---
description: OneAI Documentation
tags: EN, Case Study, Hugging Face
---
[OneAI Documentation](/s/user-guide-en)
# AI Maker Case Study - Hugging Face Text Classification
[TOC]
## 0. Introduction
[**Hugging Face**](https://huggingface.co/) is an open AI community that supports mainstream deep learning frameworks and provides a wide range of pre-trained models, datasets, and development tools, including various AI applications such as natural language processing, speech recognition, and image recognition.
By using the **`huggingface`** container image provided by OneAI and the **job** templates integrated with `PyTorch` and `transformers` framework in AI Maker, you can leverage OneAI's computational resources to accelerate the development of AI applications.
[<img src="/uploads/6bIAAox.png">](https://huggingface.co/models)
<center><a href="https://huggingface.co/models">(Image source: Hugging Face)</a></center>
<br><br>
In this example, we will use the template provided by AI Maker for Hugging Face text classification application to gradually build a text classification application. This template defines the environment variables, images, programs, and other settings required by the training job and inference task. You only need to prepare the dataset for training or the model for inference to quickly perform training jobs and inference tasks.
The main steps are as follows:
- **Dataset Preparation**
At this stage, we will download public datasets from [**Hugging Face Datasets**](https://huggingface.co/datasets) and prepare formatted data suitable for this model training.
- **Train the Model**
At this stage, we will configure the training job for model training and fitting, and store the trained model.
- **Create Inference Service**
At this stage, we deploy the stored model to the service to perform inference.
:::info
:bulb: **Tips: Reference Information**
* [Hugging Face official website](https://huggingface.co/)
* [Hugging Face - Text classification](https://huggingface.co/docs/transformers/v4.21.1/en/tasks/sequence_classification)
* [Hugging Face - IMDB Dataset](https://huggingface.co/datasets/imdb)
:::
## 1. Prepare the Dataset
In this section, we will use code to download [**IMDB public dataset**](https://huggingface.co/datasets/imdb) provided by Hugging Face Datasets. If you want to use your own dataset, you just need to ensure it conforms to the [**training data format**](#11-Data-Format-Description) described in this section and upload it to the bucket in **Storage Service**.
### 1.1 Data Format Description
This example divides movie reviews into two categories, `neg` for negative reviews and `pos` for positive reviews. `label` can be set as a number or a text, if the training data `label` is a number, the inference prediction result is also a number, and vice versa.
The training data supports **CSV** or **JSON** format and is presented as two-column data.
| Columns | Description | Example |
| --- | --- | --- |
| `label` | Classification categories, which can be numeric or text labels | pos |
| `text` | Text content | "I love you" |
#### Sample CSV Format
```csv
label,text
neg,"I rented I AM CURIOUS-YELLOW ..."
pos,"*Contains spoilers due to ..."
...
```
#### Sample JSON Format
```json
{"label": "neg", "text": "I rented I AM CURIOUS-YELLOW ...."}
{"label": "pos", "text": "*Contains spoilers due to ..."}
...
```
### 1.2 Create a Bucket
Select **Storage Service** from the OneAI services to enter the Storage Service Management page, and then click **+ CREATE** to add a bucket named **`hf-imdb`**. This bucket is used to store our dataset.
### 1.3 Download Dataset
In this section, we will use OneAI's **Notebook Service** to download the train and test datasets from [**Hugging Face Datasets**](https://huggingface.co/docs/datasets/index) for [**IMDB (movie review dataset)**](https://huggingface.co/datasets/imdb) as training and validation data.
#### 1.3.1 Create Notebook Service
Select **Notebook Service** from the OneAI services to enter the Notebook Service Management page, and then click **+ CREATE**. The information for creating Notebook Service is as follows. For more information, please refer to [**Notebook Service**](/s/notebook-en) documentation.
* Basic Information
- Name: **`hf-demo`**, duplicated names are not allowed, please create your own name
- Framework: **`PyTorch-21.02-py3`**
* Hardware settings: choose the minimum computing resources
* Storage settings: bucket to be mounted for training data
- Mount Path: **`/workspace`**
- Storage: **`/hf-imdb`**
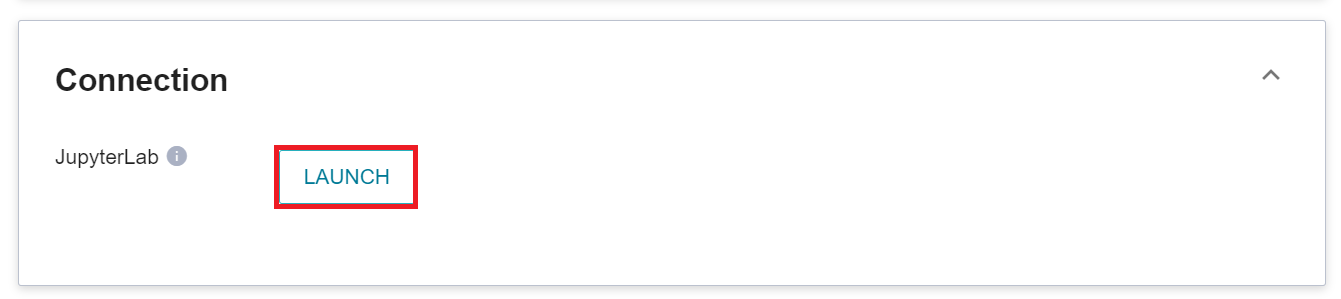
After the Notebook Service is created, enter the Notebook Service Details page, and in the **Connection** section, click **LAUNCH** on the right side of JupyterLab.
#### 1.3.2 Download and Process Data
After launching JupyterLab, create a Notebook named **`download.ipynb`**.
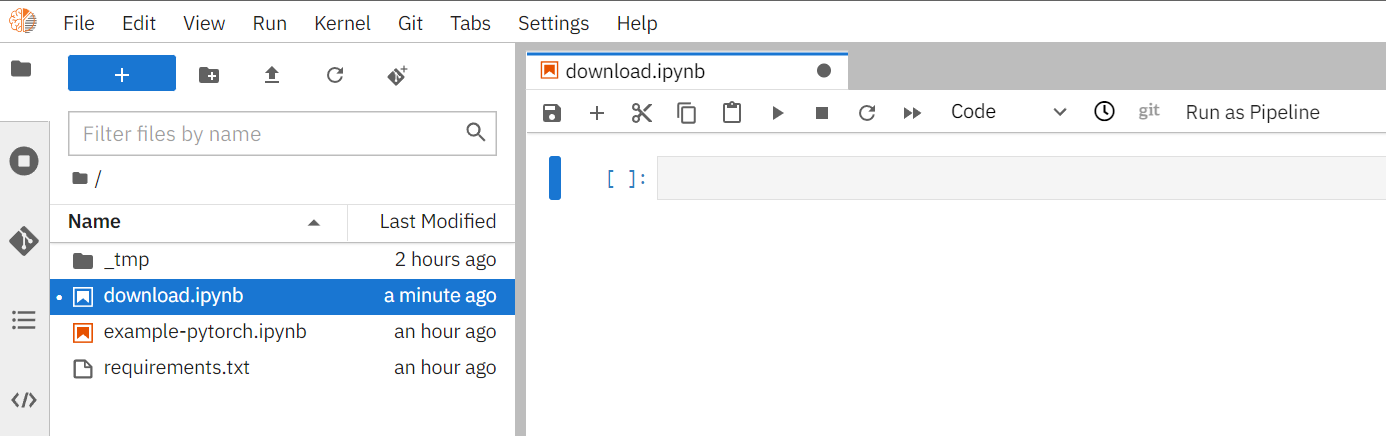
Next, copy and execute the following code to download the dataset.
```python=
# Install Datasets library
!pip install datasets==2.3.2
# Download Hugging Face Dataset
# Please Ensure That There Are No Folders with the Same Name as the Variable in the Storage Space to Avoid Any Errors.
folder = "imdb"
from datasets import load_dataset
imdb = load_dataset("imdb")
print(imdb)
print(imdb['train'].features)
print(imdb['train'][0])
# Save in Corresponding Format
import csv
import os
def save2CSV(dataset, outputFile):
data = dataset.map(
lambda texts, labels: {
"text": texts,
"class": [dataset.features["label"].int2str(sample) for sample in labels]
},
input_columns=["text", "label"], batched=True
)
os.makedirs(os.path.dirname(outputFile), exist_ok=True)
with open(outputFile, 'w+', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['label', 'text'])
for record in data:
writer.writerow([record["class"], record["text"]])
save2CSV(imdb['train'], 'imdb/train.csv')
save2CSV(imdb['test'], 'imdb/val.csv')
```
After execution, the `imdb` folder will be generated and will contain two files, `train.csv` and `val.csv`. The directory structure is as follows:
```
└── imdb
├── train.csv
└── val.csv
```
## 2. Train Text Classification Task Model
After completing the [**Dataset Preparation**](#1-Prepare-the-Dataset), you can use these data to train and fit our text classification model.
