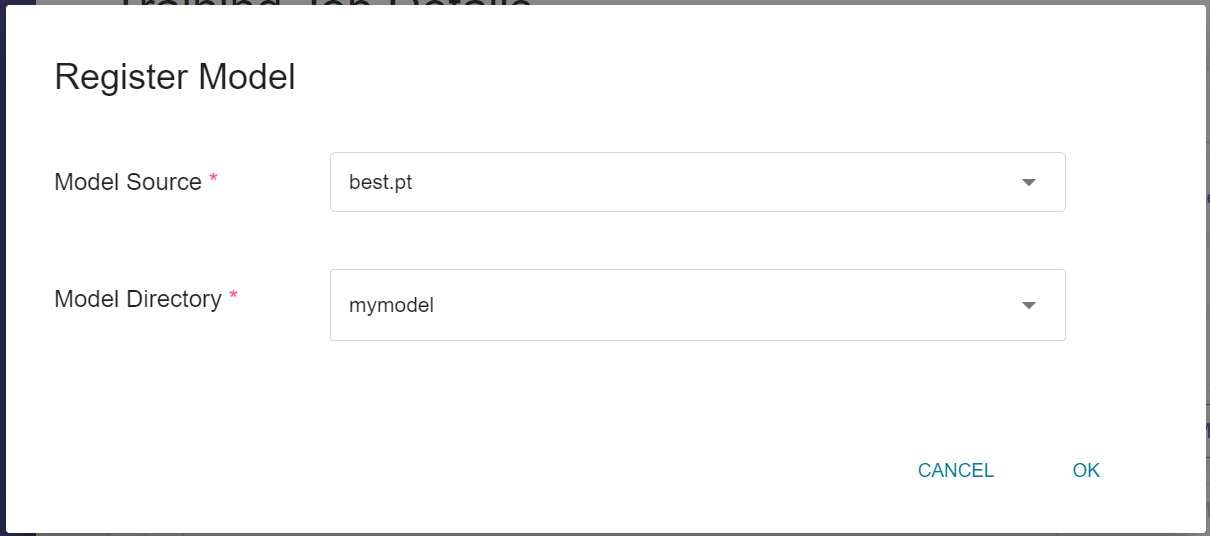
:::info
:bulb: **Tip: Model Source**
* `best.pt` represents the best model weight.
* `last.pt` represents the weight of the model after the last training.
:::
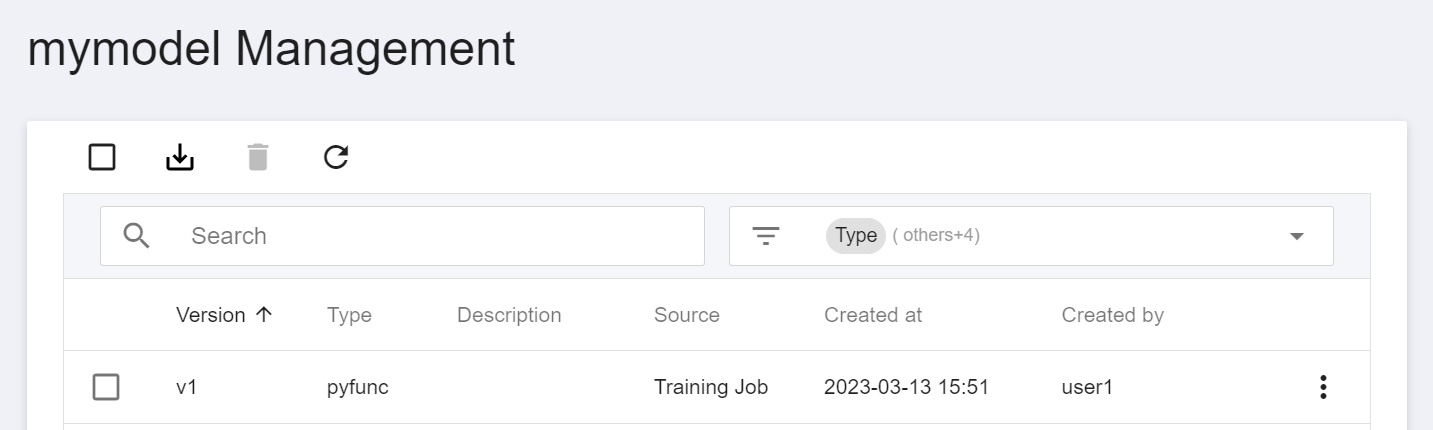
After saving, go back to the **Model Management** page. Find the model in the list, click to enter the version list of the model, you can see all the versions, descriptions, sources and results of the stored model.
## 4. Create Inference Service
After you have trained the YOLO network and stored the trained model, you can deploy it to an application or service to perform inference using the **Inference** function.
### 4.1 Create Inference Service
Select **AI Maker** from the OneAI services, then click **Inference** to enter the inference management page, and click **+CREATE** to create an inference service. The steps for creating the inference service are described below:
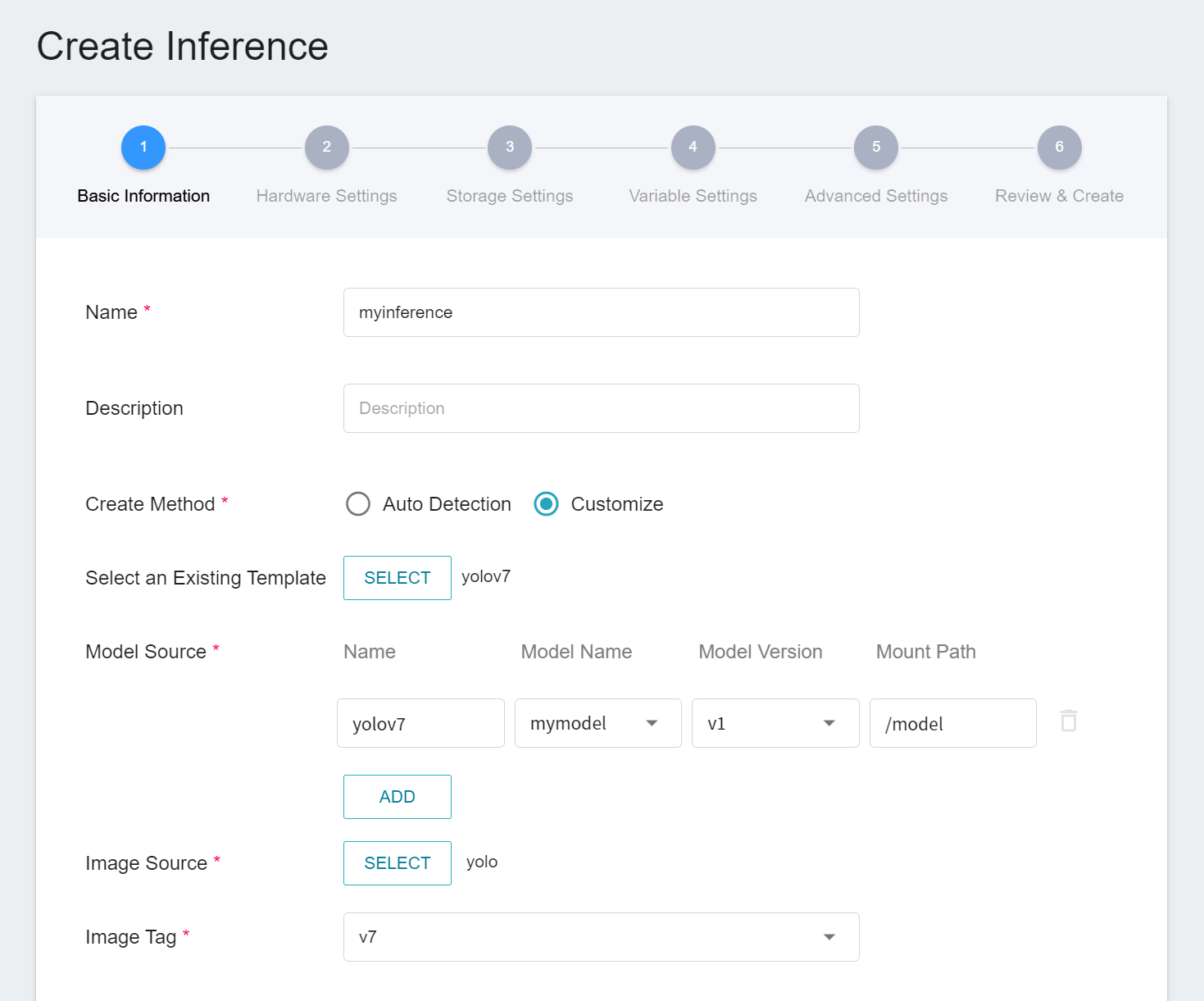
1. **Basic Information**
First, change the **Create Method** to **Customize** to apply the public template **`yolov7`** to load the default settings and deploy the model as an inference REST endpoint. However, although the default settings are loaded through the template, the model name and version still need to be set manually.
- **Name**
The file name of the loaded model relative to the program's ongoing read, this value will be set by the `yolov7` inference template.
- **Model Name**
The name of the model to be loaded, that is, the model we saved in [**3.4 Model Registration**](#34-Model-Registration).
- **Version**
The version number of the model to be loaded is also the version number set in [**3.4 Model Registration**](#34-Model-Registration).
- **Mount Path**
Location of the loaded model relative to the program's ongoing read, this value will be set by the `yolov7` inference template.
2. **Hardware Settings**
Select the appropriate hardware resource from the list with reference to the current available quota and training program requirements. In order to have the best experience, when choosing hardware, please choose a specification that includes a GPU and a CPU with 8 Cores or more.
3. **Storage Settings**
No configuration is required for this step.
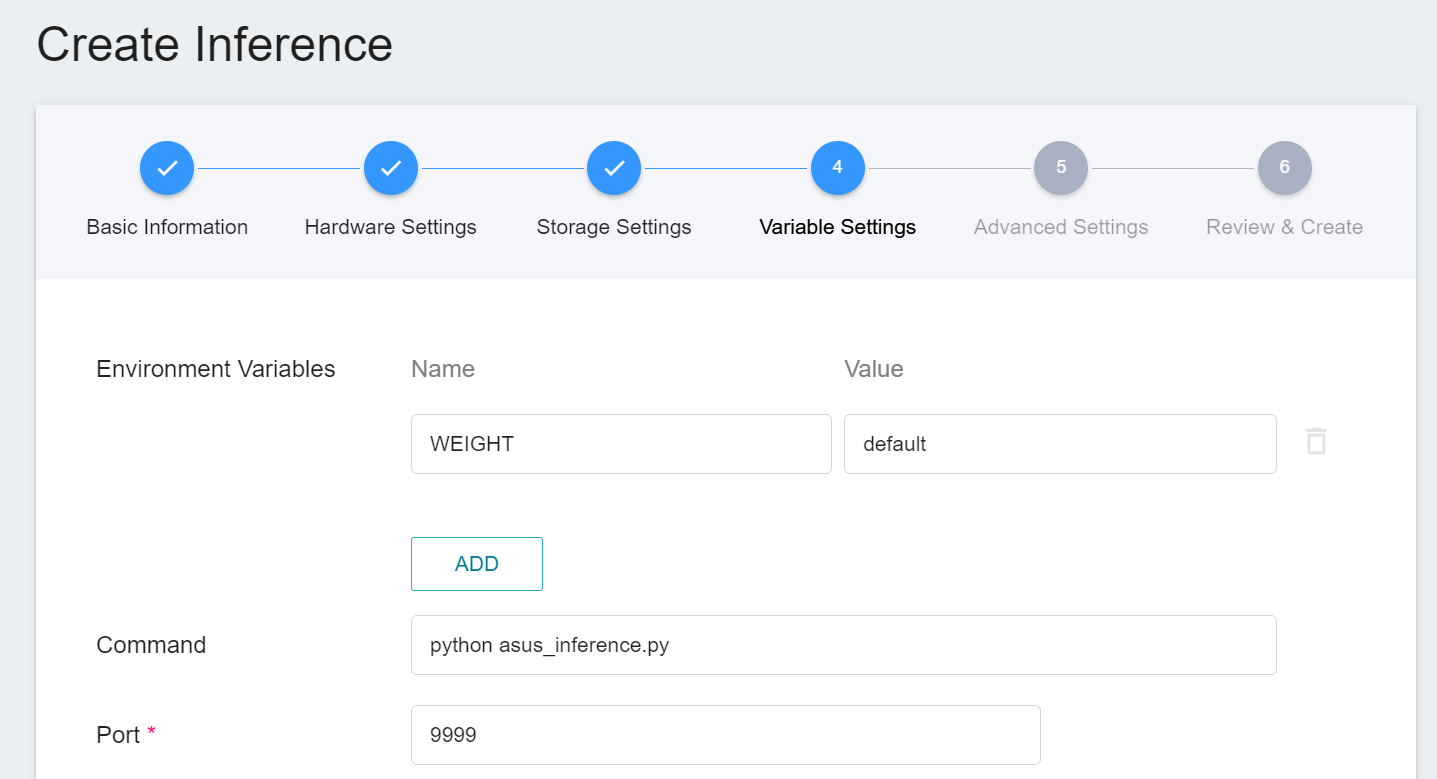
4. **Variable Settings**
In the Variable Settings page, these commands and parameters are automatically brought in when the **`yolov7`** template is applied.
5. **Advanced Settings**
* **Monitor Data**
The purpose of monitoring is to observe the number of API calls and inference statistics over a period of time for the inference service.

| Name | Type | Description |
|-----|-----|------------|
| object_detect | Tag | The total number of times the object has been detected in the specified time interval.<br> In other words, the distribution of the categories over a period of time.<br>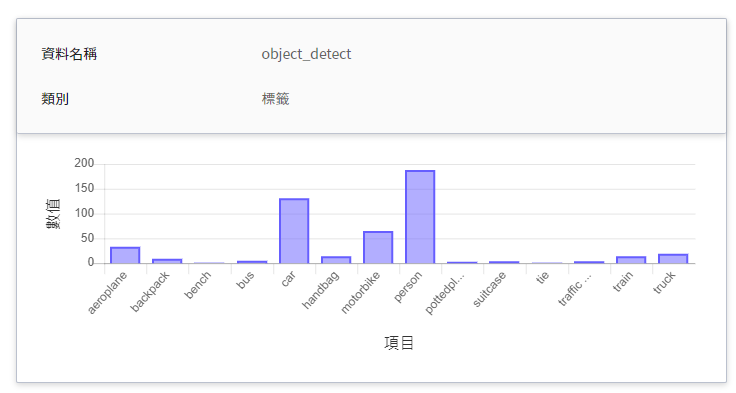|
| confidence | Number | The confidence value of the object being detected when the inference API is called once at a certain point in time.<br>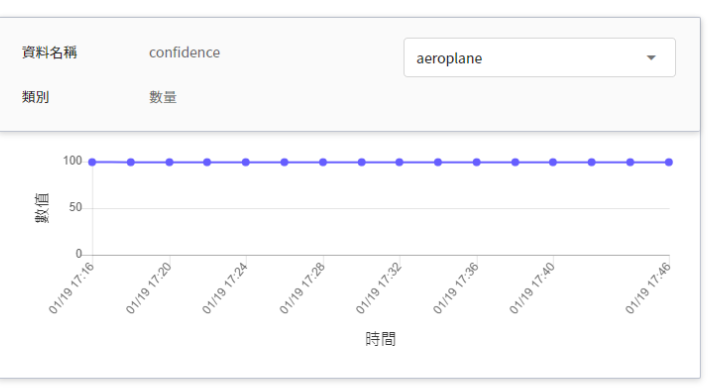|
6. **Review & Create**
Finally, confirm the entered information and click CREATE.