### 2.1 Create Training Job
Select **AI Maker** from the OneAI services, and then click **Training Job** to enter the Training Job Management page. AI Maker provides two training methods: **Smart ML Training Job** and **Normal Training Job**. Different parameters must be set for different training methods.
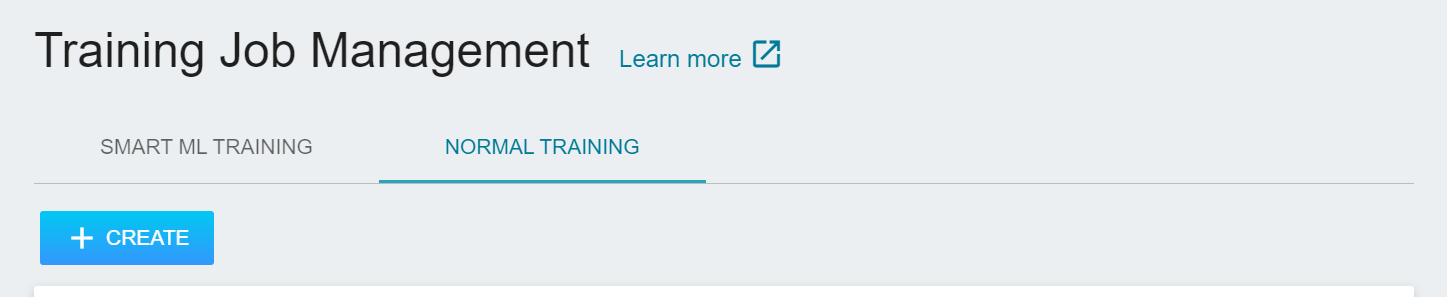
- **Normal Training Job**
Perform a one-time training job based on your given training parameters.
- **Smart ML Training Job**
Hyperparameters can be automatically adjusted, and computing resources can be efficiently used for multiple model training to save you time and cost in analyzing and adjusting model training parameters.
In this example we choose **Normal Training Job** to create a new training job. The steps to create a training job are as follows. For detailed instructions, please refer to the [**AI Maker > Training Job**](/s/ai-maker-en#Training-Job).
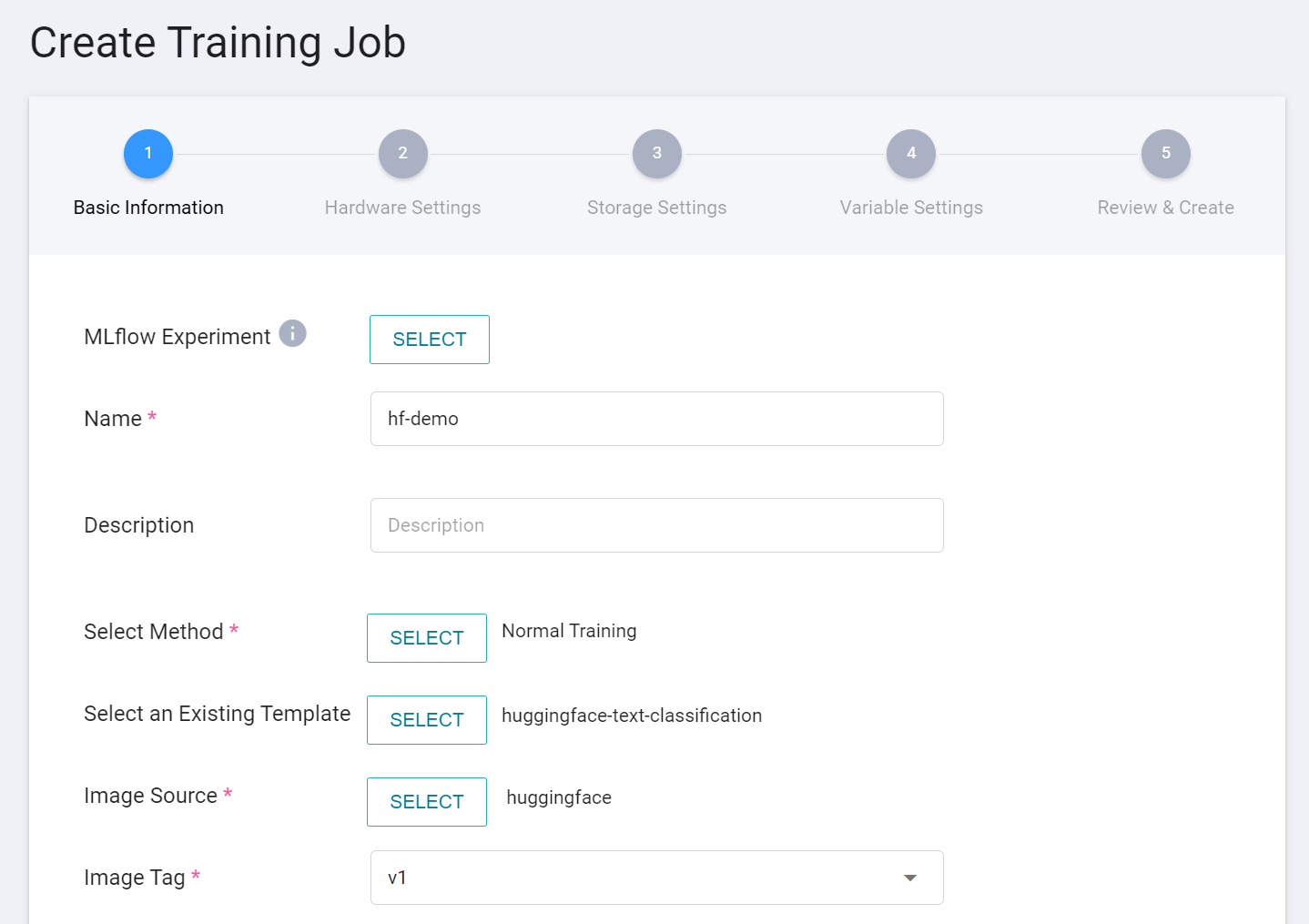
1. **Basic Information**
**AI Maker** provides a **`huggingface-text-classification`** template for text classification training. After entering the name and description, you can select the **`huggingface-text-classification`** template provided by the system to automatically bring up the public image **`huggingface:v1`** and parameter settings for subsequent steps.
:::info
:bulb: **Tips:** Duplicated names are not allowed, please create your own name.
:::
2. **Hardware Settings**
Based on the current available quota and the requirements of the training program, select the appropriate hardware resources from the list, and select the hardware option including **GPU** to accelerate the computation.