### 4.2 Making Inference
After completing the settings of the inference service, go back to the inference management page, you can see the service you just created, and click the list to view the detailed settings of the service. When the service state shows as **`Ready`**, click **VIEW LOG**.
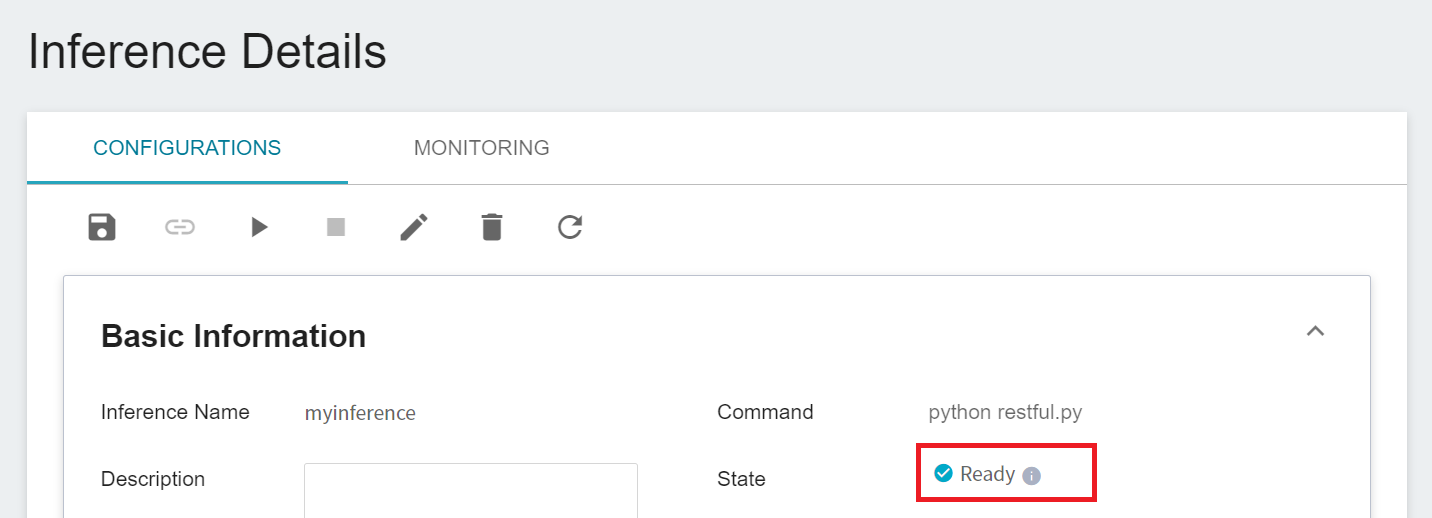
If you see the following message in the log, it means that the inference service is already in operation, you can start connecting to the inference service for inference.
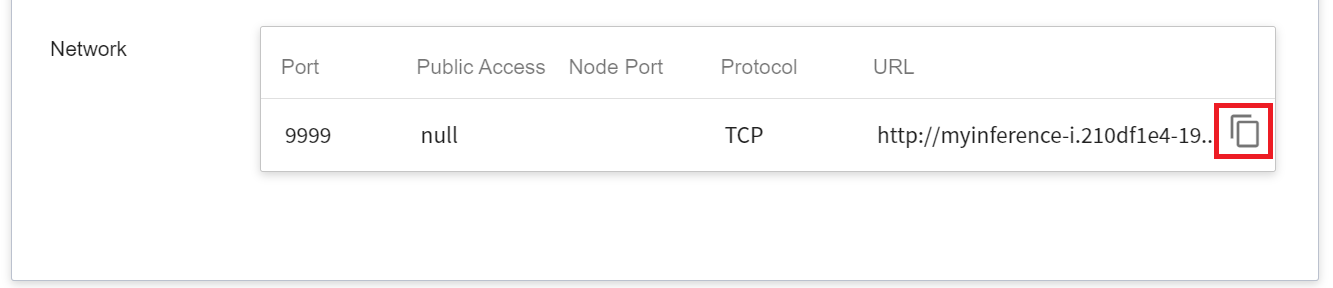
Worth noting is the **URL** in the detailed settings. Since the current inference service does not have a public service port for security reasons, we can communicate with the inference service we created through the **Notebook Service**. The way to communicate is through the **URL** provided by the inference service, which will be explained in the next section.
:::info
:bulb: **Tips: Inference Service URL**
- The URLs in the document are for reference only, and the URLs you got may be different.
- For security reasons, the **URL** provided by the inference service can only be used in the system's internal network, and cannot be accessed through the external Internet.
- To provide this Inference Service externally, please refer to [**AI Maker > Provide External Service**](/s/ai-maker-en#Making-Inference) for instructions.
:::
You can click on the **Monitor** tab to see the relevant monitoring information on the monitoring page, as shown in the figure below.
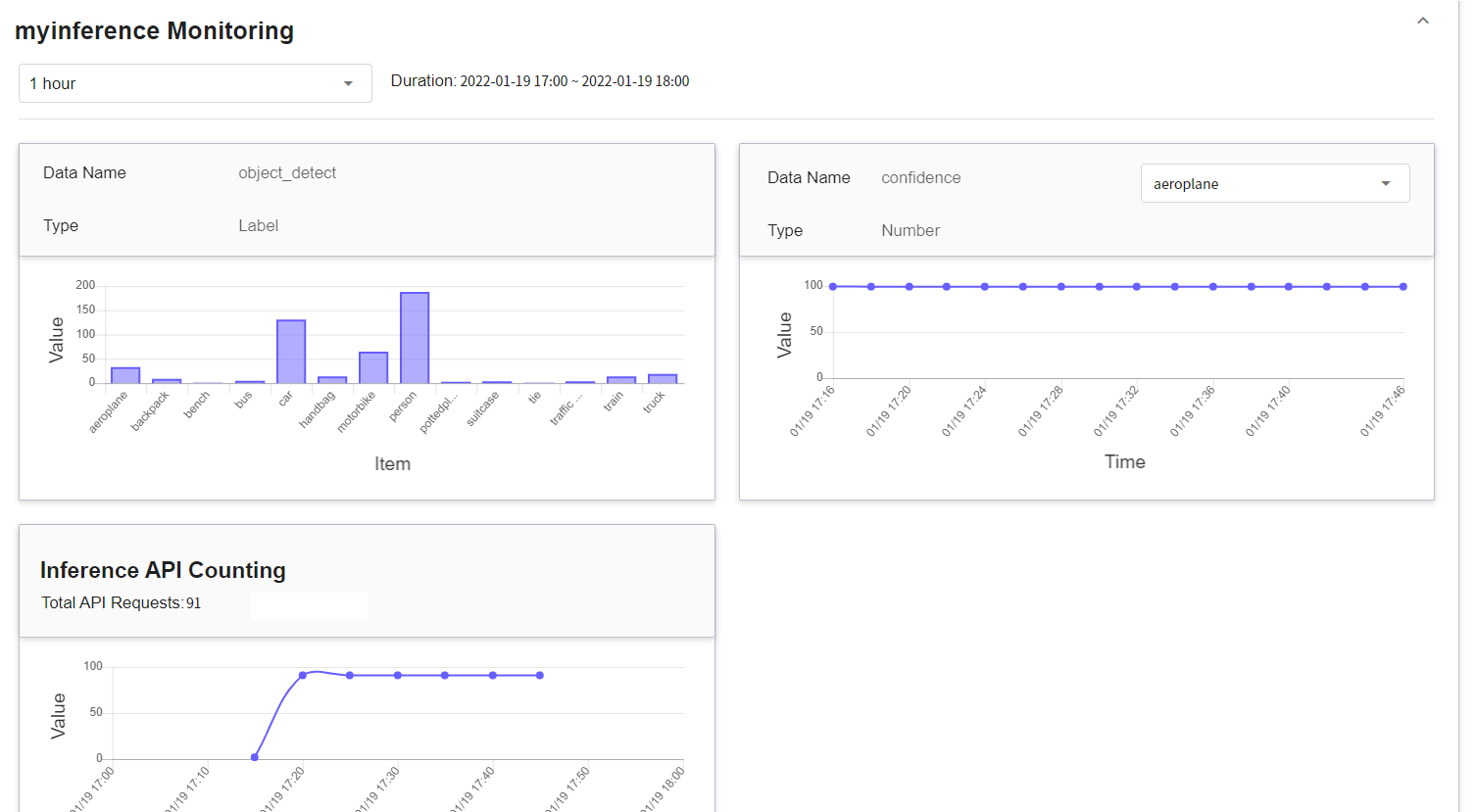
Click the Period menu to filter the statistics of the Inference API Call for a specific period, for example: 1 hour, 3 hours, 6 hours, 12 hours, 1 day, 7 days, 14 days, 1 month, 3 months, 6 months, 1 year, or custom.