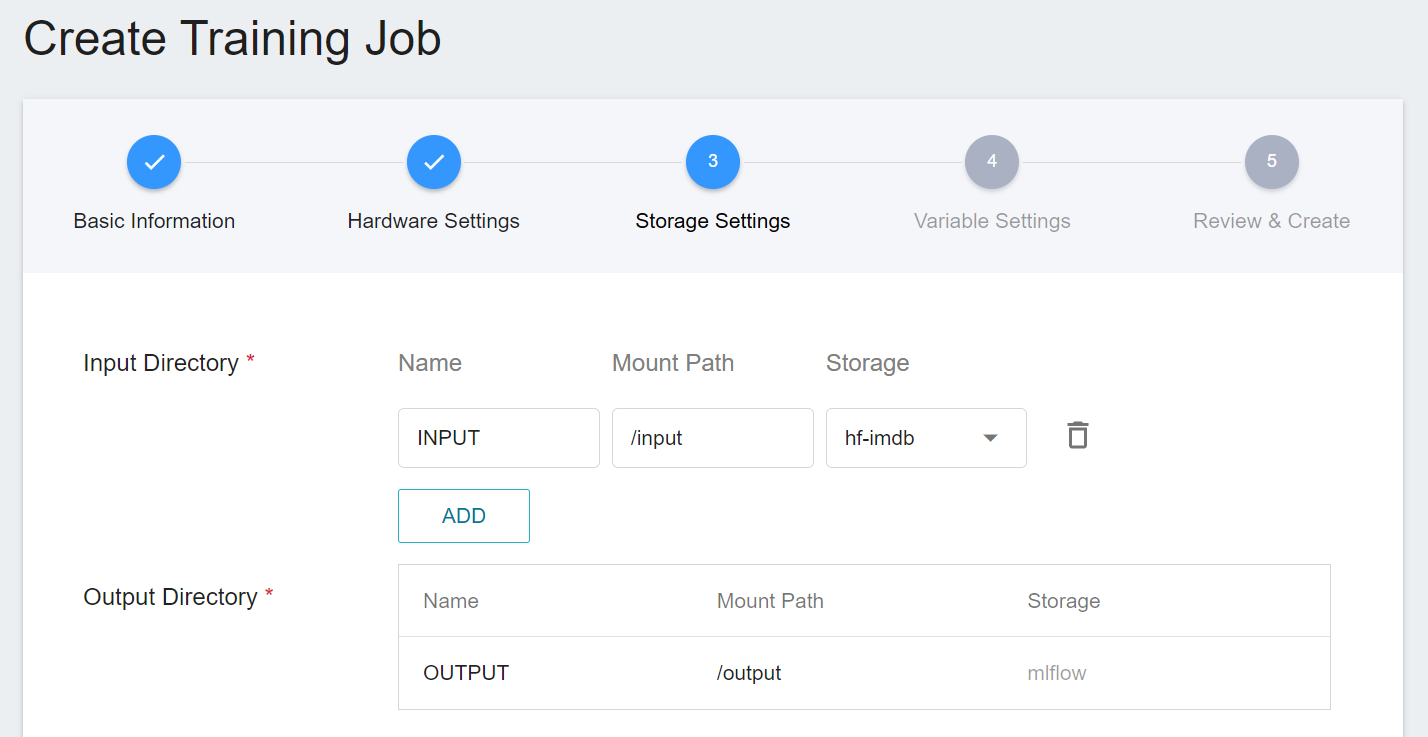
3. **Storage Settings**
This stage is to mount the bucket storing the training data into the training environment. The mount path and environment variables are already set in the template. Here, you only need to select the bucket created in the step [**Create a Bucket**](#12-Create-a-Bucket).
4. **Variable Settings**
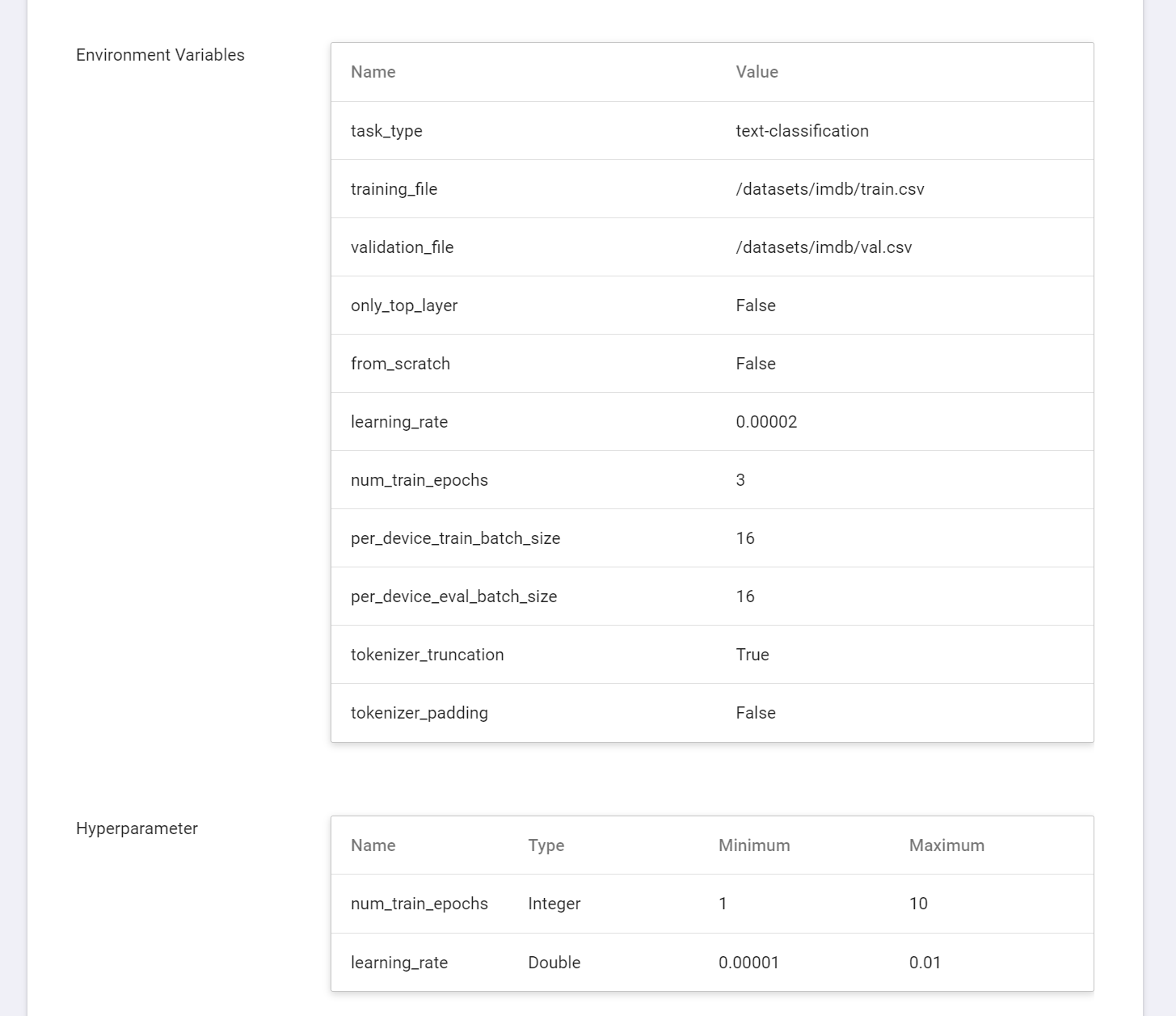
When entering the basic information, choose to apply the **`huggingface-text-classification`** template, and the basic variables and commands will be automatically brought in. The values of the variable settings can be adjusted or added according to your development needs. The parameters provided by the **`huggingface-text-classification`** template are described below.
| Variable Name | Default | Description |
| --- | --- |--- |
| task_type | text-classification | Hugging Face Task Type |
| training_file | /datasets<br>/imdb<br>/train.csv | Training Dataset description file, absolute path of the mounted bucket. |
| validation_file | /datasets<br>/imdb<br>/val.csv | Validation Dataset description file, if not specified, will be split from the training set based on the `validation_size`. |
| validation_size | 0.2 | The Validation Dataset will only be generated if it is not explicitly specified. It will be randomly generated from the training set based on the defined ratio. In addition to specifying a ratio (decimal), you can also specify the exact number (integer) to be used as the validation set. |
| pretrained_model | [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) | The pre-trained model for an AI job can be specified either by using [Hugging Face Models](https://huggingface.co/models) or by providing the path to the model stored in the bucket. When creating a training job, you can add a new input source and specify the absolute path to the model. |
| pretrained_tokenizer | | Without specific settings, the training process will refer to the settings of the `pretrained_model`. In addition to specifying [Hugging Face Models](https://huggingface.co/models), you can also use the absolute path to the tokenizer folder stored in the bucket. |
| model_config | | Without specific settings, the training process will refer to the settings of the `pretrained_model`. In addition to specifying [Hugging Face Models](https://huggingface.co/models), you can also use the absolute path to the folder containing the model configuration file `config.json` stored in the bucket. |
| from_scratch | False | If set to `True`, the entire model will be retrained without using the parameters of the pre-trained model. |
| only_top_layer | False | If set to `True`, the base layer of the model will be frozen or fixed, and only the top layer will be adjusted. |
| tokenizer_truncation | True | Refer to [Hugging Face - Tokenizer](https://huggingface.co/docs/transformers/v4.21.1/en/main_classes/tokenizer#transformers.PreTrainedTokenizer.__call__.truncation) for the setting method. It can be set as a boolean or string value. If set to True, it will truncate the input based on either the `max_length` parameter or the maximum length accepted by the model. If set to `only_first` / `only_second`, it will perform the truncation respectively only on the first or second sequence of text. |
| tokenizer_padding | False | Refer to [Hugging Face - Tokenizer](https://huggingface.co/docs/transformers/v4.21.1/en/main_classes/tokenizer#transformers.PreTrainedTokenizer.__call__.padding) for the setting method. It can be set as a boolean or string value. If set to `True`, it will pad the input sequences in a batch based on the length of the longest sequence. Alternatively, you can set the `max_length` parameter as a benchmark. |
| tokenizer_max_length | | Refer to [Hugging Face - Tokenizer](https://huggingface.co/docs/transformers/v4.21.1/en/main_classes/tokenizer#transformers.PreTrainedTokenizer.__call__.max_length) for the setting method, which is the maximum length, and is used in conjunction with the first two parameters of `truncation` and `padding` |
:::info
:bulb: **Tips: Pre-trained Model**
`pretrained_model` must be a model based on `PyTorch` and `Transformers` framework and conform to the task type (`text-classification`) for it to be used.
:::
For advanced training parameter settings, please refer to the official documentation of [**Hugging Face - TrainingAuguments**](https://huggingface.co/docs/transformers/v4.21.1/en/main_classes/trainer#transformers.TrainingArguments). The following describes several commonly used parameters.
| Variable Name | Default | Description |
| --- | --- | --- |
| num_train_epochs | 3 | The number of training times for all datasets. If the [**max_steps**](https://huggingface.co/docs/transformers/v4.21.1/en/main_classes/trainer#transformers.TrainingArguments.max_steps) parameter is set, it will override the number of epochs when training the entire dataset. |
| learning_rate | 0.00002 | Learning rate |
| per_device_train_batch_size<br>per_device_eval_batch_size | 16<br>16 | |
| auto_find_batch_size | False | When enabled, it will automatically find a suitable batch_size to avoid CUDA Out-of-Memory errors |
| load_best_model_at_end | False | Whether to save the best model after training |
| evaluation_strategy<br>save_strategy | epoch<br>epoch | The values of these two parameters must be both epoch or steps |
| save_total_limit | 2 | Must be greater than or equal to 2, store the number of checkpoints, but all will be deleted after the final training |
| ... | ... | Other variables are used with reference to the original [**function library**](https://huggingface.co/docs/transformers/v4.21.1/en/main_classes/trainer#transformers.TrainingArguments) |
:::info
:bulb: **Tips: Items not currently supported**
| Variable Name | Default | Description |
| --- | --- | --- |
| use_iepx | False | Intel® Extension is not currently supported |
| tf32 | False | tf32 related settings are not currently supported |
| bf16<br>bf16_full_eval | False<br>False | bf16 related settings are not currently supported |
| xpu_backend | | Distributed training (mpi/ccl) is currently not supported |
| tpu_num_cores | | TPU is not currently supported |
| sharded_ddp | False | [FairScale](https://github.com/facebookresearch/fairscale) is not currently supported |
| fsdp<br>fsdp_min_num_params | False<br>0| [FSDP](https://pytorch.org/docs/stable/fsdp.html) is not currently supported |
| deepspeed | | [DeepSpeed](https://github.com/microsoft/deepspeed) is not currently supported |
:::
5. **Environment Variables and Hyperparameters**
Depending on the training method selected at [**Create Training Job**](#21-Create-Training-Job), which would be either **Smart ML Training Job** or **Normal Training Job**, the variable settings will be slightly different.
| Field name | Description |
| --- | --- |
| Environment variable | Enter the name and value of the environment variables. The environment variables here include not only the settings related to the training execution, but also the parameters required for the training network. |
| Hyperparameter<sup style="color:red"><b>\*</b></sup> | **(Smart ML Training Job)** This tells the job what parameters to try. Each parameter must have a name, type, and value (or range of values) when it is set. After selecting the type (integer, float, and array), enter the corresponding value format when prompted. |
| Target Parameter<sup style="color:red"><b>\*</b></sup> | **(Smart ML Training Job)** When using **`Bayesian`** or **`TPE`** algorithms, they will repeatedly adjust the appropriate parameters based on the results of the **target parameters** as a benchmark for the next training job. <br> After training, a value will be returned as the final result. Here, the name and target direction need to be set for this value. For example, if the returned value is the accuracy rate, you can name it accuracy and set its target direction to the maximum value; if the returned value is the error rate, you can name it error and set its direction to the minimum value.<br><br> The metrics provided according to the task type is **`accuracy`**, and its direction is **`Maximum`**. |
| Command | Enter the command or program name to be executed. The command provided in this image is: `python3.8 /usr/src/app/training.py`. |
| Trial Times<sup style="color:red"><b>\*</b></sup> | **(Smart ML Training Job)** That is, the number of training sessions, the training job is executed multiple times to find a better parameter combination. |
Here, **environment variables** and **hyperparameters** can switch from one to another. If you want a parameter to be a fixed value, you can remove it from the hyperparameter setting and add it to the environment variable with a fixed value; conversely, if you want to add the parameter to the trial, remove it from the environment variable and add it to the hyperparameter settings below.
6. **Review & Create**
Finally, confirm the entered information and click CREATE.
### 2.2 Start a Training Job
After completing the setting of the Training Job, go back to the **Training Job Management** page, and you can see the job you just created. Click the job to view the detailed settings of the training job. If the job state is displayed as **`Ready`**, you can click **START** to execute the training job.
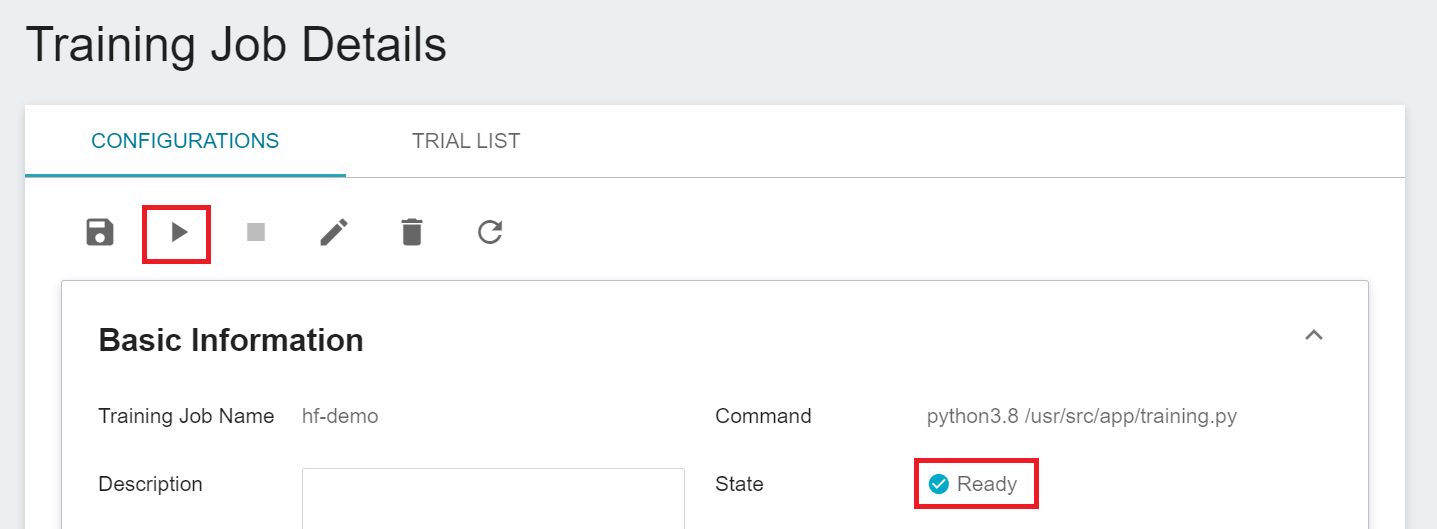
Once started, click the **TRIAL LIST** tab above to view the execution status and schedule of the job in the list. During training, you can click **VIEW LOG** or **VIEW DETAIL STATE** in the list on the right of the job to know the details of the current job execution.
### 2.3 View Training Results
Please refer to the [**AI Maker > View Training Results**](/s/ai-maker-en#View-Training-Results) documentation for step by step instructions. You can refer to the items starting with `eval_` for the Metrics of the training job. In this example, it is `eval_accuracy`. The larger the value, the better.

### 2.4 Model Registration
Select the result that meets expectation from one or more trial results, and then click **REGISTER MODEL** on the right to save them to Model Management; if no results meet expectation, then re-adjust the value or value range of environment variables and hyperparameters.