:::info
:bulb: **Tips: About the Start and End Time of the Observation Period**
For example, if the current time is 15:10, then.
- **1 Hour** refers to 15:00 ~ 16:00 (not the past hour 14:10 ~ 15:10)
- **3 Hours** refers to 13:00 ~ 16:00
- **6 Hours** refers to 10:00 ~ 16:00
- And so on.
:::
## 5. Perform Image Recognition
In this chapter, we will use the PyTorch development framework `PyTorch-22.08-py3` provided by [**Notebook Service**](/s/notebook-en) to start JupyterLab and connect with the inference service.
### 5.1 Create a Notebook Service
Select **Notebook Service** from OneAI services to enter the **Notebook Service Management** page, then click **+ CREATE**.
1. **Basic Information**
When creating a notebook server, choose the PyTorch-22.08-py3 development framework.
2. **Hardware Settings**
Select the appropriate hardware resource from the list with reference to the current available quota and training program requirements. There is no need to configure GPU here.
3. **Storage Settings**
No configuration is required for this step.
4. **Review & Create**
Finally, confirm the entered information and click CREATE.
### 5.2 Use JupyterLab
After the Notebook Service is established successfully, enter the Details page of the Notebook Service. In the **Connection** block, click **Start** to start JupyterLab in the browser.
### 5.3 Making Inference
Open JupyterLab, we can copy [**5.4 Attachment Code**](#54-Attachmen-Code) to Notebook for execution, please modify this code according to your environment for inference, the code description is as follows.
#### 1. Send Request
This example uses the requests module to generate an HTTP POST request, and passes the image and parameters as a dictionary structure to the JSON parameter.
```python=1
# Initial Setup:
# INFE_URL:Inference URL
# threshold:Yolov7 inference threshold
# image_path:Image full path
# result_path:Result save full path
INFE_URL = "http://myinference-i.abf29785-7dd8-4c15-a06a-733f124772b3:9999"
threshold = 0.5
image_path = "/workspace/dog.jpg"
result_path = "/workspace/result/"
# Case2、Infrence
ROUTE = "/yolov7/detect"
url = "{base}{route}".format(
base=URL_BASE,
route=ROUTE)
with open(image_path, "rb") as inputFile:
data = inputFile.read()
body = {"image": base64.b64encode(data).decode("utf-8"), "thresh": threshold}
res = requests.post(url, json=body)
status_code = res.status_code
content = json.loads(res.content)
content = json.dumps(content, indent=4)
print("[code]:\t\t{code}\n[content]:\n{text}".format(code=status_code,text=content))
```
There are several variables that require special attention.
* **`INFE_URL`** need to be filled with the URL of the inference service.
The **`INFE_URL`**: in this example is **`http://myinference-i.abf29785-7dd8-4c15-a06a-733f124772b3:9999`**, please modify to your inferernce service URL.
* **`threshold`** It means that when the predicted confidence value must be greater than this value, it can be classified as this category.
* **`image_path`** It is the image path to be inferred, and the image in this example is obtained through the following command.
<br>
```shell=
wget https://raw.githubusercontent.com/WongKinYiu/yolov7/main/deploy/triton-inference-server/data/dog.jpg -P /workspace/
```
#### 2. Retrieve Results
After the object detection is completed, the results are sent back in JSON format:
* **`results`**: an object array, including one or more object detection results. If no object can be detected, an empty array is returned.
- **`points`**: [xmin, ymin, xmax, ymax].
- **`label`**: the classification result of this object.
- **`confidence`**: the confidence score for the classification of this object.
Once we have this information, we can draw the bounding accordingly.

Based on these two programs, a request can be sent to the inference service, and the detection results can be retrieved and plotted on the original image.
:::info
:bulb: **Tips:** This example only supports displaying labels in English.
:::
### 5.4 Attached Code
:::spoiler **Program Code**
```python=1
import numpy as np
import base64
import io
import os
import requests
import json
from PIL import Image as Images,Image,ImageDraw
from IPython.display import Image, clear_output, display
import cv2
%matplotlib inline
from matplotlib import pyplot as plt
from pathlib import Path
from os.path import join
# Initial Setup:
# INFE_URL:Inference URL
# threshold:Yolov7 inference threshold
# image_path:Image full path
# result_path:Result save full path
INFE_URL = "http://myinference-i.abf29785-7dd8-4c15-a06a-733f124772b3:9999"
threshold = 0.5
image_path = "/workspace/dog.jpg"
result_path = "/workspace/result/"
# Case1、Connect test
URL_BASE = "{url}".format(url=INFE_URL)
ROUTE = "/yolov7"
url = "{base}{route}".format(
base=URL_BASE,
route=ROUTE)
try:
res = requests.get(url)
print("[code]:\t\t{code}\n[content]:\t{text}".format(code=res.status_code,text=res.text))
except requests.exceptions.RequestException as e:
print(e)
# Case2、Infrence
ROUTE = "/yolov7/detect"
url = "{base}{route}".format(
base=URL_BASE,
route=ROUTE)
with open(image_path, "rb") as inputFile:
data = inputFile.read()
body = {"image": base64.b64encode(data).decode("utf-8"), "thresh": threshold}
res = requests.post(url, json=body)
status_code = res.status_code
content = json.loads(res.content)
content = json.dumps(content, indent=4)
print("[code]:\t\t{code}\n[content]:\n{text}".format(code=status_code,text=content))
# Display Result
def arrayShow(imageArray):
resized = cv2.resize(imageArray, (500, 333), interpolation=cv2.INTER_CUBIC)
ret, png = cv2.imencode('.png', resized)
return Image(data=png)
if not os.path.exists(result_path):
os.makedirs(result_path)
output = join(result_path,str(Path(image_path)))
color = (255, 0, 0)
detected = res.json()
objects_json = json.loads(detected.get('results'))
oriImage = cv2.imread(image_path)
img_pil = Images.fromarray(cv2.cvtColor(oriImage, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_pil)
for obj in objects_json:
xmin = (obj['points'][0])
ymin = (obj['points'][1])
xmax = (obj['points'][2])
ymax = (obj['points'][3])
label = (obj['label'])
confidence = obj['confidence']
pos = tuple((int(xmin),int(ymin)))
box = (int(xmin), int(ymax)), (int(xmax), int(ymin))
draw.text(pos, label, fill = color)
draw.rectangle(box,outline="green")
cv_img = cv2.cvtColor(np.asarray(img_pil),cv2.COLOR_RGB2BGR)
cv2.imwrite(output, cv_img)
img = arrayShow(cv_img)
clear_output(wait=True)
display(img)
```
:::
## 6. CVAT Assisted Annotation
CVAT has assisted annotation function to save time in manual annotation. As deep learning model is required to use CVAT to provide assisted annotation, you can train your own deep learning model by referring to the [**Training YOLO Model**](#3-Training-YOLO-Model). This section will introduce how to use the trained deep learning model to perform assisted annotation of image data with CVAT annotation tool.