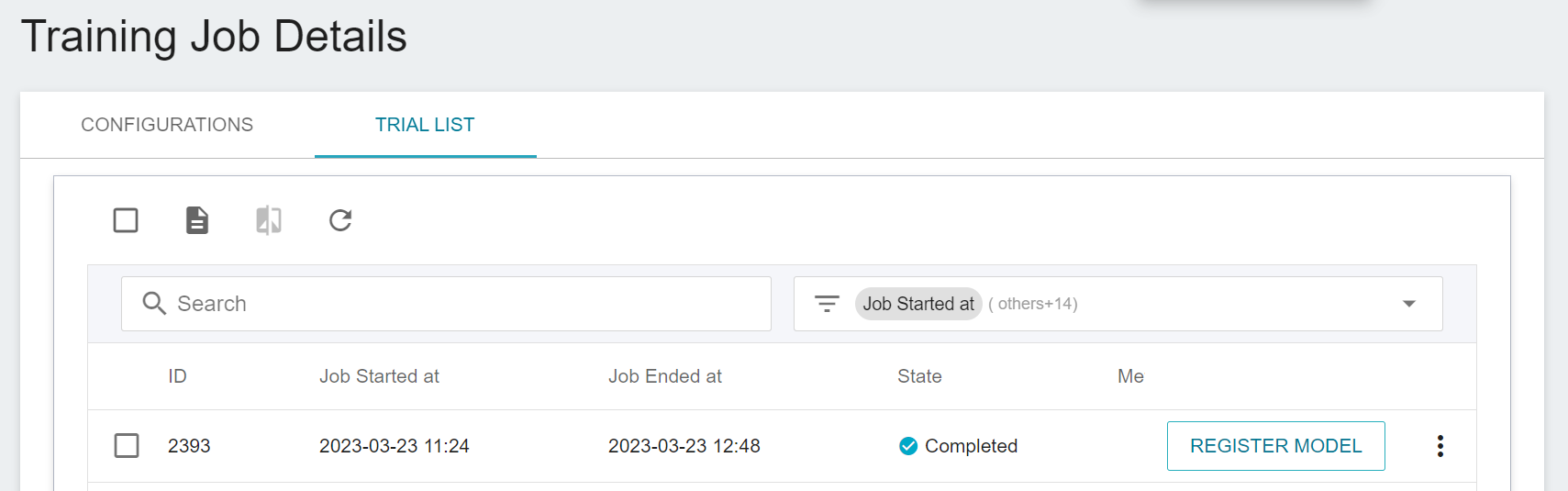
In the **Register Model** window, you can enter the desired model directory name. For example, you can input `hf-imdb` to create a new model directory, or choose an existing model directory.
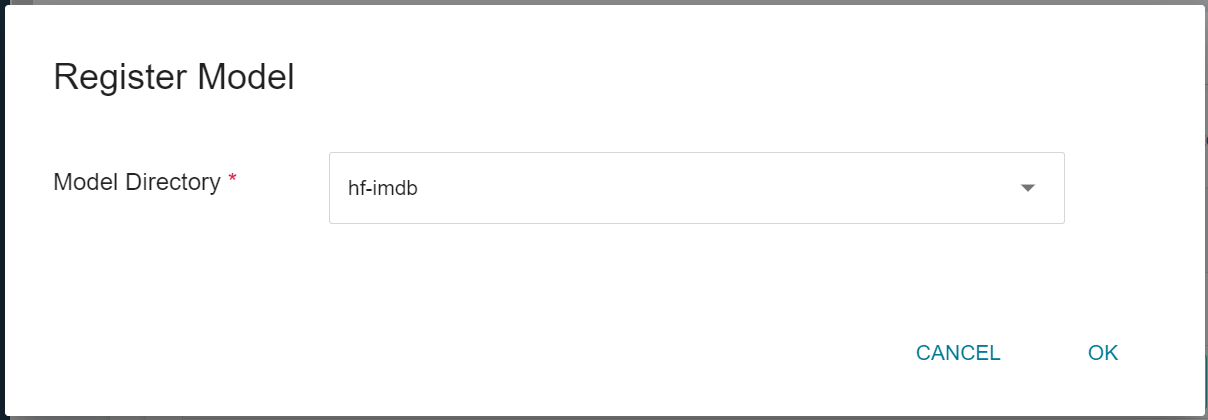
After saving, you can find the model in the model management list, click to enter the version list of the model, and you can see the version, type, description and source of the saved model.
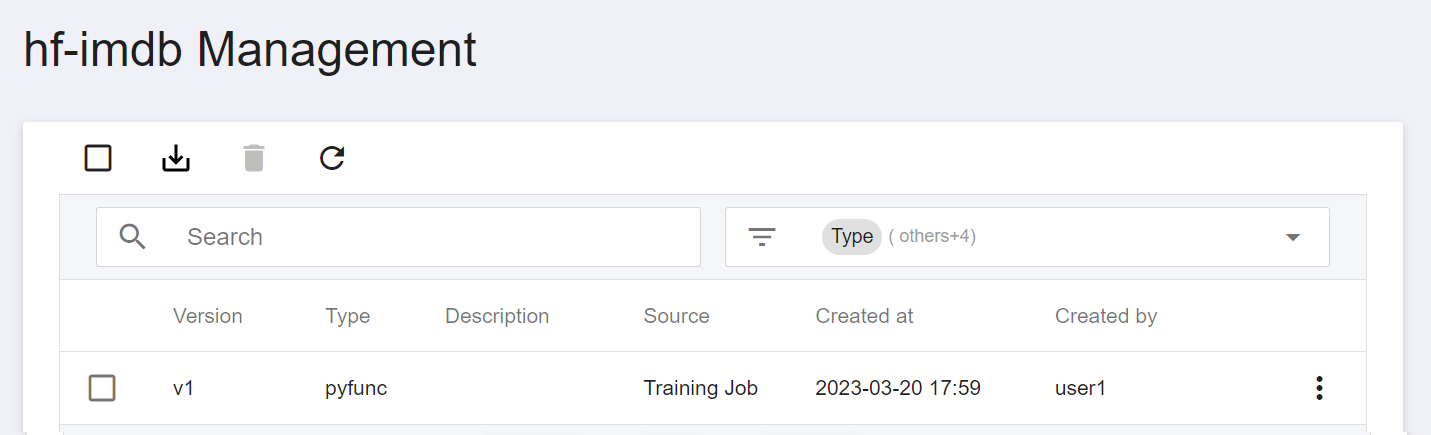
## 3. Create Inference Service
Once you have trained the network for text classification tasks and stored the trained model, you can deploy it to an application or service to perform inference using the **Inference** function.
### 3.1 Create Inference Service
First, click **Inference** in the Services on the left, enter the Inference Management page, and click **+ CREATE** to create an inference service. The steps for creating the inference tasks are described below:
1. **Basic Information**
First, change the **Create Method** to **Customization**. Similar to the previous settings, we also use the **`huggingface-text-classification`** template for the task. However, the model name and version number to be loaded still need to be set manually.
- **Name**
The file name of the loaded model, which can be input by the user. In this example, it is `model`.
- **Model Name**
The name of the model to be loaded is the model stored in [**2.4 Register Model**](#24-Model-Registration).
- **Version**
The version number of the model to be loaded is also the version number generated in [**2.4 Register Model**](#24-Model-Registration).
- **Mount Path**
The location of the loaded model is related to the model loading function in the Inference program. This value is set by the `huggingface-text-classification` Inference Template.
<br>
:::info
:bulb: **Tips:** Duplicated names are not allowed, please create your own name.