### 6.1 Create YOLOv7 Assisted Annotation Service
The AI Maker system provides a **yolov7-cvat** inference template that allows you to quickly create assisted annotation inference services for the **yolov7 model**.
First, click **Inference** on the left to enter the **Inference Management** page, and click **+CREATE** to create an inference service.
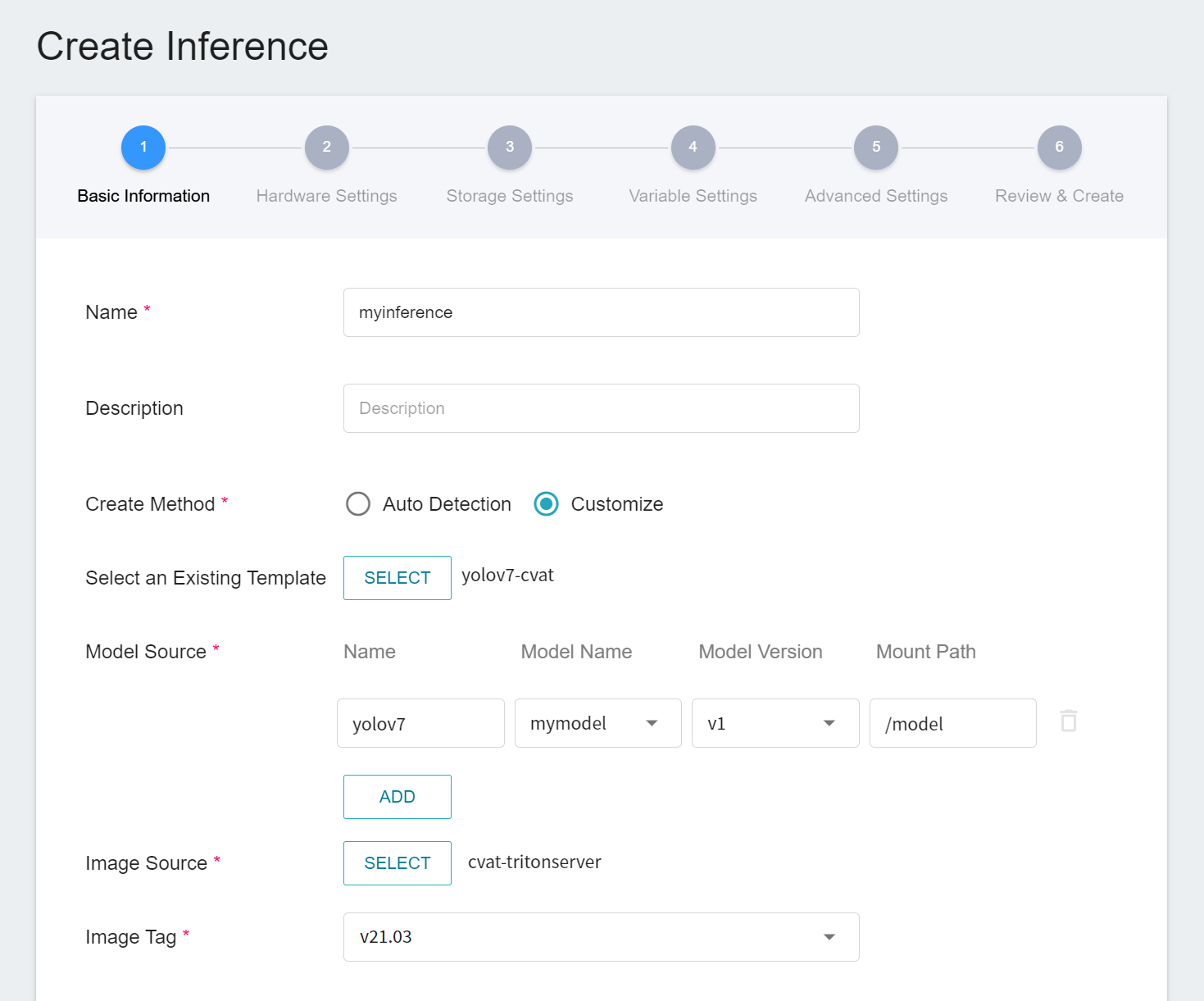
1. **Basic Information**
Enter basic information about the inference service, select the **`yolov7-cvat`** template and choose the name and version of the model to be used for assisted annotation in the **Source Model**.
2. **Hardware Settings**
Select the appropriate hardware resource from the list with reference to the current available quota and training program requirements.
:::info
:bulb: **Tips:** For a better and faster experience with the assisted annotation function, please select the hardware option with GPU for the hardware settings.
:::
3. **Storage Settings**
No configuration is required for this step.
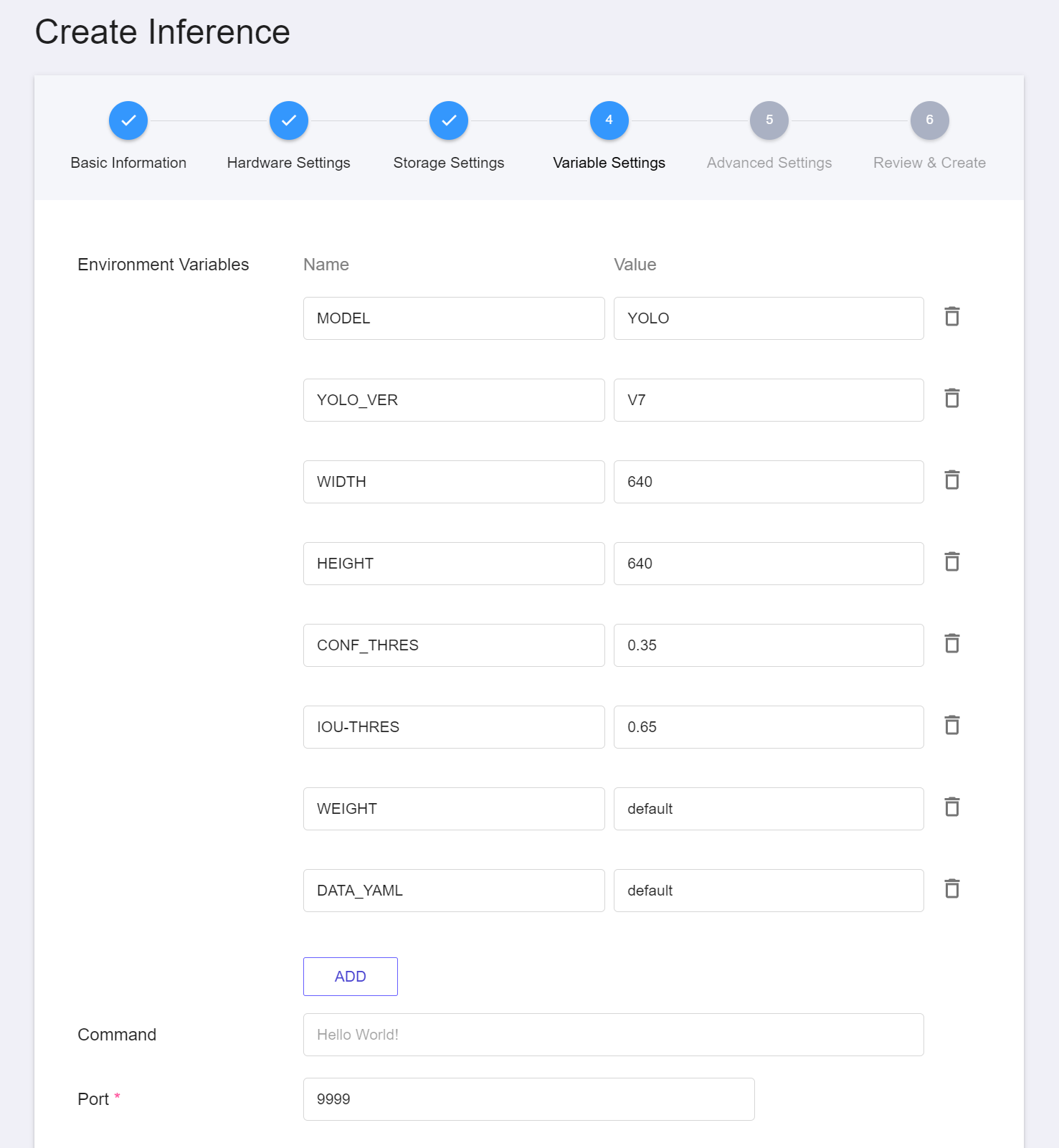
4. **Variable Settings**
In the Variable Settings page, these commands and parameters are automatically brought in when the **`yolov7-cvat`** template is applied.
5. **Subsequent Steps**
The subsequent steps are similar to those of other tasks and will not be repeated here.
### 6.2 Connect to CVAT
After you have created YOLOv4 assisted annotation inference service, you need to take another step to connect your inference service to CVAT. There are three places in AI Maker's inference service to connect to the CVAT service:
1. **CVAT Management** page
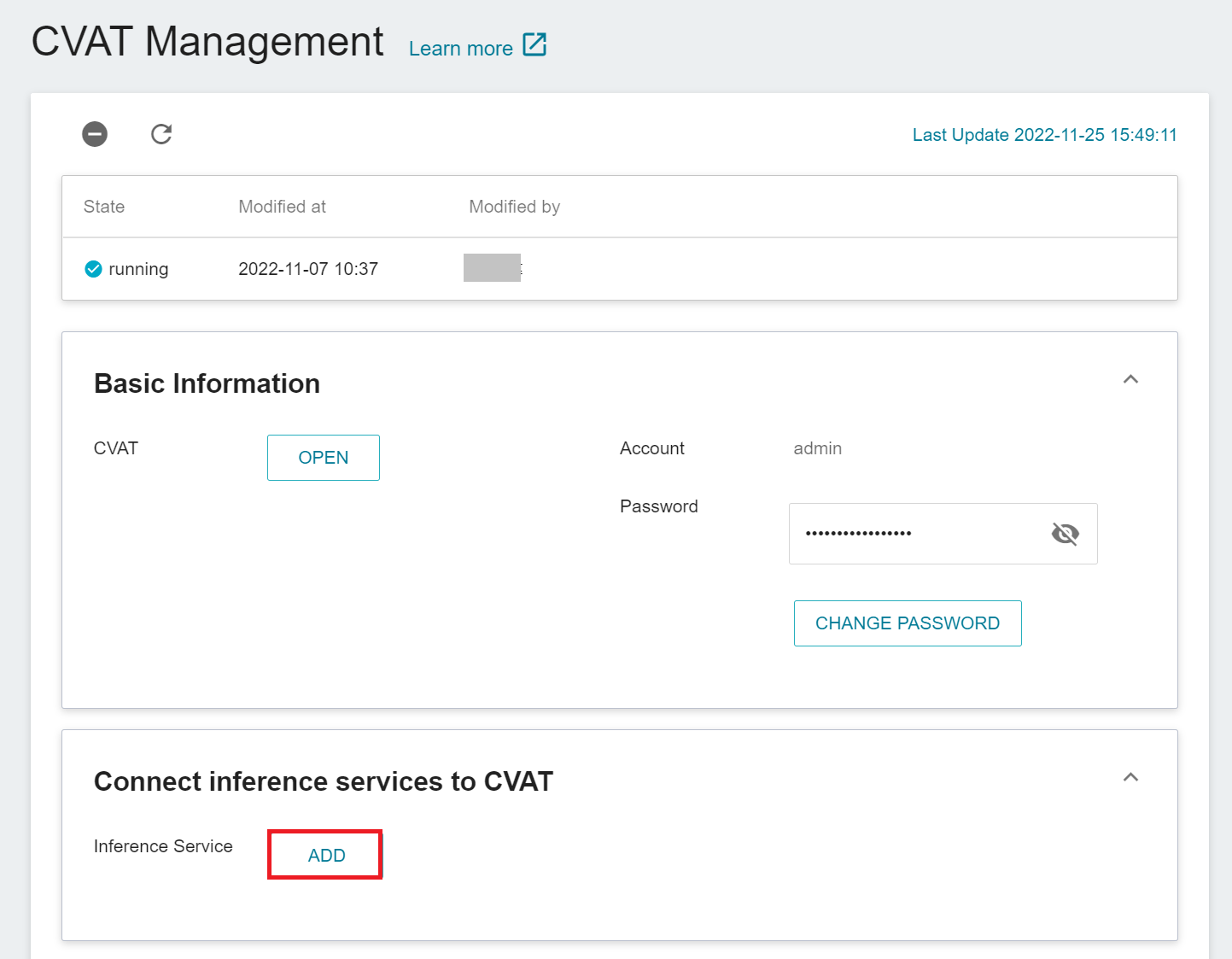
Click **Annotation Tools** on the left menu bar to enter the CVAT service home page. You need to click **ENABLE CVAT SERVICE** if you are using it for the first time. Only one CVAT service can be enabled for each project.
After entering the **CVAT Management** page, click the **ADD** button under the **Connect Inference Service to CVAT** section. If an existing inference service is connected to the CVAT, this button will change to **EDIT**.
After the **Connect Inference Service to CVAT** window appears, select the inference service you want to connect to.