:::
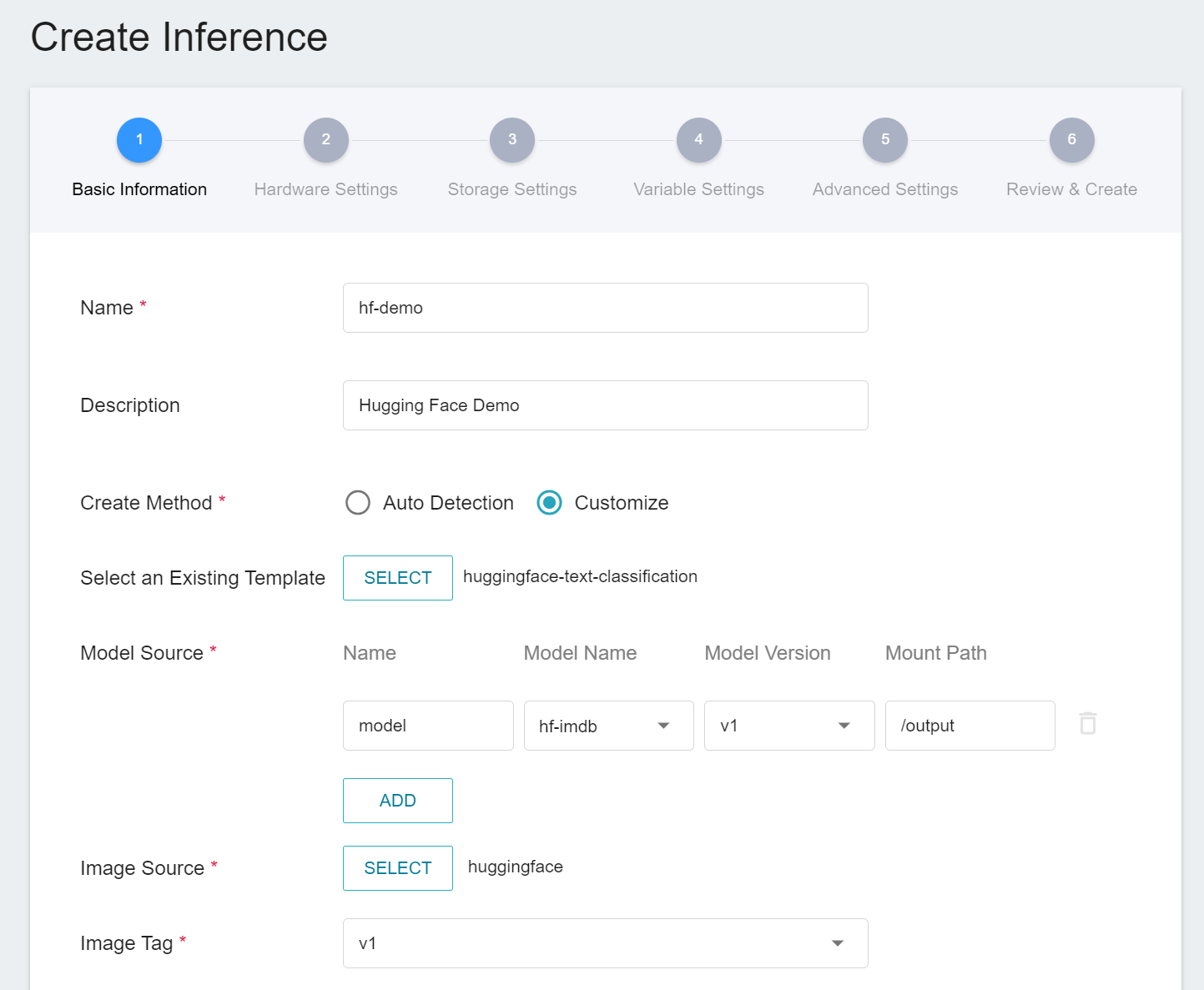
2. **Hardware Settings**
Select the appropriate hardware resource from the list with reference to the current available quota and requirements. If you want the response of the inference service to be more immediate, choose a specification that includes a **GPU**.
3. **Storage Settings**
No configuration is required for this step.
4. **Variable Settings**
In the Variable Settings step, the usual commands and parameters are automatically brought in when the template is applied.
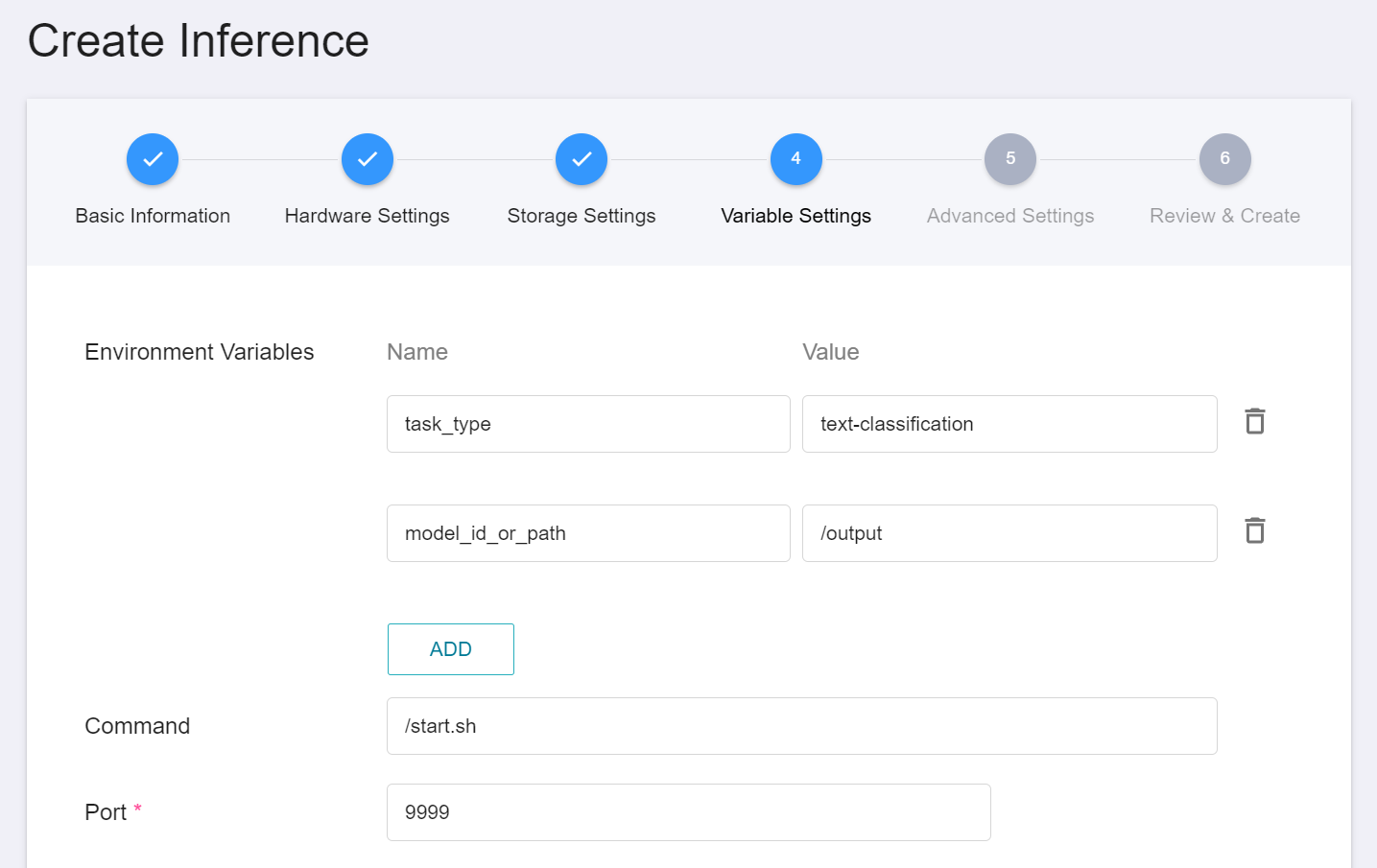
5. **Advanced Settings**
* **Monitor Data**
The purpose of monitoring is to observe the number of API calls and inference statistics over a period of time for the inference service.