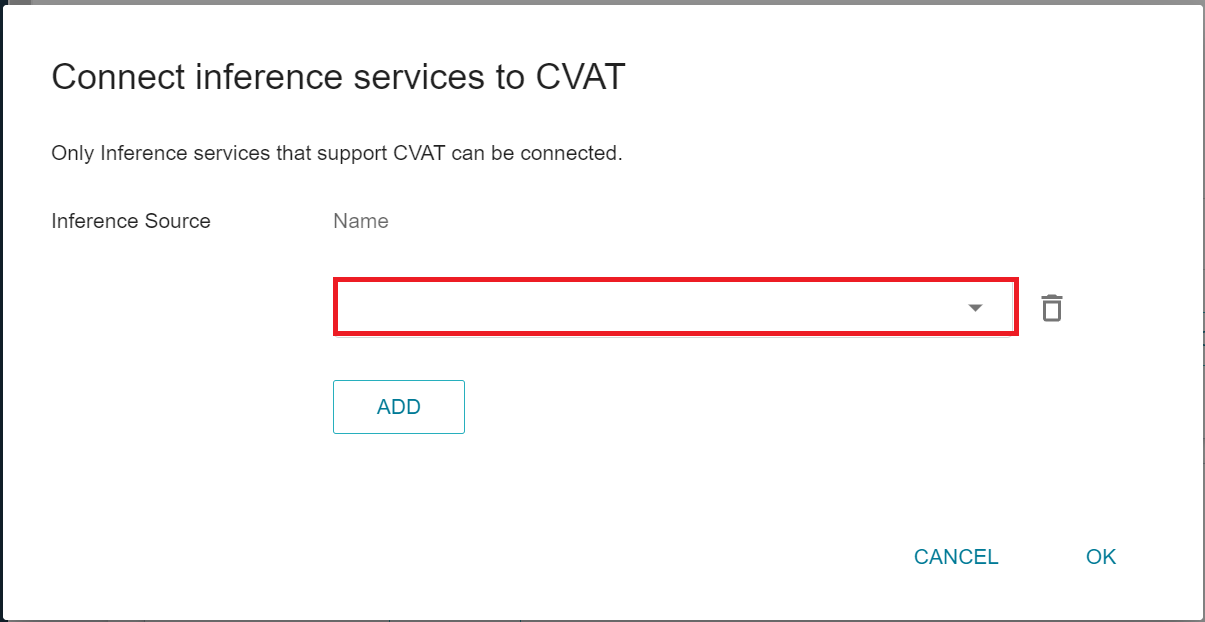
2. **Inference Management** page
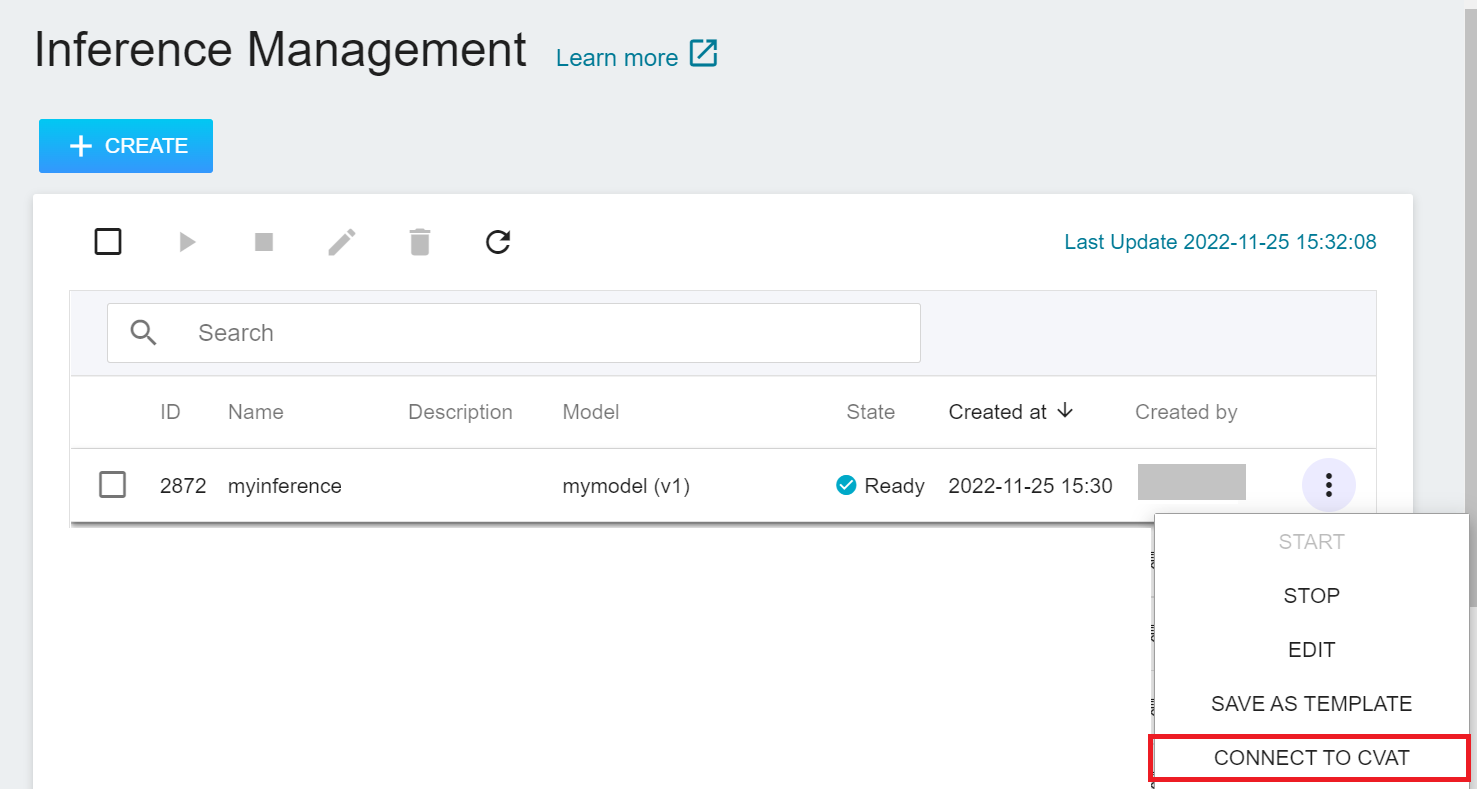
Click **Inference** on the left function bar to enter **Inference Management**, move the mouse to the more options icon on the right side of automatic annotation task, and then click **CONNECT TO CVAT**.
3. **Inference Details** page
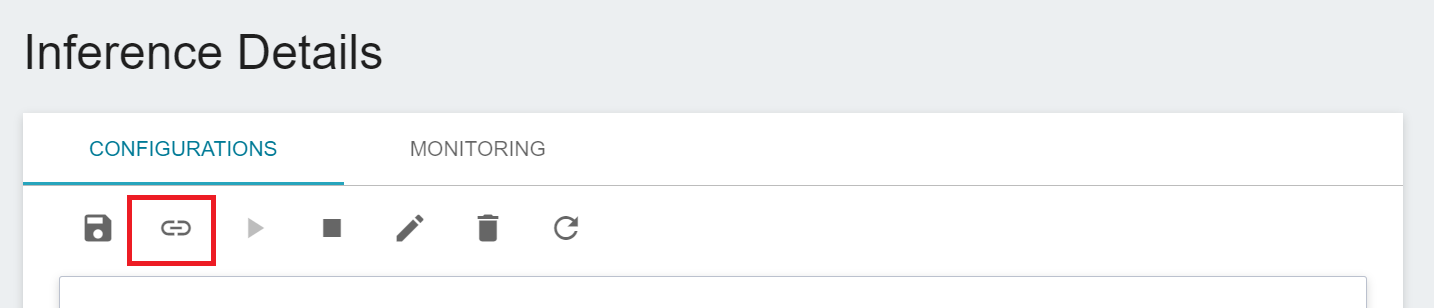
Click the inference task list you want to connect to CVAT, enter the **Inference Details** page, and then click the **CONNECT TO CVAT** icon above.
### 6.3 Use CVAT Assisted Annotation Function
After you have completed the above steps, you can then log in to CVAT to use the assisted annotation function. Please refer to the instructions below for the steps:
1. View CVAT Model
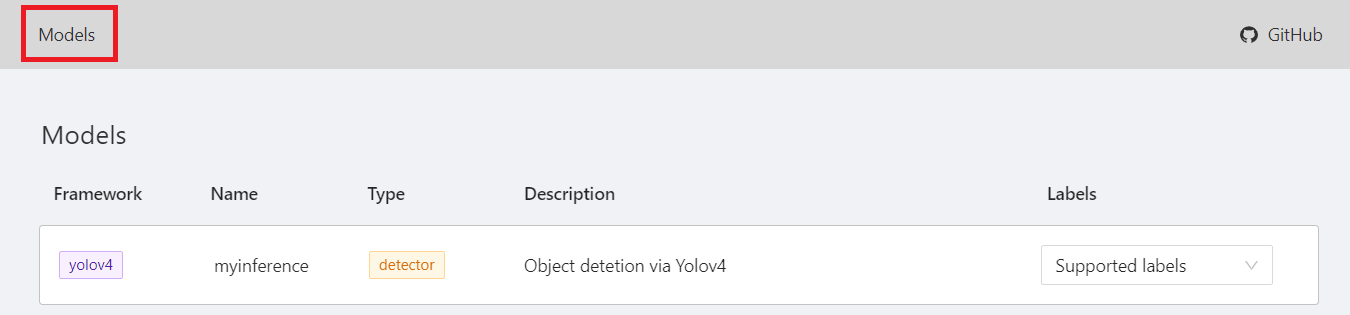
After entering the CVAT service page, click **MODELS** at the top, and you can see the inference service you just connected to CVAT.