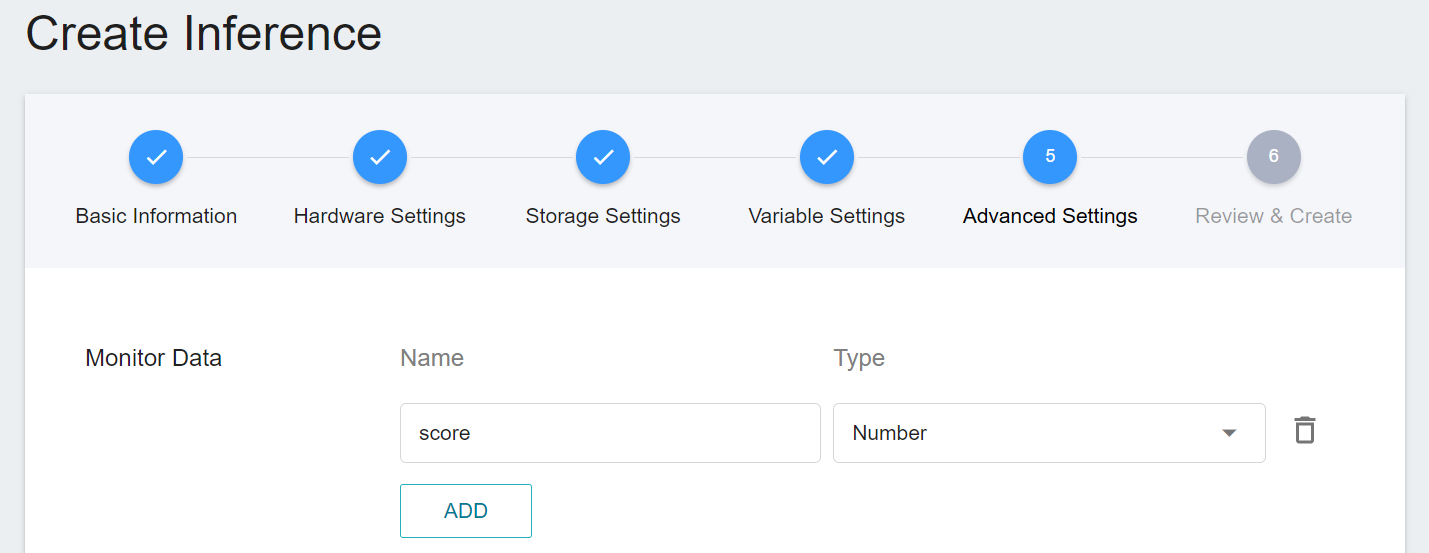
| Name | Type |Description |
|-----|-----|------------|
| score| Number | The score of the predicted type when the inference API is called once at a certain point in time.<br>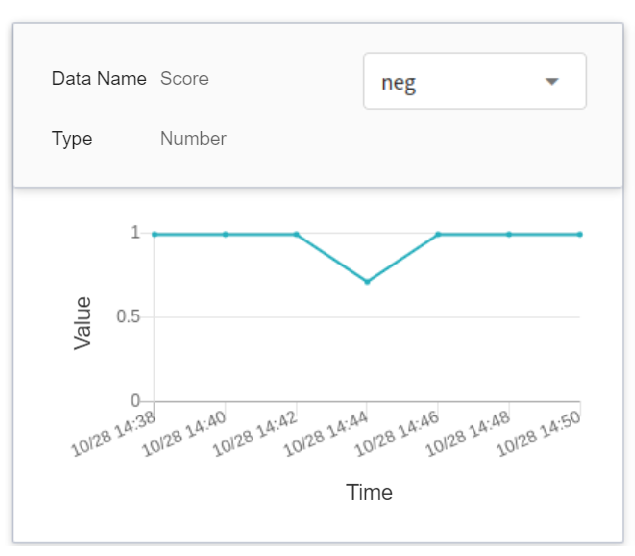|
<br>
6. **Review & Create**
Finally, confirm the entered information and click **CREATE**.
:::info
:bulb: **Tips:**
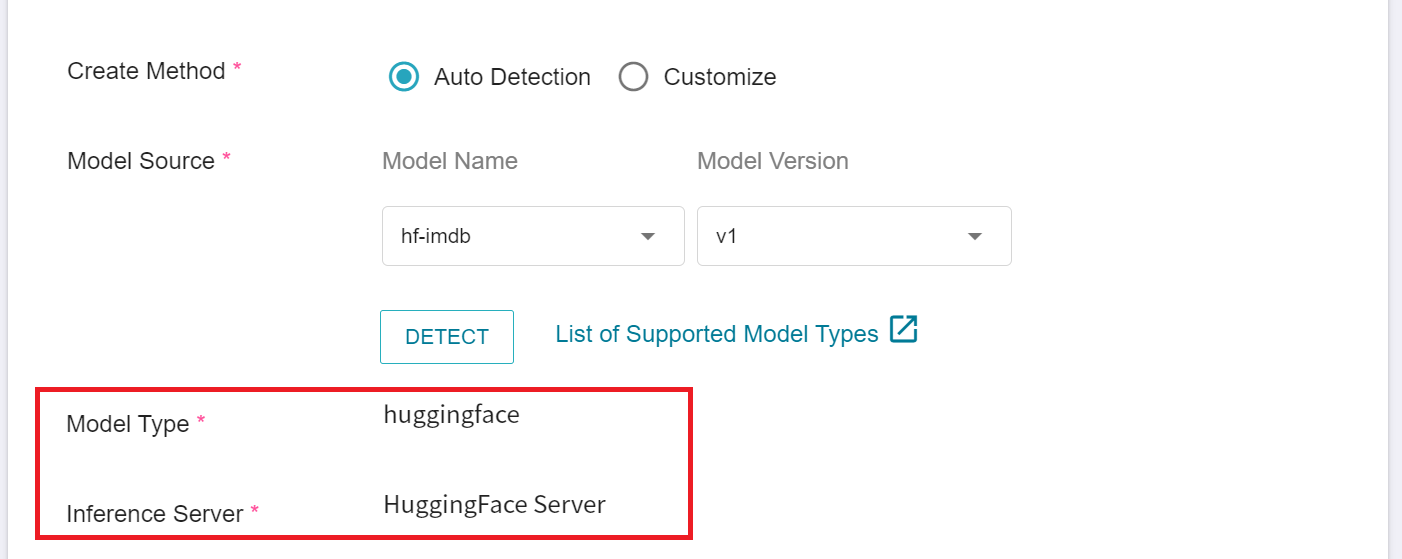
In addition to using the Template method, the system also provides an additional auto-detection method. Press the **DETECT** button, the Model Type will be displayed as **huggingface**, and the Inference Server will be **HuggingFace Server**.
:::
### 3.2 Make Inference
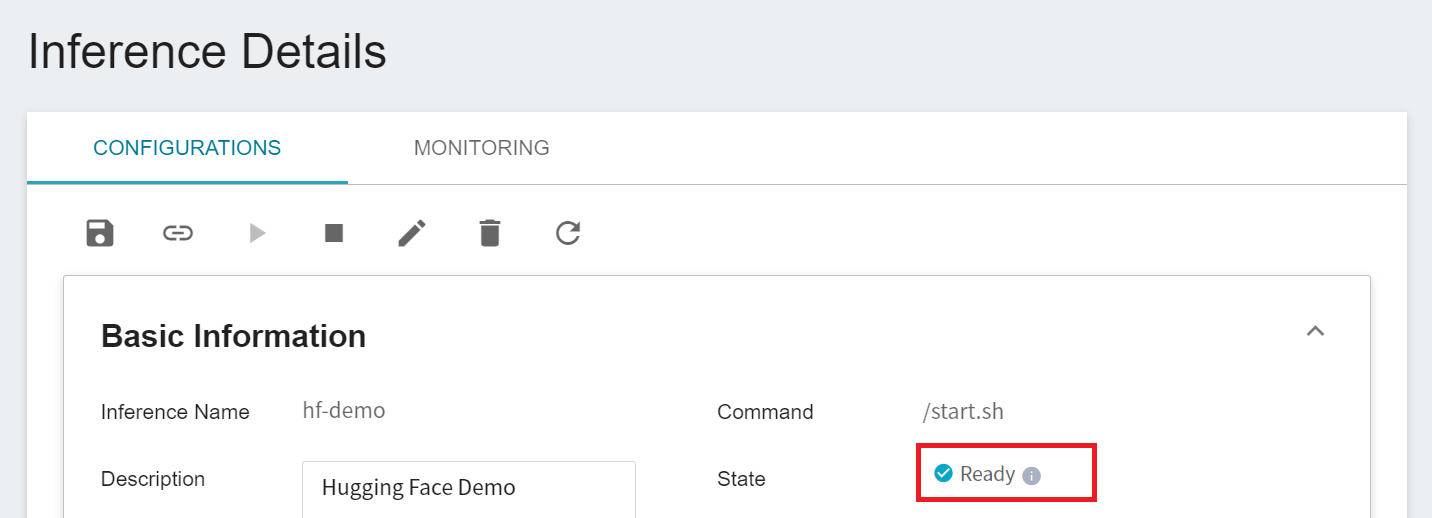
After completing the setting, please go to the Inference Service's detailed settings to confirm whether it is successfully started. When the service state shows as **`Ready`**, you can start connecting to the Inference Service.