2. Enable Assisted Annotation Function
Go to the **Tasks** page and find the Task you want to annotate, then move the mouse over the More options icon in **Actions** to the right of the Task you want to annotate automatically, and then click **AUTOMATIC ANNOTATION**.
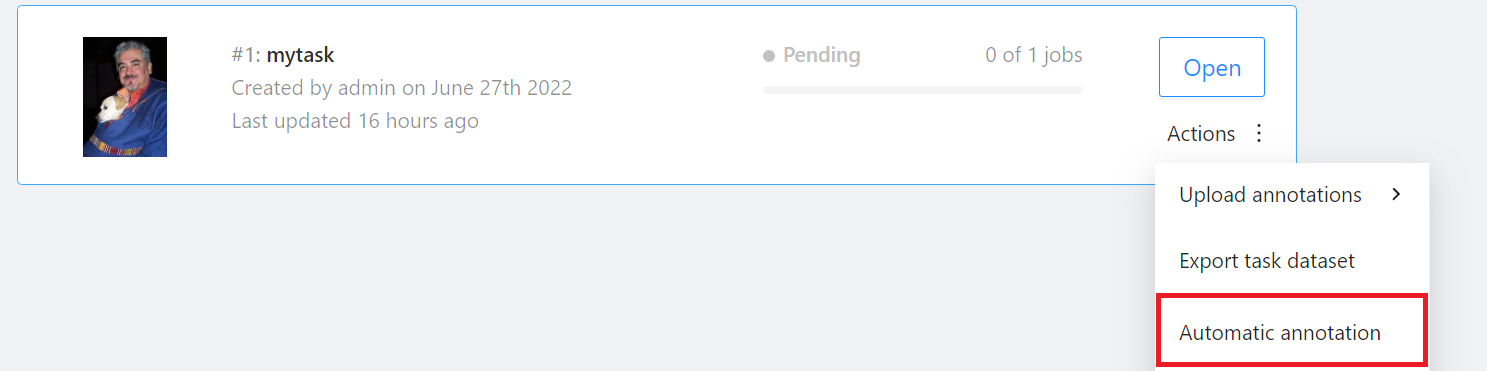
On the **Automatic Annotation** window that appears, click the **MODEL** drop-down menu and select the connected inference task.
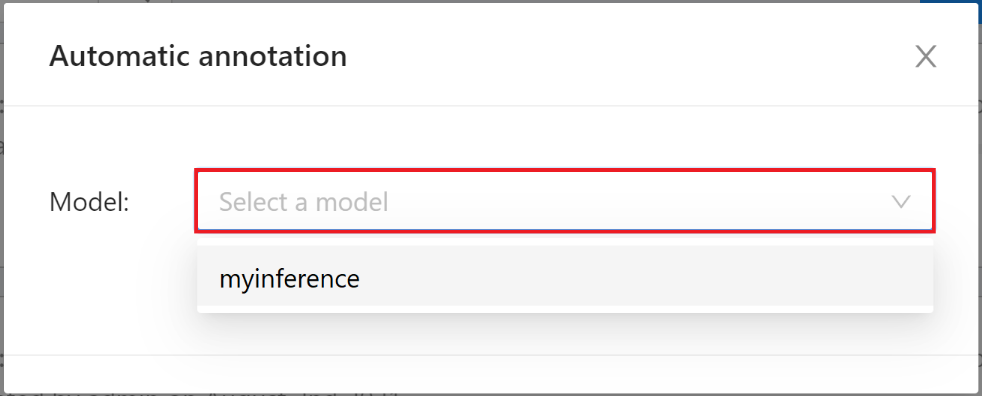
Then set the model to correspond to the task Label, and finally click **ANNOTATE** to perform automatic annotation.
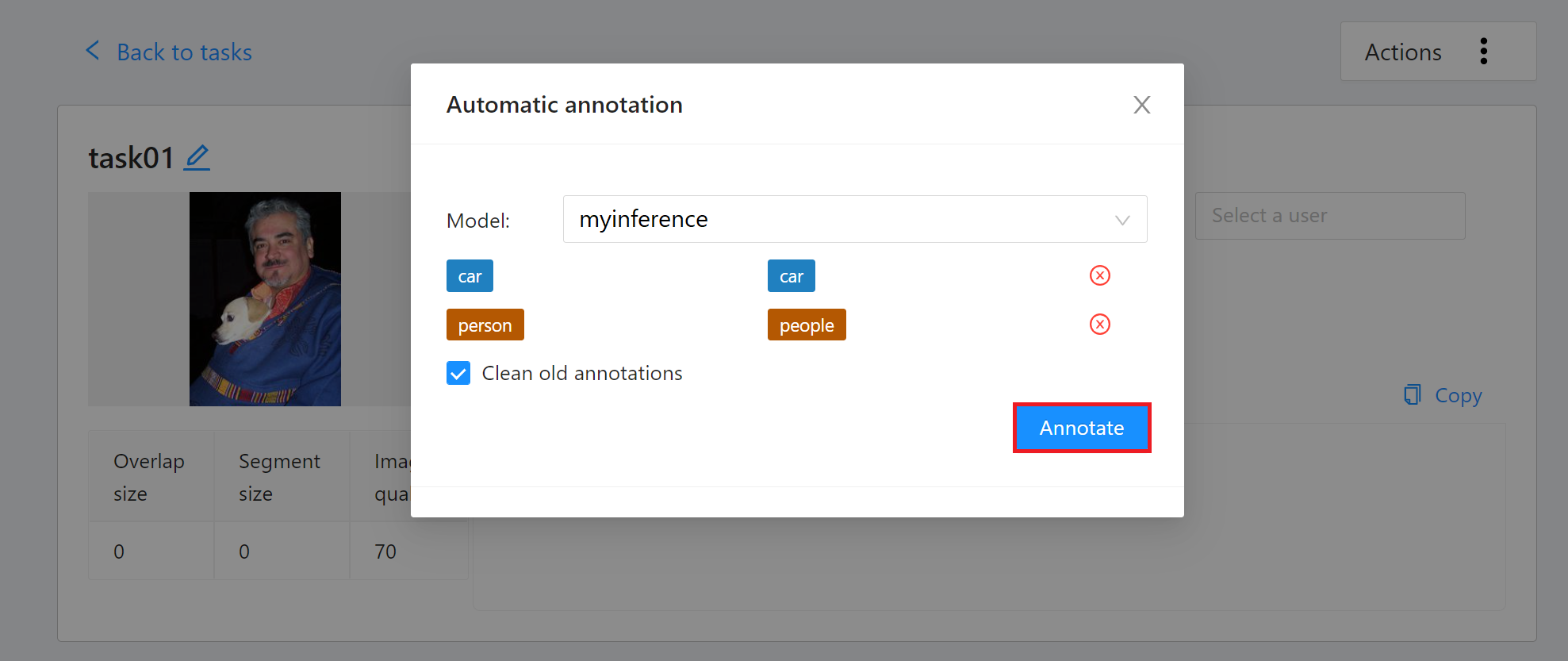
Once the automatic annotation task has started, you can see the percentage of completion. It will take some time to annotate a large amount of data, and a message will appear on the screen after the annotation is completed.

After the annotation is completed, enter the CVAT Annotation Tools page to view the automatic annotation result. If you are not satisfied with the result, you can perform manual annotation correction or retrain and optimize the model.