Inference service currently does not support public Node Port for security reasons, we can communicate with the created Inference service through the **Notebook Service**. The way to communicate is through the **Network** information displayed at the bottom of the **Inference Details** page.
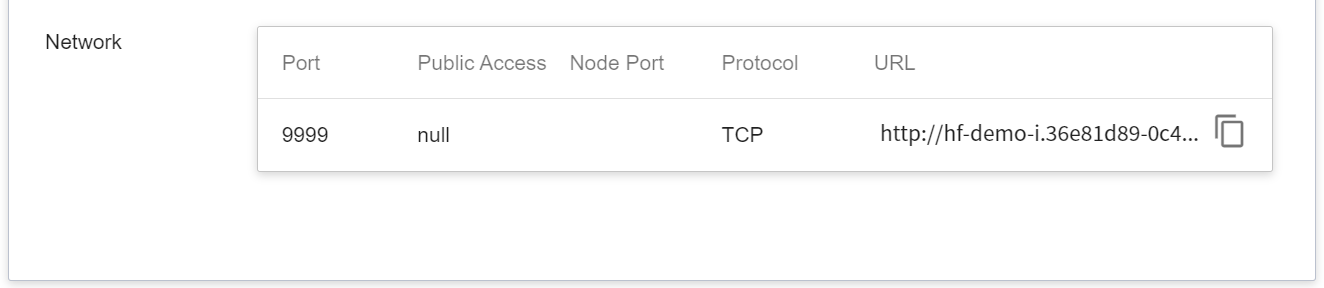
:::info
:bulb: **Tips: Inference Service URL**
- For security reasons, the **URL** provided by the inference service can only be used in the system's internal network, and cannot be accessed through the external Internet.
- To provide this Inference Service externally, please refer to [**AI Maker > Provide External Service**](/s/ai-maker-en#Making-Inference) for instructions.
:::
You can click on the **MONITORING** tab to see the relevant monitoring information on the monitoring page, and the following figure shows the inference results after a period of time.
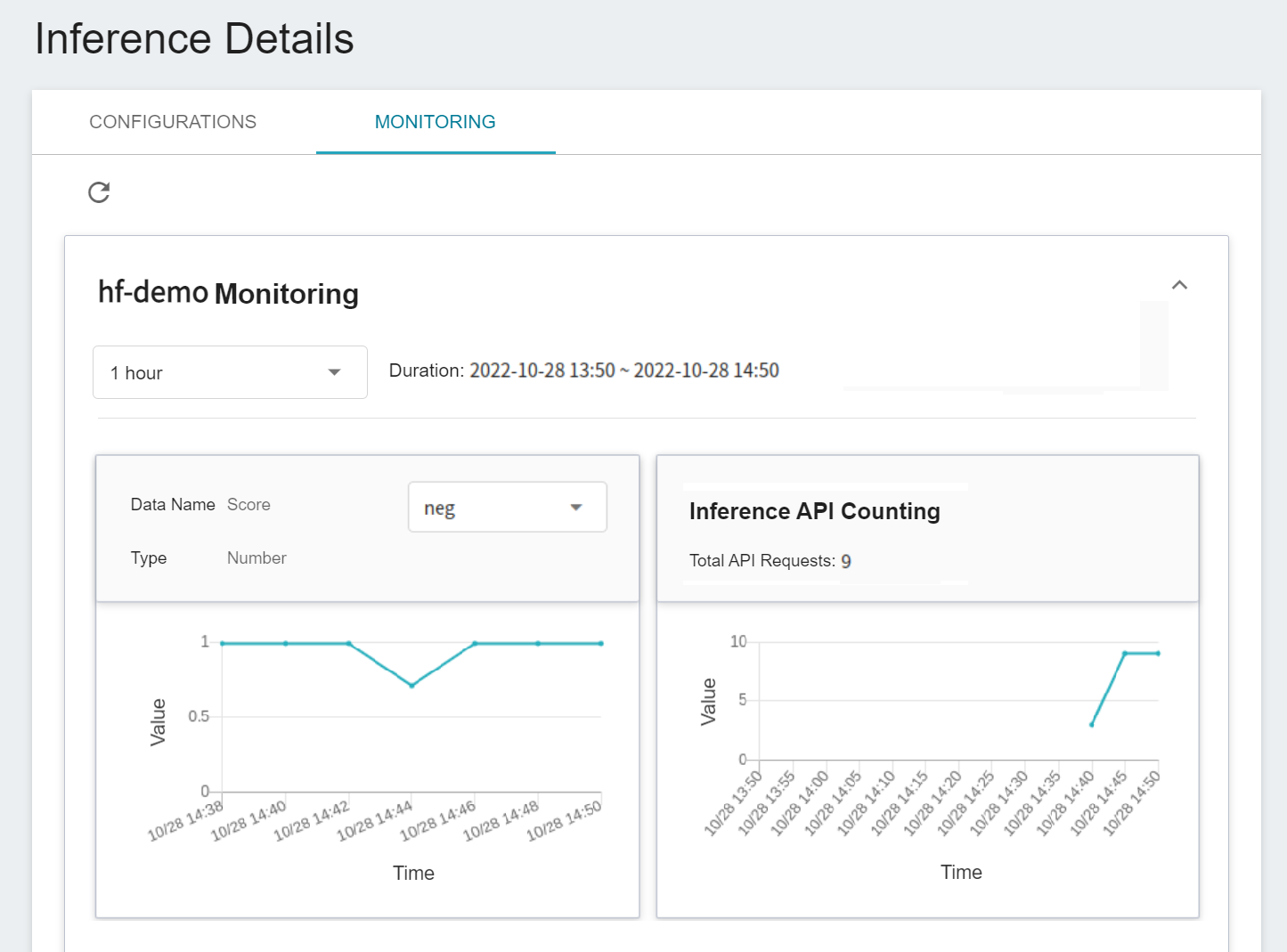
Click the Period menu to filter the statistics of the Inference API Call for a specific period, for example: 1 hour, 3 hours, 6 hours, 12 hours, 1 day, 7 days, 14 days, 1 month, 3 months, 6 months, 1 year, or custom.

:::info
:bulb: **About the start and end time of the observation period**
For example, if the current time is 15:10, then.
- **1 Hour** refers to 15:00 ~ 16:00 (not the past hour 14:10 ~ 15:10)
- **3 Hours** refers to 13:00 ~ 16:00
- **6 Hours** refers to 10:00 ~ 16:00
- And so on.
:::
#### 3.2.1 Test the Inference Service with the curl Command
If you want to test the Inference service, you can use the [**Notebook Service**](s/notebook-en), and apply the PyTorch framework, such as `PyTorch-21.02-py3`, and use curl to call send Inference API requests:
```python
!curl -X POST hf-demo-i.36e81d89-0c43-4e89-a7d8-a58705042436:9999 -d "I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn't match the background, and painfully one-dimensional characters cannot be overcome with a 'sci-fi' setting. (I'm sure there are those of you out there who think Babylon 5 is good sci-fi TV. It's not. It's clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It's really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it's rubbish as they have to always say ""Gene Roddenberry's Earth..."" otherwise people would not continue watching. Roddenberry's ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again."
```
When the server receives the comment text, it will classify and predict, and finally return whether the text is a positive or negative comment, as well as the score:
> [{"label":"neg","score":0.997795820236206}]
#### 3.2.2 Use Python Program to Run Inference Service
In addition to using curl, you can also use [**Notebook Service**](/s/notebook-en) with the PyTorch development framework, such as `PyTorch-21.02-py3` to launch JupyterLab and establish a connection with the inference service. Below is an example code snippet:
1. **Send Request**
Use the requests module here to generate an HTTP POST request. The **`endpoint`** variable needs to be filled with the URL link of the inference service.
```python=
import json
import requests
def predict(text):
endpoint = "http://hf-demo-i.36e81d89-0c43-4e89-a7d8-a58705042436:9999"
return requests.post(endpoint, data=text.encode('utf-8'))
response = predict("I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn't match the background, and painfully one-dimensional characters cannot be overcome with a 'sci-fi' setting. (I'm sure there are those of you out there who think Babylon 5 is good sci-fi TV. It's not. It's clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It's really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it's rubbish as they have to always say ""Gene Roddenberry's Earth..."" otherwise people would not continue watching. Roddenberry's ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again.")
print(response.json())
```
2. **Retrieve Results**
After text classification is complete, the result will be returned in JSON format, including the predicted type and score.
> [{'label': 'neg', 'score': 0.9963846206665039}]